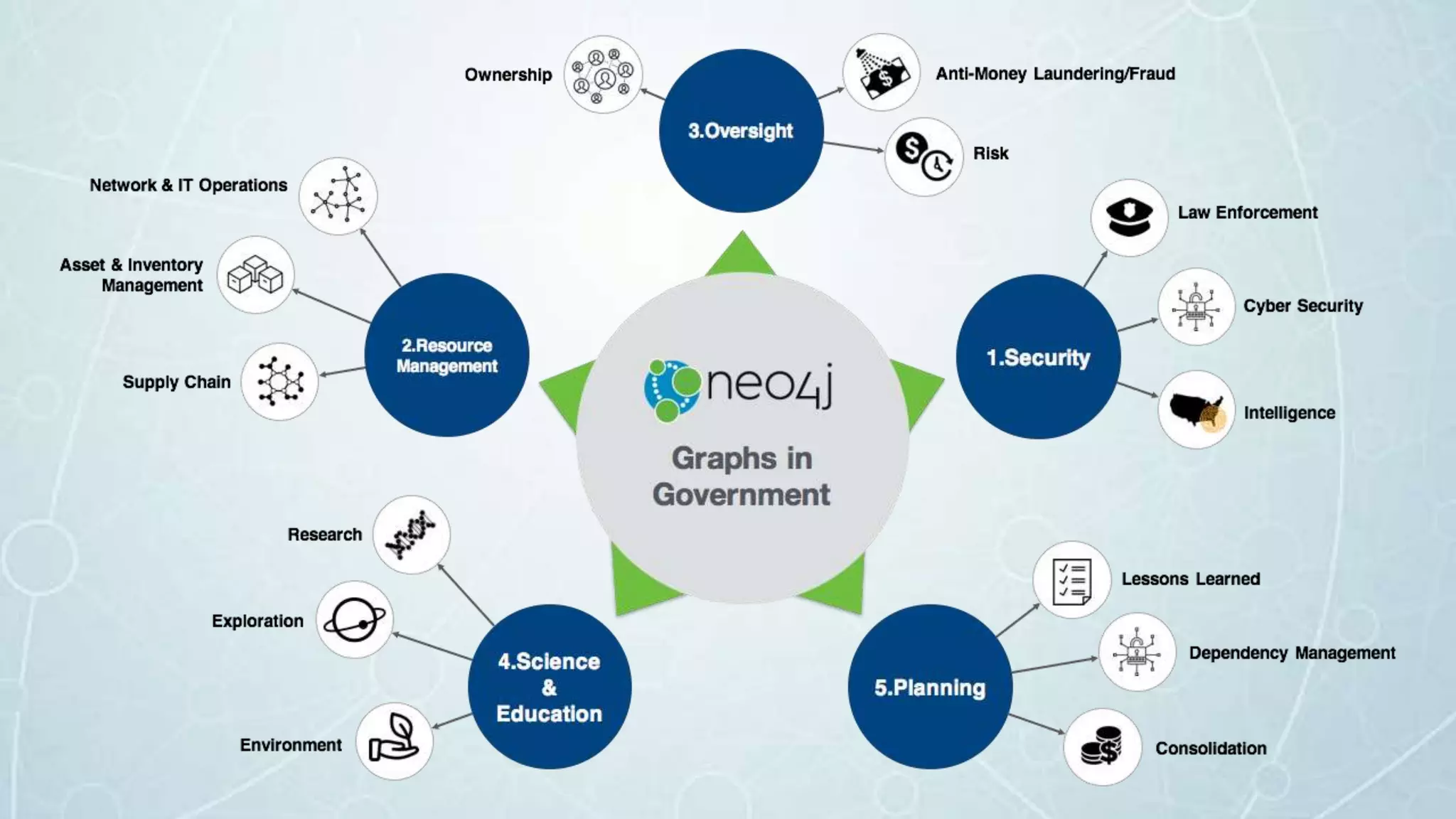
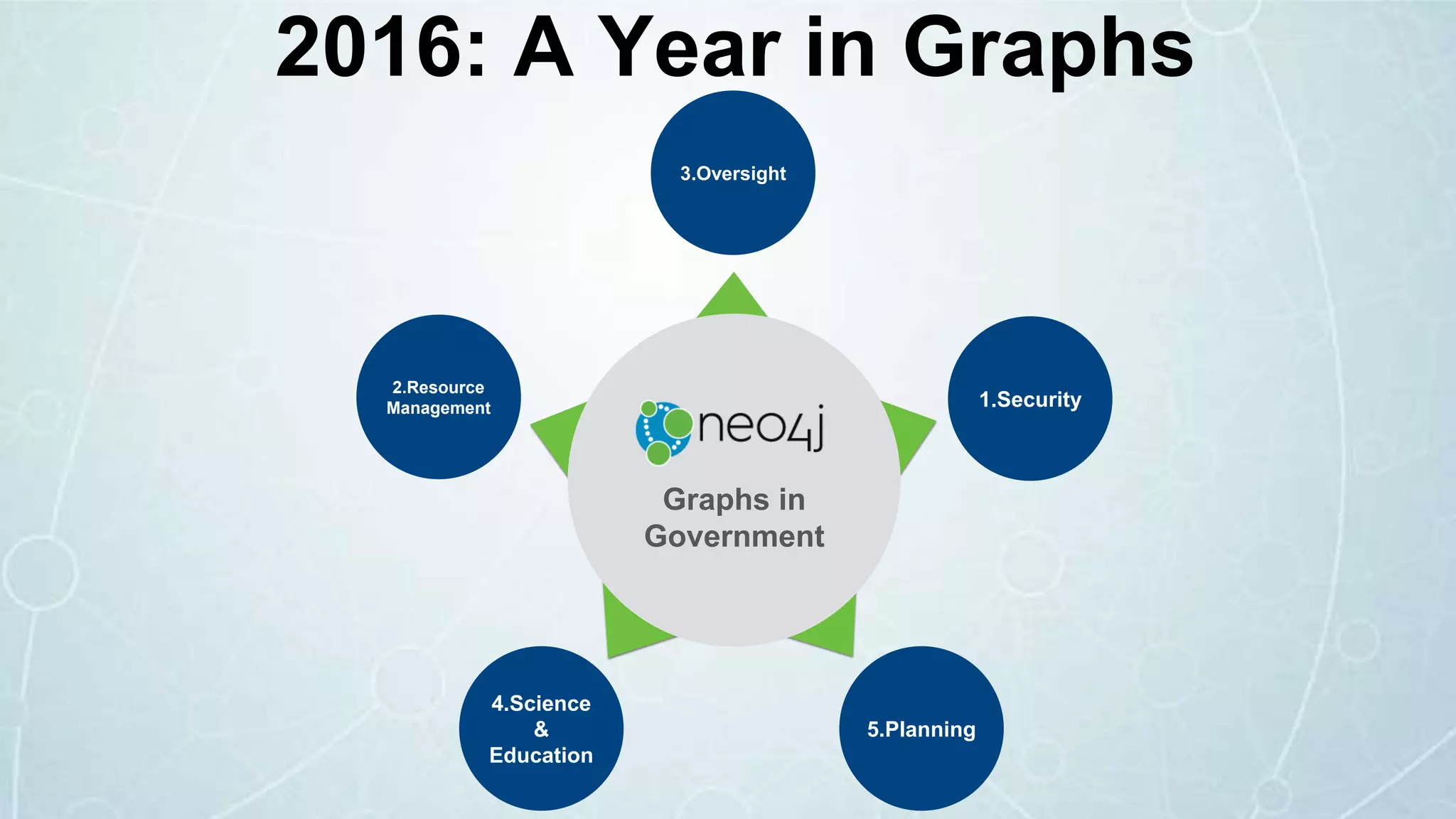
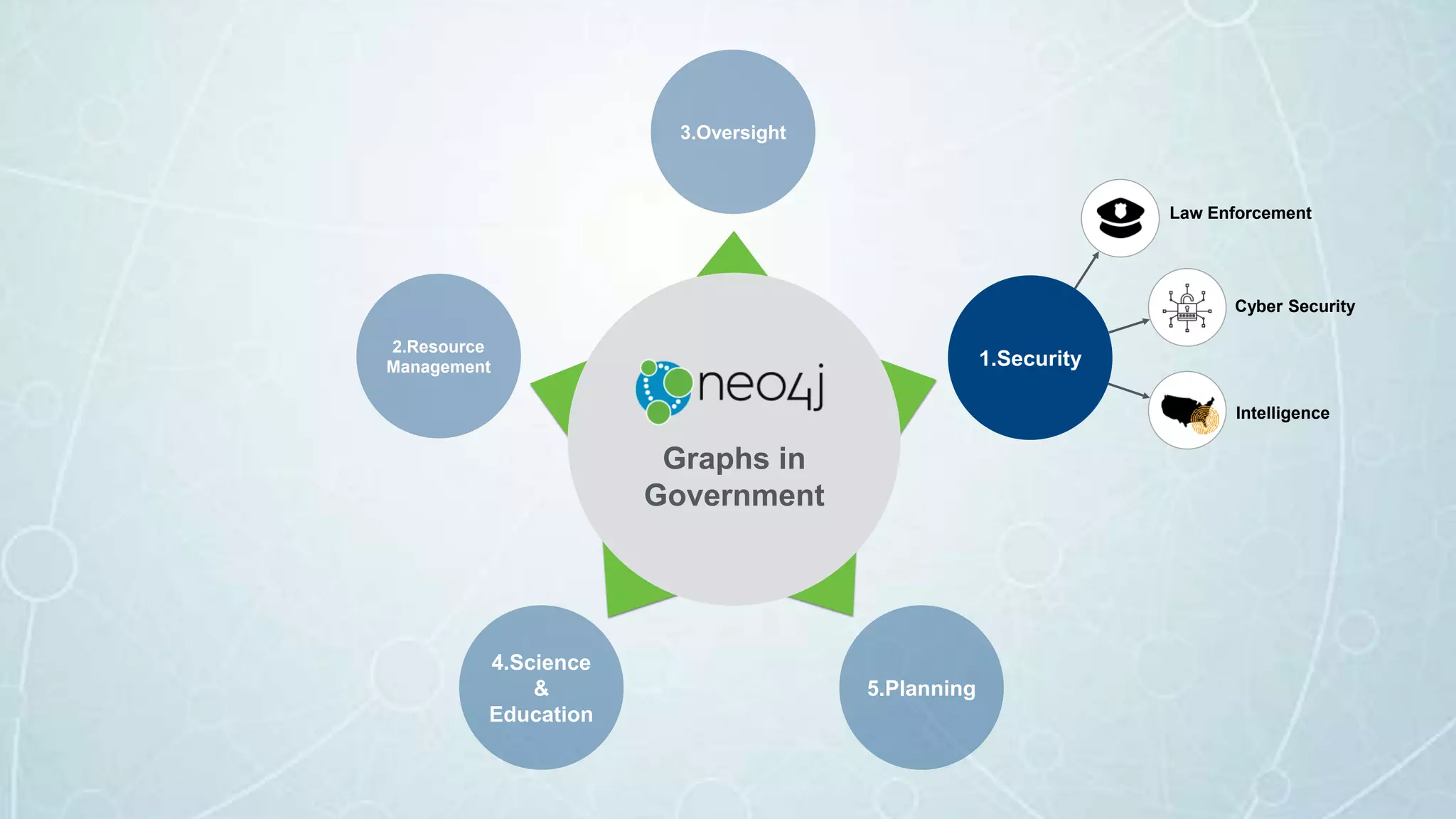
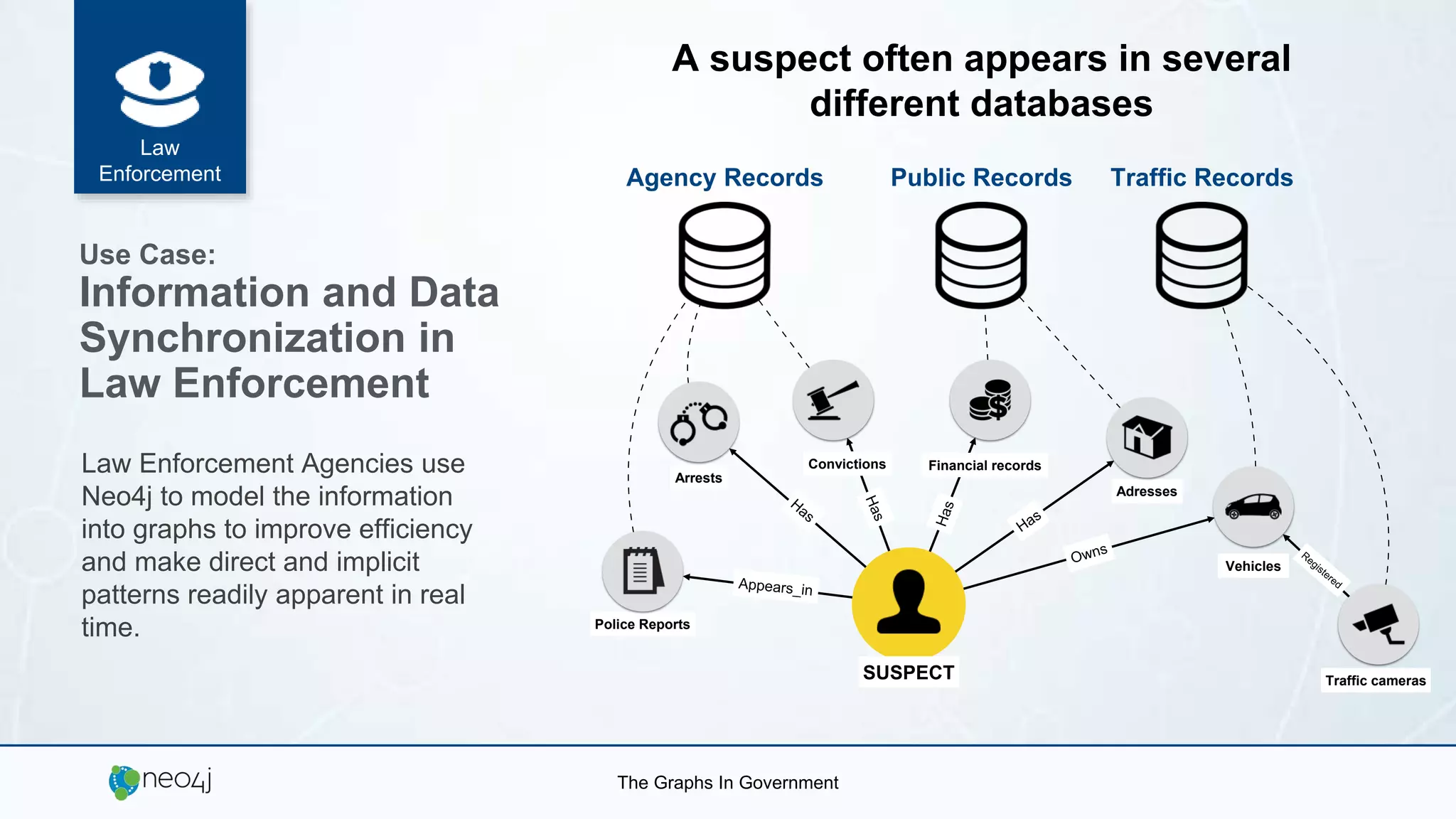
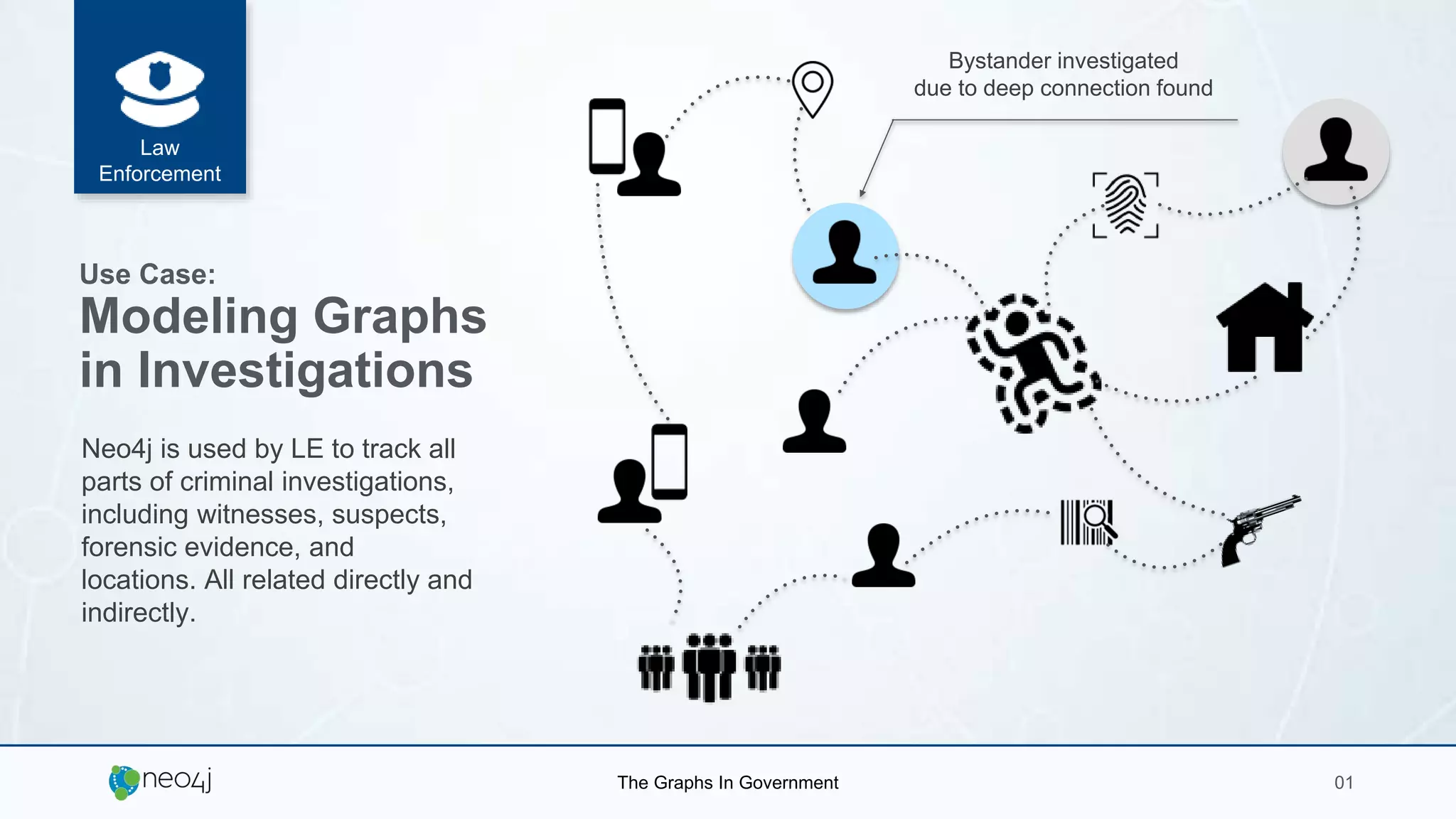
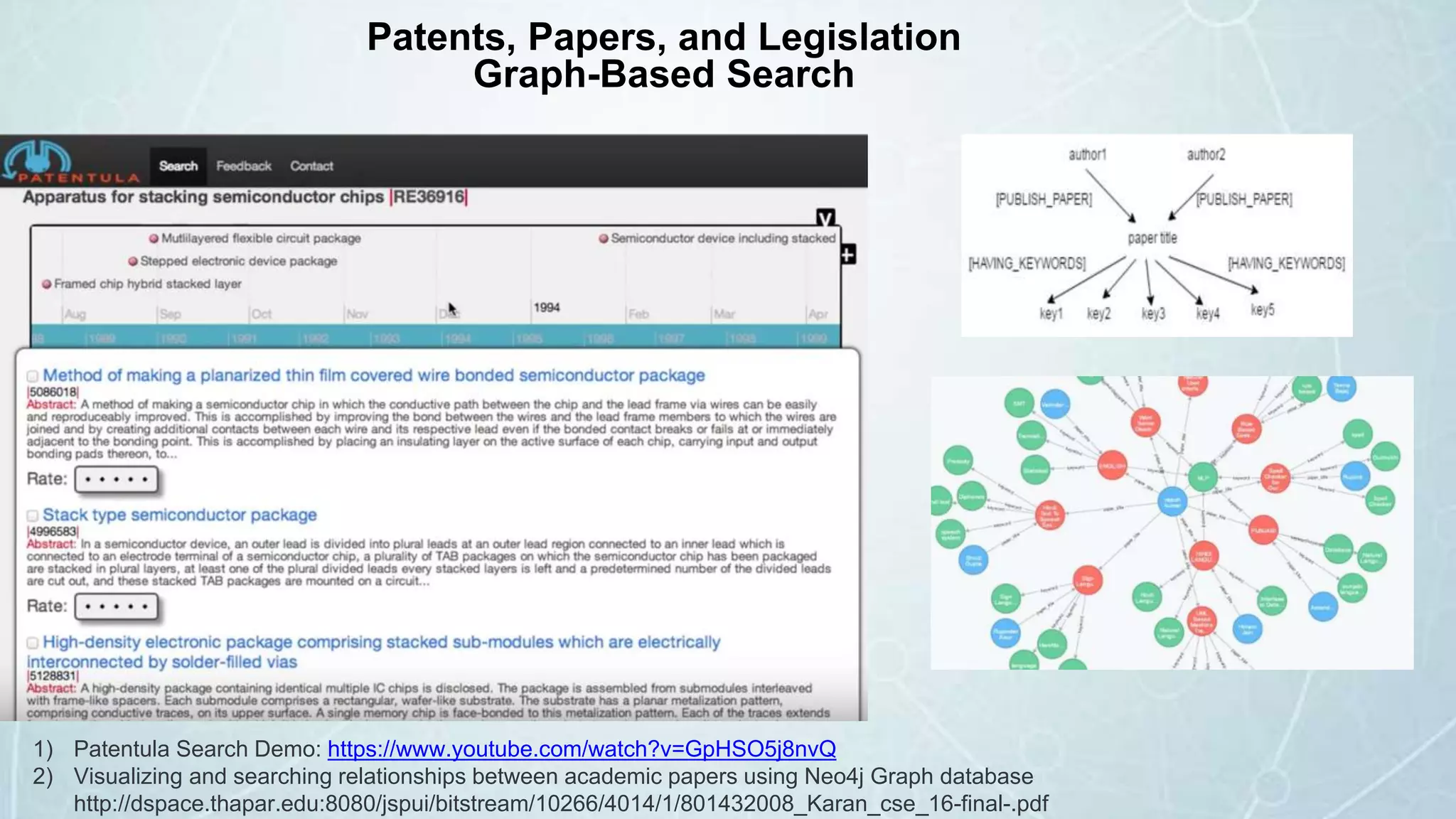
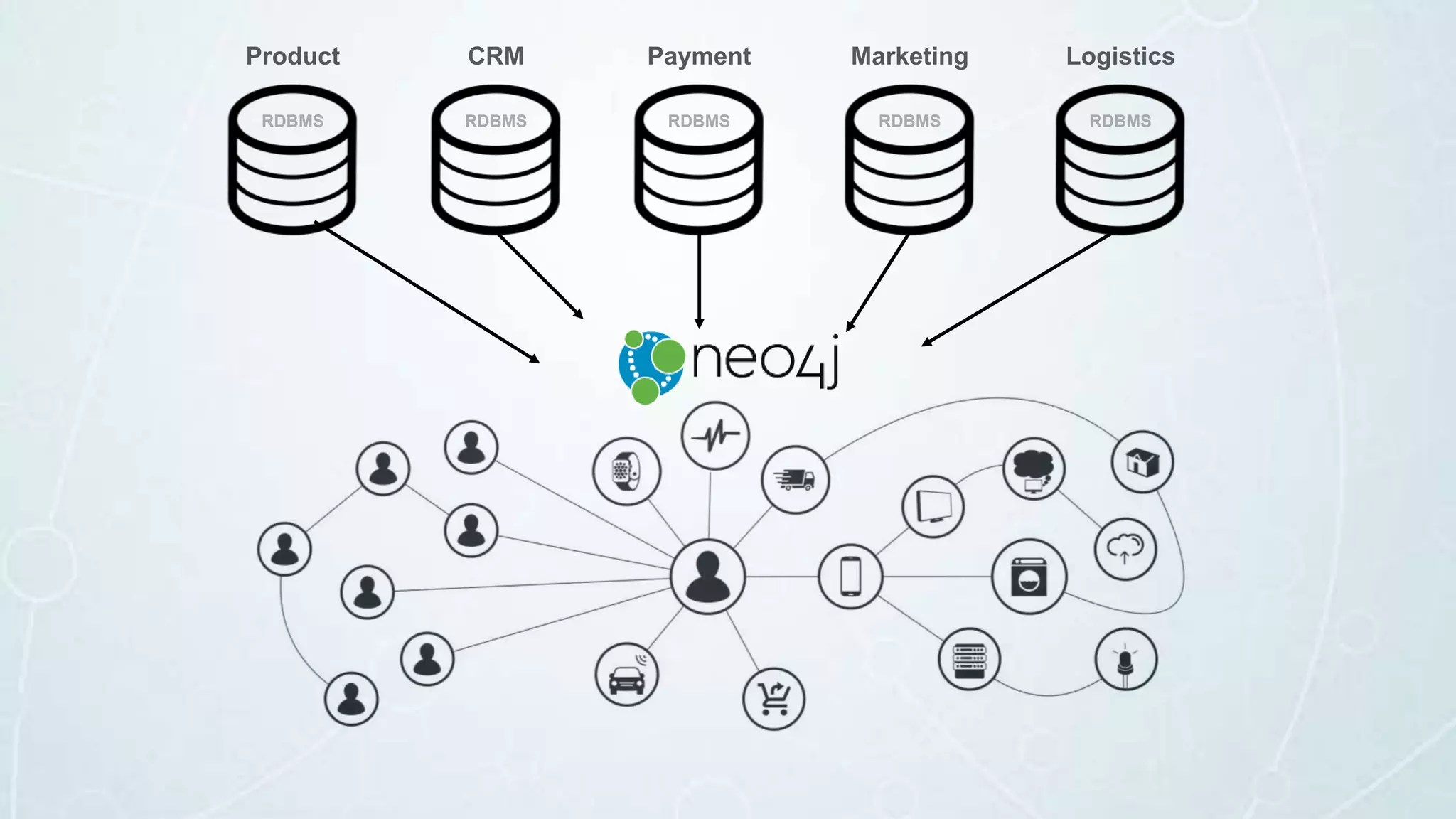
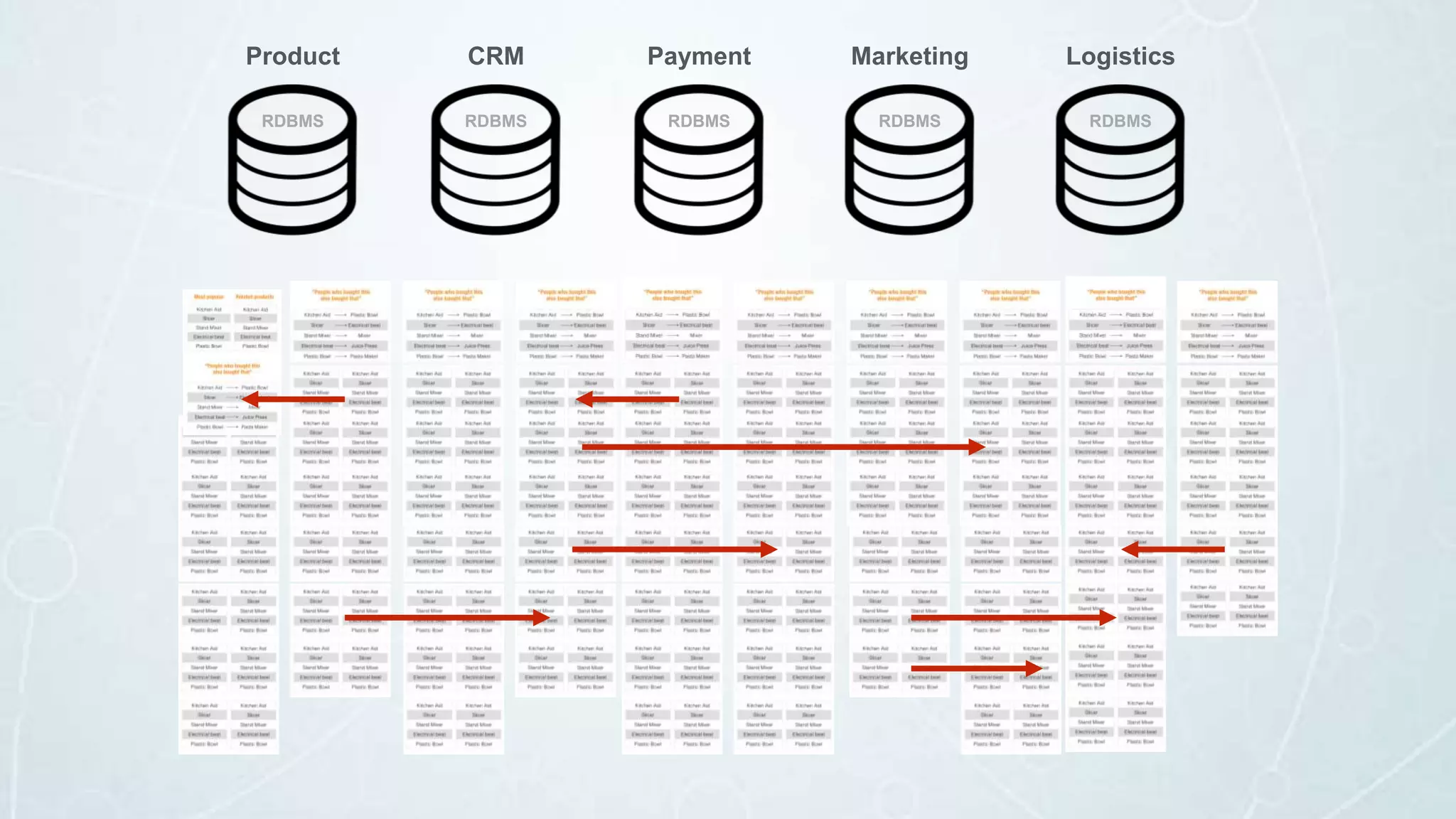
The document details a seminar in Washington D.C. focusing on how government agencies utilize the Neo4j graph database for various applications, including intelligence analysis and ecosystem modeling. It highlights the effectiveness of graph databases in handling complex, interconnected data and outlines use cases in law enforcement, fraud detection, and cybersecurity. Key speakers included Fred Kagan and David Mesa, addressing the growing significance of graph databases in data-driven decision-making within government operations.




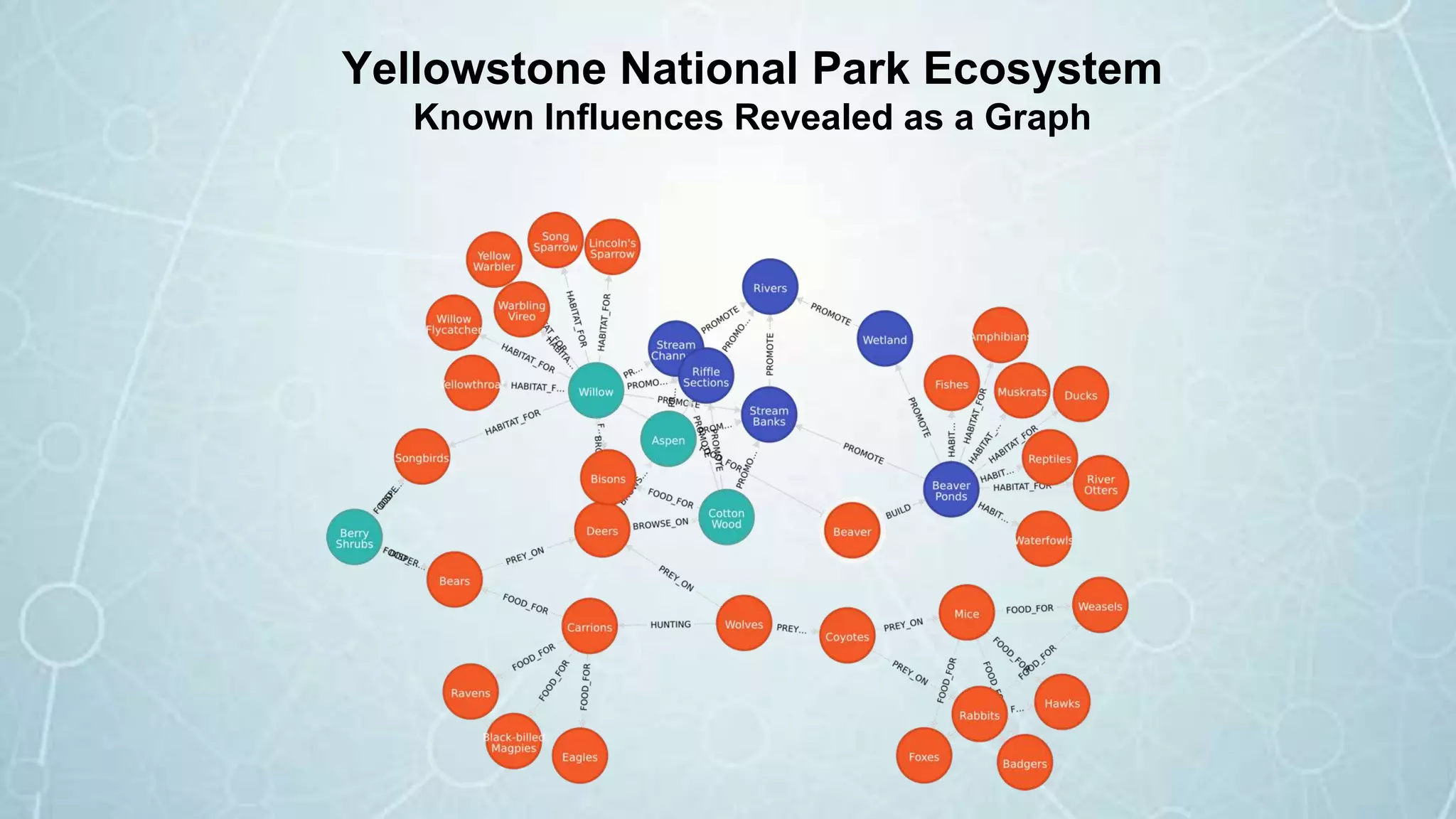
![Yellowstone National Park Ecosystem
Known Influences Entered One-at-a-Time
(Willow)-[:HABITAT_FOR]->(Lincoln’s Sparrow)
(Aspen)-[:FOOD_FOR]->(Beaver)
(Beaver Ponds)-[:HABITAT_FOR]->(Beaver)
(Deer)-[:BROWSE_ON]->(Cottonwood)
(Berry Shrubs)-[:FOOD_FOR]->(Bears)
…](https://image.slidesharecdn.com/washingtond-170301173801/75/The-Five-Graphs-of-Government-How-Federal-Agencies-can-Utilize-Graph-Technology-6-2048.jpg)
![MATCH path = (:Animal {Entity:"Wolves"})-[*]->(:Landscape {Entity:"Rivers"})
WITH extract(node IN nodes(path) | node.Yellowstone) AS factor, rand() AS number
RETURN factor AS How_Wolves_Affect_RiverStability
ORDER BY number
LIMIT 5
Yellowstone National Park Ecosystem
Query for Trophic Cascades
Conclusion:](https://image.slidesharecdn.com/washingtond-170301173801/75/The-Five-Graphs-of-Government-How-Federal-Agencies-can-Utilize-Graph-Technology-8-2048.jpg)








![MATCH (:Person { name:“Dan”} ) -[:MARRIED_TO]-> (spouse)
MARRIED_TO
Dan Ann
NODE RELATIONSHIP TYPE
LABEL PROPERTY VARIABLE
Magic Ingredient #2 of 3:
A Productive and Powerful Graph Query Language](https://image.slidesharecdn.com/washingtond-170301173801/75/The-Five-Graphs-of-Government-How-Federal-Agencies-can-Utilize-Graph-Technology-29-2048.jpg)
![3
3
Example HR Query in SQL The Same Query using Cypher
MATCH (boss)-[:MANAGES*0..3]->(sub),
(sub)-[:MANAGES*1..3]->(report)
WHERE boss.name = “John Doe”
RETURN sub.name AS Subordinate,
count(report) AS Total
Project Impact
Less time writing queries
• More time understanding the answers
• Leaving time to ask the next question
Less time debugging queries:
• More time writing the next piece of code
• Improved quality of overall code base
Code that’s easier to read:
• Faster ramp-up for new project members
• Improved maintainability & troubleshooting
Magic Ingredient #2 of 3:
A Productive and Powerful Graph Query Language](https://image.slidesharecdn.com/washingtond-170301173801/75/The-Five-Graphs-of-Government-How-Federal-Agencies-can-Utilize-Graph-Technology-30-2048.jpg)




![Predicting WWI
[Easley and Kleinberg]](https://image.slidesharecdn.com/washingtond-170301173801/75/The-Five-Graphs-of-Government-How-Federal-Agencies-can-Utilize-Graph-Technology-57-2048.jpg)