Download as PDF, PPTX

![> me
$name
[1] "Takashi Kitano"
$twitter
[1] "@kashitan"
$work_in
[1] " "](https://image.slidesharecdn.com/20180901tokyor72-180901132705/75/tidytext-RMeCab-2-2048.jpg)














![> mecab_result <- talks_ja %>%
+ RMeCabDF("transcript_ja", 1)
> glimpse(mecab_result)
List of 1
$ : Named chr [1:1445] " " " " " " " " ...
..- attr(*, "names")= chr [1:1445] " " " " " " " " ...](https://image.slidesharecdn.com/20180901tokyor72-180901132705/75/tidytext-RMeCab-18-2048.jpg)
![> mecab_result <- talks_ja %>%
+ as.data.frame() %>%
+ RMeCabDF("transcript_ja", 1)
> glimpse(mecab_result)
List of 2551
$ : Named chr [1:1445] " " " " " " " " ...
..- attr(*, "names")= chr [1:1445] " " " " " " " " ...
$ : Named chr [1:2903] " " " " " " " " ...
..- attr(*, "names")= chr [1:2903] " " " " " " " " ...
$ : Named chr [1:2208] " " " " " " " " ...
..- attr(*, "names")= chr [1:2208] " " " " " " " " ...](https://image.slidesharecdn.com/20180901tokyor72-180901132705/75/tidytext-RMeCab-19-2048.jpg)
![> # tibble 1 tibble
> class(talks_ja[, "transcript_ja"])
[1] "tbl_df" "tbl" "data.frame"
> # 1
> length(talks_ja[, "transcript_ja"])
[1] 1
> # data.frame 1
> class(as.data.frame(talks_ja)[, "transcript_ja"])
[1] "character"
> #
> length(as.data.frame(talks_ja)[, "transcript_ja"])
[1] 2551](https://image.slidesharecdn.com/20180901tokyor72-180901132705/75/tidytext-RMeCab-20-2048.jpg)














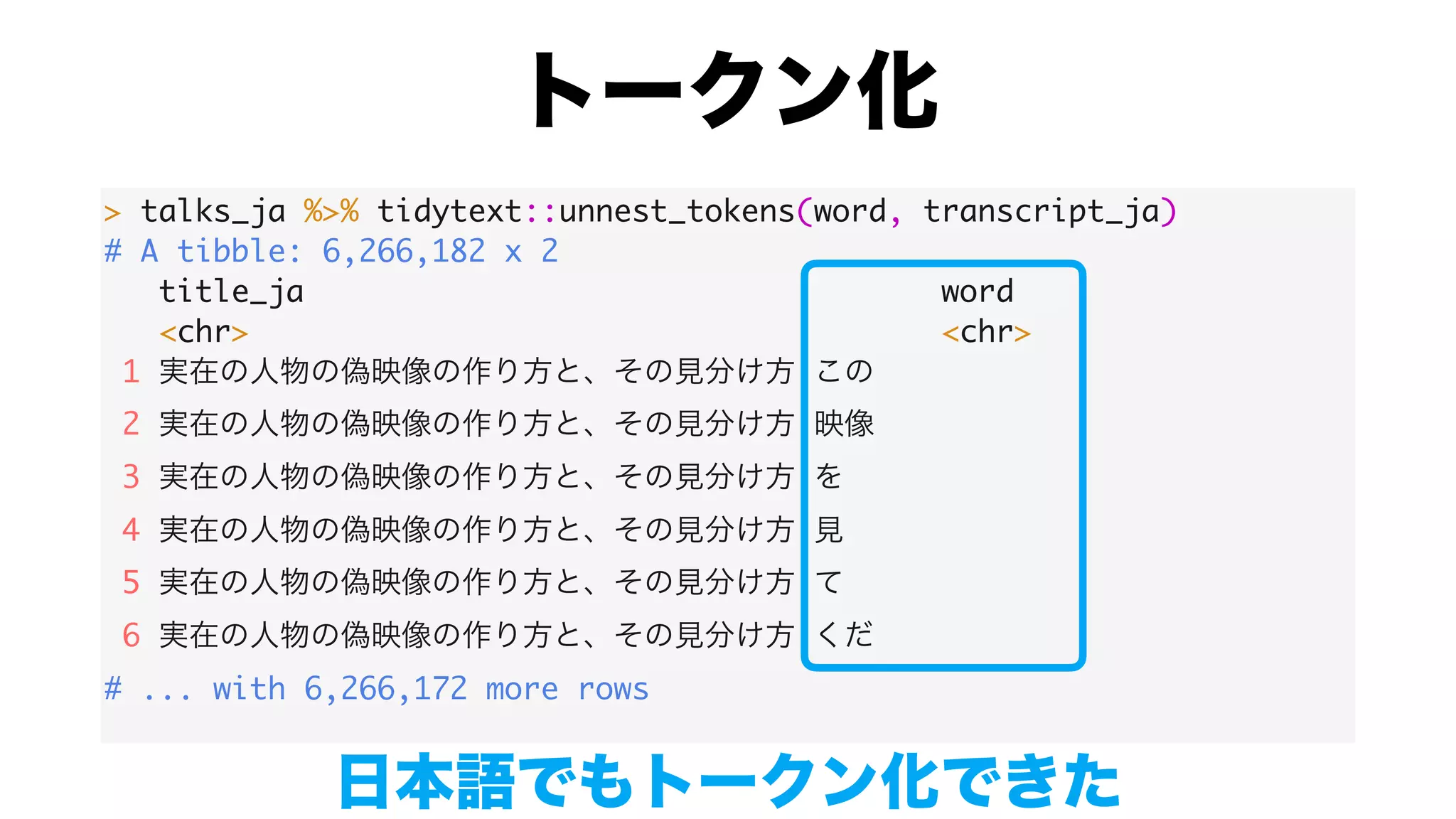
This document discusses analyzing text data from Japanese language transcripts of talks in R. It shows tokenizing the Japanese text into words using the MeCab library and creating bigram features by grouping the tokenized words into pairs. Some key steps include: 1. Tokenizing the Japanese transcripts into words and part-of-speech tags using RMeCabDF(). 2. Creating a tokens dataframe with title, word, and POS columns. 3. Generating bigram features by grouping words by title and leading the next word.








































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)