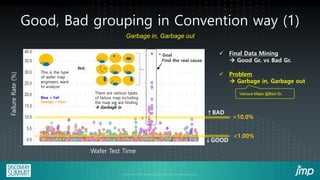
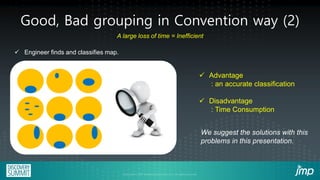
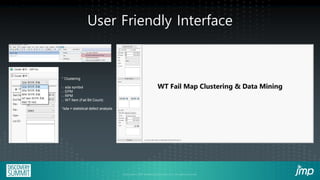
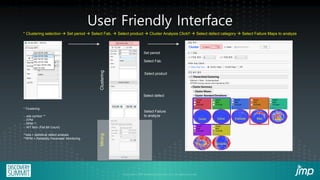
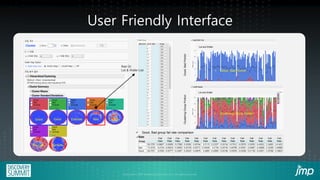
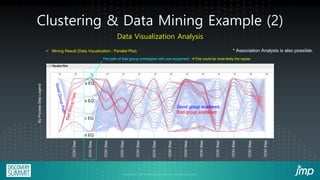
This document describes how semiconductor wafer test failure maps can be clustered and analyzed using a JMP add-in to more efficiently identify defects. Conventionally, engineers manually group wafers as good or bad, which is time-consuming and leads to inaccurate classifications. The JMP add-in provides a user-friendly interface for engineers to automatically cluster failure maps based on selected parameters like fab, product, and defect type. It then performs data mining algorithms to identify potential causes of defects ranked by likelihood. Examples show how the add-in can detect equipment issues or delayed process steps for the bad wafer cluster compared to the good cluster. Using this method reduces the time engineers spend on classification and analysis from hours to minutes.










![WF Count Human [min] AI [min]
100 6 0.03
1000 60 0.16
3000 180 5
Clustering Process Time [ Human vs AI ]
Human
[min]
AI
[min]
AI
180min
5min
Human
Wafer Count
✓ Dramatically reduces time consumption for engineer](https://image.slidesharecdn.com/track3-1skhynixtl-231113053259-553dea2f/85/3-1-Semiconductor-Wafer-Test-Fail-Map-Clustering-and-Data-Mining-Using-JMP-Add-in-SK-Hynix-TL-17-320.jpg)




















![[PaperReview] LightGCN: Simplifying and Powering Graph Convolution Network fo...](https://cdn.slidesharecdn.com/ss_thumbnails/lightgcn-211217151725-thumbnail.jpg?width=640&height=640&fit=bounds)



























































