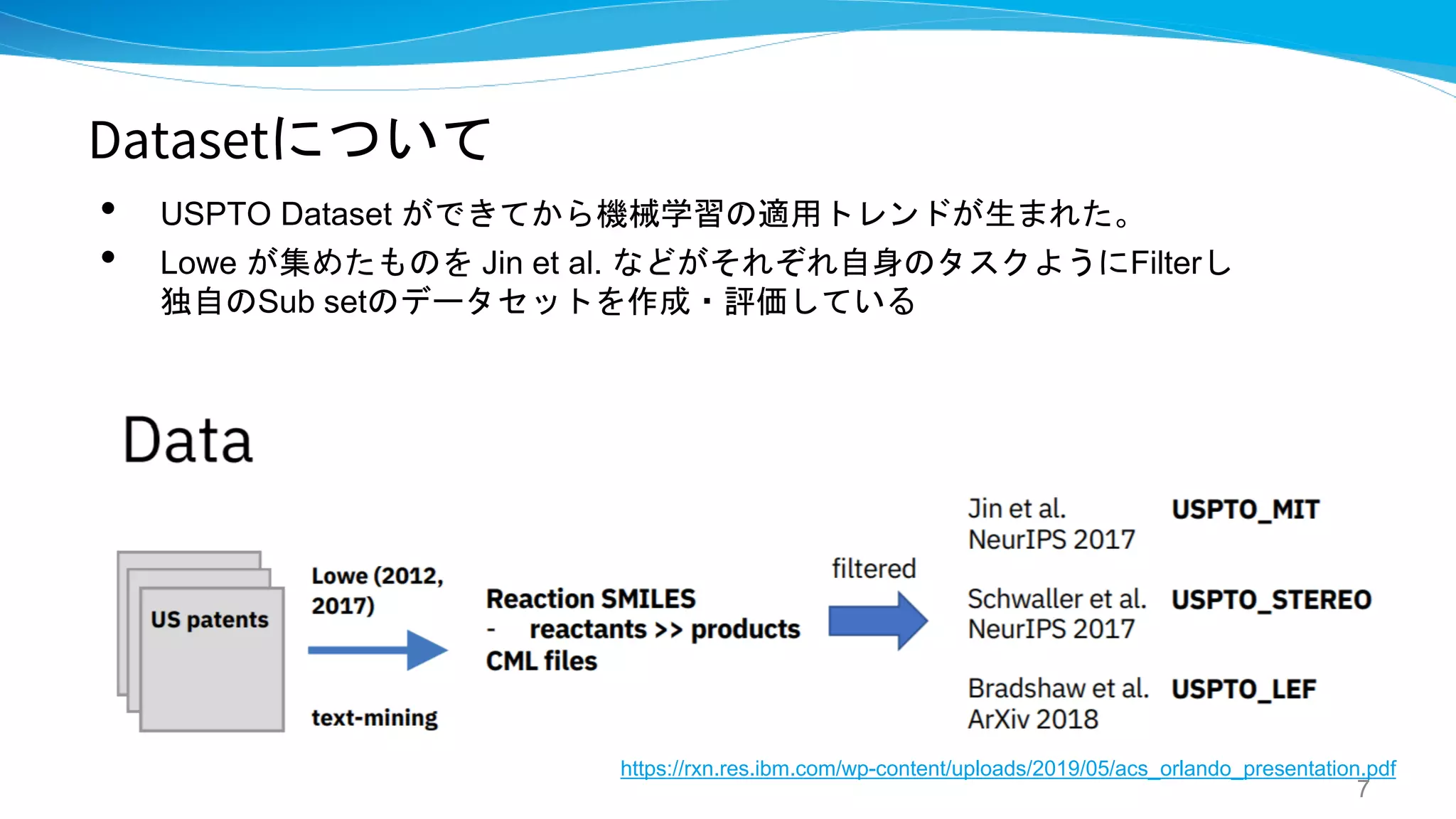
Datasetについて
• USPTO Datasetができてから機械学習の適用トレンドが生まれた。
• Lowe が集めたものを Jin et al. などがそれぞれ自身のタスクようにFilterし
独自のSub setのデータセットを作成・評価している
7
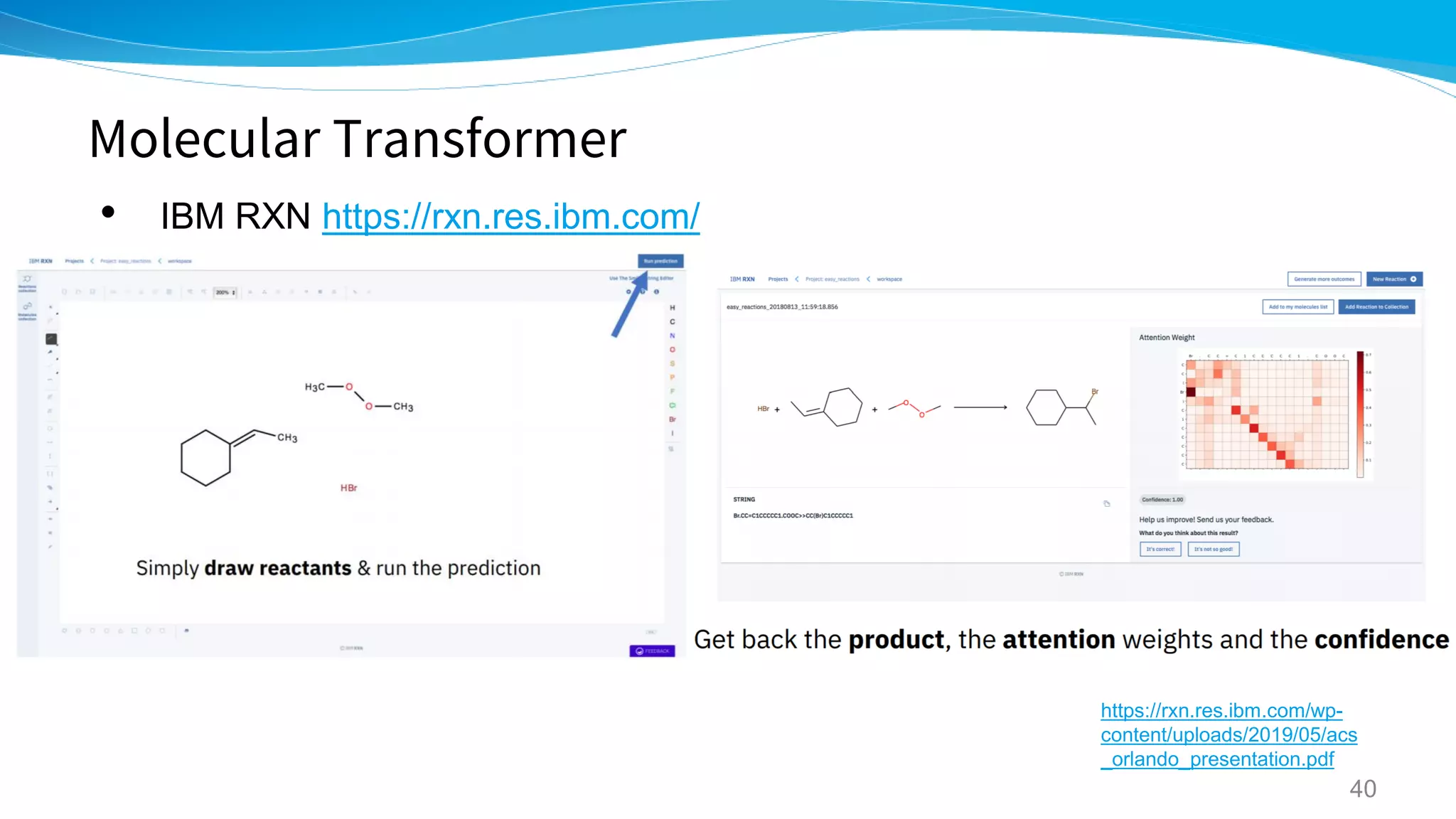
https://rxn.res.ibm.com/wp-content/uploads/2019/05/acs_orlando_presentation.pdf
8.
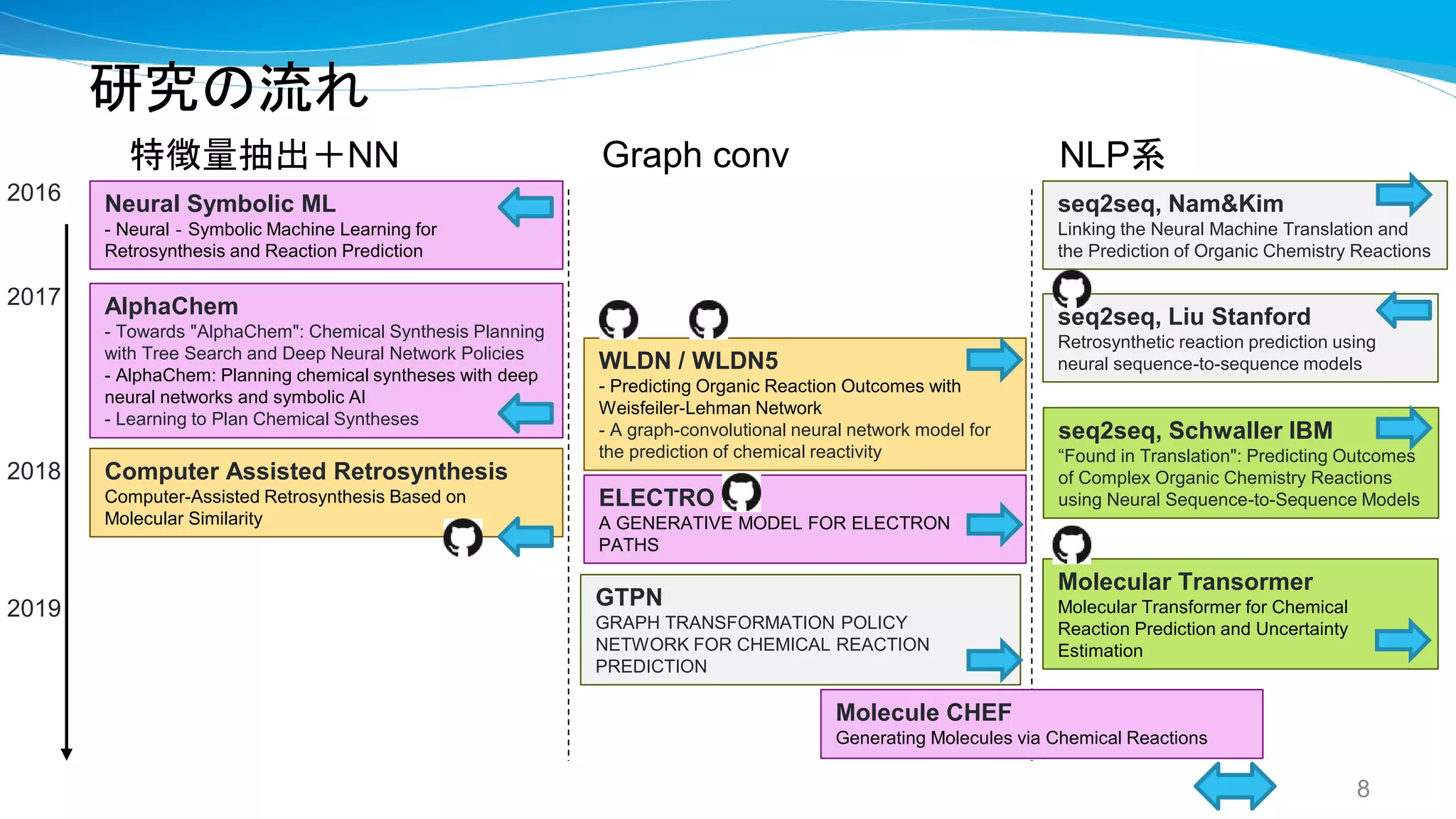
研究の流れ
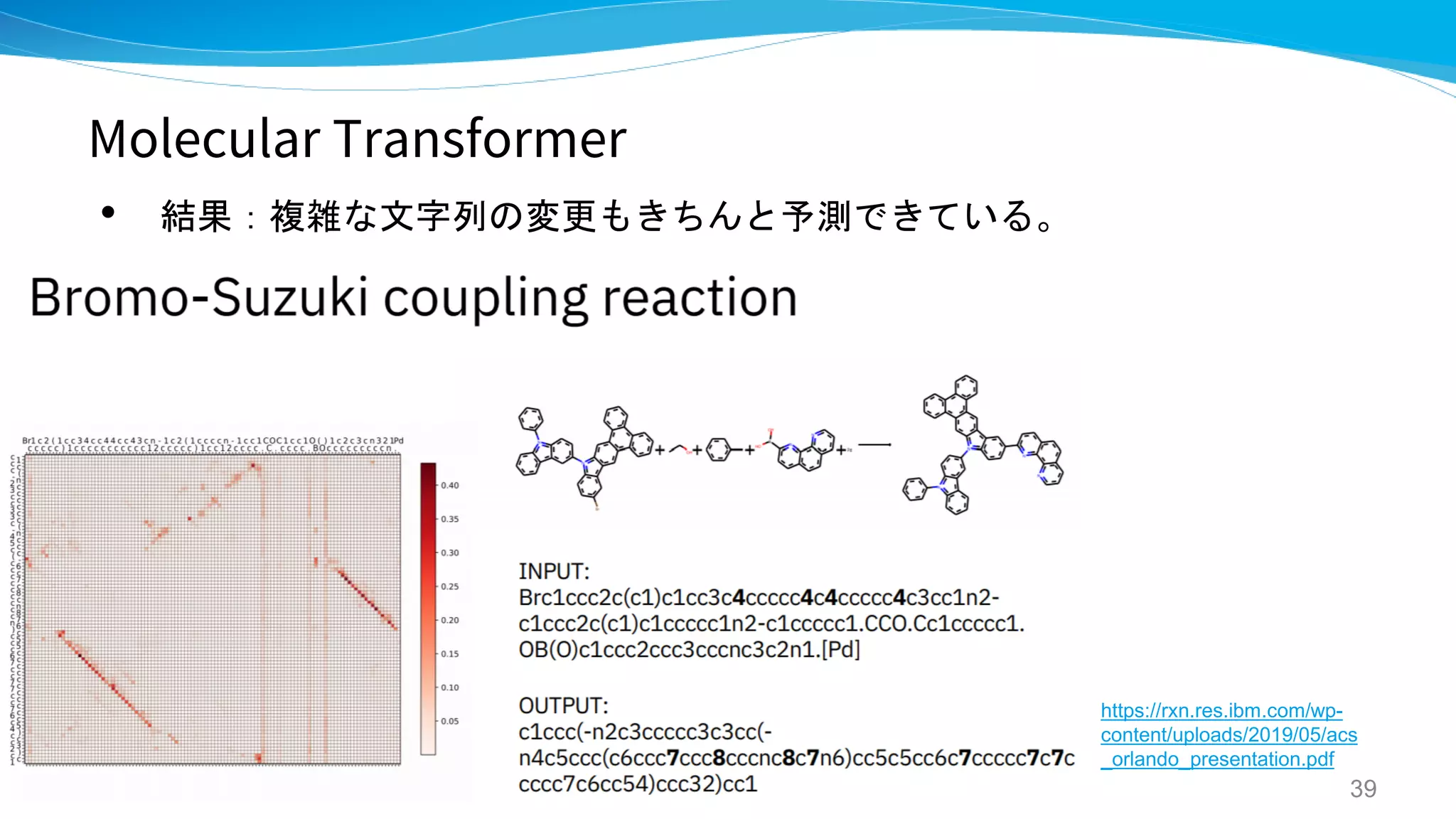
Molecular Transormer
Molecular Transformerfor Chemical
Reaction Prediction and Uncertainty
Estimation
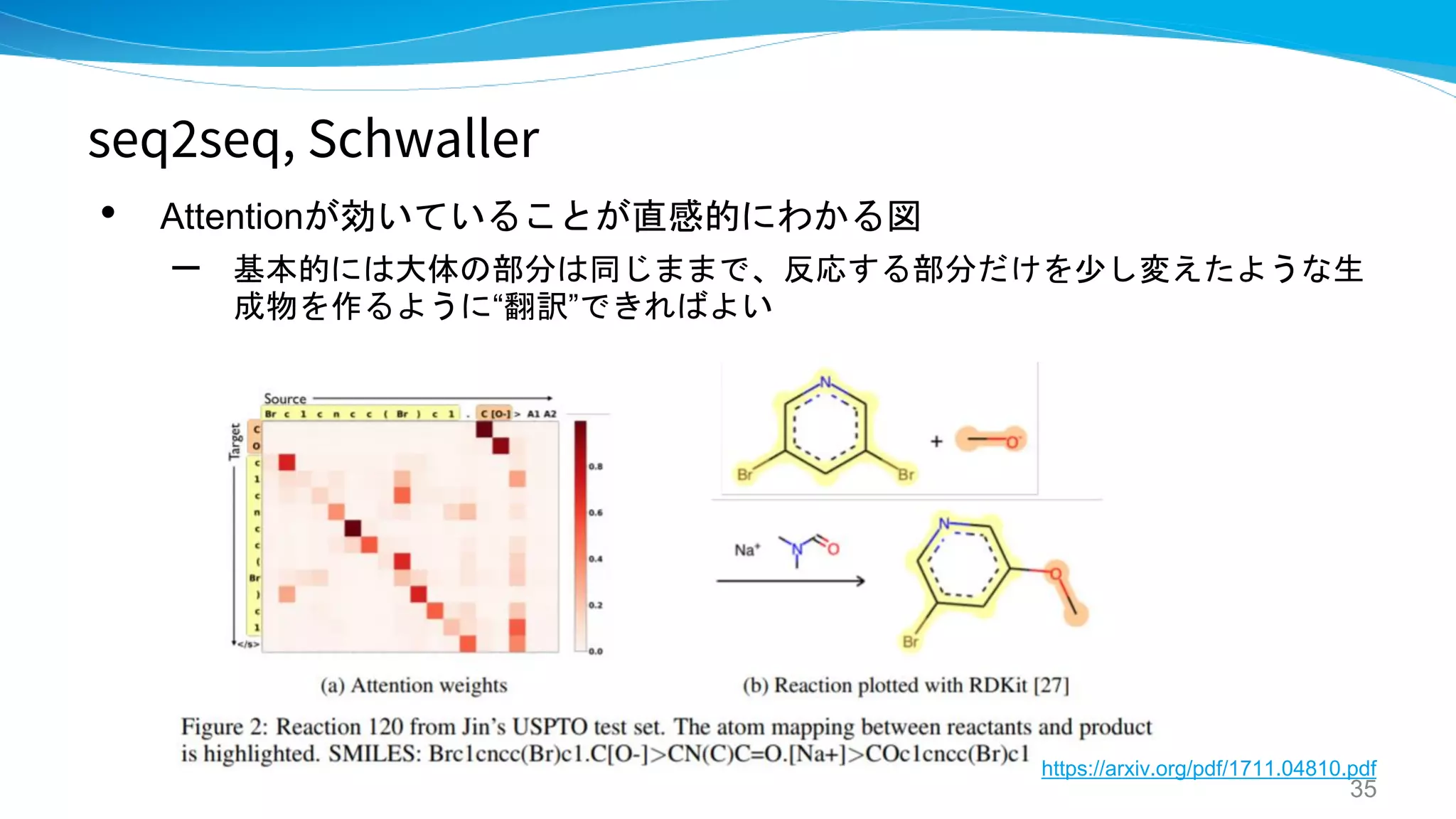
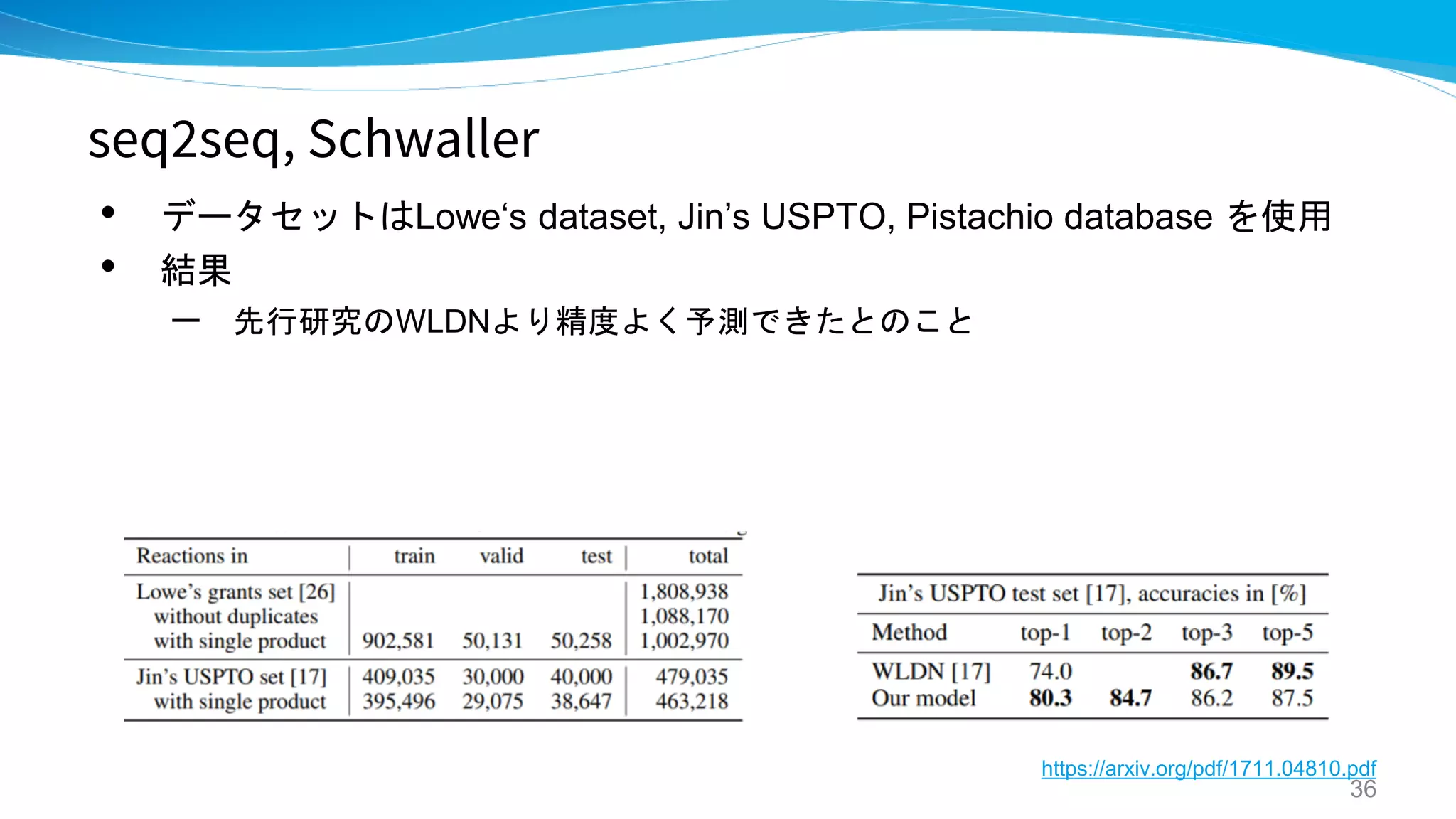
seq2seq, Schwaller IBM
“Found in Translation": Predicting Outcomes
of Complex Organic Chemistry Reactions
using Neural Sequence-to-Sequence Models
2017
2016
2019
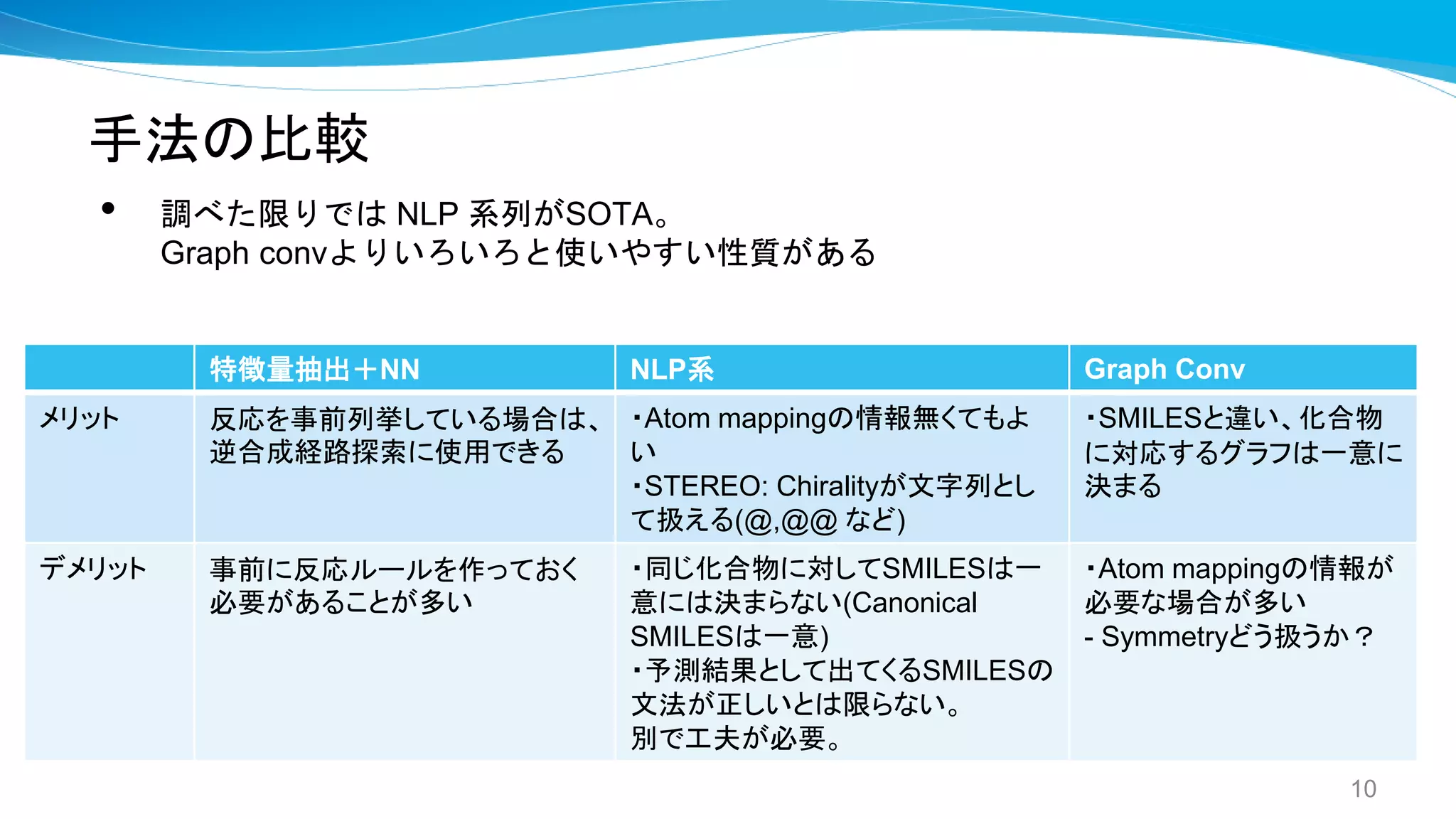
NLP系
8
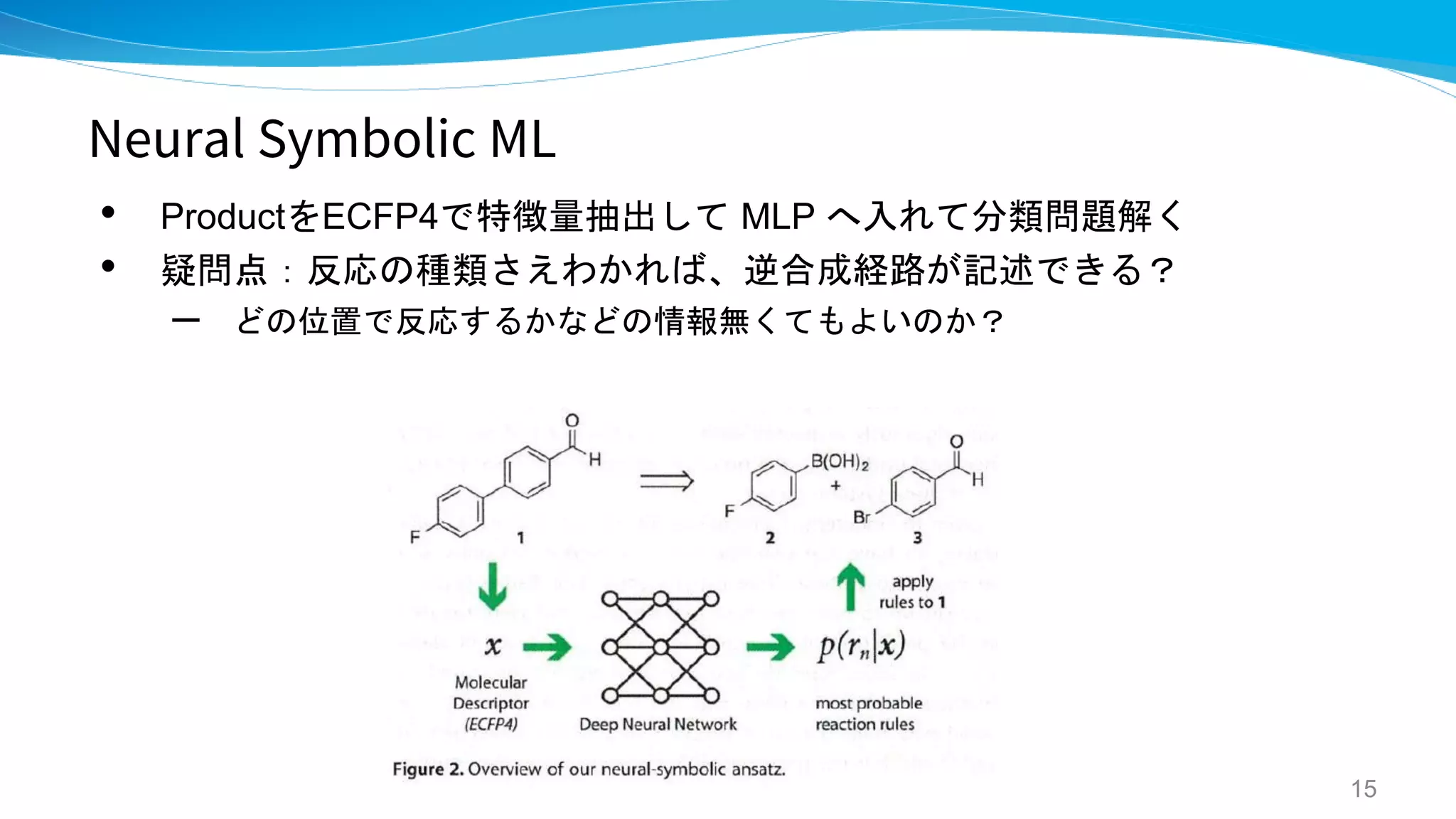
Neural Symbolic ML
- Neural‐Symbolic Machine Learning for
Retrosynthesis and Reaction Prediction
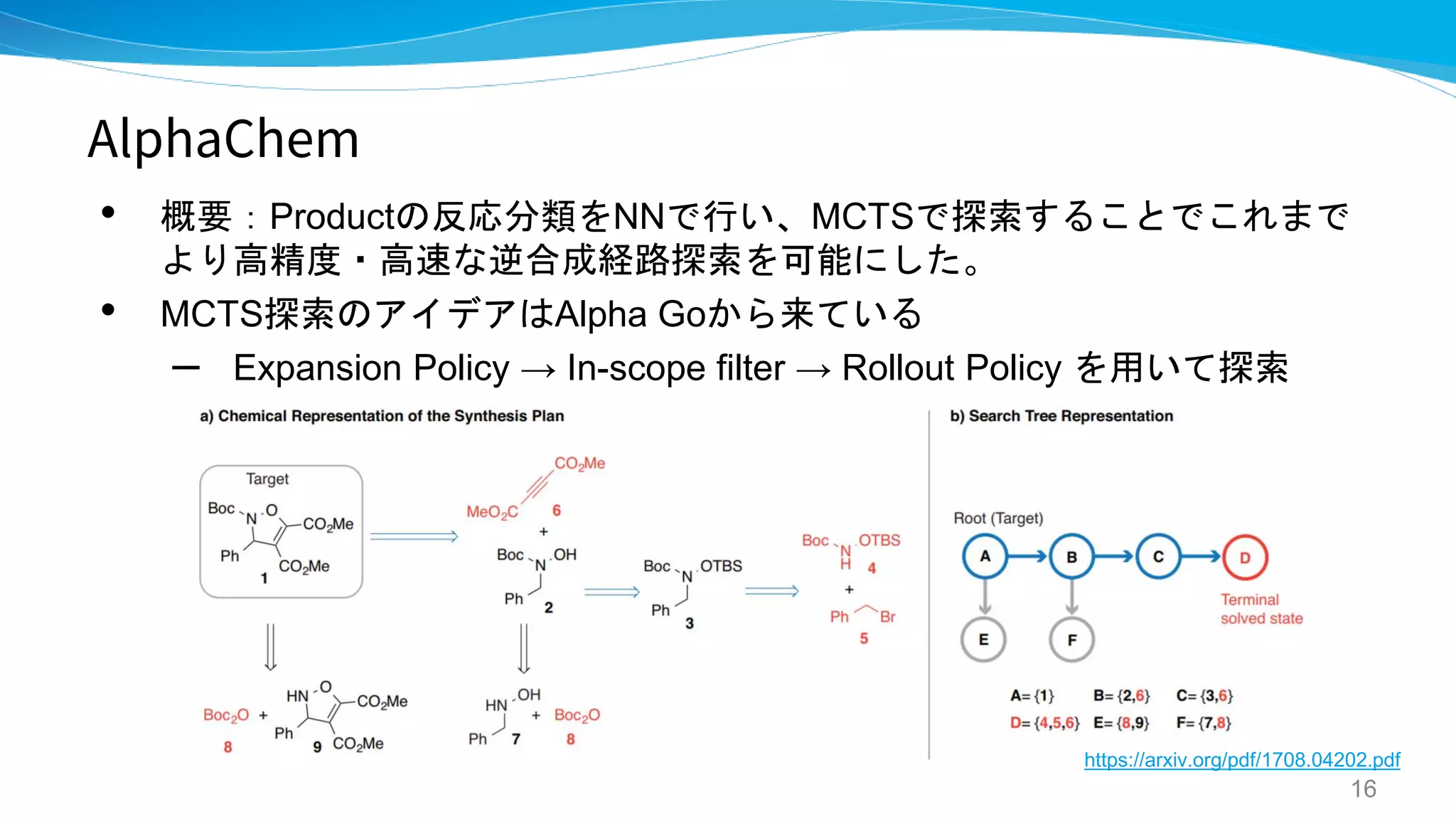
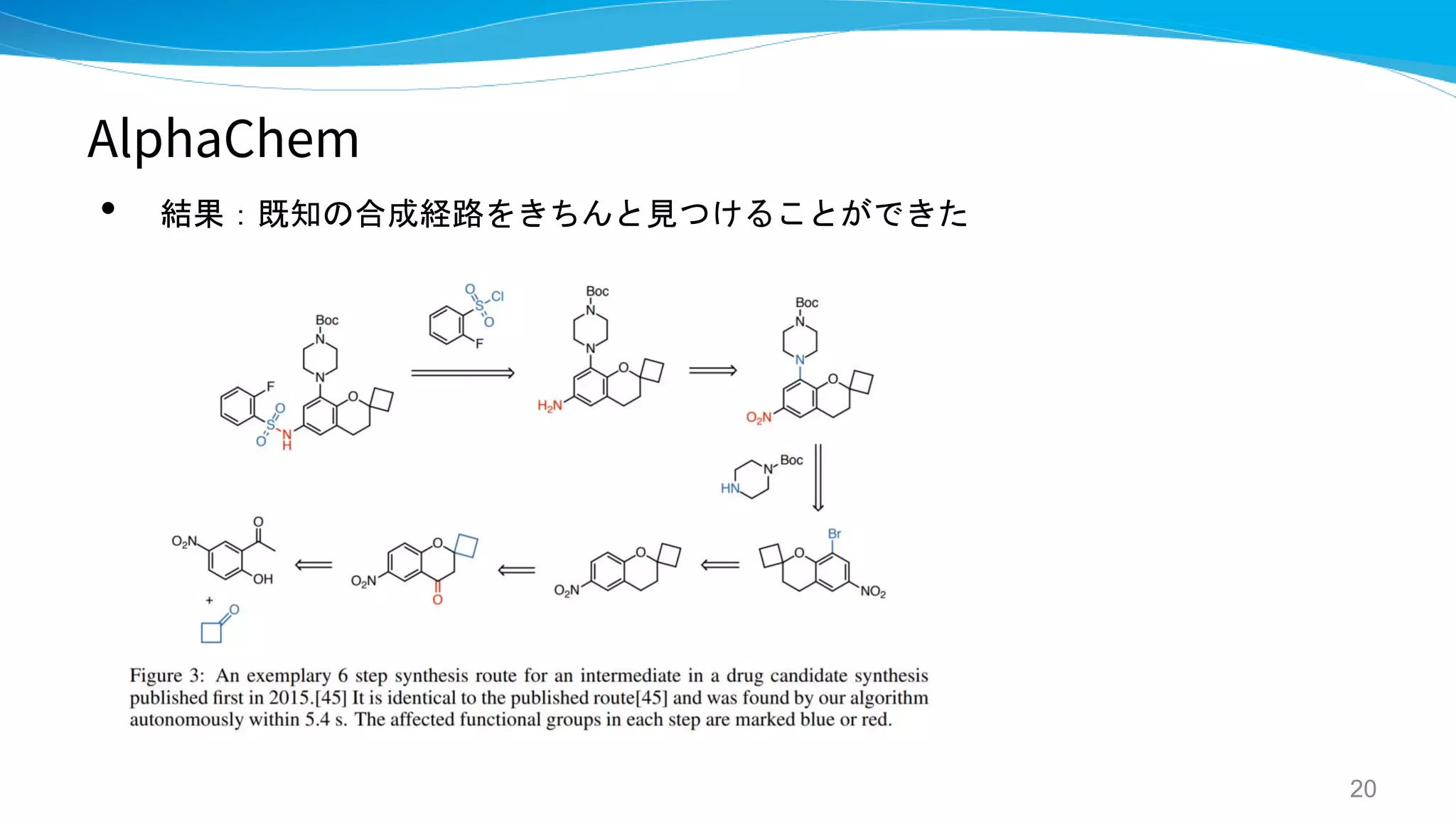
AlphaChem
- Towards "AlphaChem": Chemical Synthesis Planning
with Tree Search and Deep Neural Network Policies
- AlphaChem: Planning chemical syntheses with deep
neural networks and symbolic AI
- Learning to Plan Chemical Syntheses
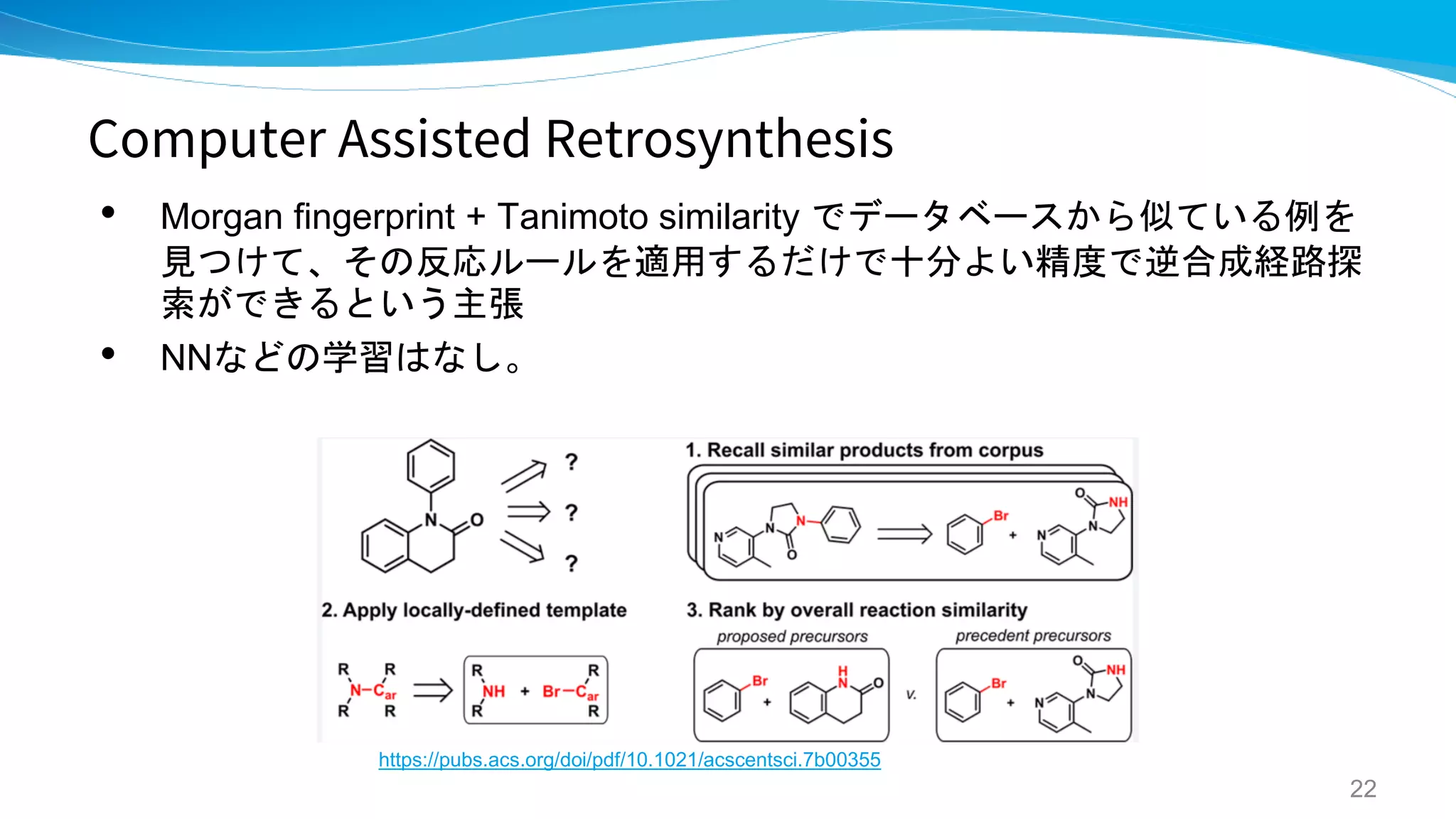
Computer Assisted Retrosynthesis
Computer-Assisted Retrosynthesis Based on
Molecular Similarity
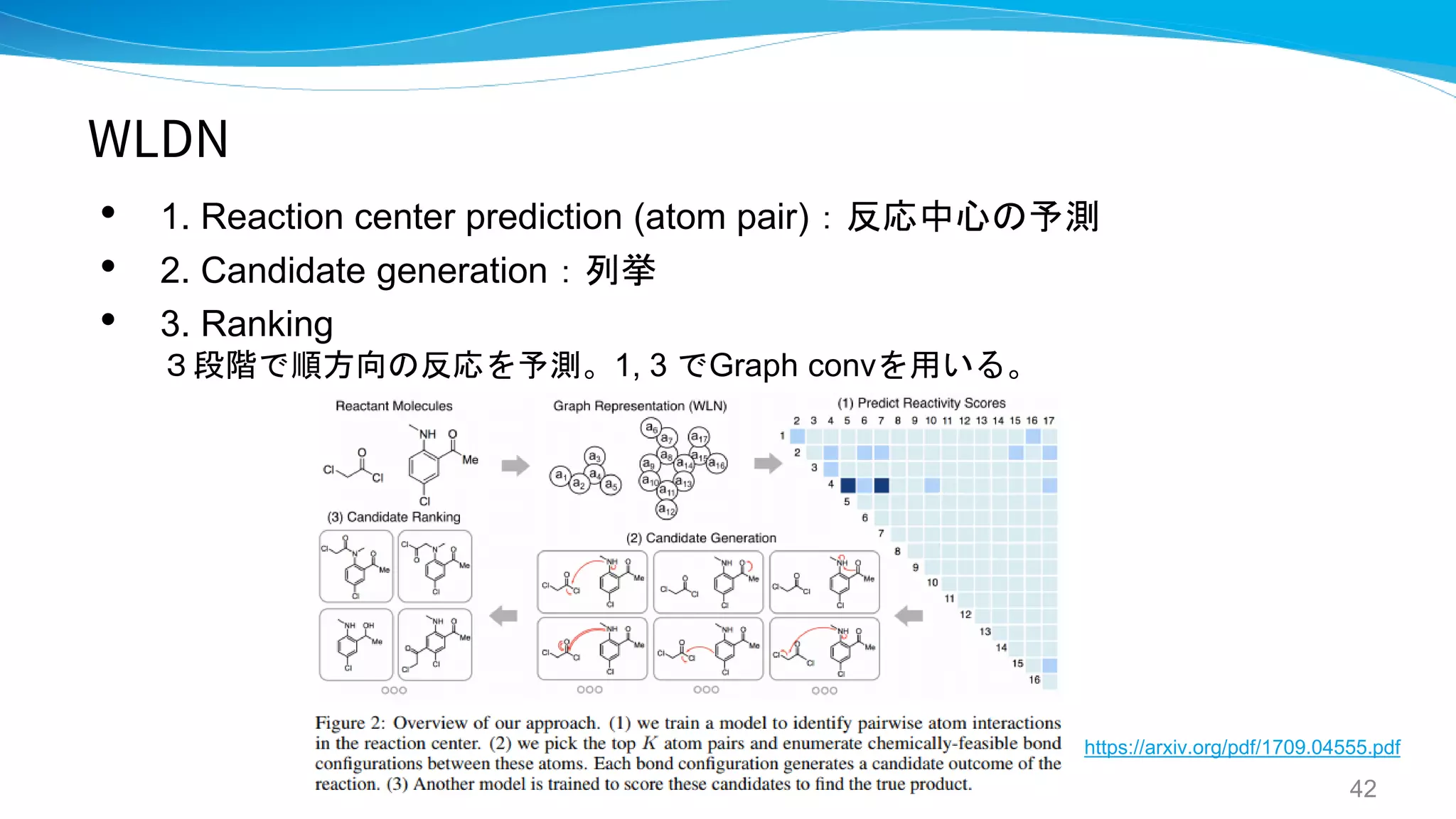
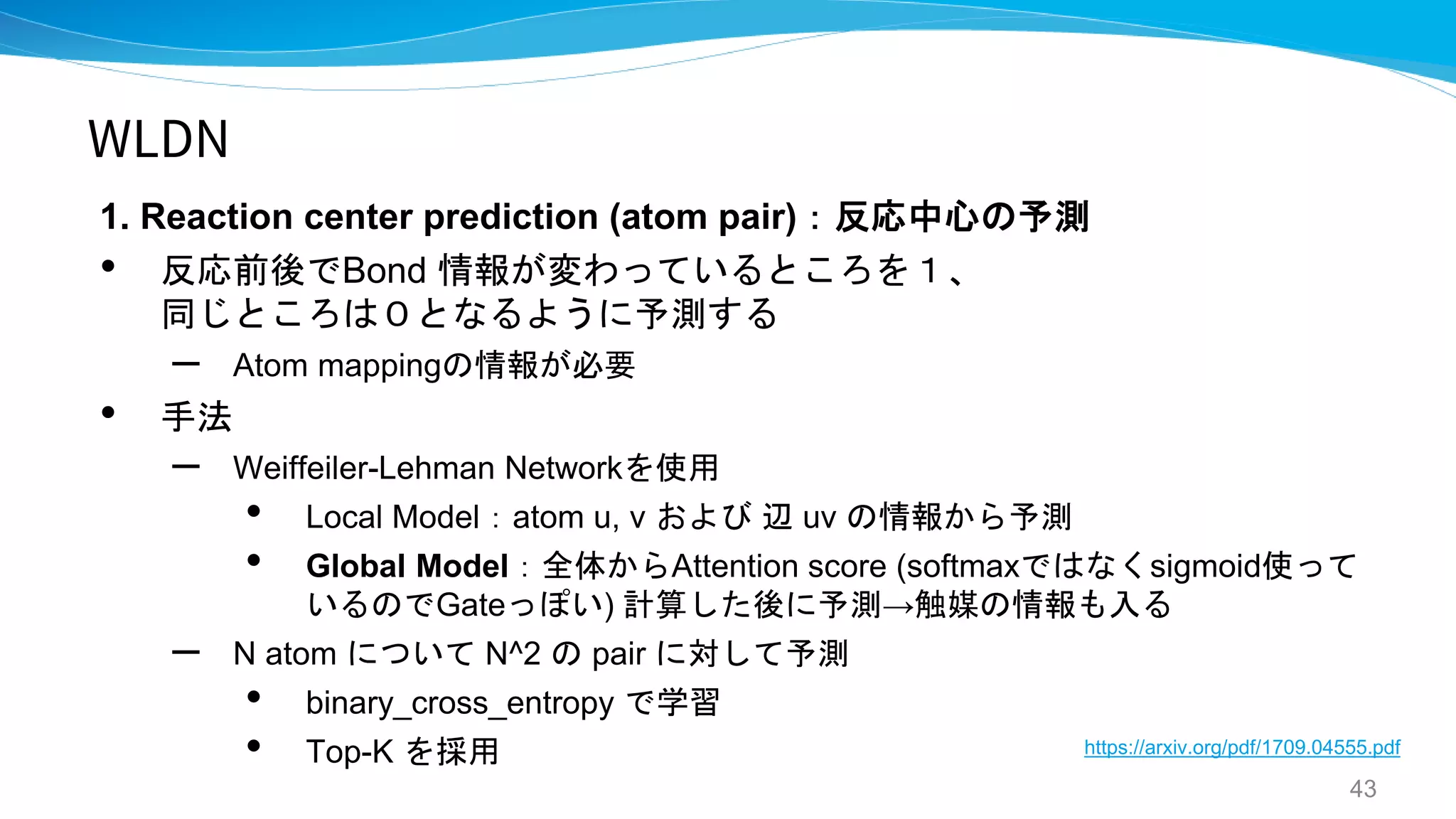
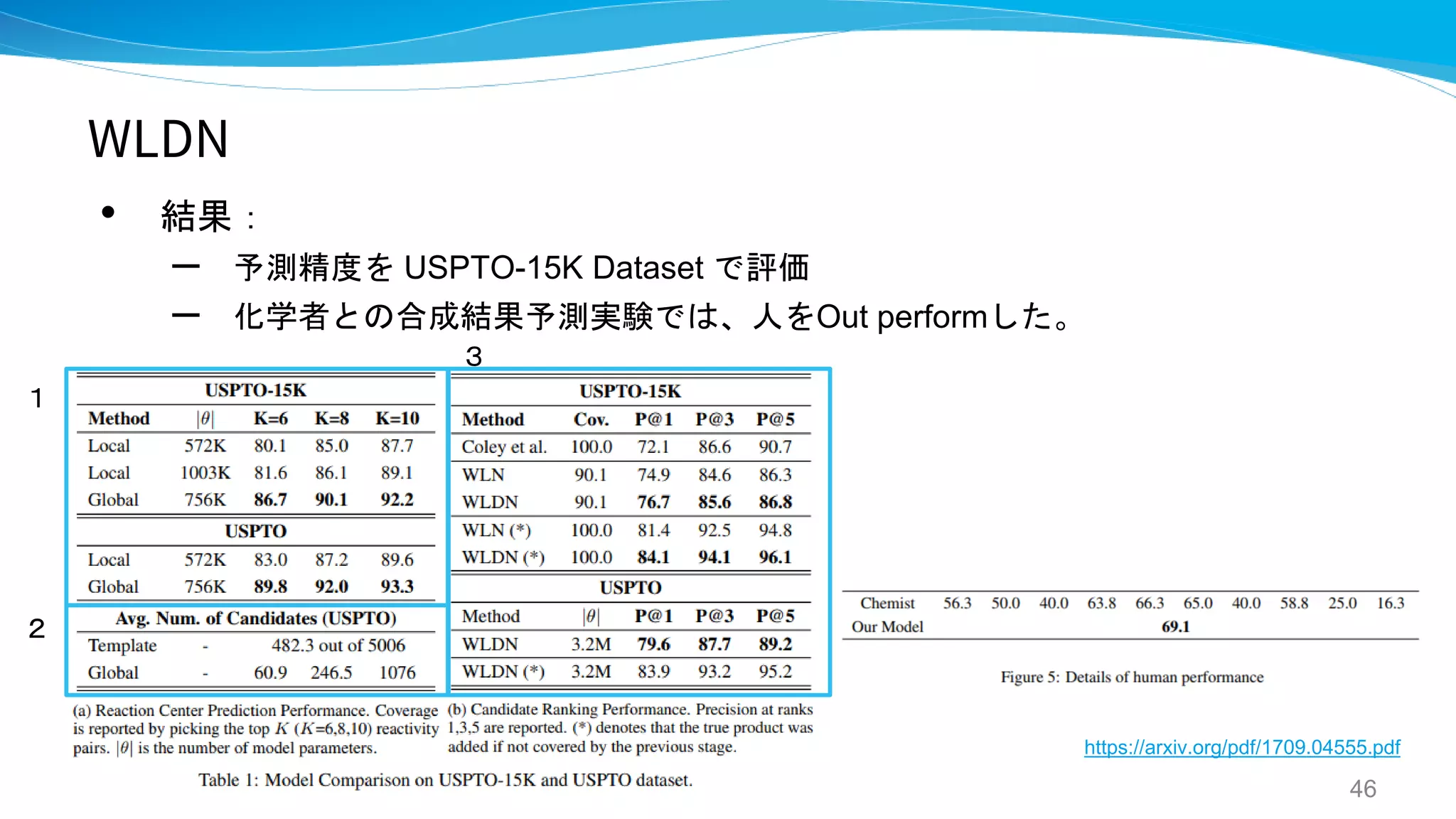
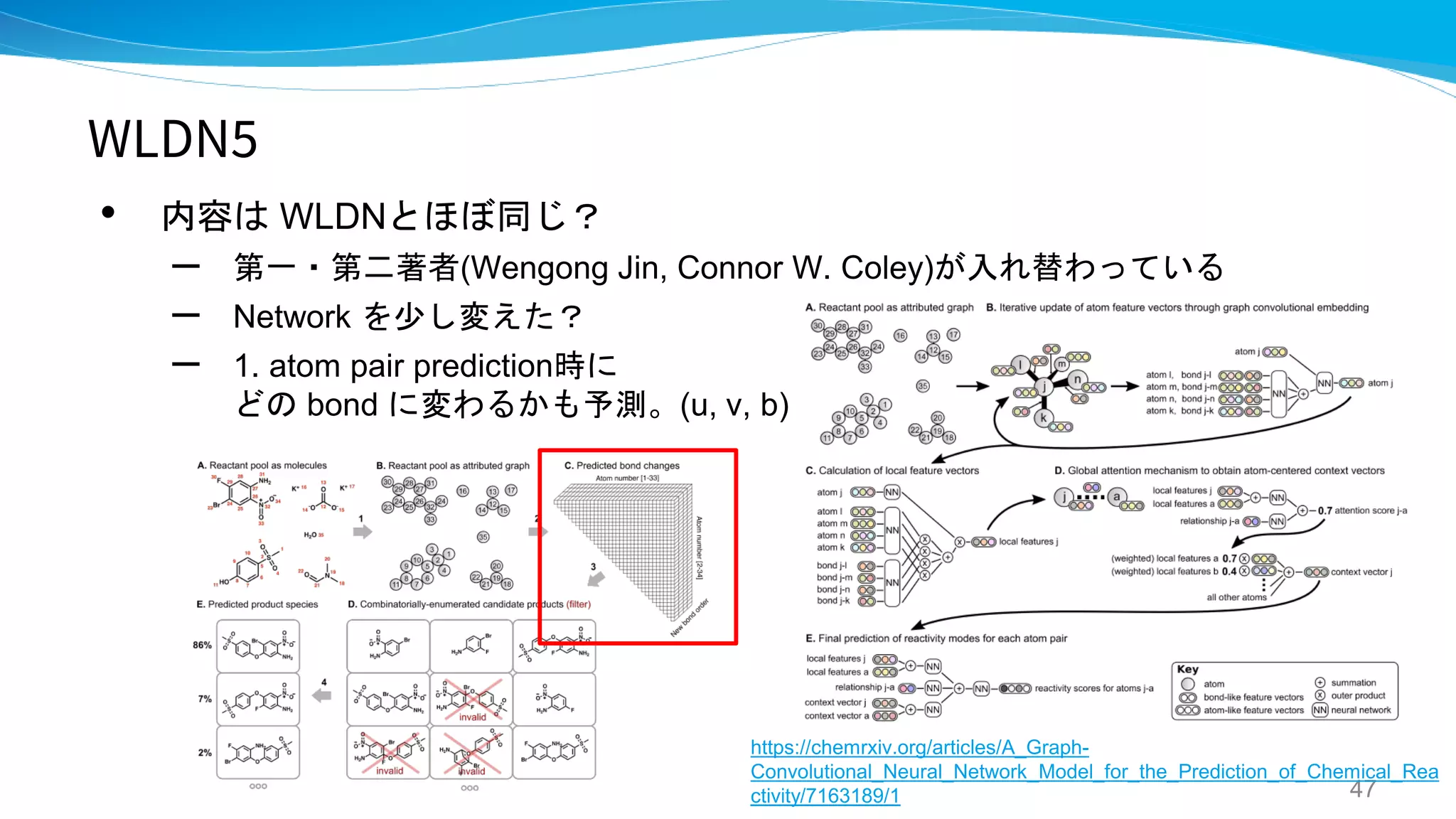
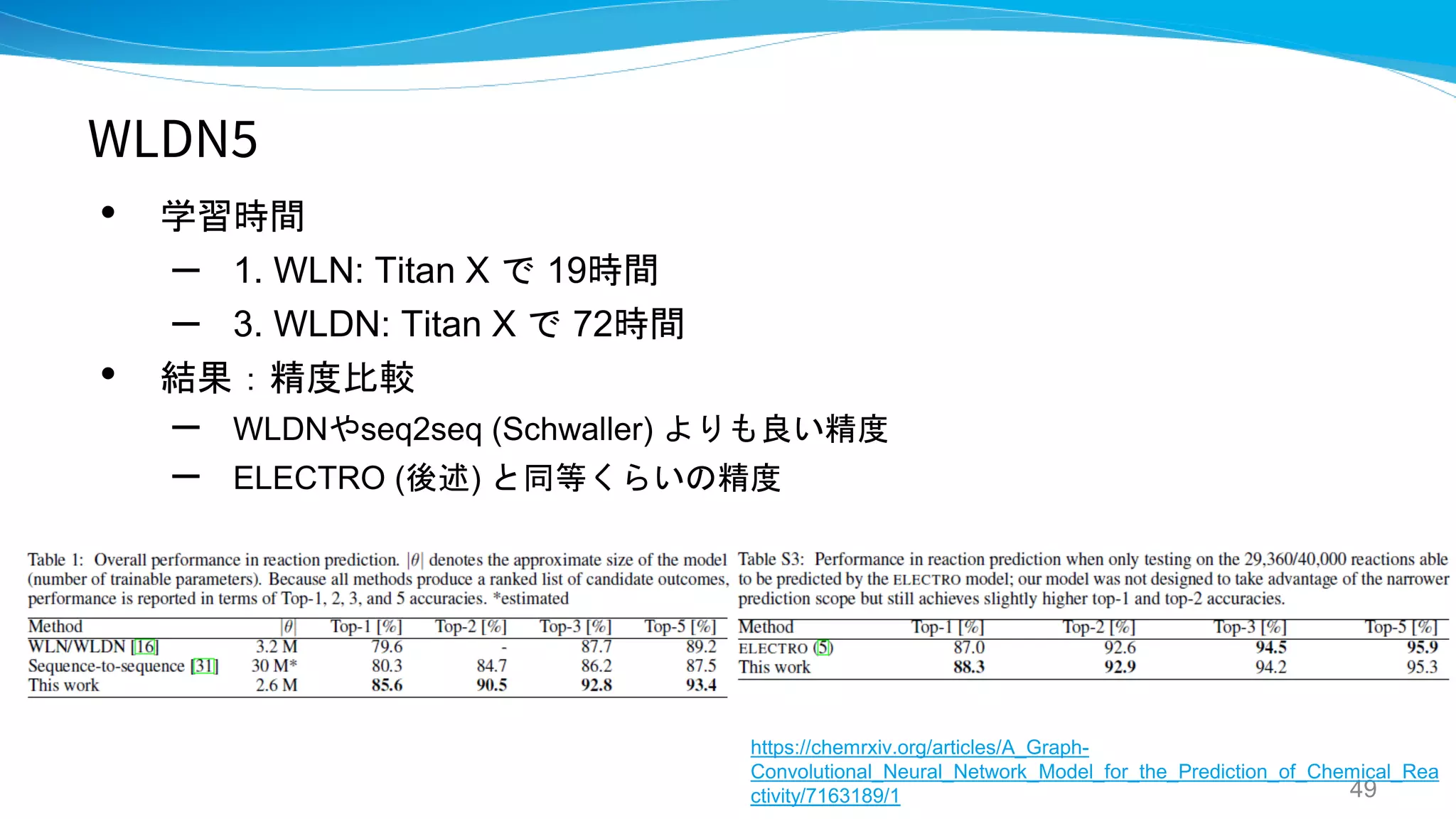
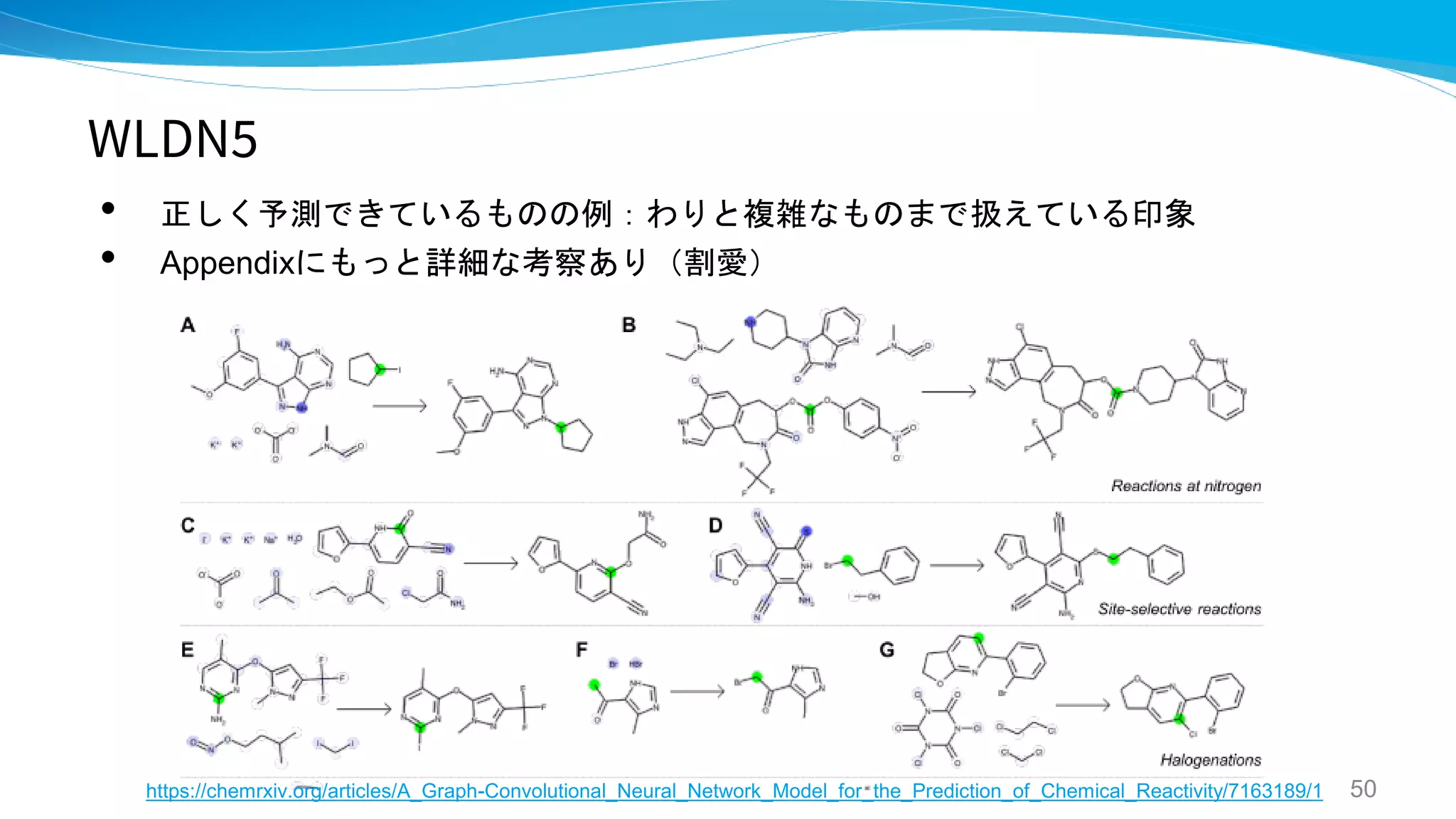
WLDN / WLDN5
- Predicting Organic Reaction Outcomes with
Weisfeiler-Lehman Network
- A graph-convolutional neural network model for
the prediction of chemical reactivity
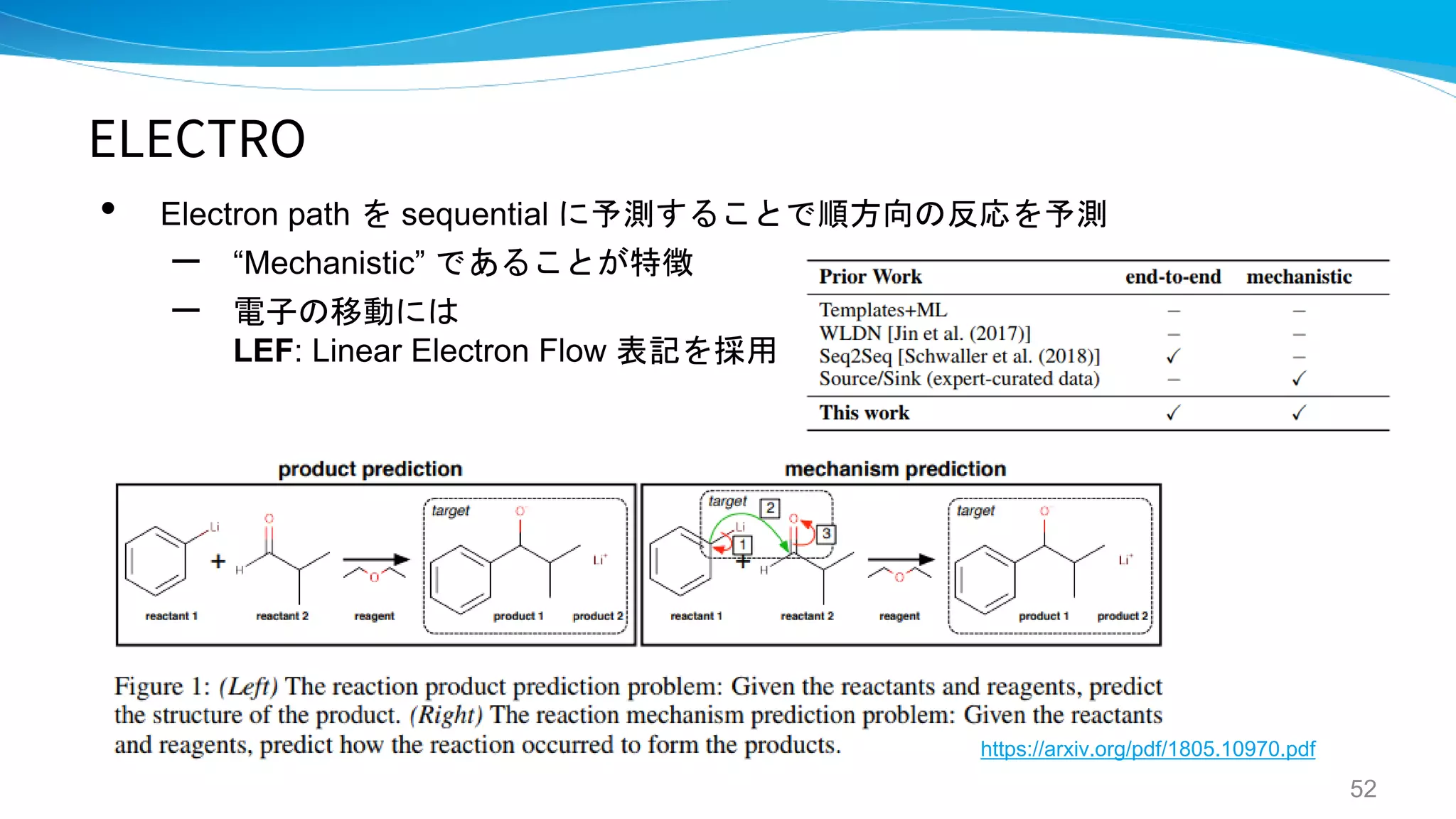
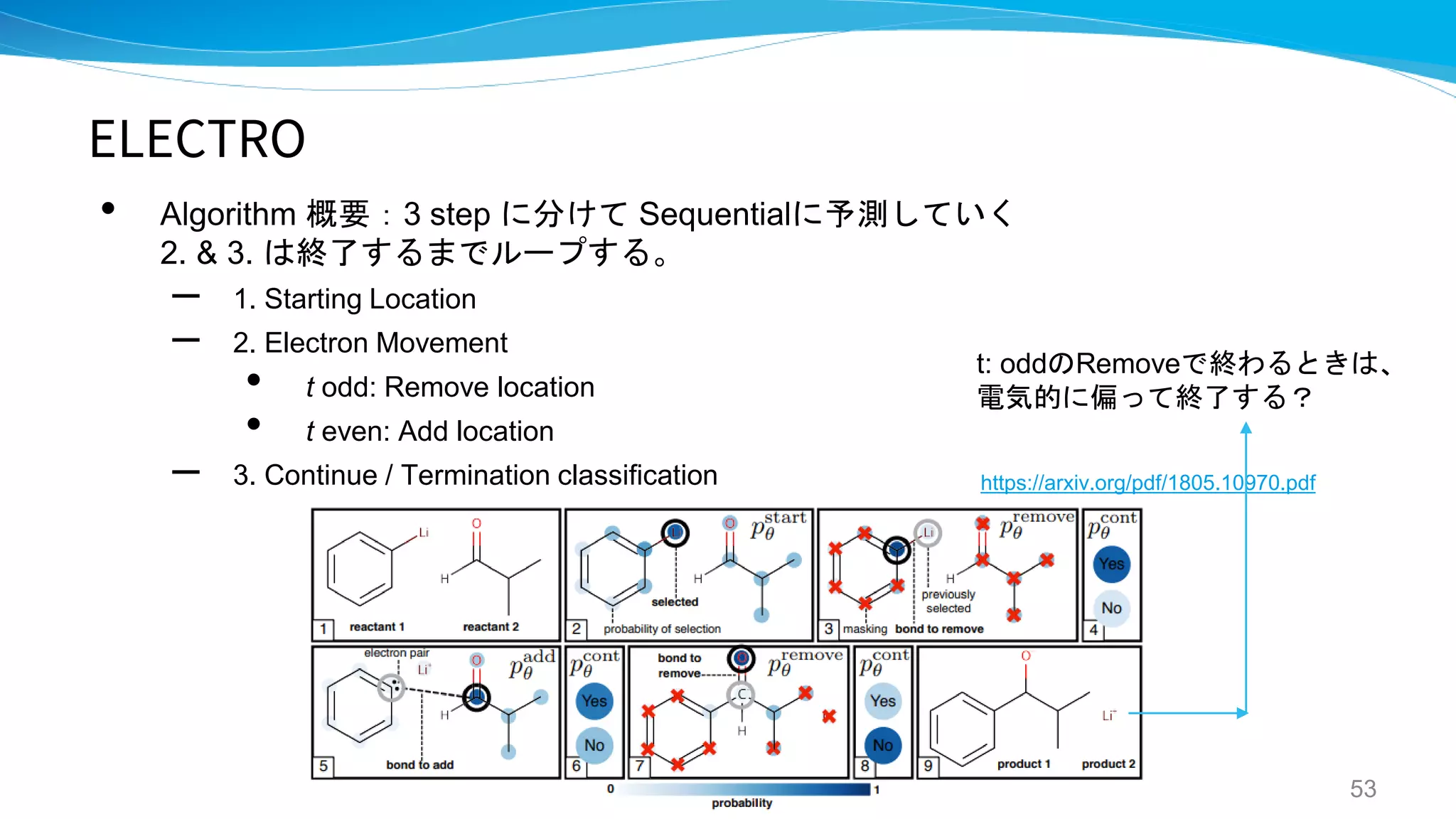
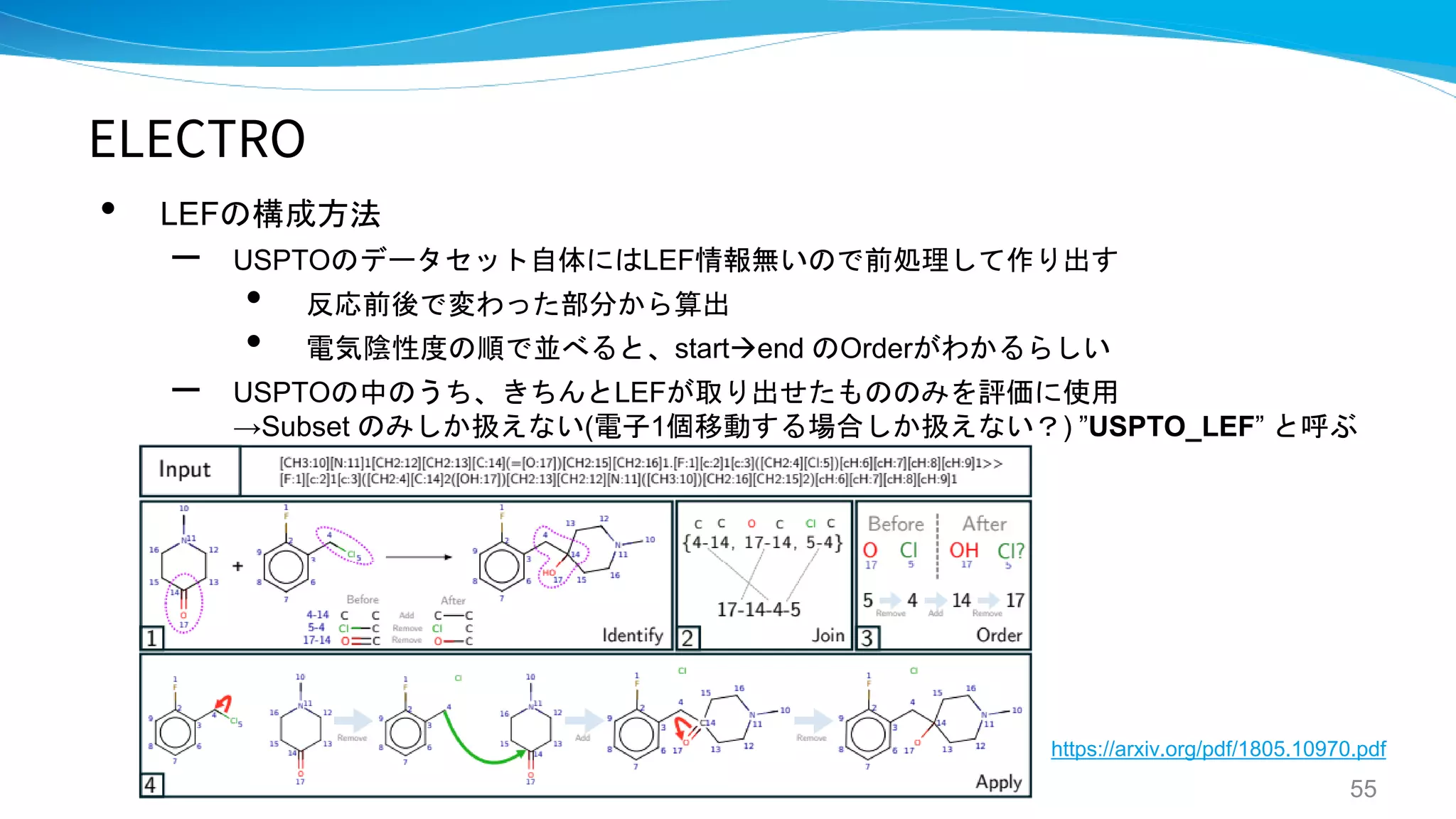
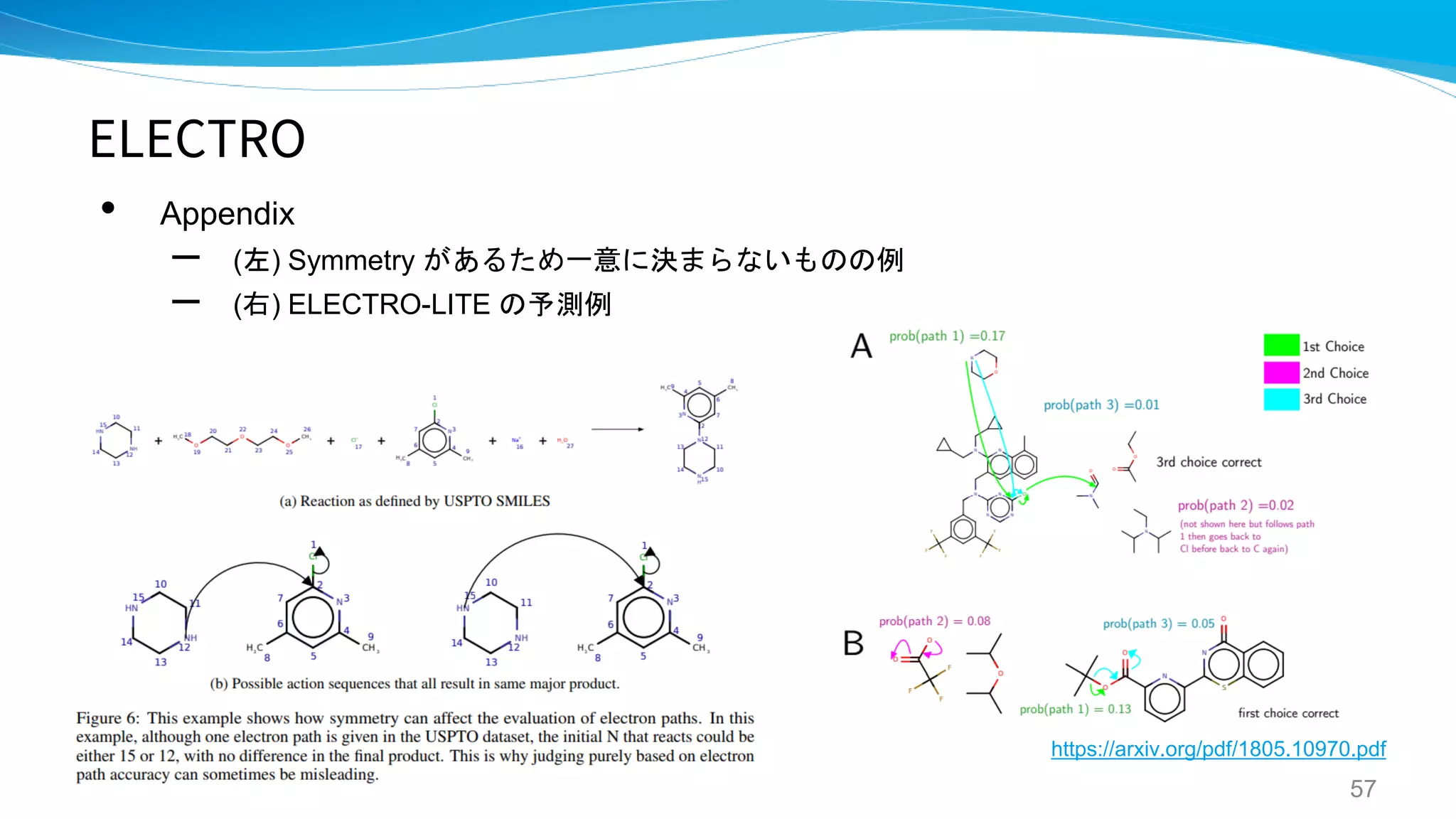
ELECTRO
A GENERATIVE MODEL FOR ELECTRON
PATHS
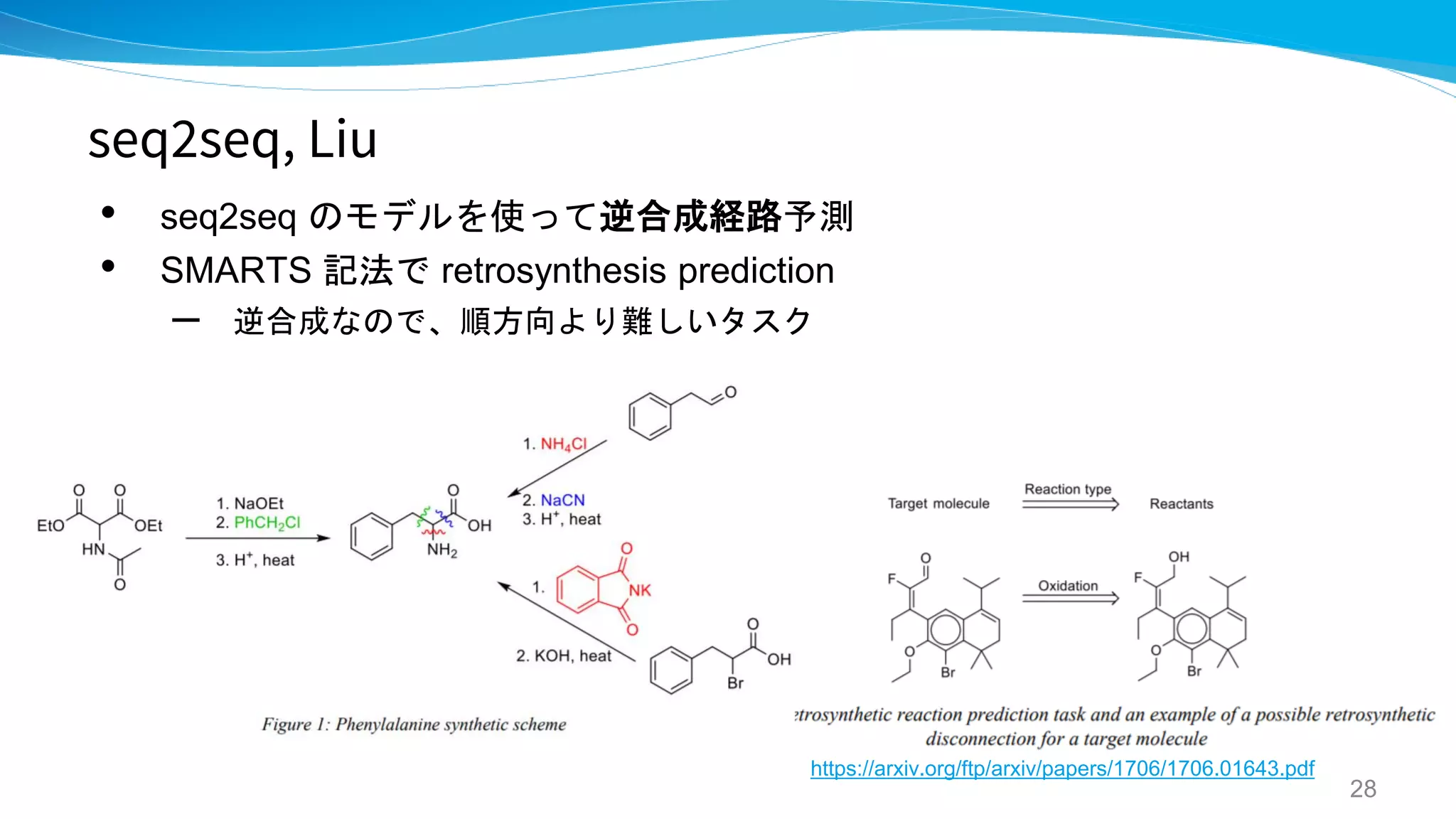
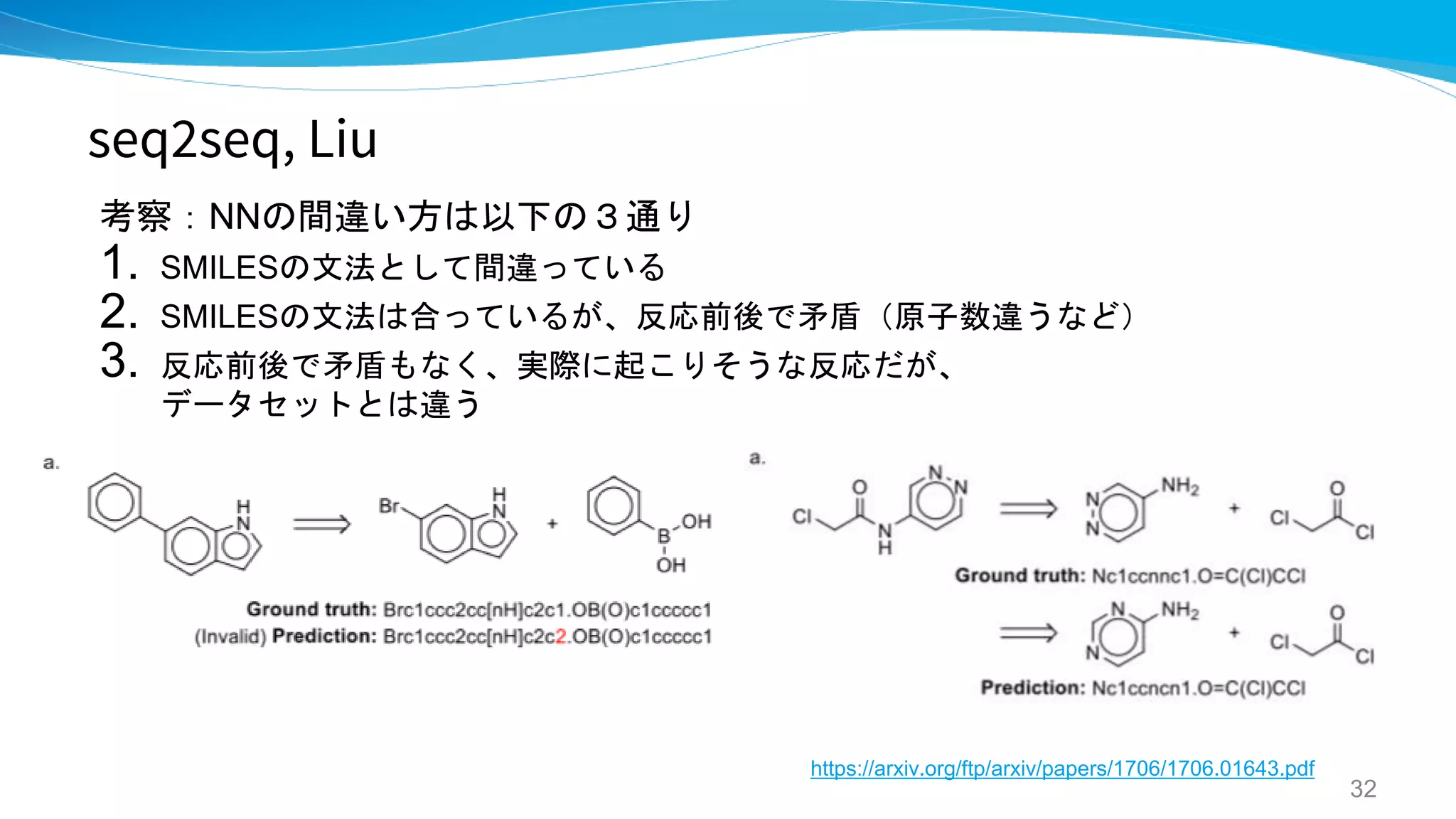
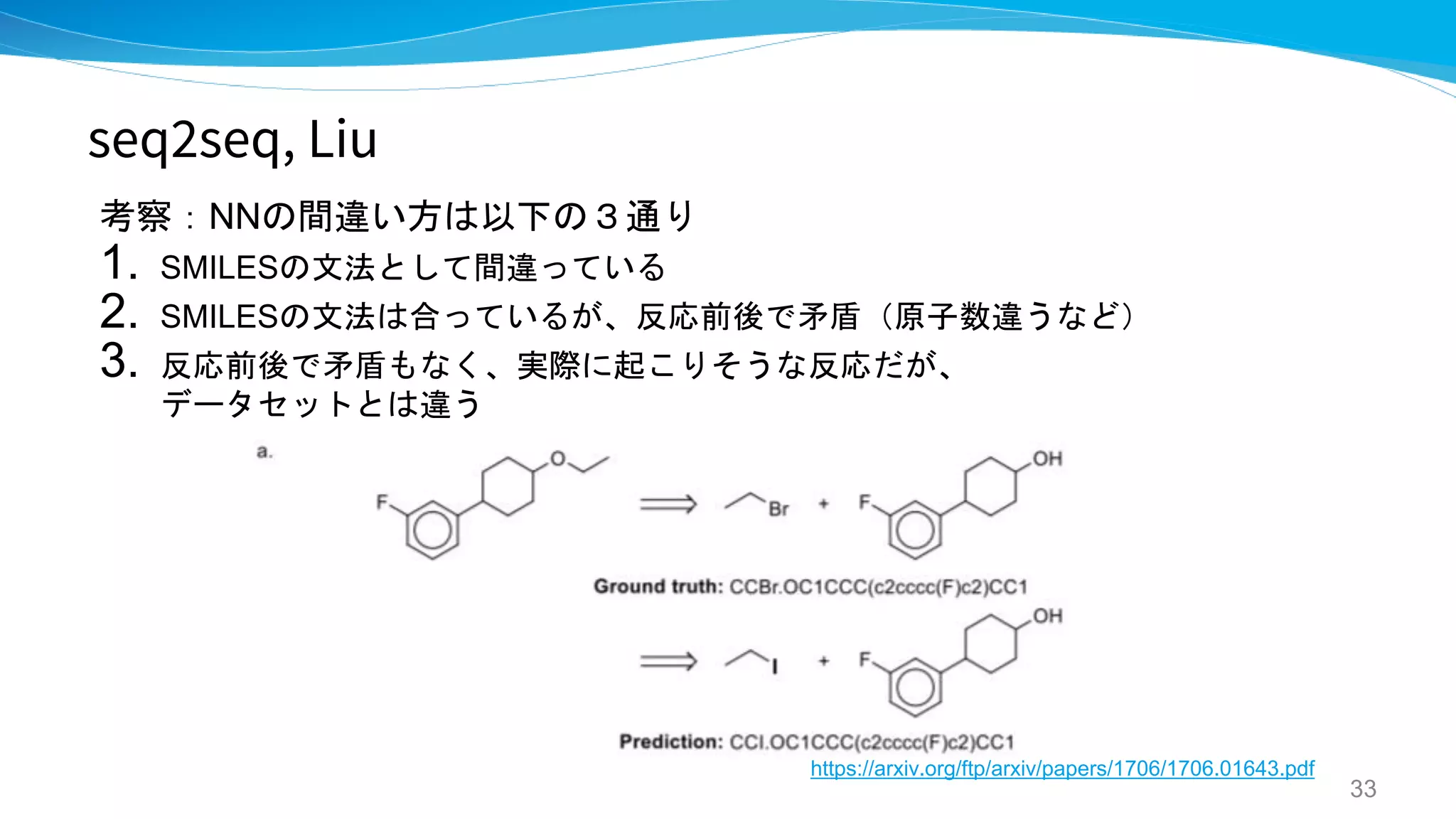
seq2seq, Liu Stanford
Retrosynthetic reaction prediction using
neural sequence-to-sequence models
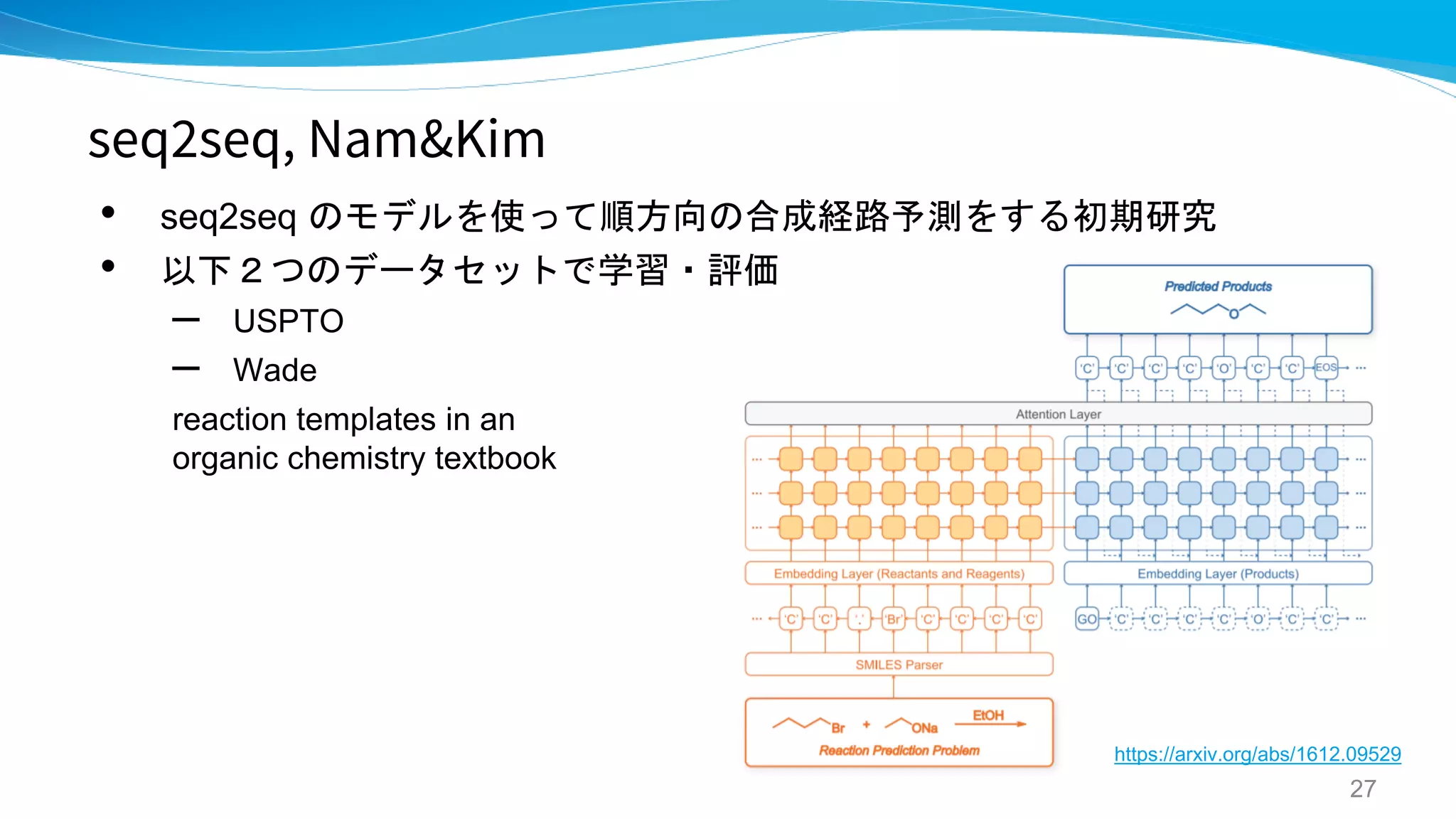
seq2seq, Nam&Kim
Linking the Neural Machine Translation and
the Prediction of Organic Chemistry Reactions
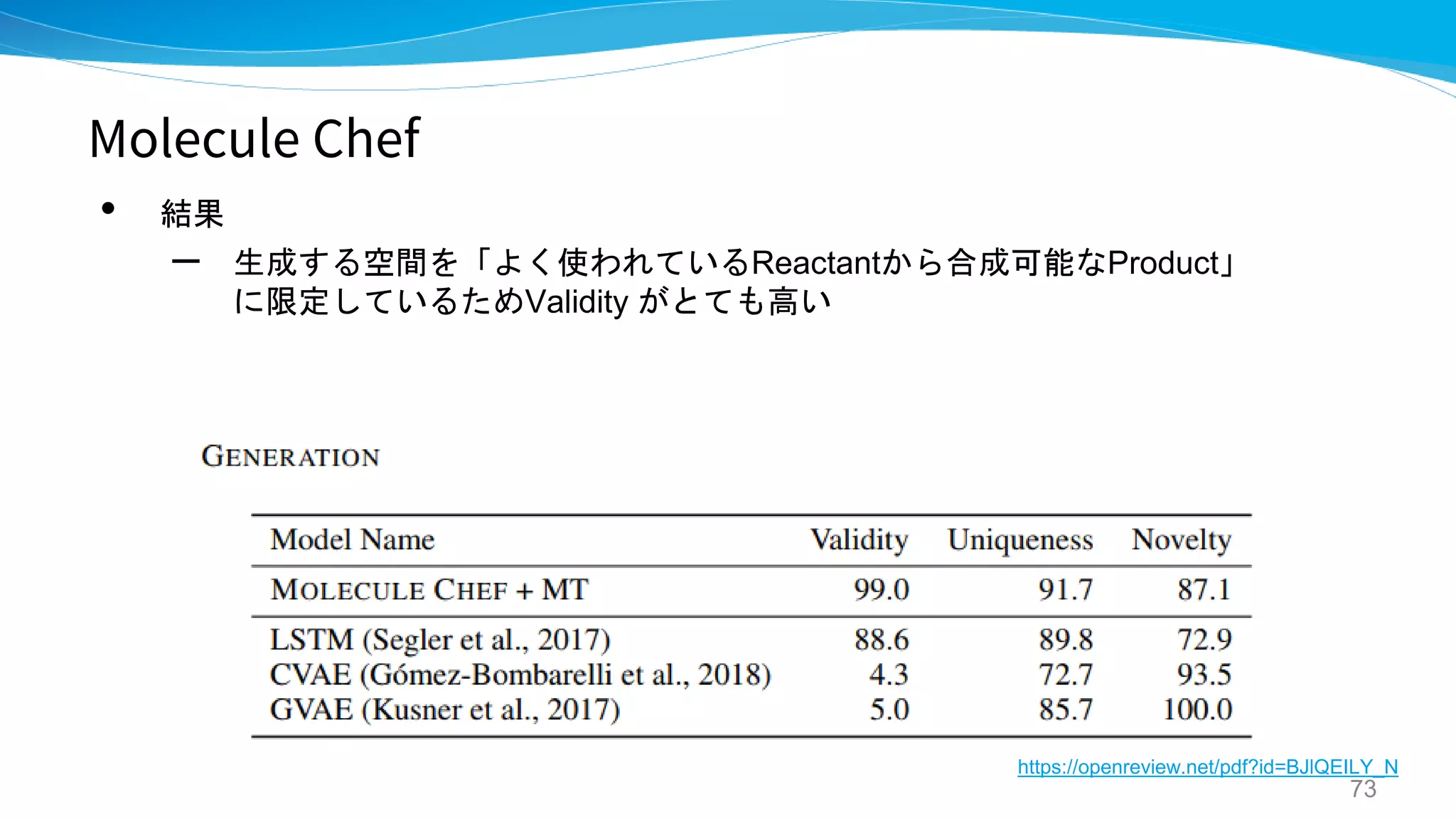
Molecule CHEF
Generating Molecules via Chemical Reactions
Graph conv特徴量抽出+NN
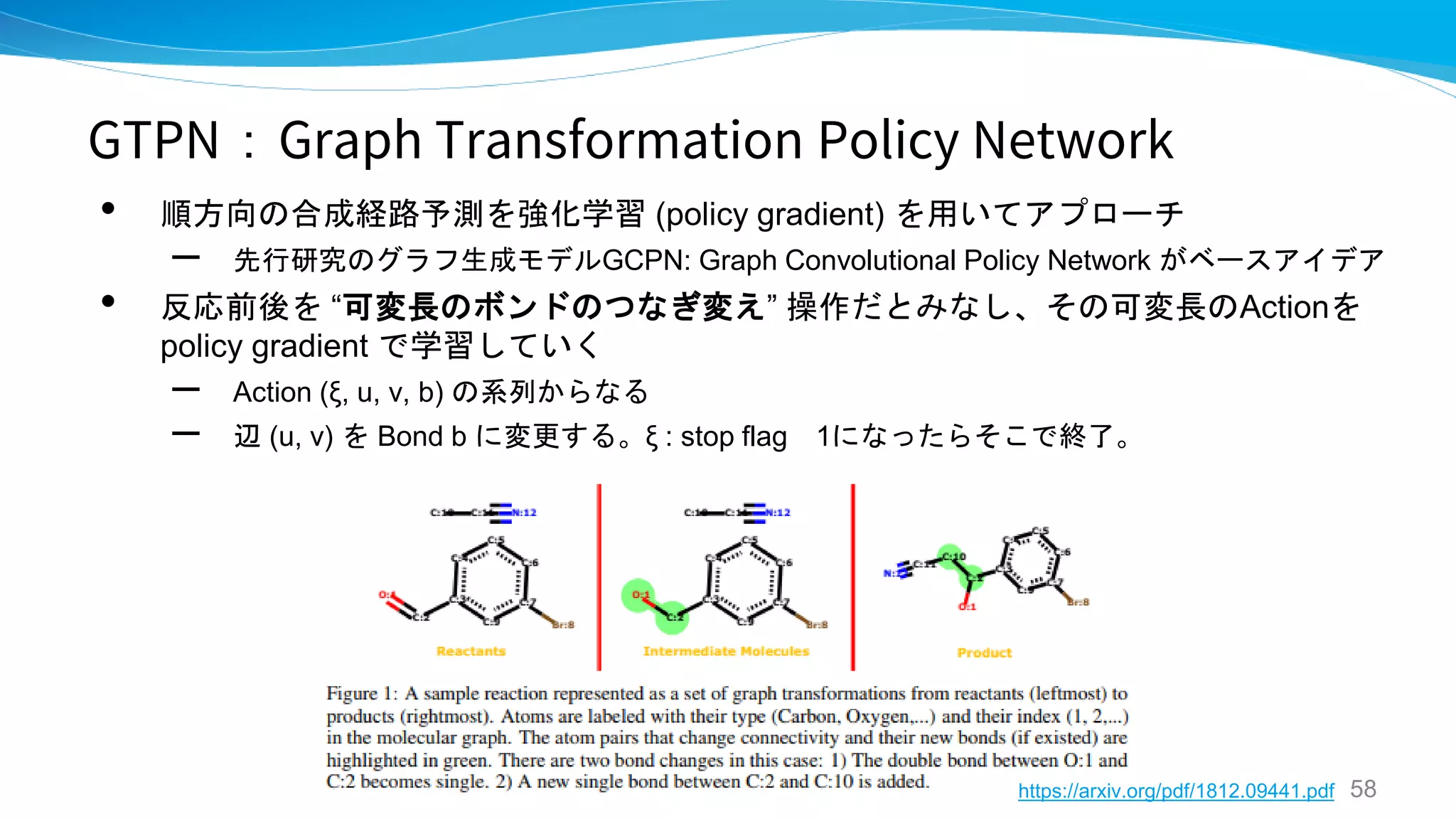
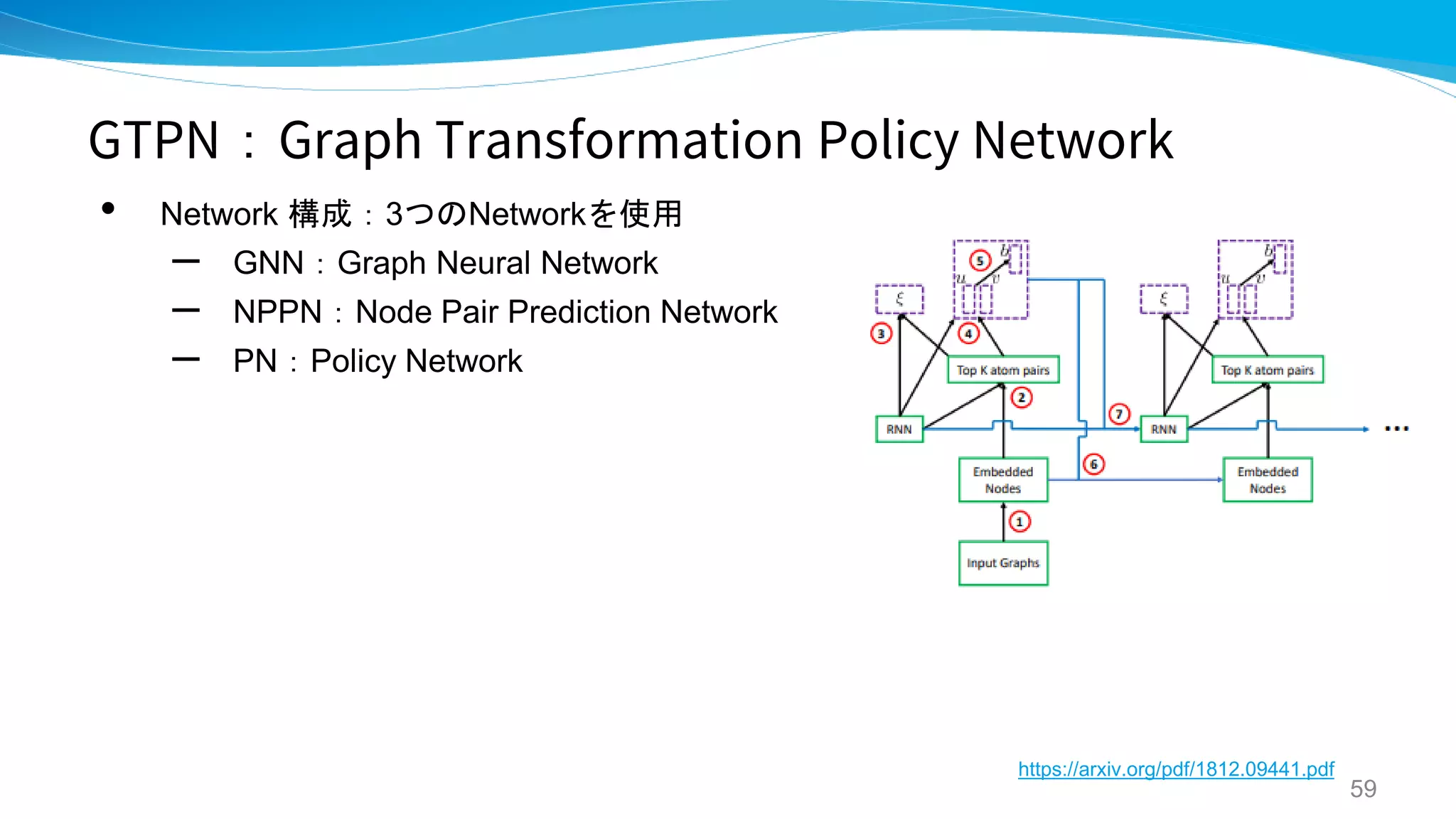
GTPN
GRAPH TRANSFORMATION POLICY
NETWORK FOR CHEMICAL REACTION
PREDICTION
2018



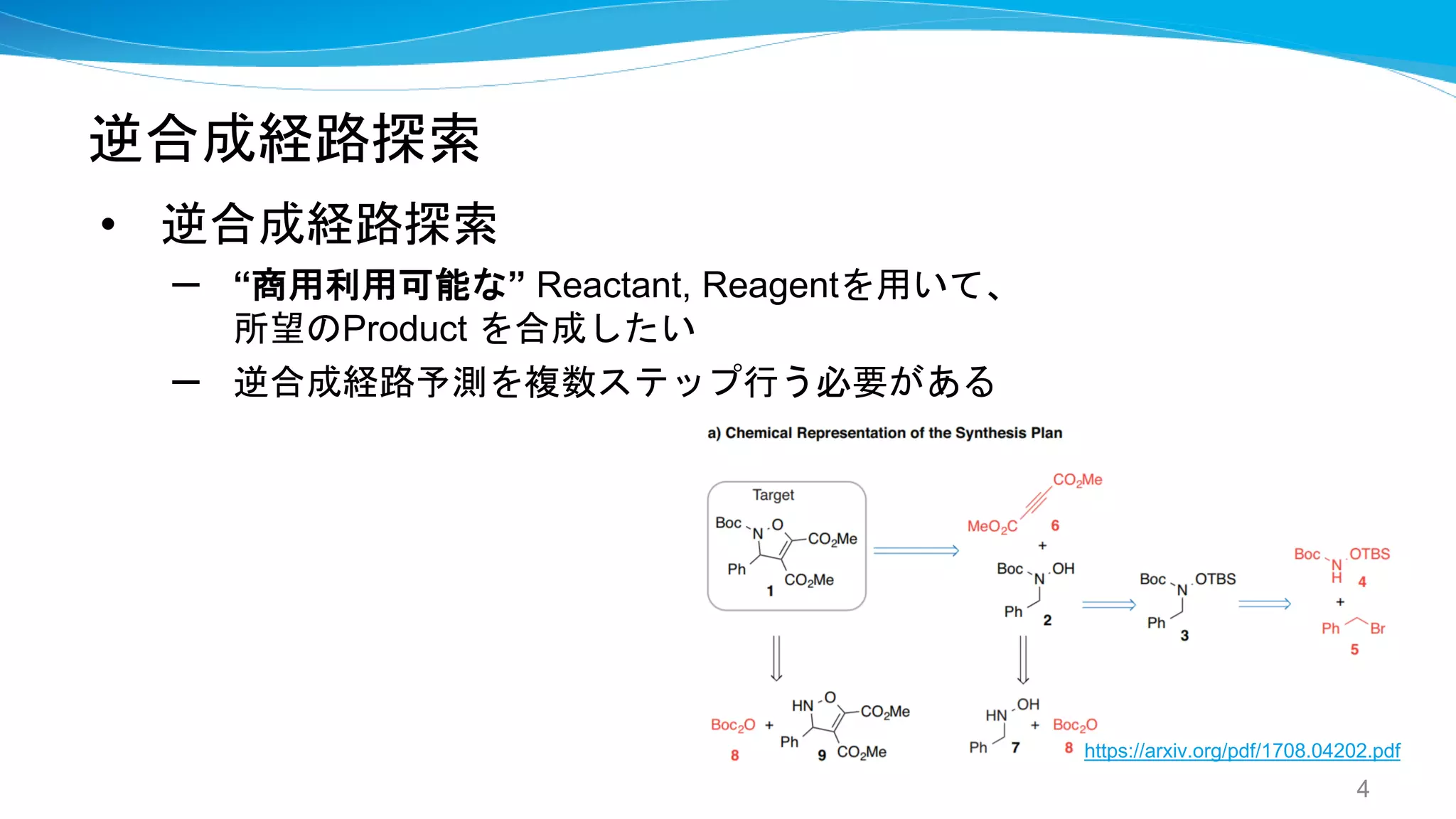












![Computer Assisted Retrosynthesis
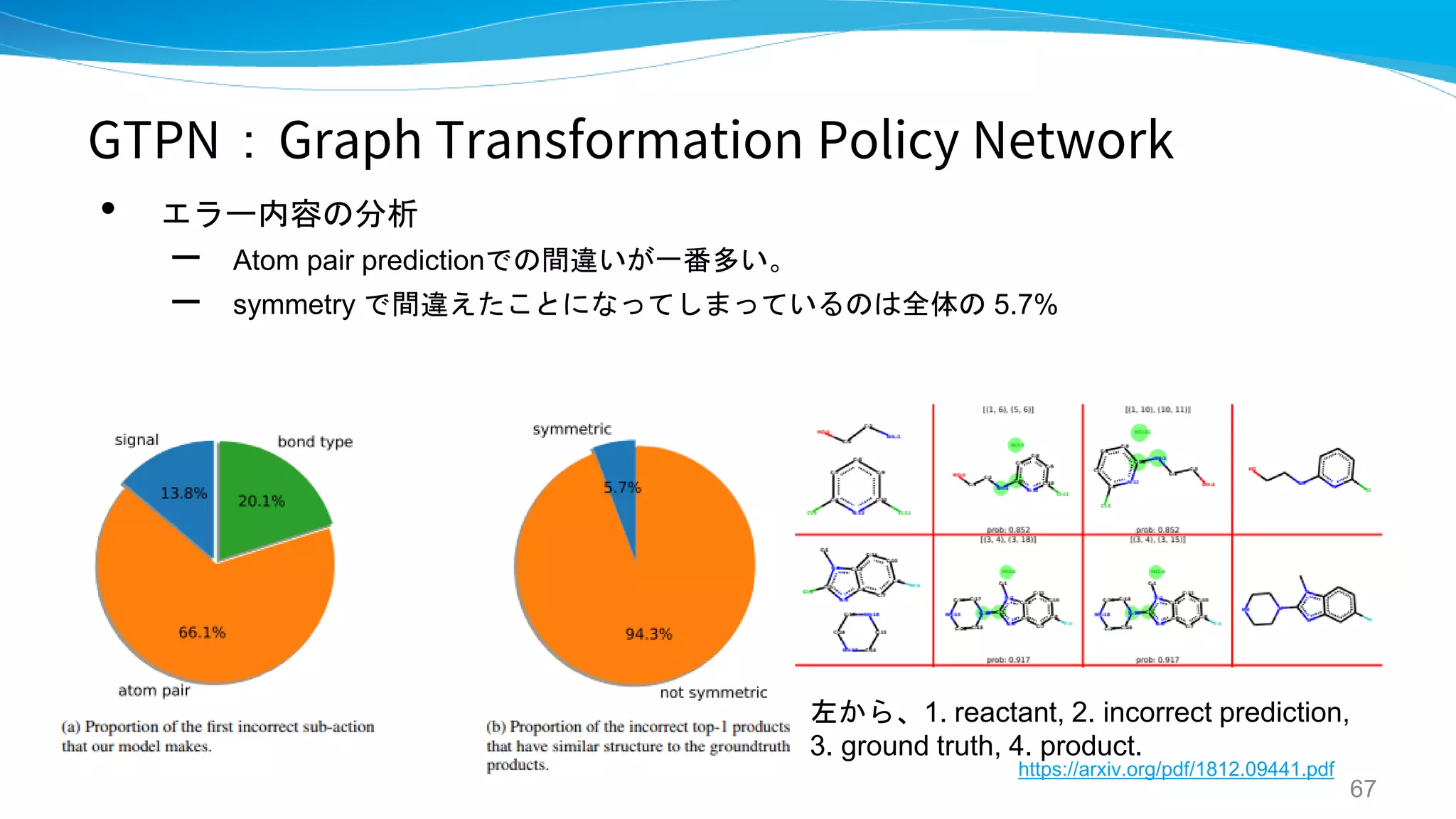
• 結果:先行研究の seq2seq [Liu] よりは精度良い
• 既知のProductの逆合成経路探索もできた。
25
https://pubs.acs.org/doi/pdf/10.1021/acscentsci.7b00355](https://image.slidesharecdn.com/synthesispubv2kosukenakago-190829035456/75/PFN-25-2048.jpg)















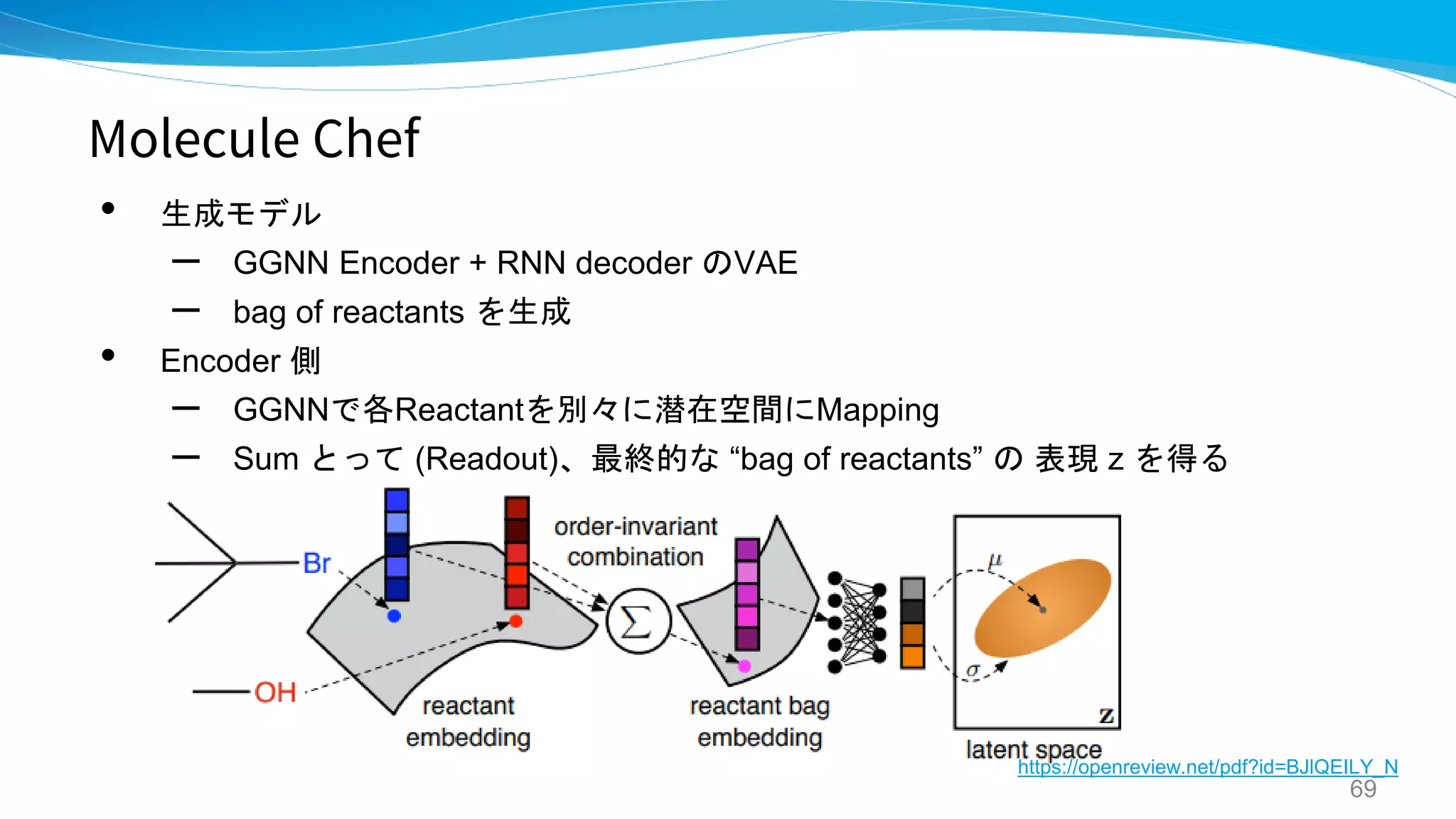
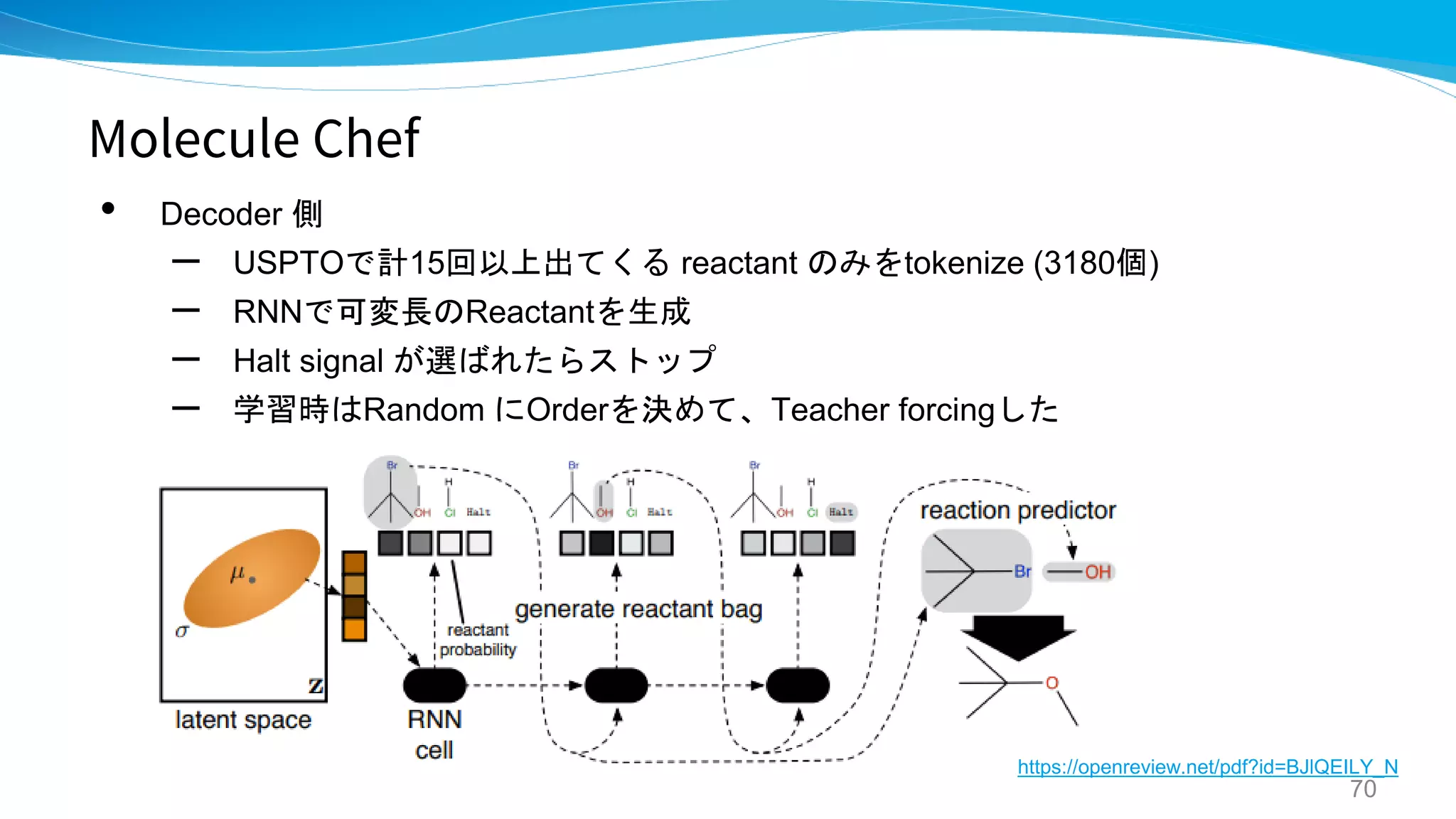
![Molecule Chef
• “合成可能な分子” のみを生成するグラフ生成モデルを提案
[発想の転換]
• これまでのようにproduct を直接出すのではなく、 bag of reactants を生成する
• 先行研究で出てきた順方向のreaction prediction model を使用することで割と精度
よく予測できることを利用 → 現状SOTAの Molecular Transformer を使用。
68
https://openreview.net/pdf?id=BJlQEILY_N
可変長のReactants のセット](https://image.slidesharecdn.com/synthesispubv2kosukenakago-190829035456/75/PFN-62-2048.jpg)


















![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network](https://cdn.slidesharecdn.com/ss_thumbnails/maml-181024060235-thumbnail.jpg?width=640&height=640&fit=bounds)

































