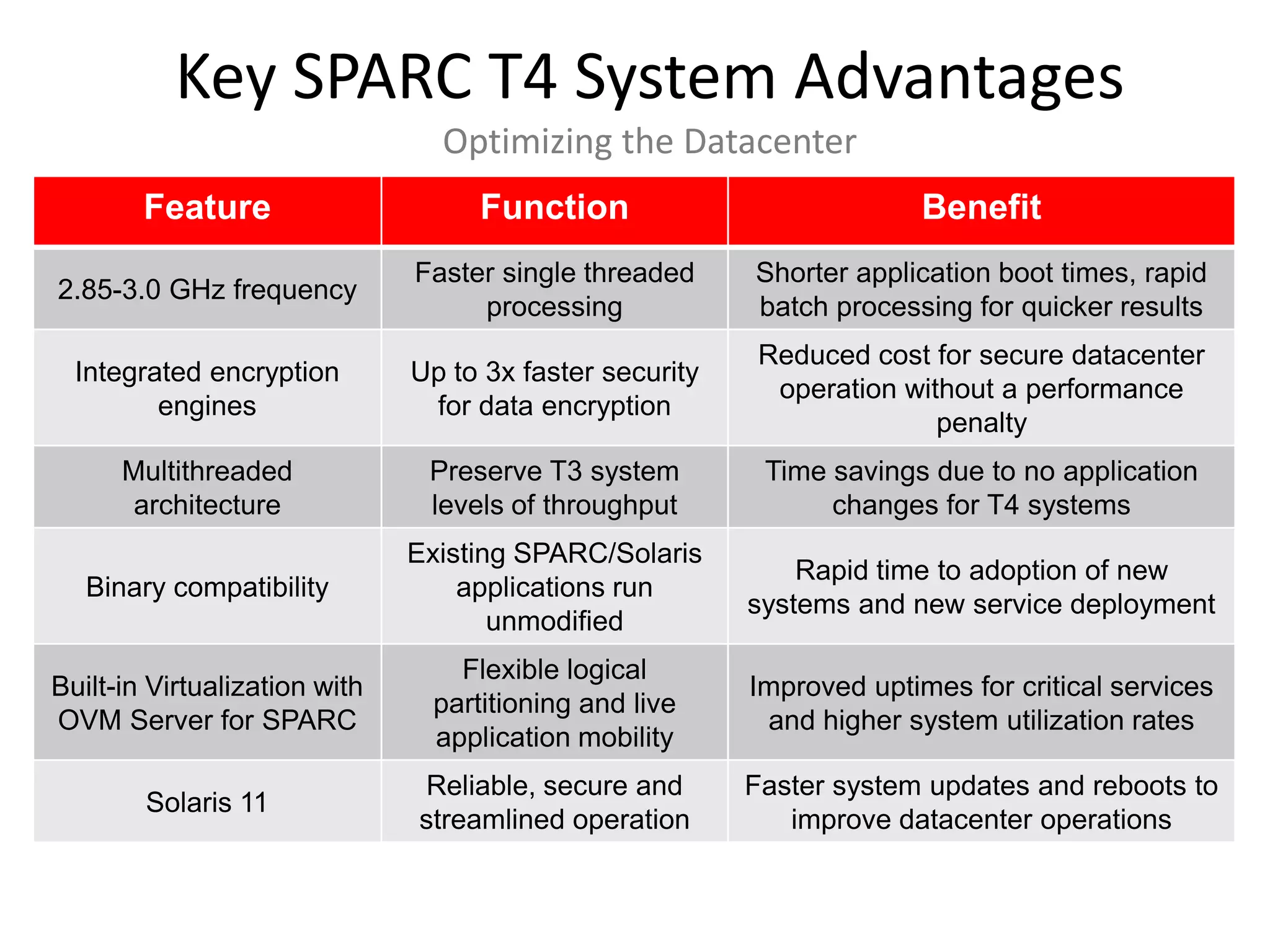
The document introduces Oracle's new SPARC T4 servers and SPARC SuperCluster solution. It provides details on the SPARC T4 processor architecture and its 5x single-thread performance increase over prior generations. It then describes the SPARC T4 server product line and highlights the performance and value advantages of the SPARC SuperCluster solution for data center consolidation, which combines SPARC T4 servers with Exadata storage.
















































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













