Download as PDF, PPTX




 { rho(i) = … }
rho0
rho1
Mapper](https://image.slidesharecdn.com/galen3-171110161708/75/The-Legion-Programming-Model-for-HPC-6-2048.jpg)












































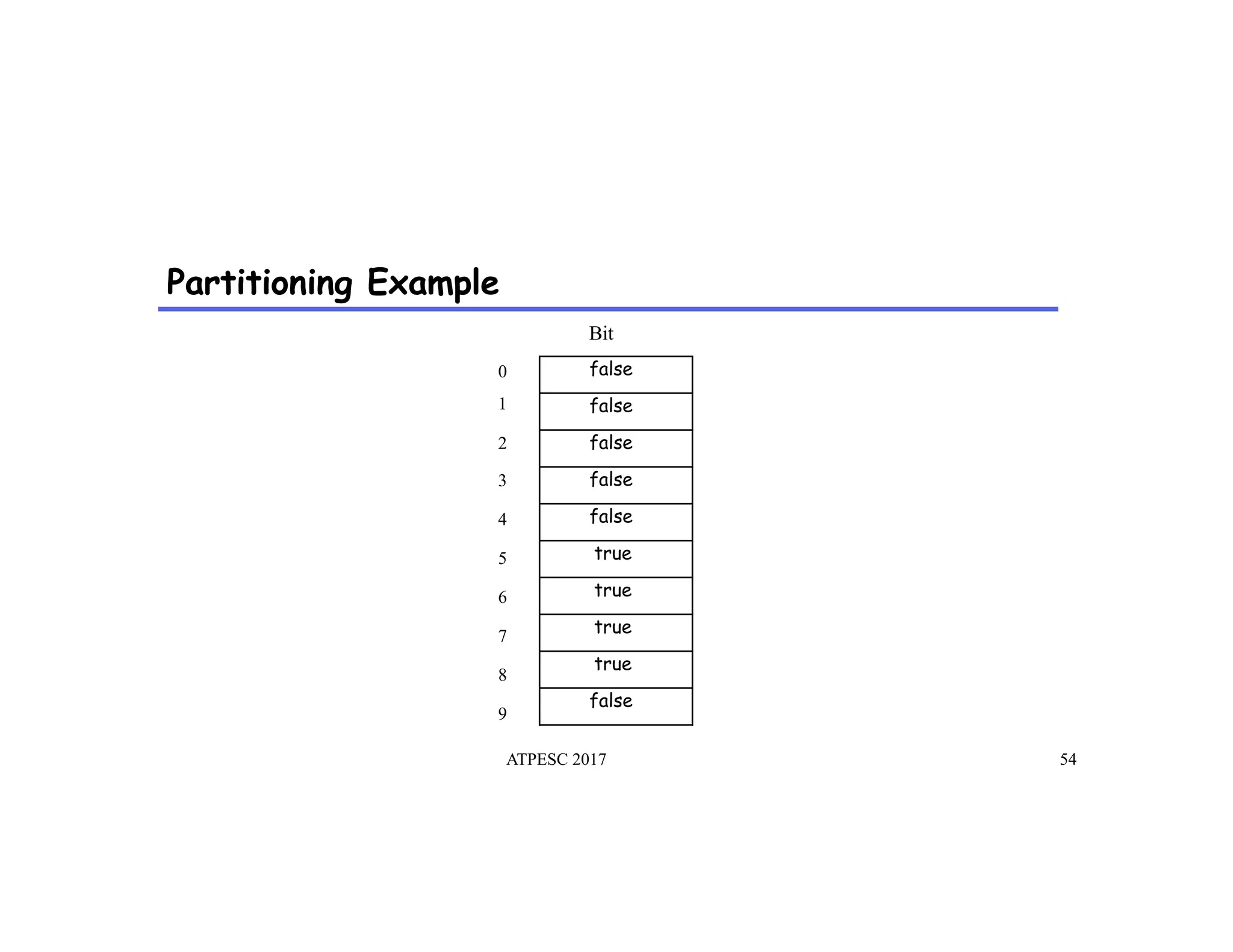
![Partitioning Example
ATPESC 2017 55
0
1
2
3
4
5
6
7
8
9
bit_region_partition[0]
bit_region_partition[1]
false
false
false
false
false
true
true
true
true
false
Bit](https://image.slidesharecdn.com/galen3-171110161708/75/The-Legion-Programming-Model-for-HPC-55-2048.jpg)

















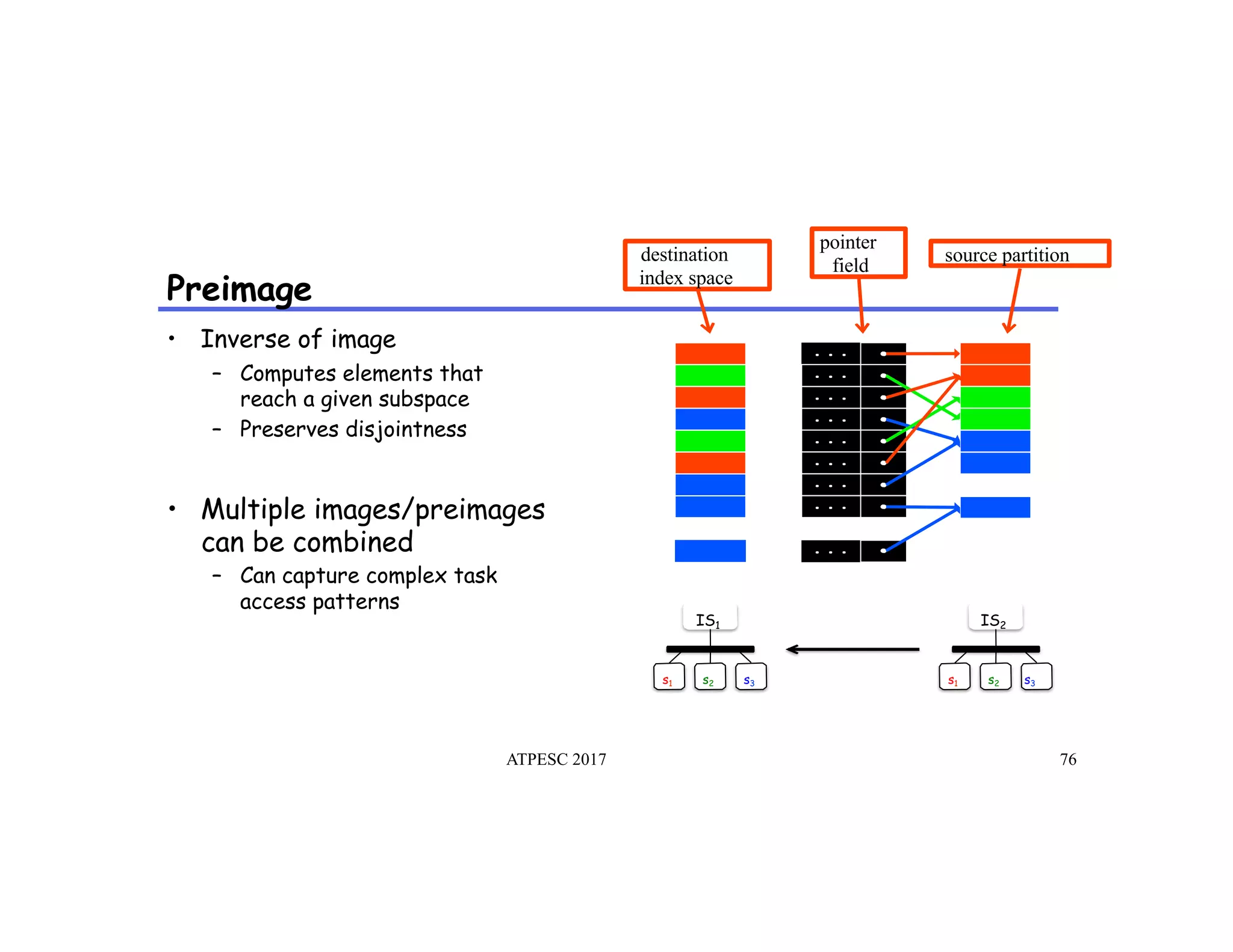

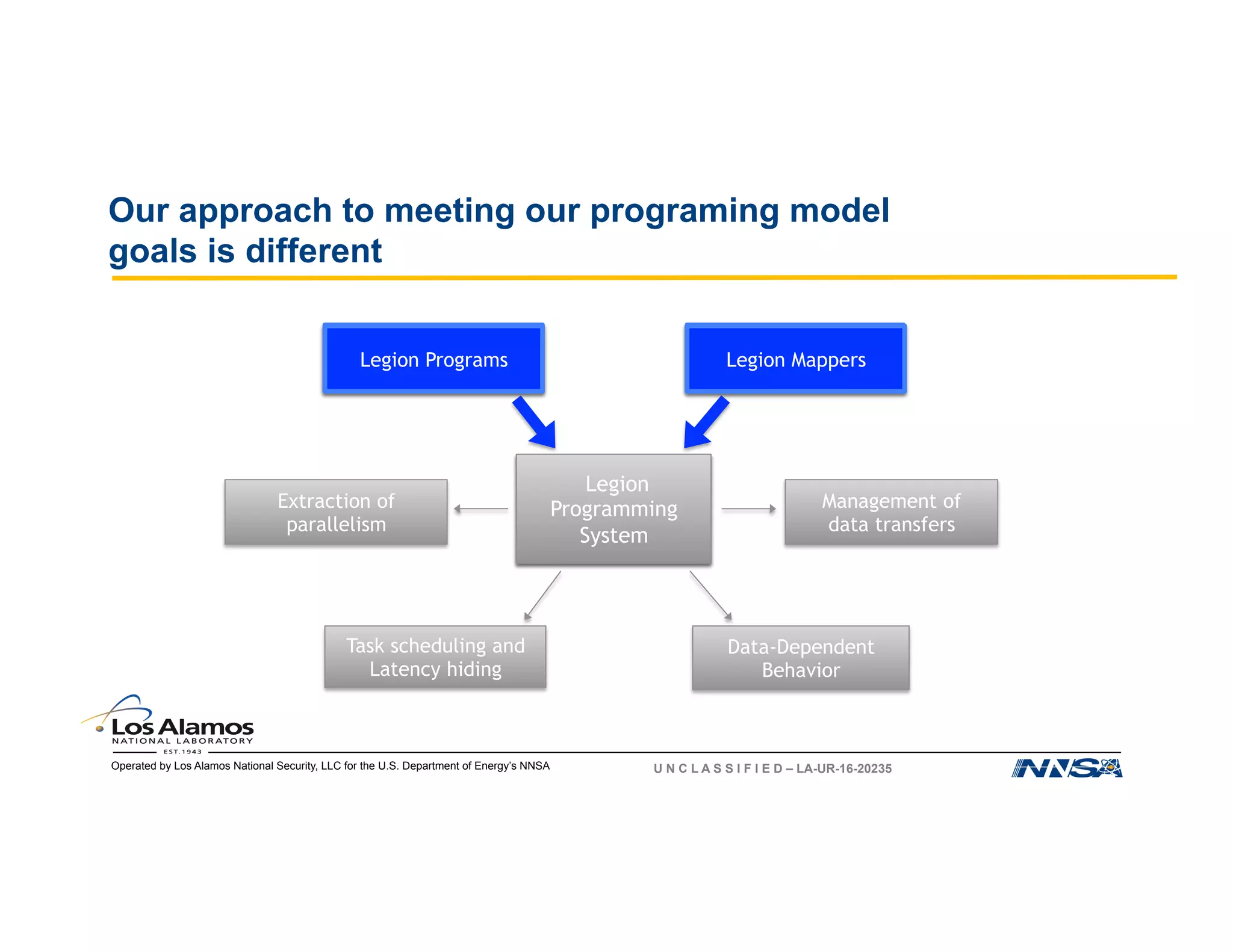
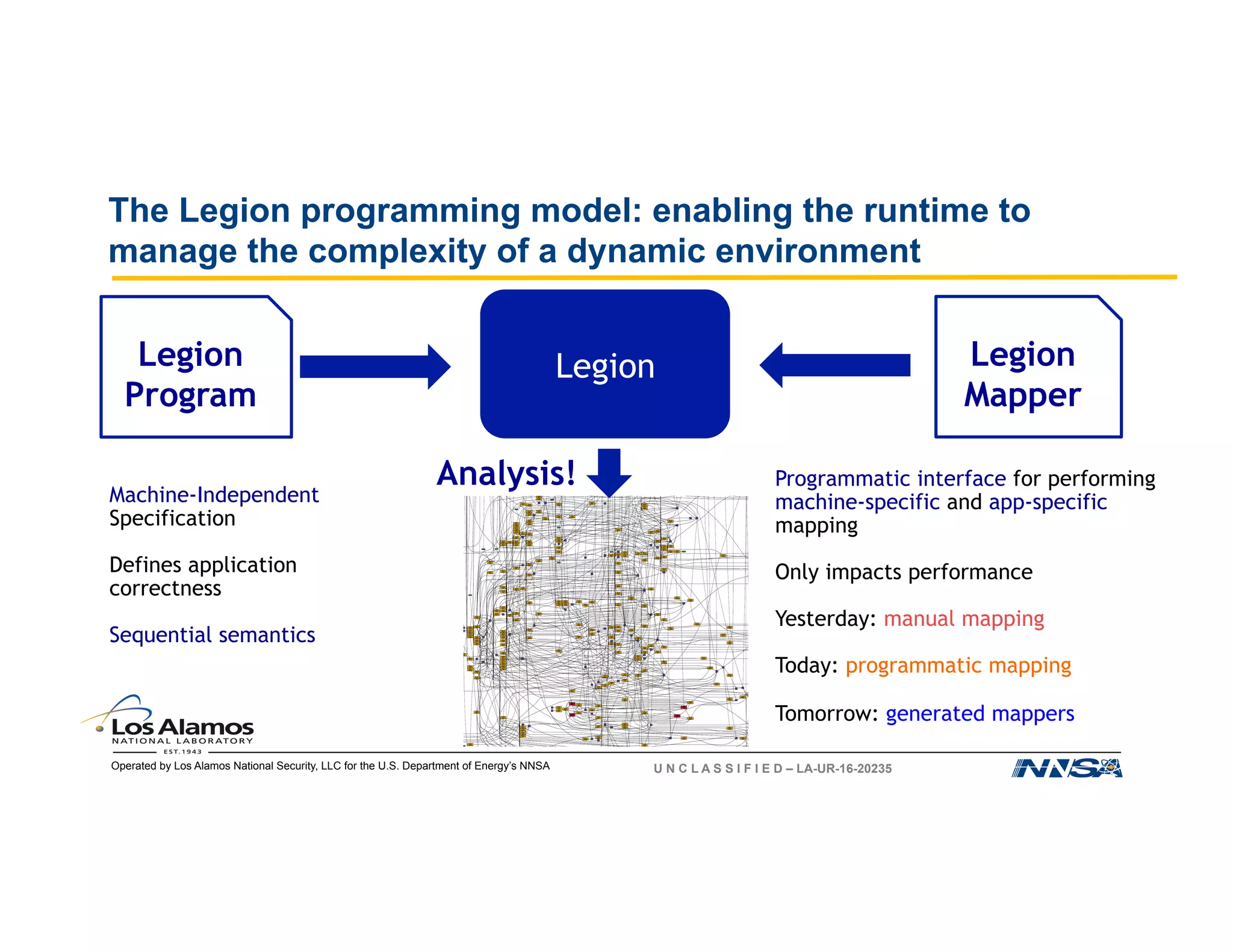
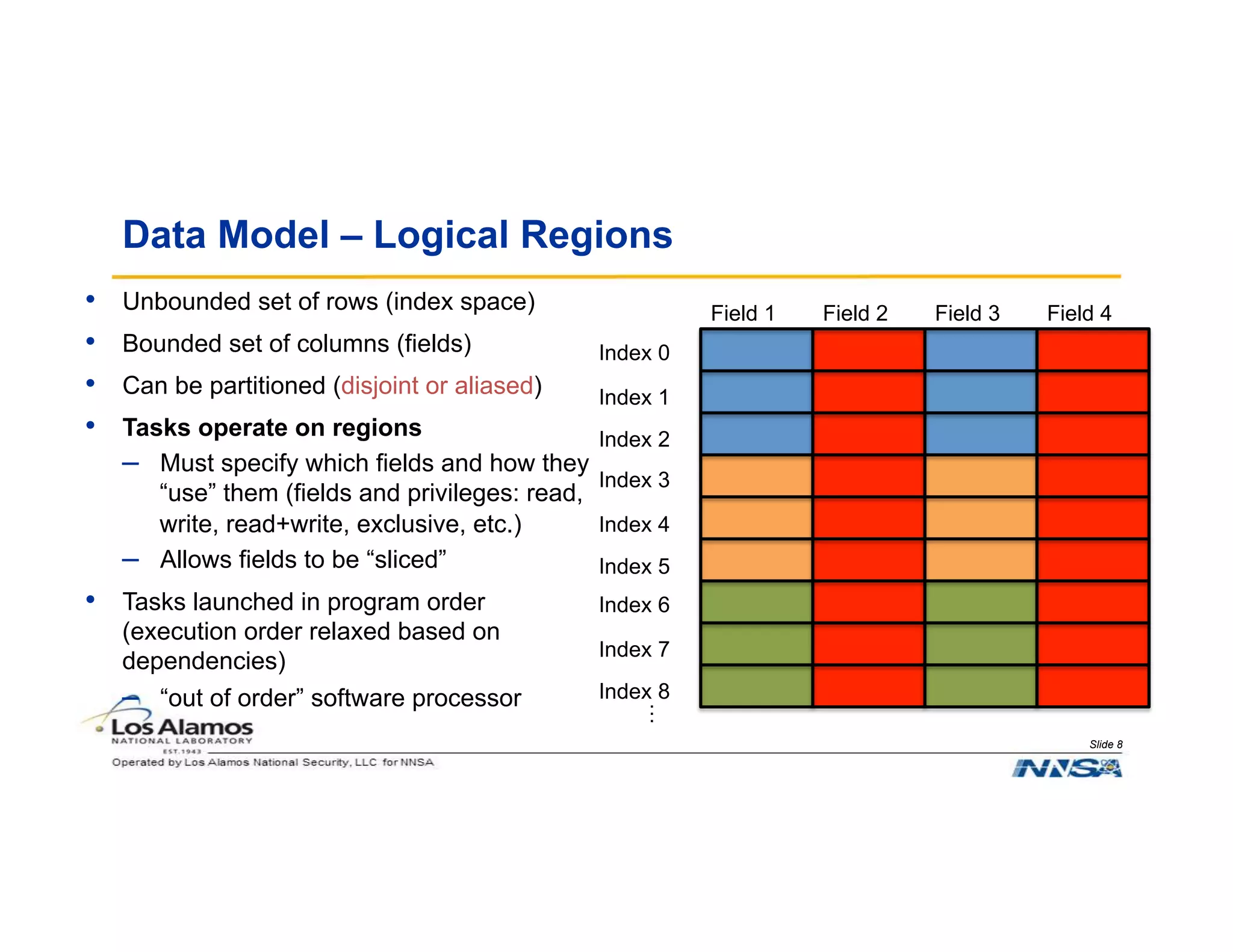
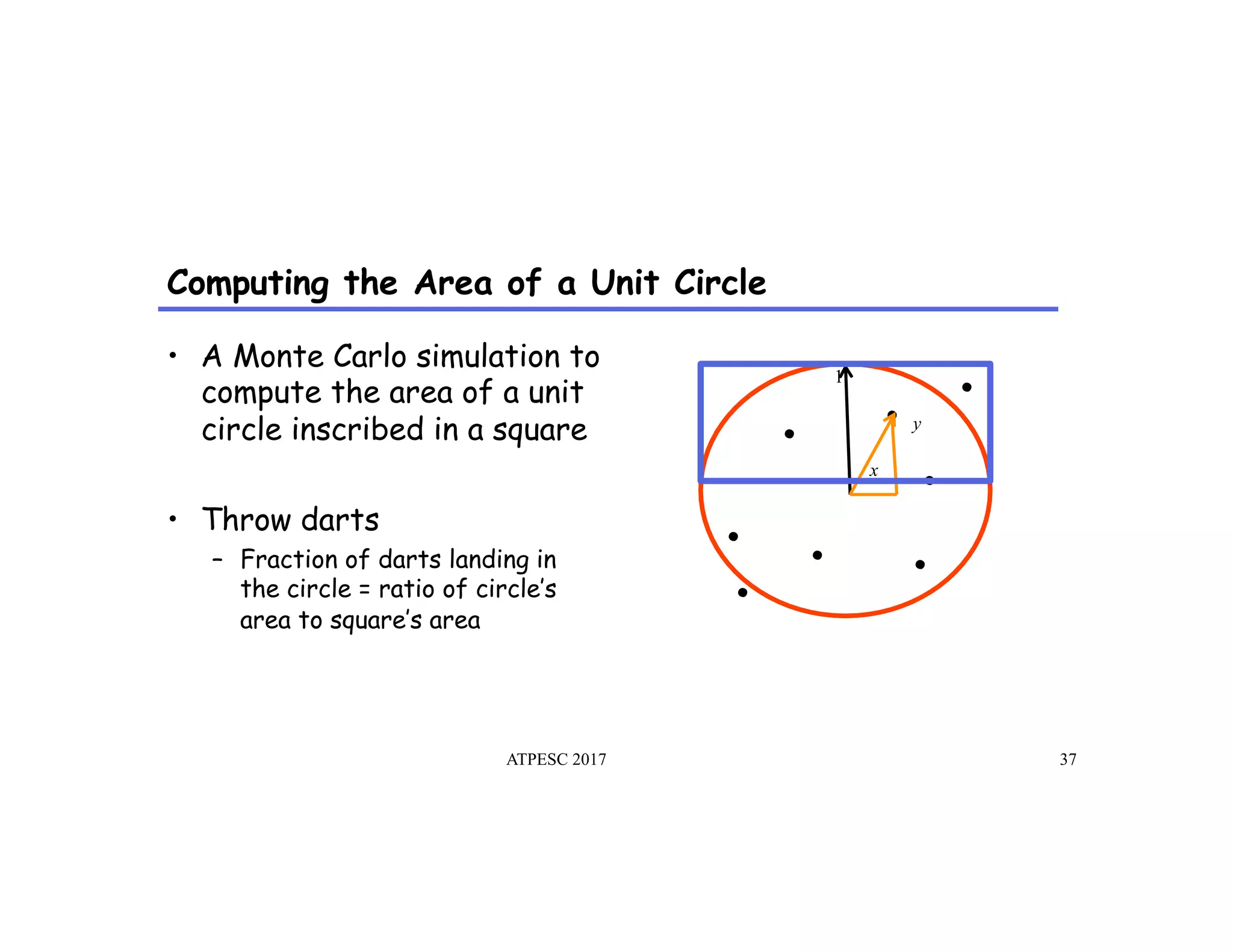
The document discusses the challenges of programming large-scale high-performance computing (HPC) systems and introduces the Legion programming model as a solution. It emphasizes the need for performance portability, programmability, and high performance, while detailing the structure and benefits of Legion's approach to managing complexity in dynamic environments. Key features of Legion include asynchronous execution, task dependency management, and a focus on data model and mapping optimizations that enhance performance and facilitate scientific advances.
















































































