自己紹介
1
岩村雅一
大阪府立大学 大学院工学研究科 准教授
[主な研究分野]
•文字認識
• 物体認識
• 視覚障害者支援システム
[主な受賞]
• 2006年:電子情報通信学会 論文賞
• 2007年:ICDAR Best Paper Award
• 2010年:DAS Best Paper Award
• 2011年:IAPR/ICDAR Young
Investigator Award
• 2017年:MVA Best Paper Award
山田良博
大阪府立大学 大学院工学研究科 D2
日本学術振興会 特別研究員
[主な研究分野]
• 深層学習を用いた一般物体認識
(CIFAR-100データセットにおいて、
世界一の認識精度を二度達成)
[主な受賞]
• 2016&2017年度:電子情報通信学会
PRMU研究会 研究奨励賞(2年連続)
• 2017年:MIRU2017
インタラクティブ発表賞
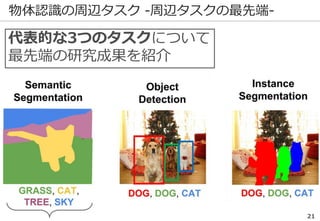
3.
自己紹介
2
岩村雅一
大阪府立大学 大学院工学研究科 准教授
[主な研究分野]
•文字認識
• 物体認識
• 視覚障害者支援システム
[主な受賞]
• 2006年:電子情報通信学会 論文賞
• 2007年:ICDAR Best Paper Award
• 2010年:DAS Best Paper Award
• 2011年:IAPR/ICDAR Young
Investigator Award
• 2017年:MVA Best Paper Award
山田良博
大阪府立大学 大学院工学研究科 D2
日本学術振興会 特別研究員
[主な研究分野]
• 深層学習を用いた一般物体認識
(CIFAR-100データセットにおいて、
世界一の認識精度を二度達成)
[主な受賞]
• 2016&2017年度:電子情報通信学会
PRMU研究会 研究奨励賞(2年連続)
• 2017年:MIRU2017
インタラクティブ発表賞
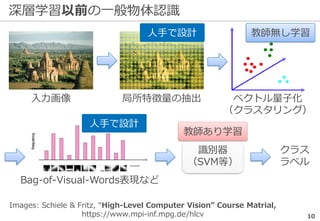
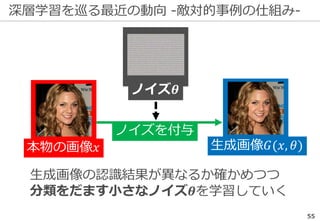
勝手に始めた人巻き込まれた人
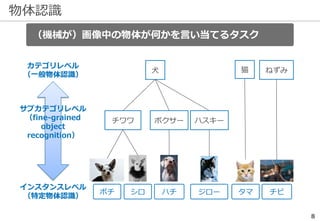
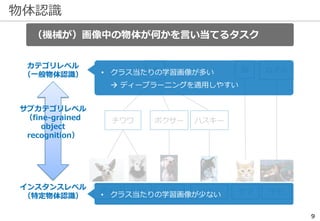
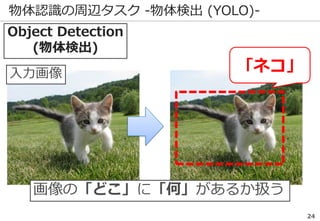
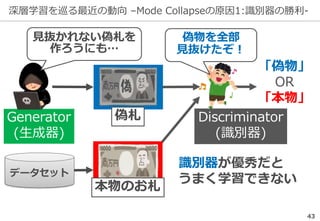
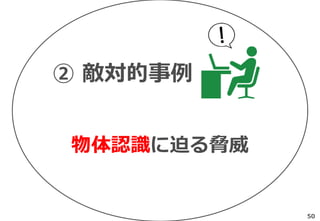
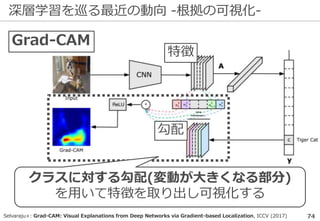
物体認識の周辺タスク -UberNet-
入力画像
Kokkinos+: UberNet: Training a ‘Universal’ Convolutional Neural Network for Low-,
Mid-, and High-Level Vision using Diverse Datasets and Limited Memory, CVPR (2017)
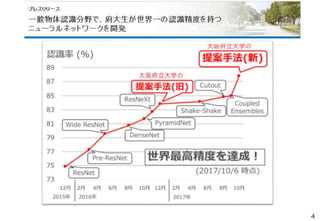
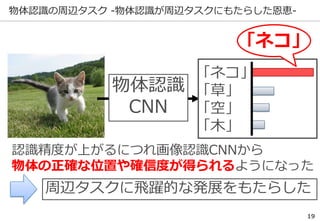
物体認識の精度向上で様々な周辺タスクが
同時に解けるまでになっている
20
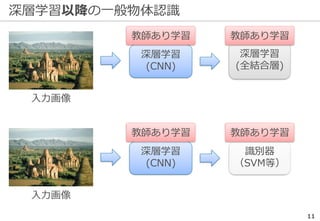
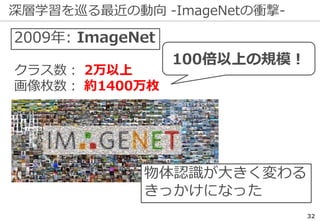
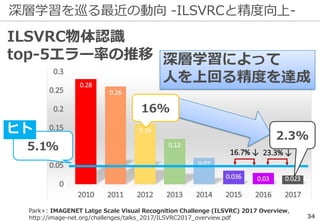
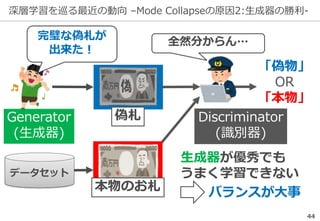
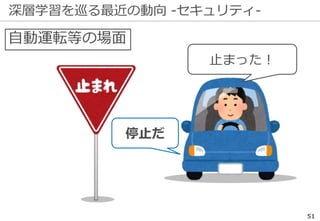
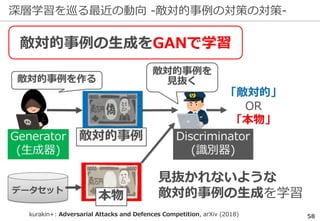
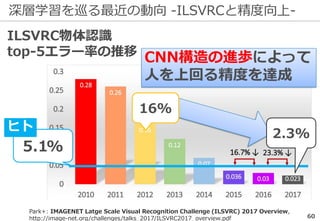
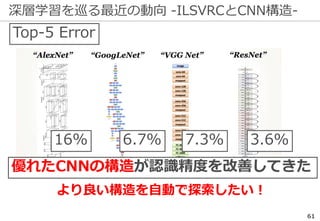
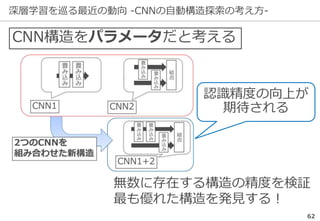
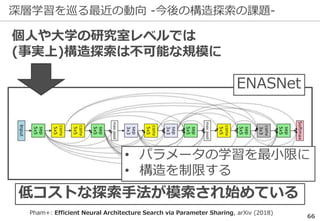
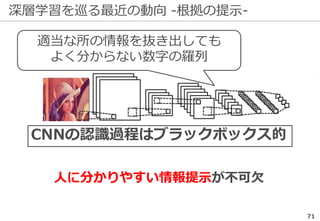
深層学習を巡る最近の動向 -ILSVRCの終了-
35
Fei-Fei+: IMAGENETWhere have we been? Where are we going?,
http://image-net.org/challenges/talks_2017/imagenet_ilsvrc2017_v1.0.pdf
ILSVRCは一定の役割を終えたとして
2017年で終了した
精度向上の結果...
※ 後継としてOpen Images Challengeが開催される
研究の主流は『単なる認識』以上の
タスクへ向きつつある
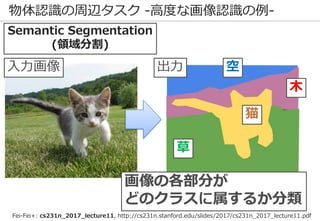
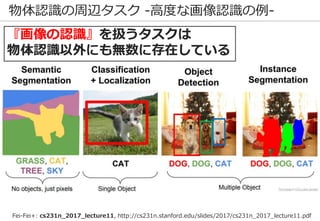
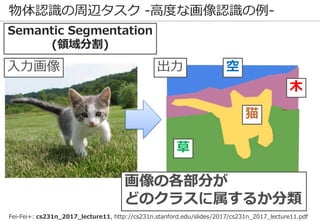
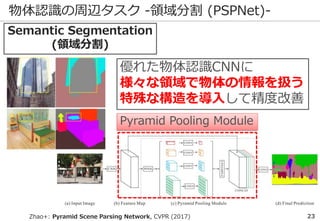
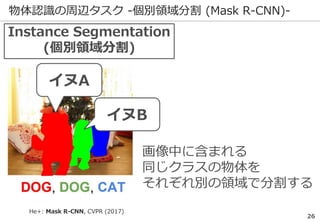
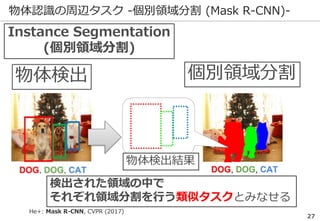
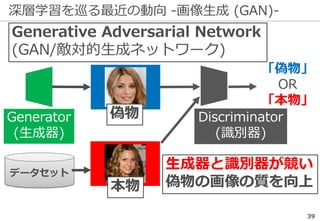
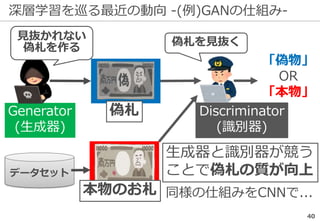
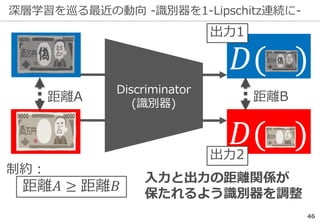
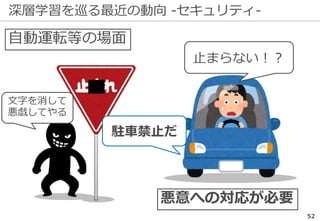
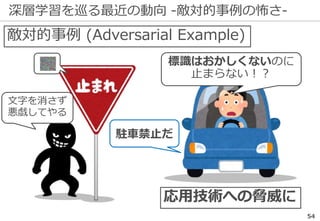
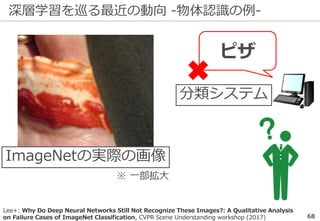
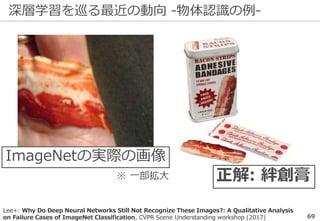
深層学習を巡る最近の動向 -物体認識の例-
69
正解: 絆創膏
ImageNetの実際の画像
※一部拡大
Lee+: Why Do Deep Neural Networks Still Not Recognize These Images?: A Qualitative Analysis
on Failure Cases of ImageNet Classification, CVPR Scene Understanding workshop (2017)


![自己紹介
1
岩村雅一
大阪府立大学 大学院工学研究科 准教授
[主な研究分野]
• 文字認識
• 物体認識
• 視覚障害者支援システム
[主な受賞]
• 2006年:電子情報通信学会 論文賞
• 2007年:ICDAR Best Paper Award
• 2010年:DAS Best Paper Award
• 2011年:IAPR/ICDAR Young
Investigator Award
• 2017年:MVA Best Paper Award
山田良博
大阪府立大学 大学院工学研究科 D2
日本学術振興会 特別研究員
[主な研究分野]
• 深層学習を用いた一般物体認識
(CIFAR-100データセットにおいて、
世界一の認識精度を二度達成)
[主な受賞]
• 2016&2017年度:電子情報通信学会
PRMU研究会 研究奨励賞(2年連続)
• 2017年:MIRU2017
インタラクティブ発表賞](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-2-320.jpg)
![自己紹介
2
岩村雅一
大阪府立大学 大学院工学研究科 准教授
[主な研究分野]
• 文字認識
• 物体認識
• 視覚障害者支援システム
[主な受賞]
• 2006年:電子情報通信学会 論文賞
• 2007年:ICDAR Best Paper Award
• 2010年:DAS Best Paper Award
• 2011年:IAPR/ICDAR Young
Investigator Award
• 2017年:MVA Best Paper Award
山田良博
大阪府立大学 大学院工学研究科 D2
日本学術振興会 特別研究員
[主な研究分野]
• 深層学習を用いた一般物体認識
(CIFAR-100データセットにおいて、
世界一の認識精度を二度達成)
[主な受賞]
• 2016&2017年度:電子情報通信学会
PRMU研究会 研究奨励賞(2年連続)
• 2017年:MIRU2017
インタラクティブ発表賞
勝手に始めた人巻き込まれた人](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-3-320.jpg)































![自己教師あり学習 (Self-supervised Learning)
76
例1:画像の色づけ [1]
• カラー画像から白黒画像を生成
• 白黒画像からカラー画像を予測
例2:動きの推定 [2]
• 動画中の2枚の画像からカメラ
の動きを推定
「手動のラベル付け」無しで特徴表現を学習
入力 出力・教師
予測
[1] Zhang+: Colorful Image Colorization, ECCV (2016)
[2] Agrawal+: Learning to See by Moving, ICCV (2015)
生成
入力 出力・教師
カ
メ
ラ
の
動
き
Egomotionはタダで
入手可能と仮定](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-77-320.jpg)
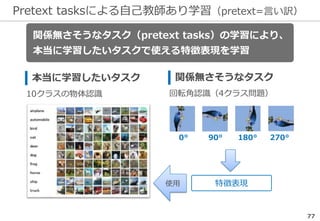

![Pretext tasksによる自己教師あり学習:1. 幾何変換
79
[3] Gidaris+: Unsupervised Representation Learning by Predicting Image Rotations,
ICLR (2018)
[4] Kilinc+: Learning Latent Representations in Neural Networks for Clustering through
Pseudo Supervision and Graph-based Activity Regularization, ICLR (2018)
回転のみ [3]
• 4クラス問題
0° 90° 180° 270°
回転と左右反転 [4]
• 8クラス問題
共通の性質(数値は[3]より抜粋)
• 90°ずつの回転が最も精度が高い
回転角 45° 90° 180°
精度
(%)
88.51 89.06
87.46
85.52
• 精度は教師あり学習には劣る
教師あり 自己教師あり
CIFAR-10 92.80 91.16
ImageNet 59.7 50.0
PASCAL
VOC
79.9 72.97](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-80-320.jpg)
![Pretext tasksによる自己教師あり学習:1. 幾何変換
80
[3] Gidaris+: Unsupervised Representation Learning by Predicting Image Rotations,
ICLR (2018)
教師あり学習 自己教師あり学習入力
学習で得られた特徴 [3]
教師あり学習と同様の特徴が得られている](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-81-320.jpg)
![Pretext tasksによる自己教師あり学習:2. 計数
81
[5] Noroozi+: Representation Learning by Learning to Count, ICCV (2017)
画像全体に含まれる物体の数は、画像の各領域に含まれる
物体の数の和という制約を利用して、画像の特徴表現を学習
画像全体の物体数
画像を4分割したときの
各領域の物体数](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-82-320.jpg)
![Pretext tasksによる自己教師あり学習:3. マルチモダリティ
82
画像と音声の組み合わせが正しいかどうかを判別することで、
画像と音声の特徴表現を学習
同じ動画のものか判定
動画
音声特徴の抽出
画像特徴の抽出
[6] Arandjelović+: Look, Listen and Learn, ICCV (2017)
画像
音声](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-83-320.jpg)
![Pretext tasksによる自己教師あり学習:4. カメラの動き
83
入力
特徴抽出 動きの推定
動画中の2枚の画像から「カメラの動き」を推定することで、
物体認識に使用できる特徴表現を学習
出力・教師
(タダで入手可能と仮定)
[2] Agrawal+: Learning to See by Moving, ICCV (2015)
カ
メ
ラ
の
動
き](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-84-320.jpg)
![Pretext tasksによる自己教師あり学習:5. パズル
84
隠れた部分を推定したり、パズルを解くことで、
物体認識に使用できる特徴表現を学習
[7] Noroozi+: Unsupervised Learning of Visual Representations by Solving Jigsaw
Puzzles, ECCV (2016)
元画像から緑の領域
を切り抜く
シャッフルした状態 正しく並べた状態
ジグソーパズル [7]](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-85-320.jpg)
![Pretext tasksによる自己教師あり学習:5. パズル
85
隠れた部分を推定したり、パズルを解くことで、
物体認識に使用できる特徴表現を学習
[8] Pathak+: Context Encoders: Feature Learning by Inpainting, CVPR (2016)
画像の穴埋め [8]
穴埋め結果入力
穴埋め](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-86-320.jpg)
![データセットの拡張:前処理の工夫
86
学習データを意図的に劣化させることで、学習を促進
[1] Zhong+: Random Erasing Data Augmentation, arXiv:1708.04896 (2017)
[2] DeVries+: Improved Regularization of Convolutional Neural Networks with Cutout,
arXiv:1708.04552 (2017)](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-87-320.jpg)
![データセットの拡張:データとクラスラベルの合成
87
画像と正解ラベルの中間状態を作り
学習サンプルを増やすことで学習性能を向上
[1] Tokozume+: Learning from Between-class Examples for Deep Sound Recognition,
ICLR (2018)
[2] Zhang+: mixup: Beyond Empirical Risk Minimization, ICLR (2018)
[3] Lee+: SGD on Random Mixtures: Private Machine Learning under Data Breach
Threats, ICLR Workshop (2018)
[4] Tokozume+: Between-class Learning for Image Classification, CVPR (2018)](https://image.slidesharecdn.com/v2-180618152816/85/Revised-on-18-July-2018-88-320.jpg)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)


