Download as PDF, PPTX








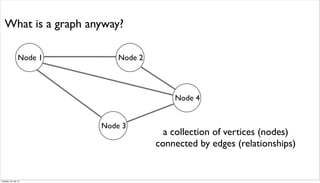
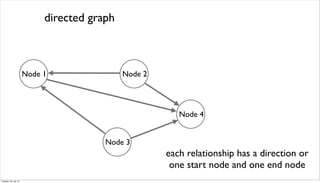



![an example graph
Node 1
me
Node 2
Steve
Node 3
Sam
Node 4
David
Node 5
Megan
me - [:knows] -> Steve -
[:knows] -> David
me - [:knows] -> Sam -
[:knows] -> Megan
Megan - [:knows] -> David
knows
knowsknows
knows
knows
Tuesday, 30 July 13](https://image.slidesharecdn.com/shutl-140415080745-phpapp02/85/Shutl-18-320.jpg)
![START me=node(1)
MATCH me-[:knows]->()-[:knows]->fof
RETURN fof
the query
Tuesday, 30 July 13](https://image.slidesharecdn.com/shutl-140415080745-phpapp02/85/Shutl-19-320.jpg)
![START me=node(1)
MATCH me-[:knows*2..]->fof
WHERE fof.name =~ 'Da.*'
RETURN fof
Tuesday, 30 July 13](https://image.slidesharecdn.com/shutl-140415080745-phpapp02/85/Shutl-20-320.jpg)
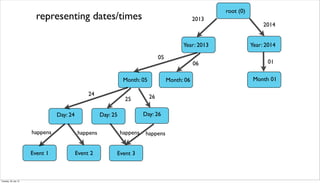
![find all events on a specific day
START root=node(0)
MATCH root-[:‘2013’]-()-[:’05’]-()-[:’24’]-()-
[:happens]-event
RETURN event
Tuesday, 30 July 13](https://image.slidesharecdn.com/shutl-140415080745-phpapp02/85/Shutl-22-320.jpg)


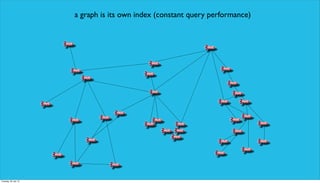
Shutl delivers with Neo4j by addressing issues with their previous MySQL database including exponential growth of joins, complex unmaintainable code, and slowing API response times. They chose Neo4j as a graph database because relationships are explicitly stored, domain modeling is simplified, and performance remains constant with growth. Queries in Neo4j use the Cypher language which focuses on pattern matching rather than implementation details.






































































