Download as PDF, PPTX



























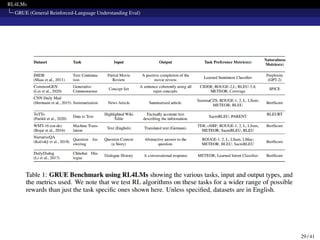




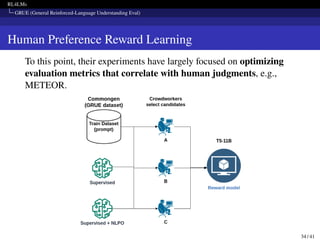








The document presents RL4LMs, a library for training language models with reinforcement learning. It introduces RL4LMs, which enables generative models to be optimized with RL algorithms. It also presents the GRUE benchmark for evaluating models, which pairs NLP tasks with reward functions capturing human preferences. Additionally, it introduces the NLPO algorithm that dynamically learns task-specific constraints to reduce the large action space in language generation. The goal is to facilitate research in building RL methods to better align language models with human preferences.
































![Quark: Controllable Text Generation with Reinforced [Un]learning.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20240409-240409112908-c718b77c-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)