Download as PDF, PPTX

![> me
$name
[1] "Takashi Kitano"
$twitter
[1] "@kashitan"
$work_in
[1] " "](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-2-2048.jpg)



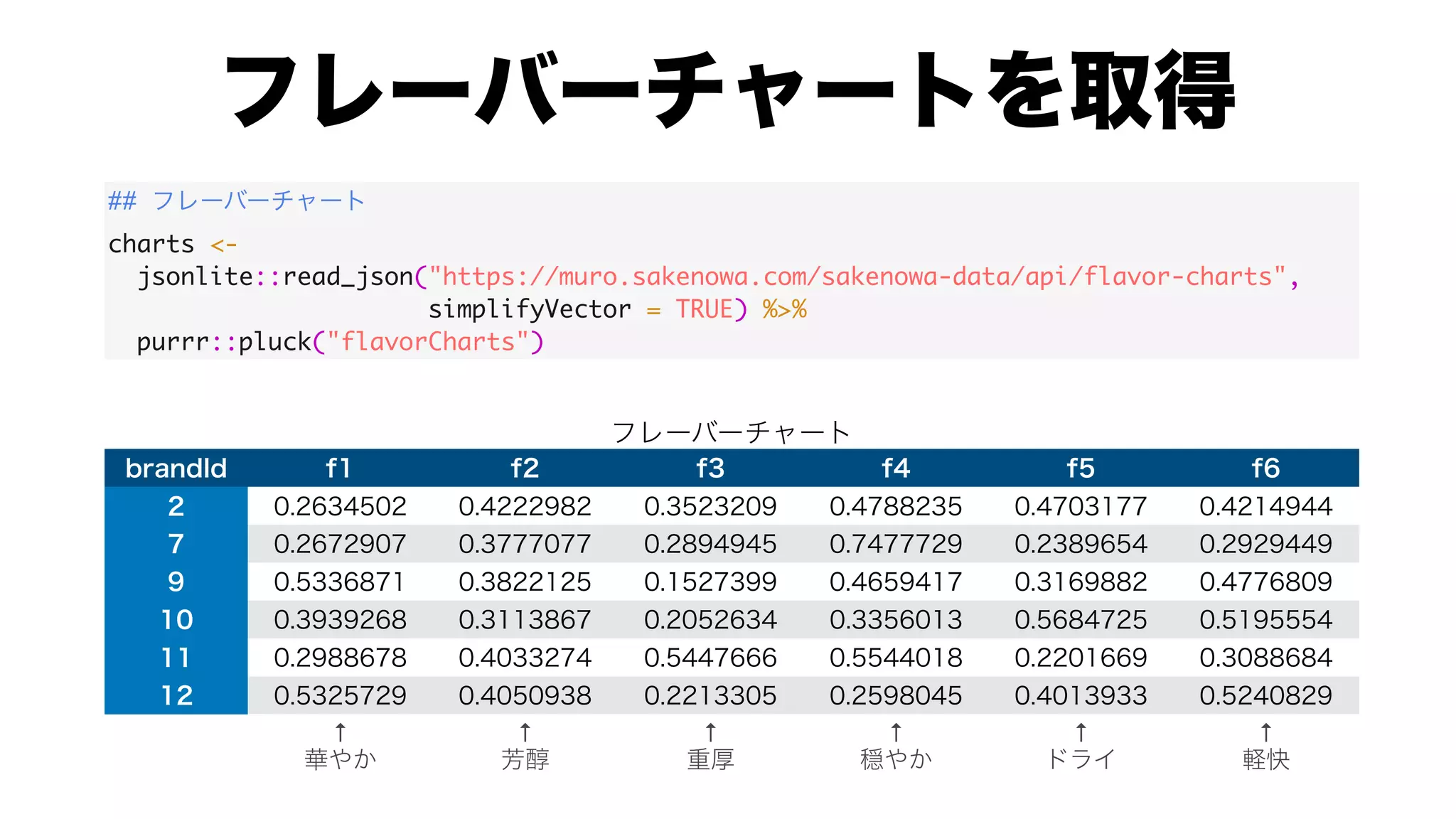

![brands.dist.mat %>%
as.matrix() %>%
.[1:8, 1:8]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-9-2048.jpg)





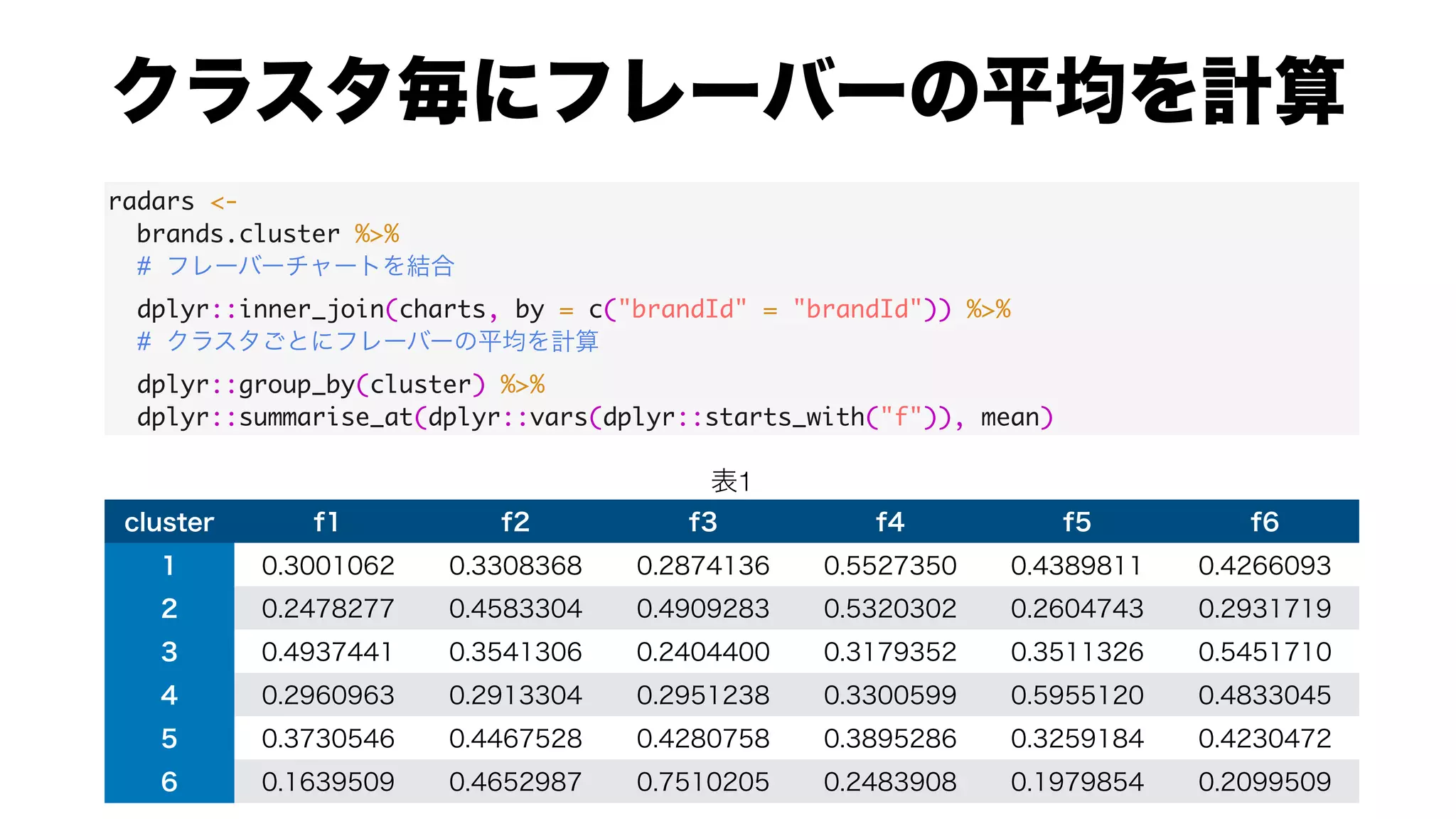
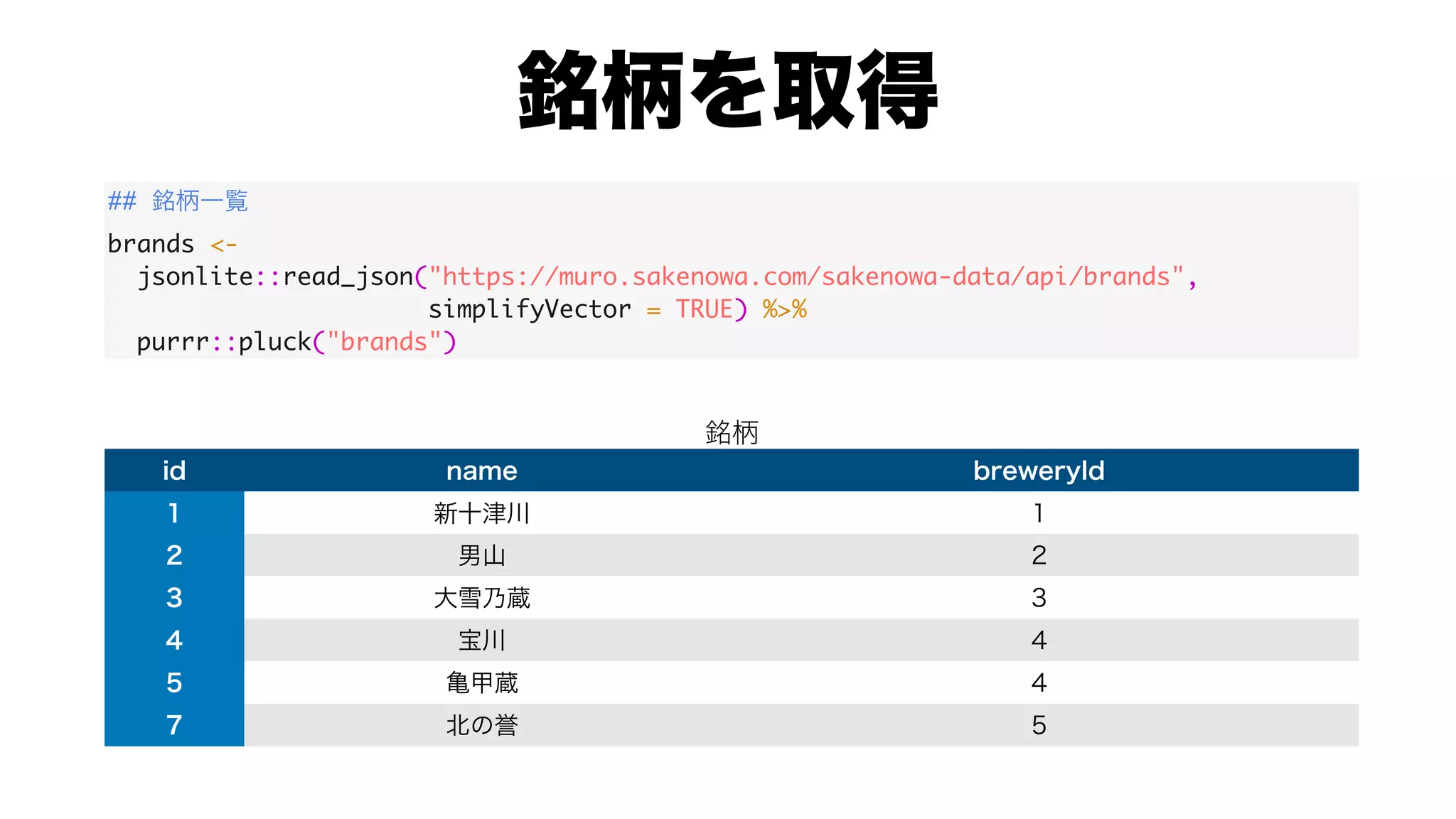
![radars <-
radars %>%
#
dplyr::group_by(cluster) %>%
tidyr::nest() %>%
dplyr::mutate(fig = purrr::map2(data, cluster, function(x, y) {
plotly::plot_ly(
type = "scatterpolar", mode = "markers",
r = c(x$f1, x$f2, x$f3, x$f4, x$f5, x$f6, x$f1),
theta = c(" ", " ", " ", " ", " ", " ", " "),
fill = 'toself',
fillcolor = RColorBrewer::brewer.pal(n = n, name = "Accent")[y],
opacity = 0.5
) %>%
plotly::layout(polar = list(angularaxis = list(
rotation = 90,
direction = 'counterclockwise')))
}))](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-18-2048.jpg)
![radars$fig[[1]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-19-2048.jpg)
![radars$fig[[4]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-20-2048.jpg)
![radars$fig[[2]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-21-2048.jpg)
![radars$fig[[6]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-22-2048.jpg)
![radars$fig[[3]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-23-2048.jpg)
![radars$fig[[5]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-24-2048.jpg)
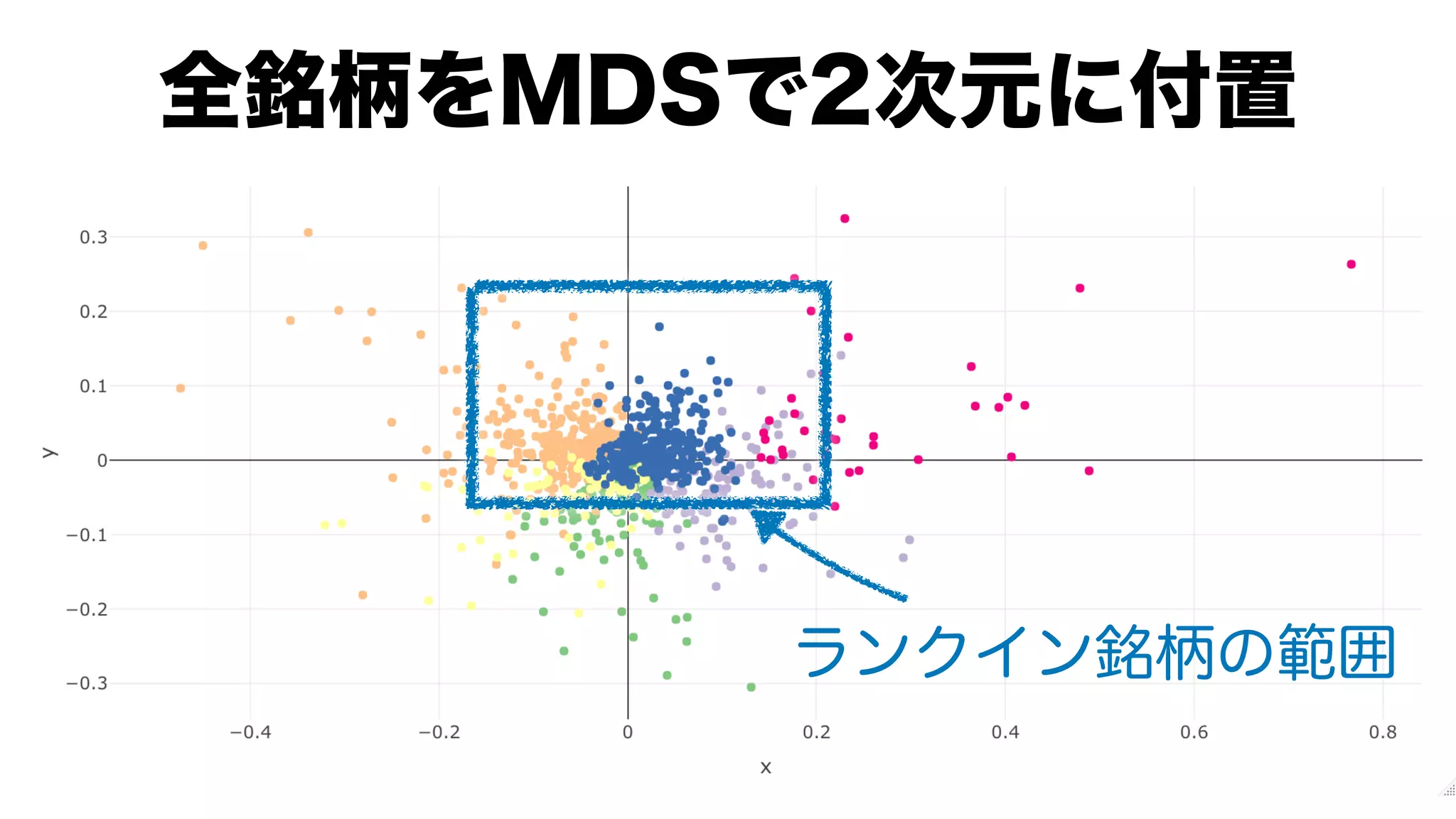
![brands.mds <-
brands.dist.mat %>%
# (MDS)
cmdscale() %>%
`colnames<-`(c("x", "y")) %>%
tibble::as_tibble(rownames = NA) %>%
tibble::rownames_to_column(var = "brandId") %>%
dplyr::mutate(brandId = as.integer(brandId)) %>%
#
dplyr::inner_join(
brands.cluster,
by = c("brandId" = "brandId")
) %>%
#
dplyr::inner_join(
brands[, -3],
by = c("brandId" = "id")
) %>%
dplyr::mutate(cluster = forcats::as_factor(cluster))
1](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-25-2048.jpg)
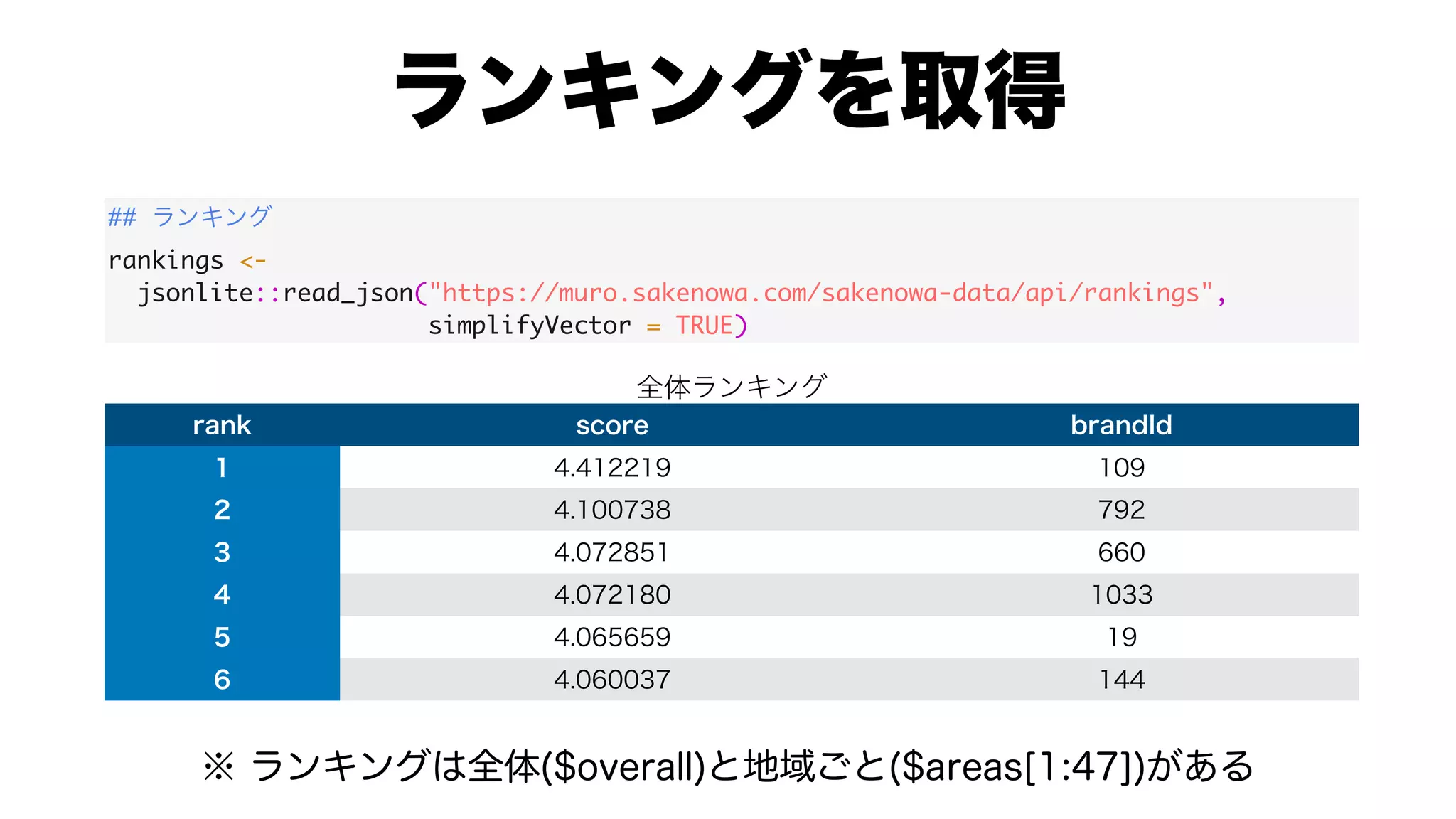

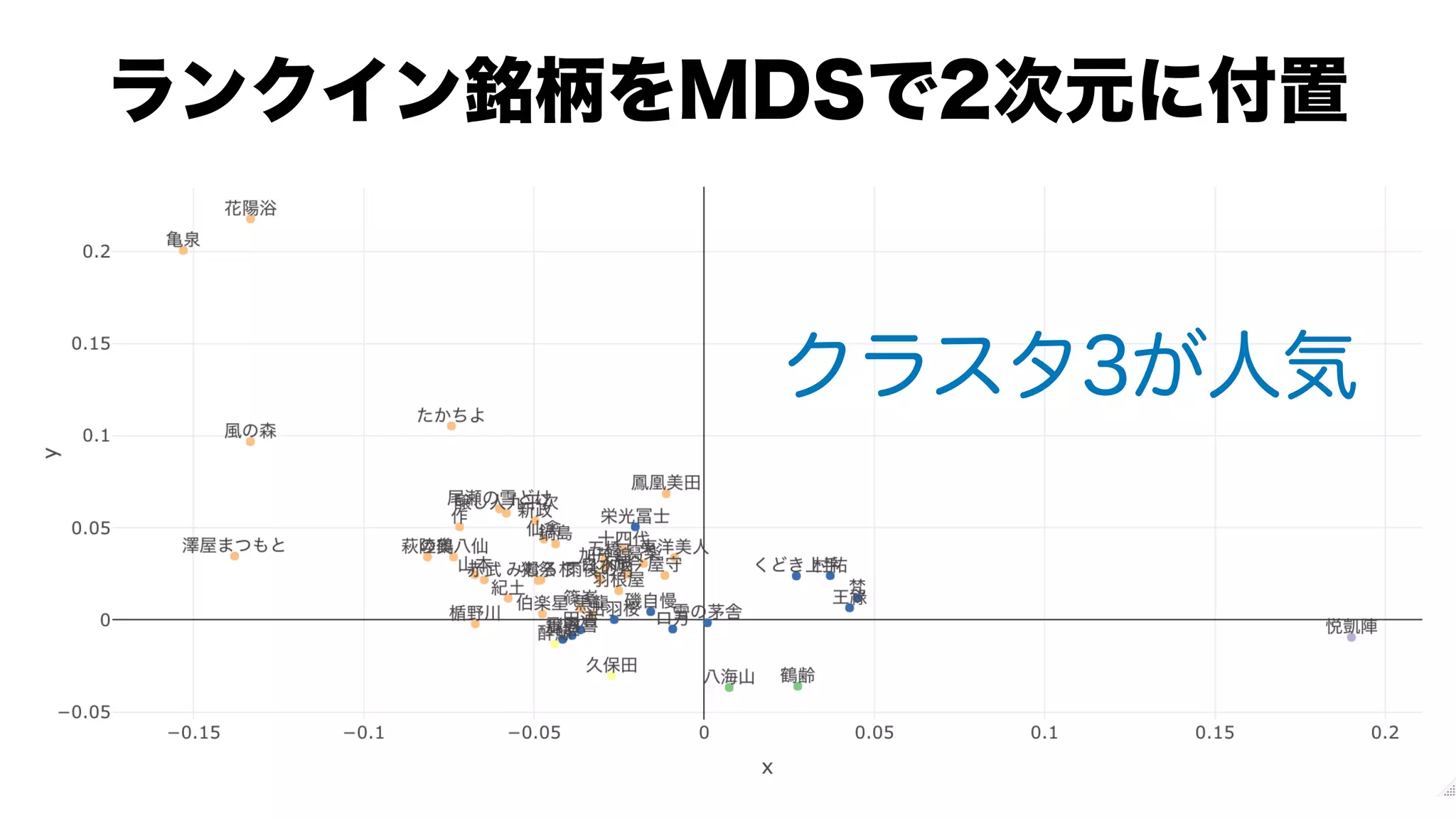



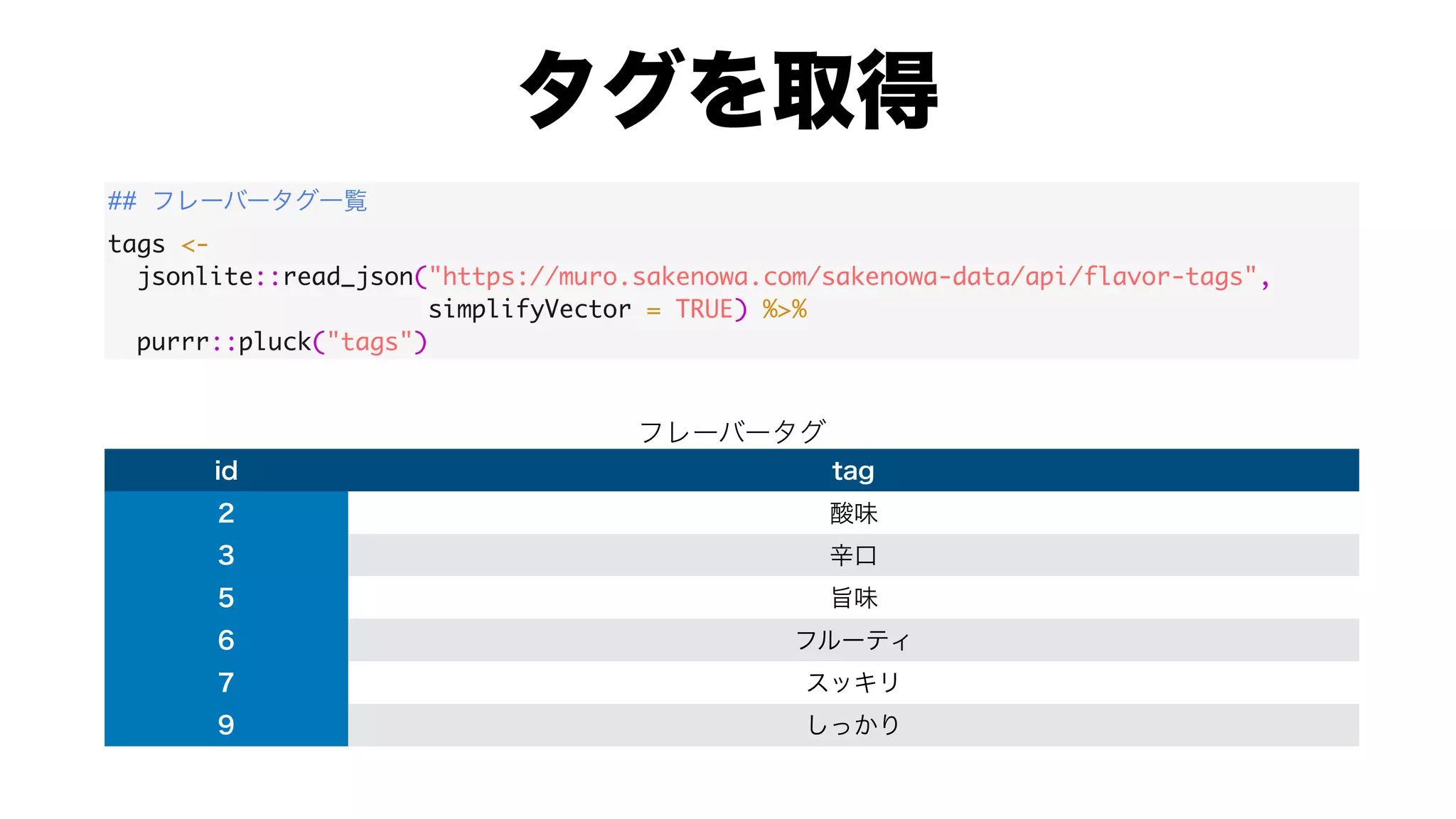
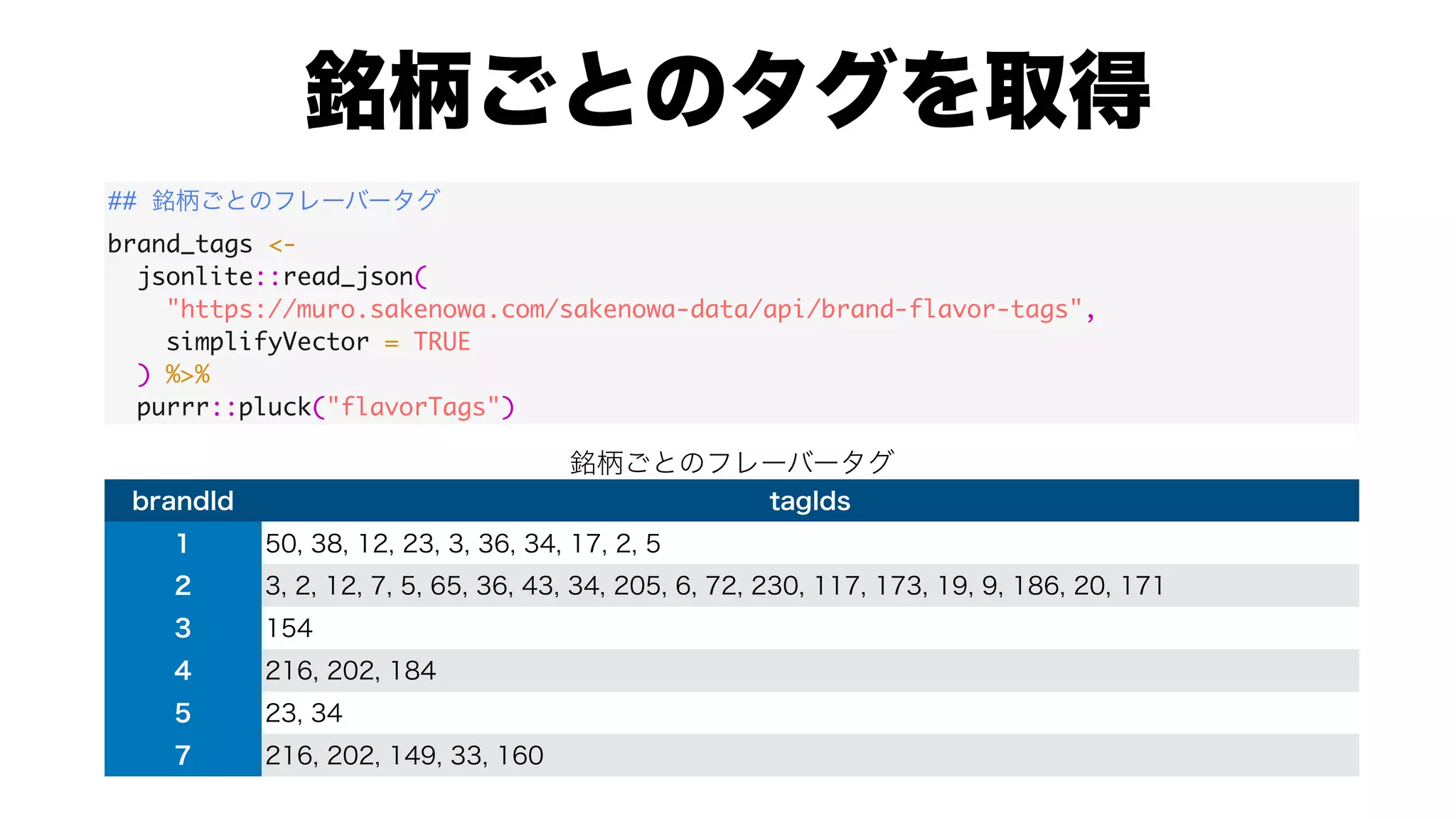


![#
res.ca <-
FactoMineR::CA(contingency.table, graph = FALSE)
# tibble
tags.biplot <-
tibble::tibble(
type = "tag",
x = res.ca$row$coord[, 1],
y = res.ca$row$coord[, 2],
label = rownames(contingency.table)) %>%
dplyr::bind_rows(
tibble::tibble(
type = "cluster",
x = res.ca$col$coord[, 1],
y = res.ca$col$coord[, 2],
label = colnames(contingency.table))
)](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-38-2048.jpg)
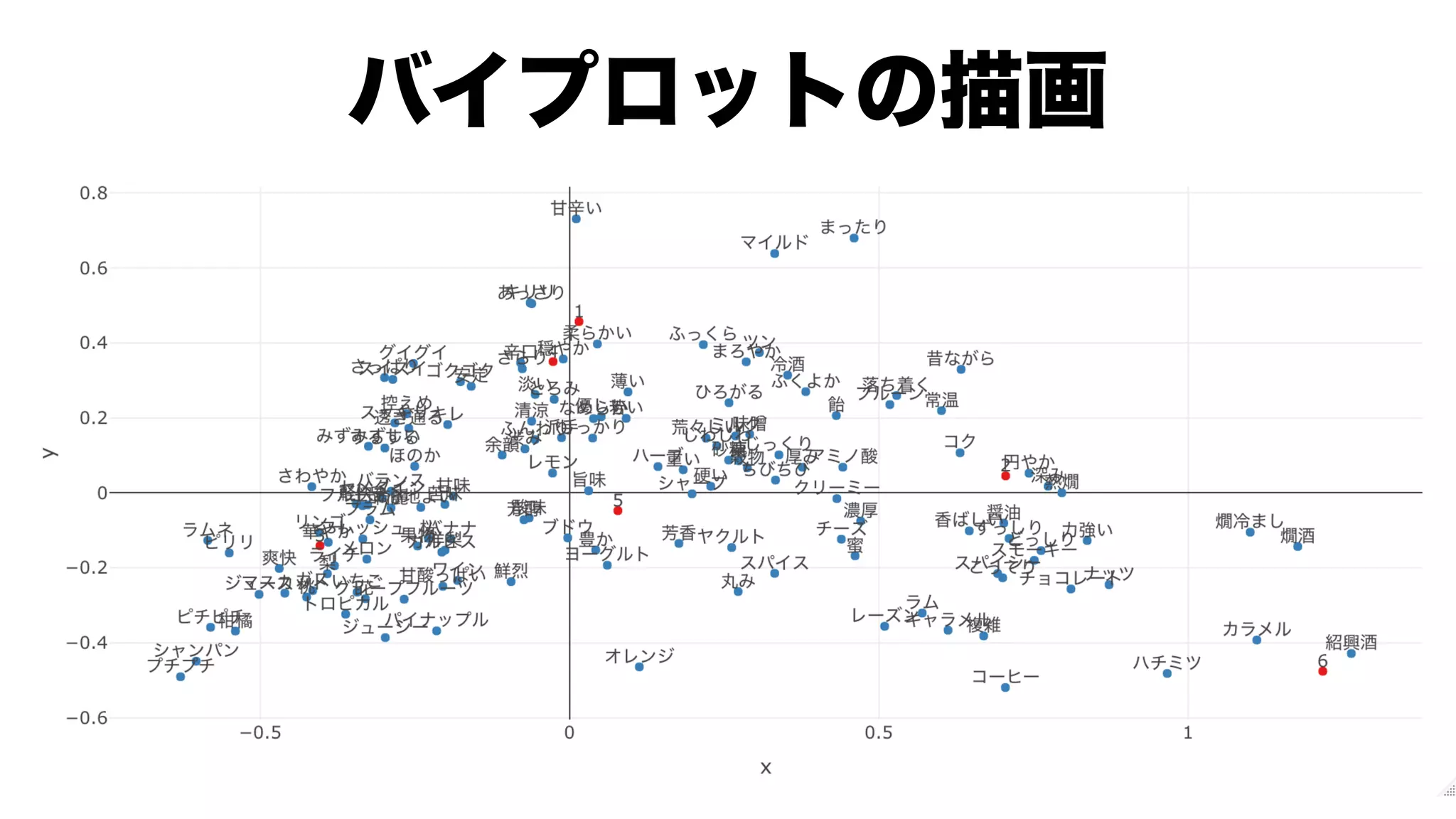
![tags.biplot %>%
plotly::plot_ly(x =~x, y =~y) %>%
plotly::add_markers(color = ~type,
colors = RColorBrewer::brewer.pal(3, "Set1")[1:2]) %>%
plotly::add_text(text = ~label, textposition = "top center") %>%
plotly::layout(showlegend = FALSE)
factoextra::fviz_ca_biplot(
res.ca,
font.family = "HiraKakuProN-W3"
)](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-39-2048.jpg)


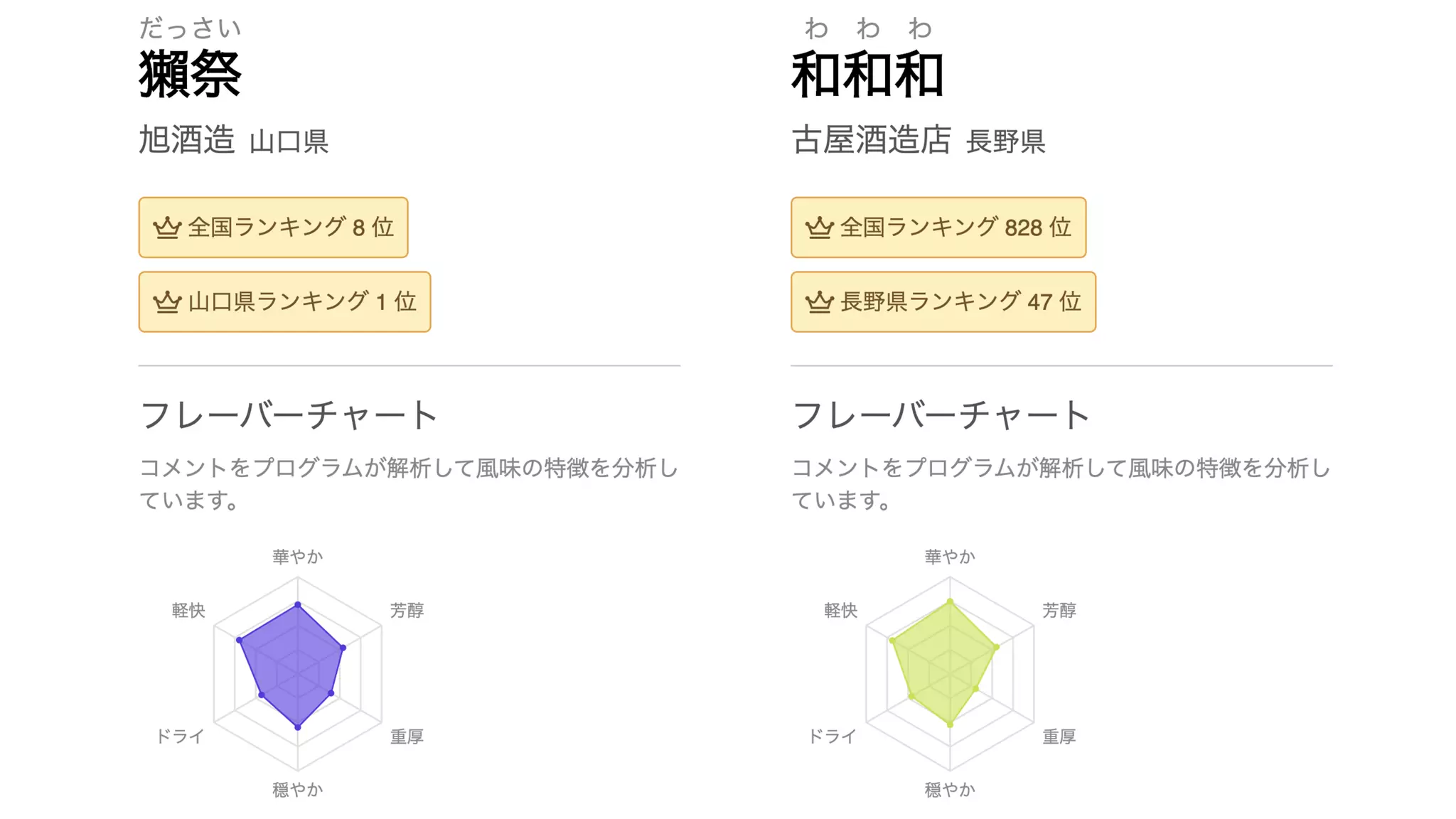
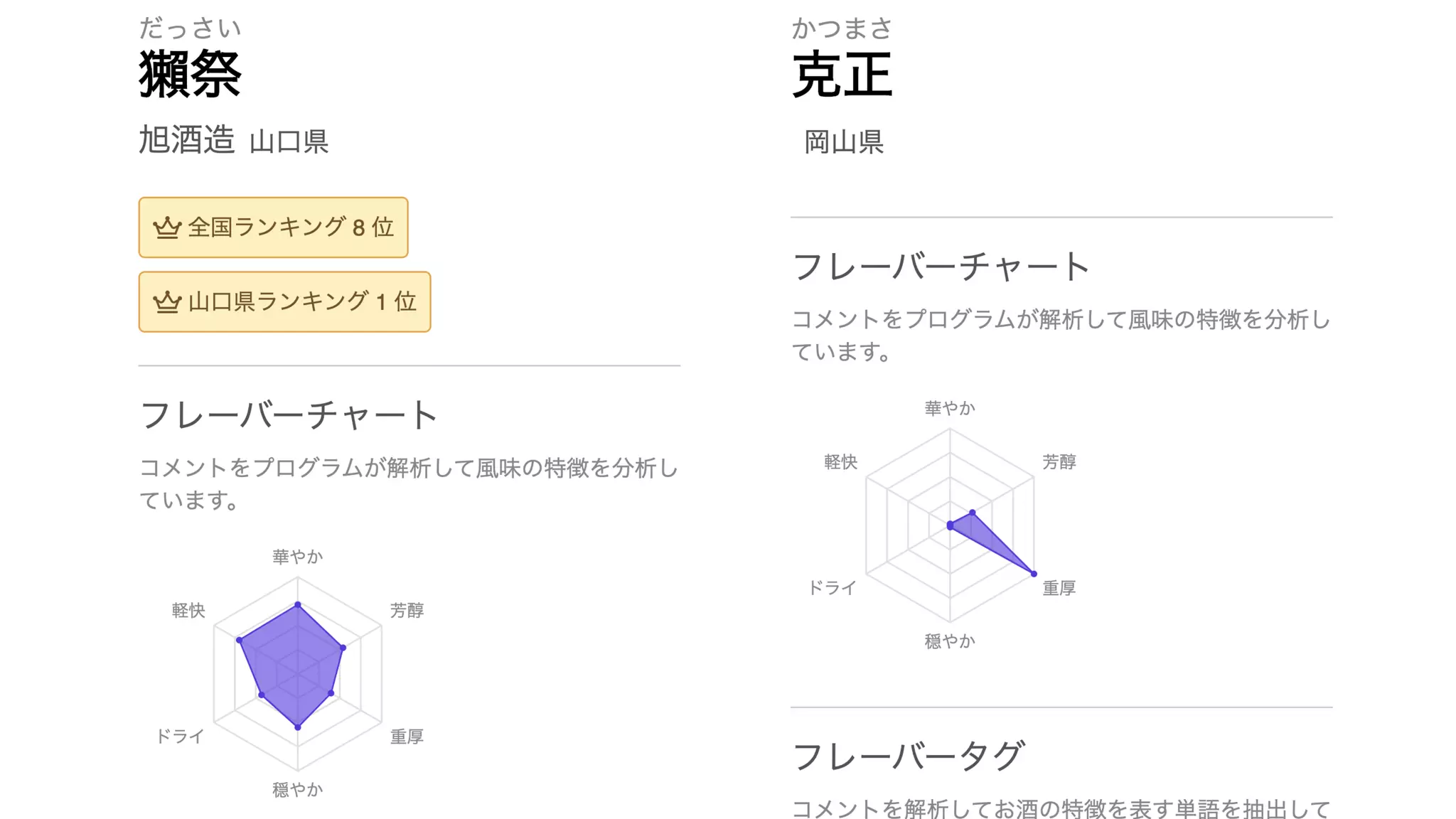
![radars$fig[[1]] wordclouds$fig[[1]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-43-2048.jpg)
![radars$fig[[4]] wordclouds$fig[[4]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-44-2048.jpg)
![radars$fig[[2]] wordclouds$fig[[2]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-45-2048.jpg)
![radars$fig[[6]] wordclouds$fig[[6]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-46-2048.jpg)
![radars$fig[[3]] wordclouds$fig[[3]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-47-2048.jpg)
![radars$fig[[5]] wordclouds$fig[[5]]](https://image.slidesharecdn.com/20200919tokyor88-200919060725/75/slide-48-2048.jpg)
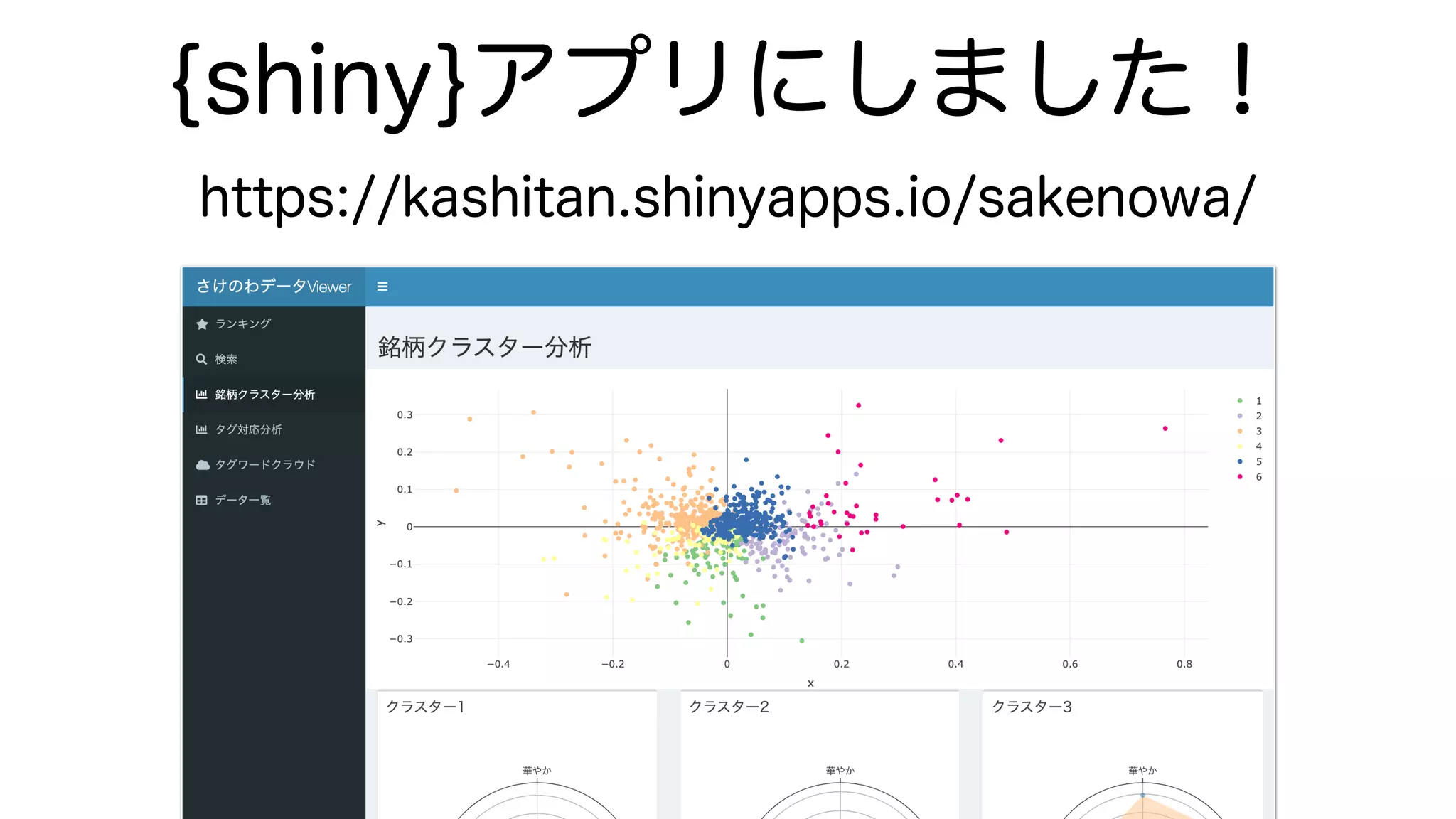



This document analyzes Japanese sake brand data to cluster brands and identify similarities. It first calculates cosine distances between brands based on flavor profiles. It then performs hierarchical clustering on the distances to group brands into 6 clusters. Finally, it creates radar charts of average flavor profiles and word clouds of common tags for each cluster to visualize differences between the groups.



























































