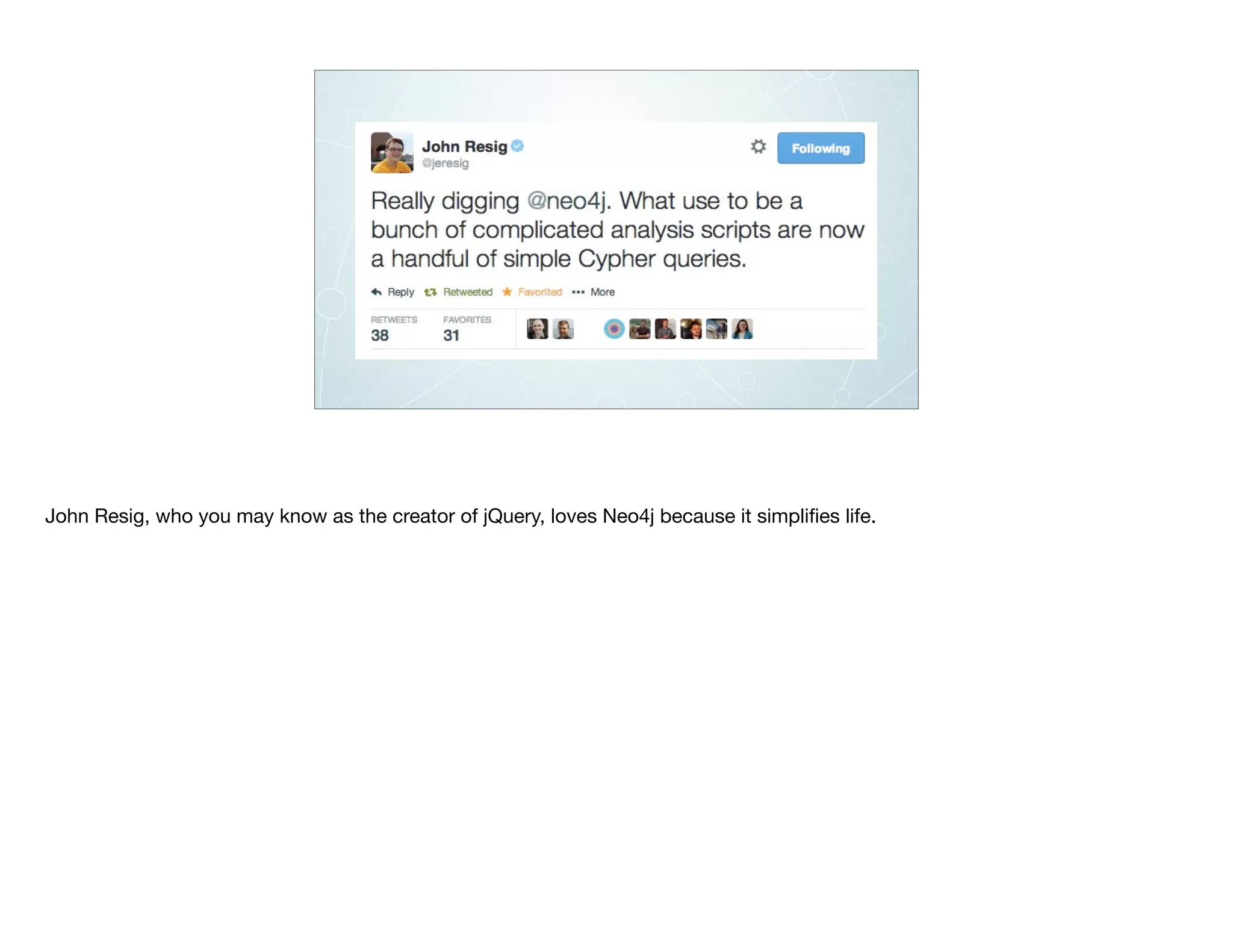
Download as PDF, PPTX








![Cypher
Typical Complex SQL Join The Same Query using Cypher
MATCH (boss)-[:MANAGES*0..3]->(sub),
(sub)-[:MANAGES*1..3]->(report)
WHERE boss.name = “John Doe”
RETURN sub.name AS Subordinate,
count(report) AS Total
Project Impact
Less time writing queries
Less time debugging queries
Code that’s easier to read
Less time writing queries
More time understanding the answers
Leaving time to ask the next question
Less time debugging queries:
More time writing the next piece of code
Improved quality of overall code base
Code that’s easier to read:
Faster ramp-up for new project members
Improved maintainability & troubleshooting](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-12-2048.jpg)





















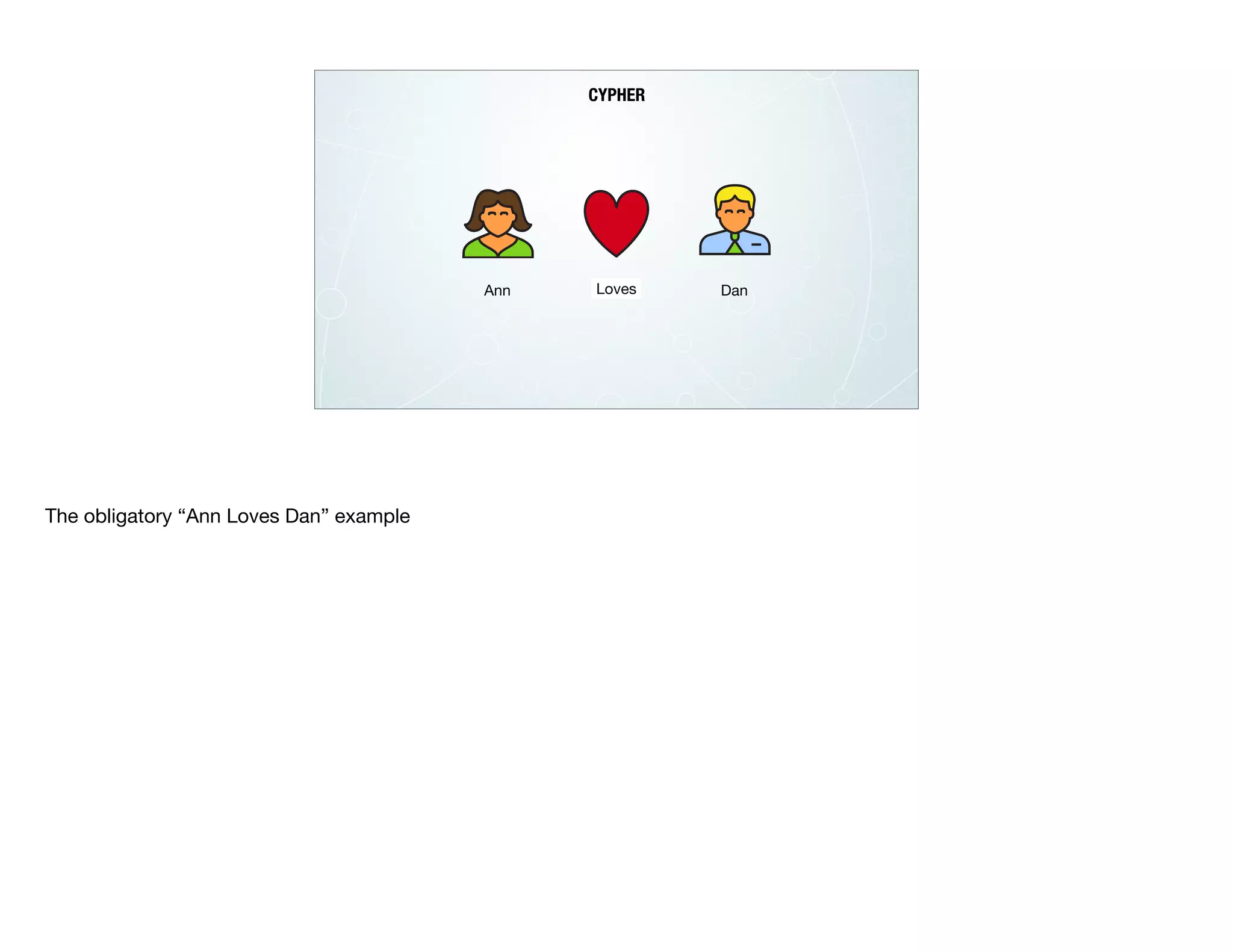
![Property Graph Model
CREATE (:Person { name:“Dan”} ) - [:LOVES]-> (:Person { name:“Ann”} )
LOVES
LABEL PROPERTY
NODE NODE
LABEL PROPERTY
The whiteboard model is the physical model.](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-50-2048.jpg)
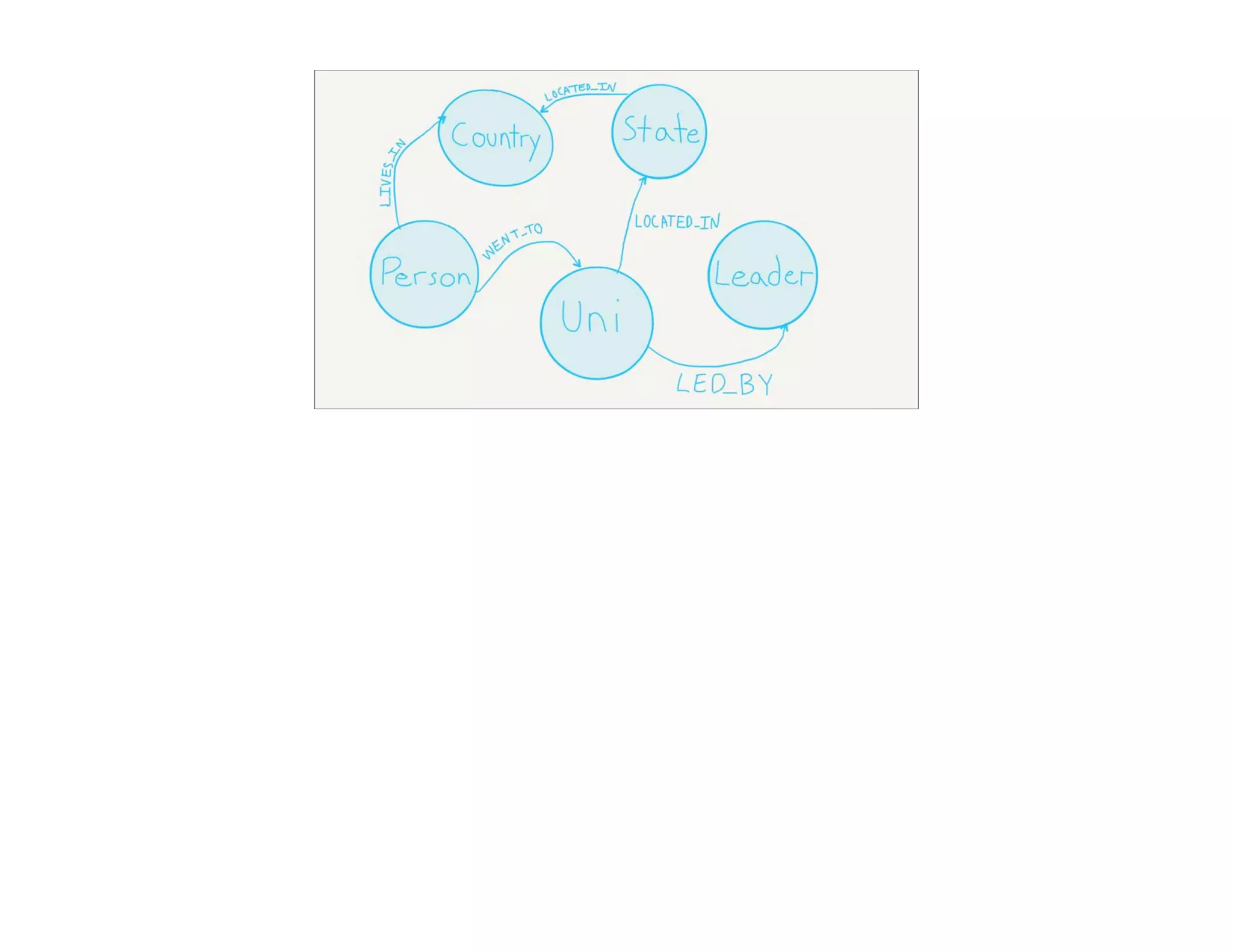
![MATCH
(p:Person)-[:WENT_TO]->(u:Uni),
(p)-[:LIVES_IN]->(c:Country),
(u)-[:LED_BY]->(l:Leader),
(u)-[:LOCATED_IN]->(s:State)
WHERE
s.abbr = ‘CT’
RETURN
p.name,
c.country, c.leader, p.hair,
u.name, l.name, s.abbr](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-52-2048.jpg)










![( )-[:TO]->(Graph)](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-69-2048.jpg)
![( )-[:IS_BETTER_AS]->(Graph)](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-71-2048.jpg)









![Property Graph Model
CREATE (:Employee{ firstName:“Steven”} ) -[:REPORTS_TO]-> (:Employee{ firstName:“Andrew”} )
REPORTS_TO
Steven Andrew
LABEL PROPERTY
NODE NODE
LABEL PROPERTY](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-82-2048.jpg)
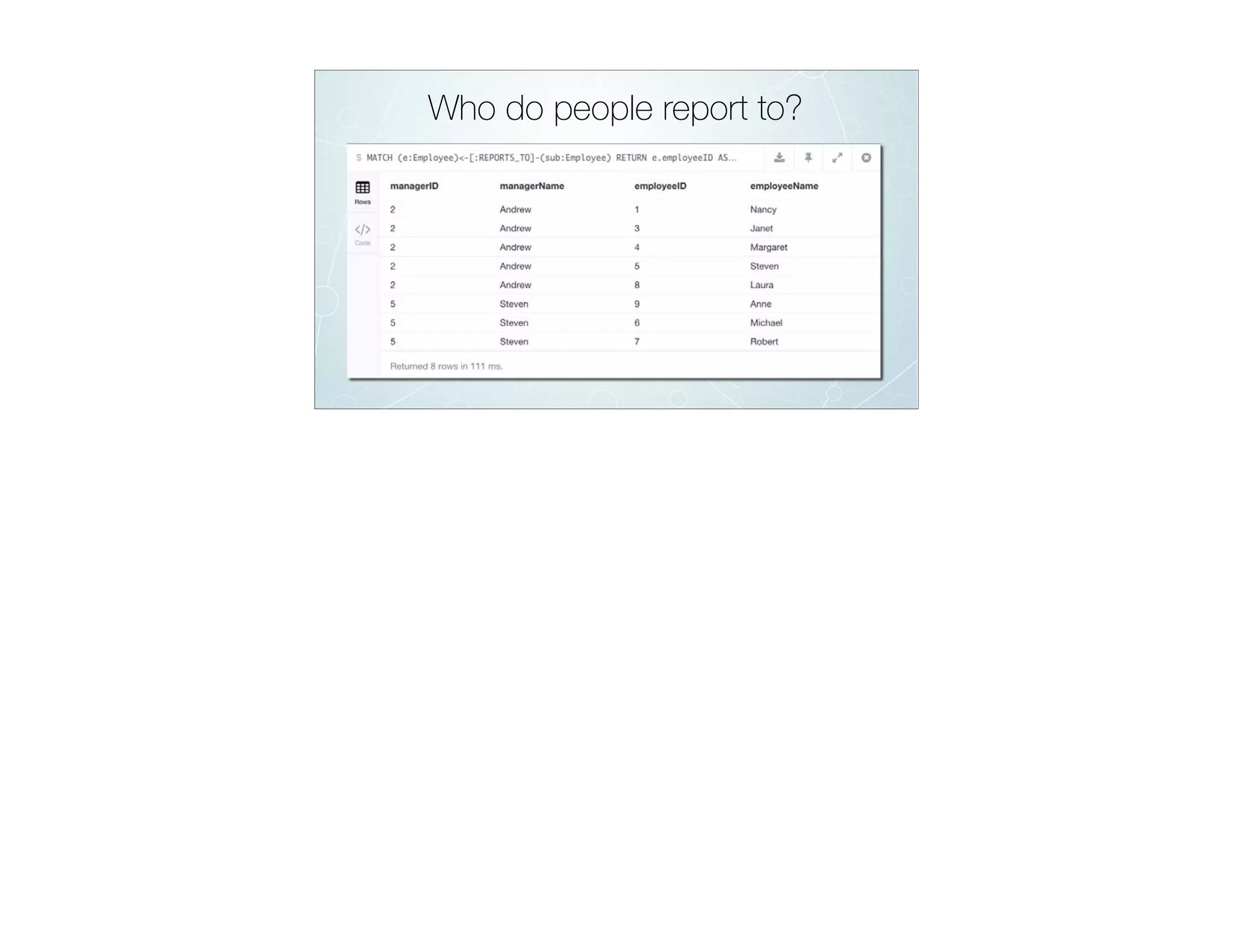
![Who do people report to?
MATCH
(e:Employee)<-[:REPORTS_TO]-(sub:Employee)
RETURN
*](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-83-2048.jpg)

![Who do people report to?
MATCH
(e:Employee)<-[:REPORTS_TO]-(sub:Employee)
RETURN
e.employeeID AS managerID,
e.firstName AS managerName,
sub.employeeID AS employeeID,
sub.firstName AS employeeName;
or alternatively as a table.](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-85-2048.jpg)
![Who does Robert report to?
MATCH
p=(e:Employee)<-[:REPORTS_TO]-(sub:Employee)
WHERE
sub.firstName = ‘Robert’
RETURN
p](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-87-2048.jpg)

![What is Robert’s reporting chain?
MATCH
p=(e:Employee)<-[:REPORTS_TO*]-(sub:Employee)
WHERE
sub.firstName = ‘Robert’
RETURN
p
But the power of the graph is in the ability to query arbitrary length paths.
See the asterisks.](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-89-2048.jpg)

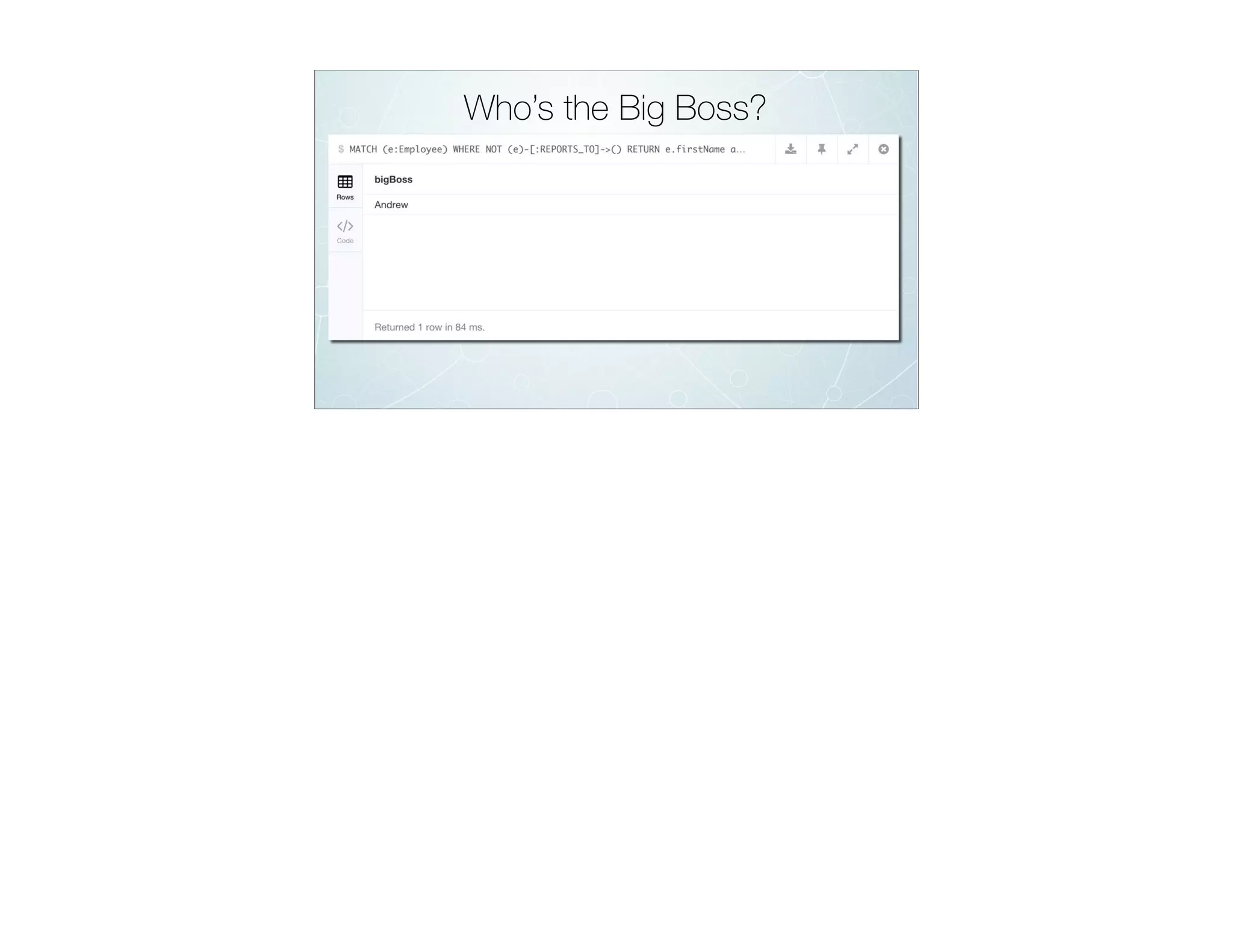
![Who’s the Big Boss?
MATCH
(e:Employee)
WHERE
NOT (e)-[:REPORTS_TO]->()
RETURN
e.firstName as bigBoss](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-91-2048.jpg)
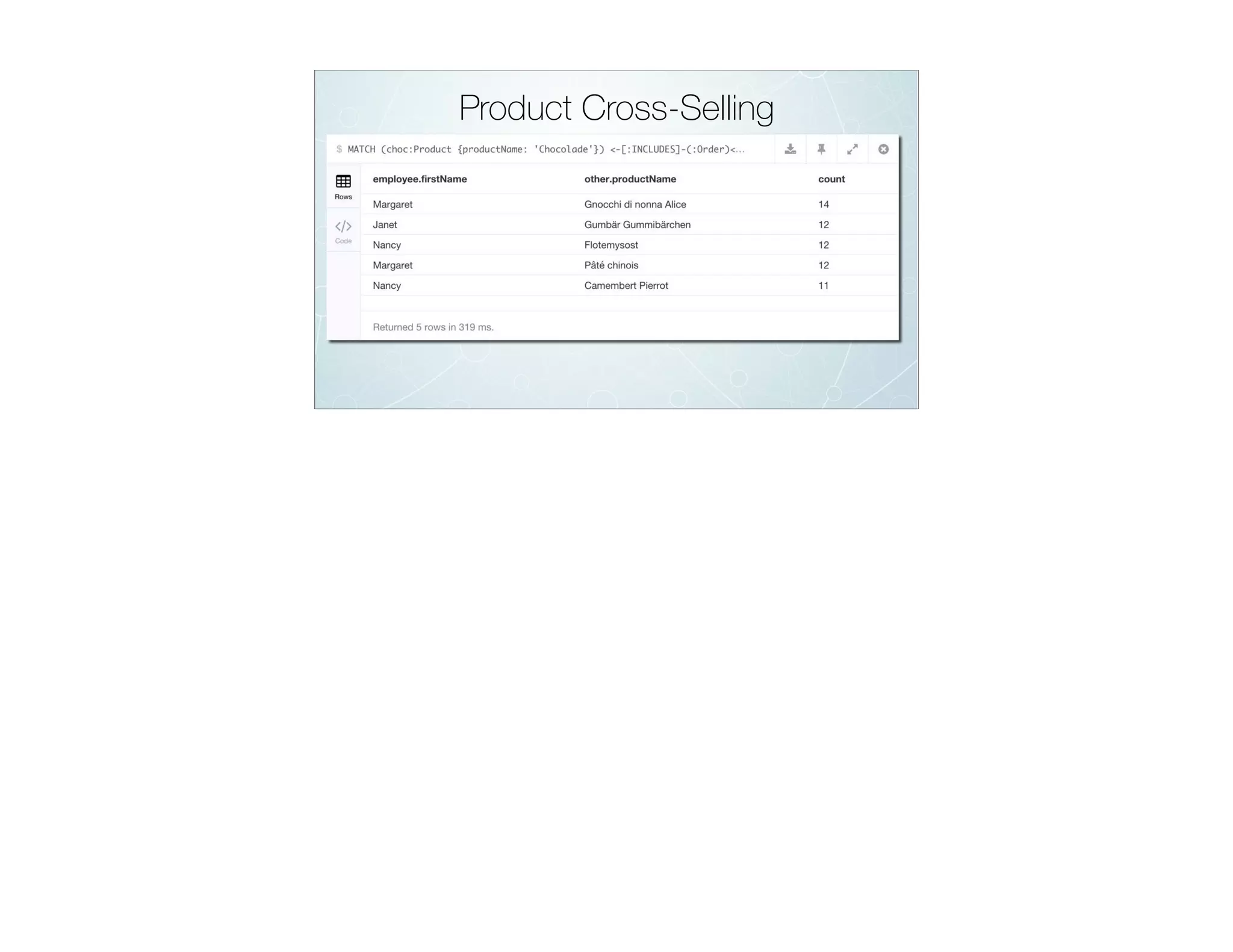
![Product Cross-Selling
MATCH
(choc:Product {productName: 'Chocolade'})
<-[:INCLUDES]-(:Order)<-[:SOLD]-(employee),
(employee)-[:SOLD]->(o2)-[:INCLUDES]->(other:Product)
RETURN
employee.firstName,
other.productName,
COUNT(DISTINCT o2) as count
ORDER BY
count DESC
LIMIT 5;](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-93-2048.jpg)

![Shortest Path Between Airports
MATCH
p = shortestPath(
(a:Airport {code:”SFO”})-[*0..2]->
(b:Airport {code: “MSO”}))
RETURN
p
Example using built-in algorithms.
Dijkstra also available for weighted paths](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-96-2048.jpg)















![Creating Relationships
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://
raw.githubusercontent.com/neo4j-contrib/developer-resources/
gh-pages/data/northwind/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (customer:Customer {customerID: row.CustomerID})
MERGE (customer)-[:PURCHASED]->(order);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://
raw.githubusercontent.com/neo4j-contrib/developer-resources/
gh-pages/data/northwind/products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (supplier:Supplier {supplierID: row.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-114-2048.jpg)
![Creating Relationships
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/neo4j-
contrib/developer-resources/gh-pages/data/northwind/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (product:Product {productID: row.ProductID})
MERGE (order)-[pu:INCLUDES]->(product)
ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity =
toFloat(row.Quantity);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/neo4j-
contrib/developer-resources/gh-pages/data/northwind/orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (employee:Employee {employeeID: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-115-2048.jpg)
![Creating Relationships
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/
neo4j-contrib/developer-resources/gh-pages/data/northwind/
products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (category:Category {categoryID: row.CategoryID})
MERGE (product)-[:PART_OF]->(category);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/
neo4j-contrib/developer-resources/gh-pages/data/northwind/
employees.csv" AS row
MATCH (employee:Employee {employeeID: row.EmployeeID})
MATCH (manager:Employee {employeeID: row.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);](https://image.slidesharecdn.com/rdbmstographwebinar-march2016-reduced-160311031007/75/RDBMS-to-Graph-Webinar-116-2048.jpg)



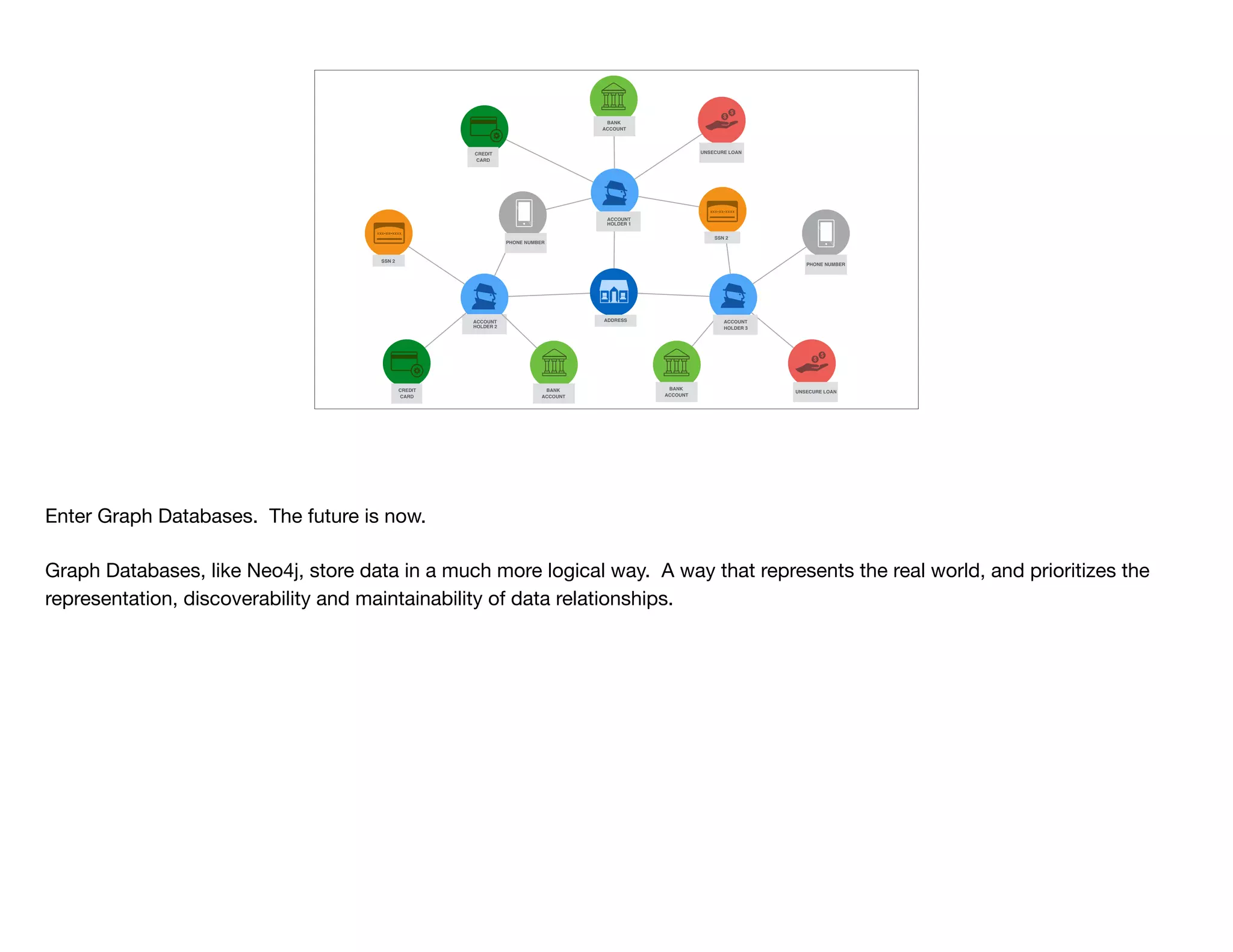
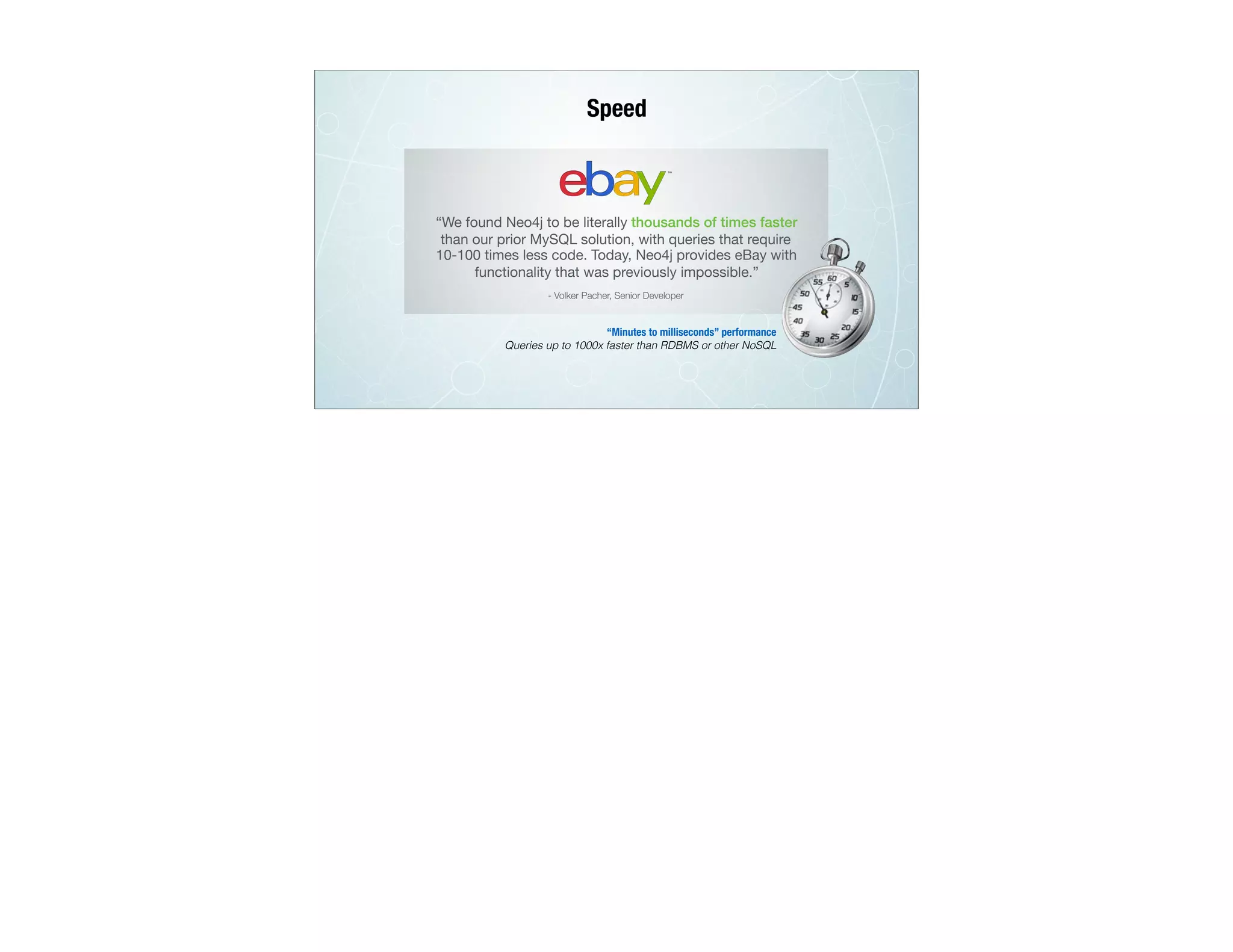
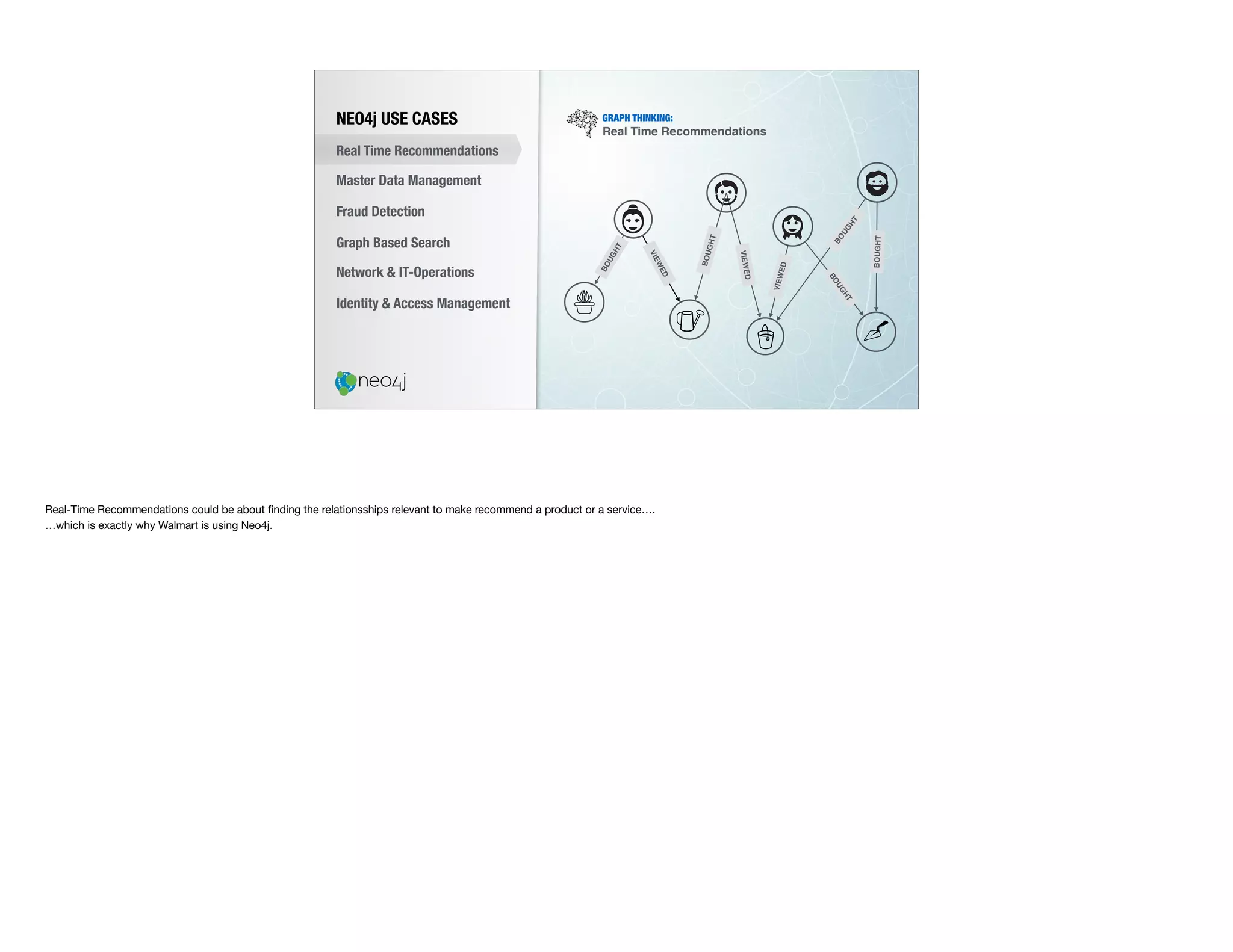
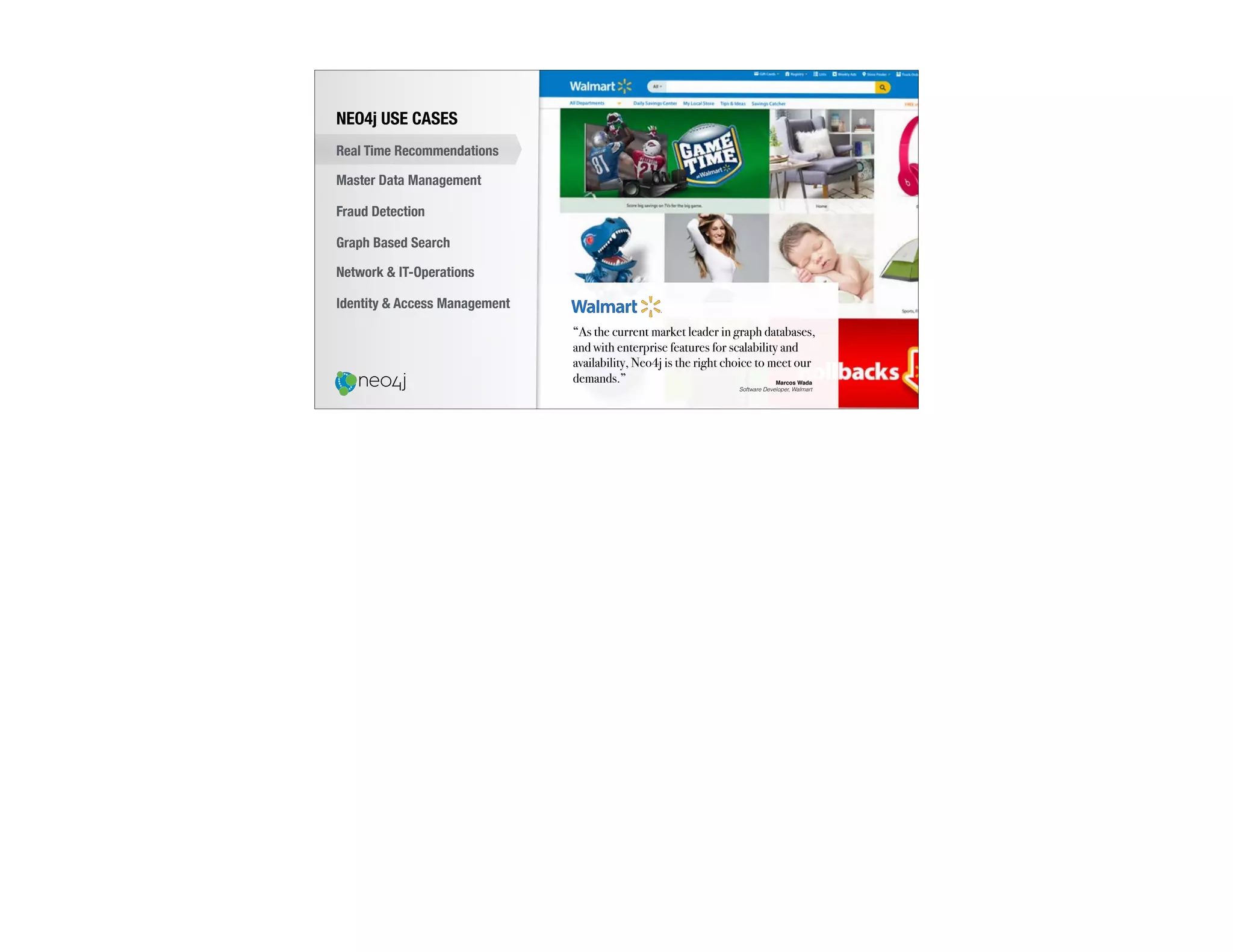
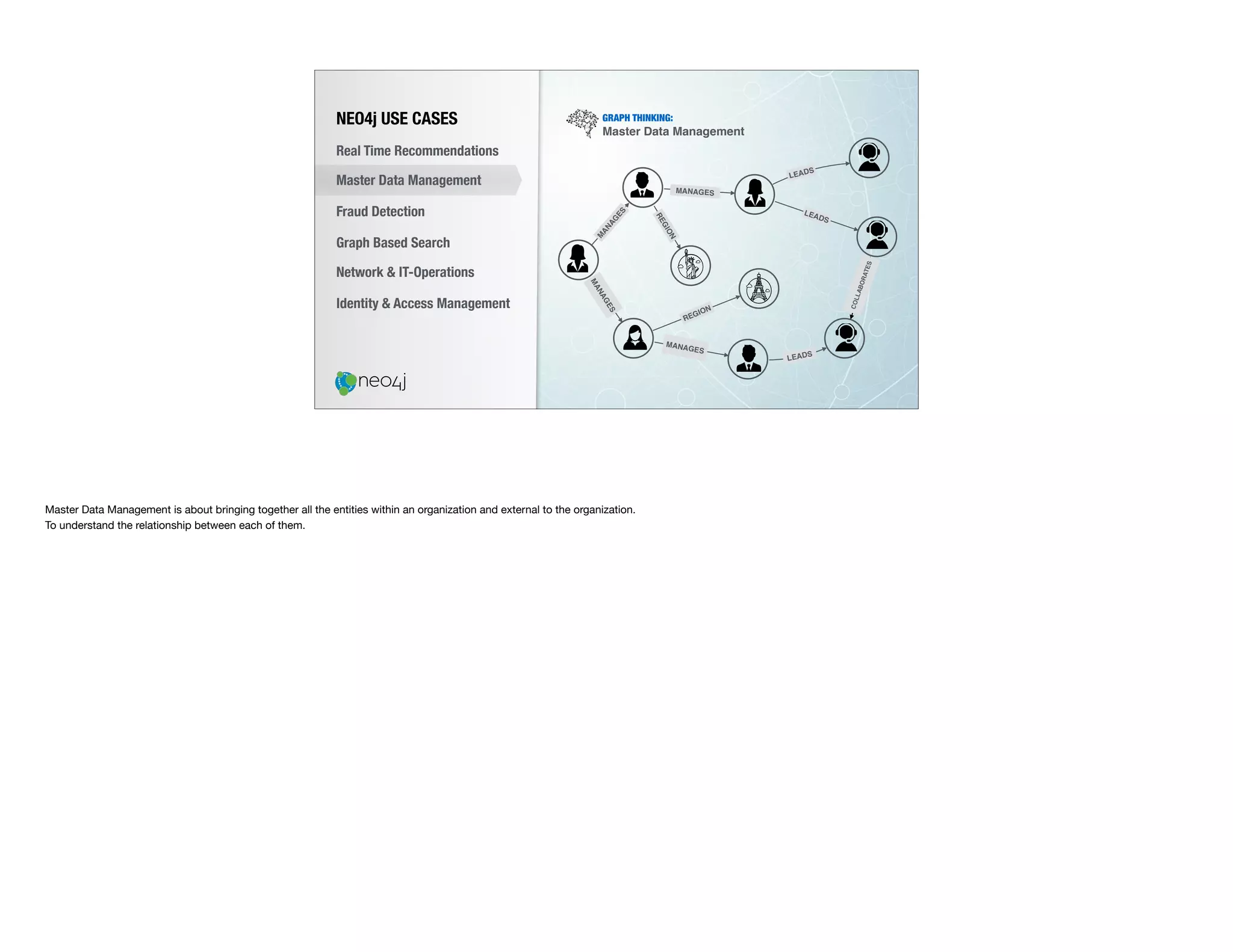
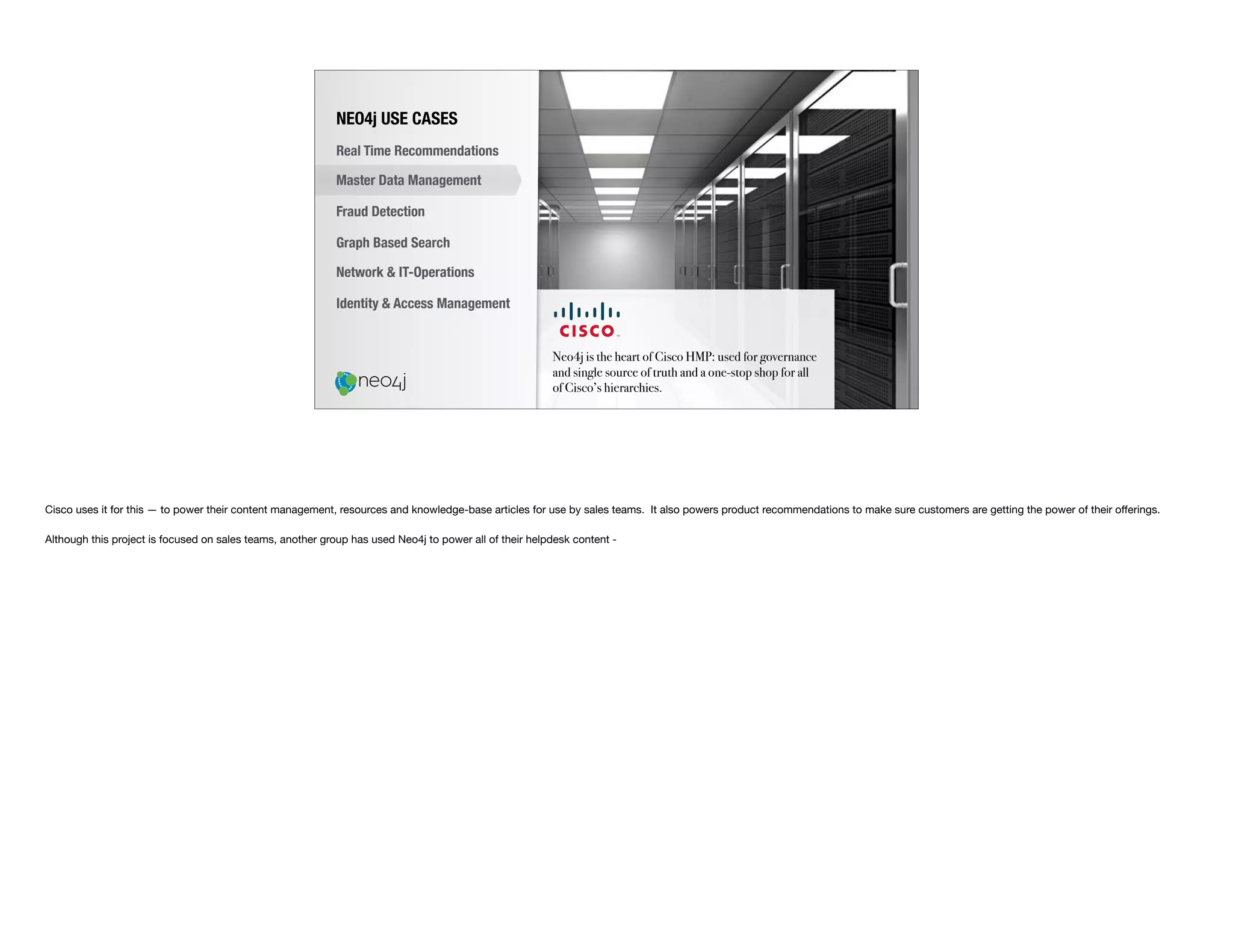
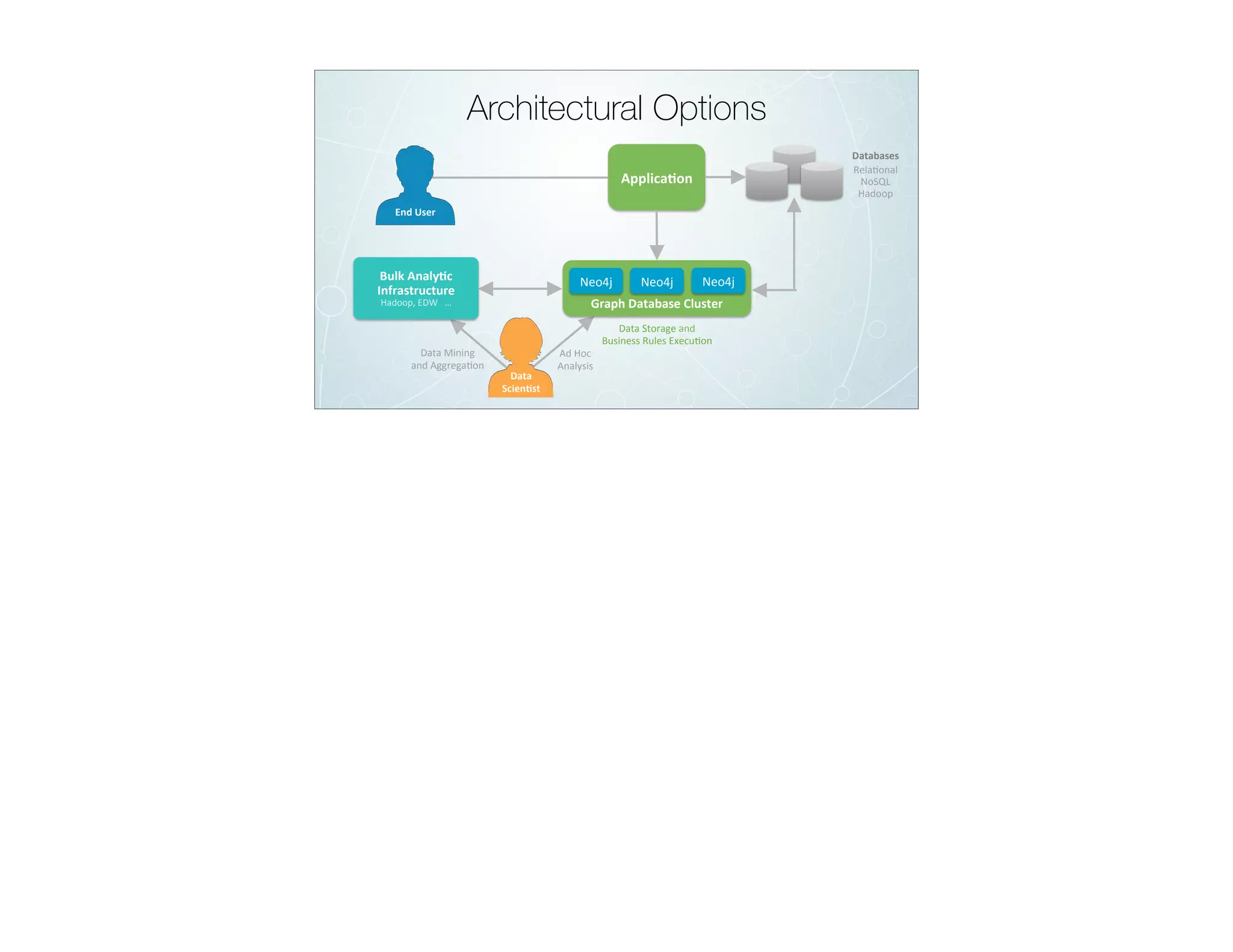
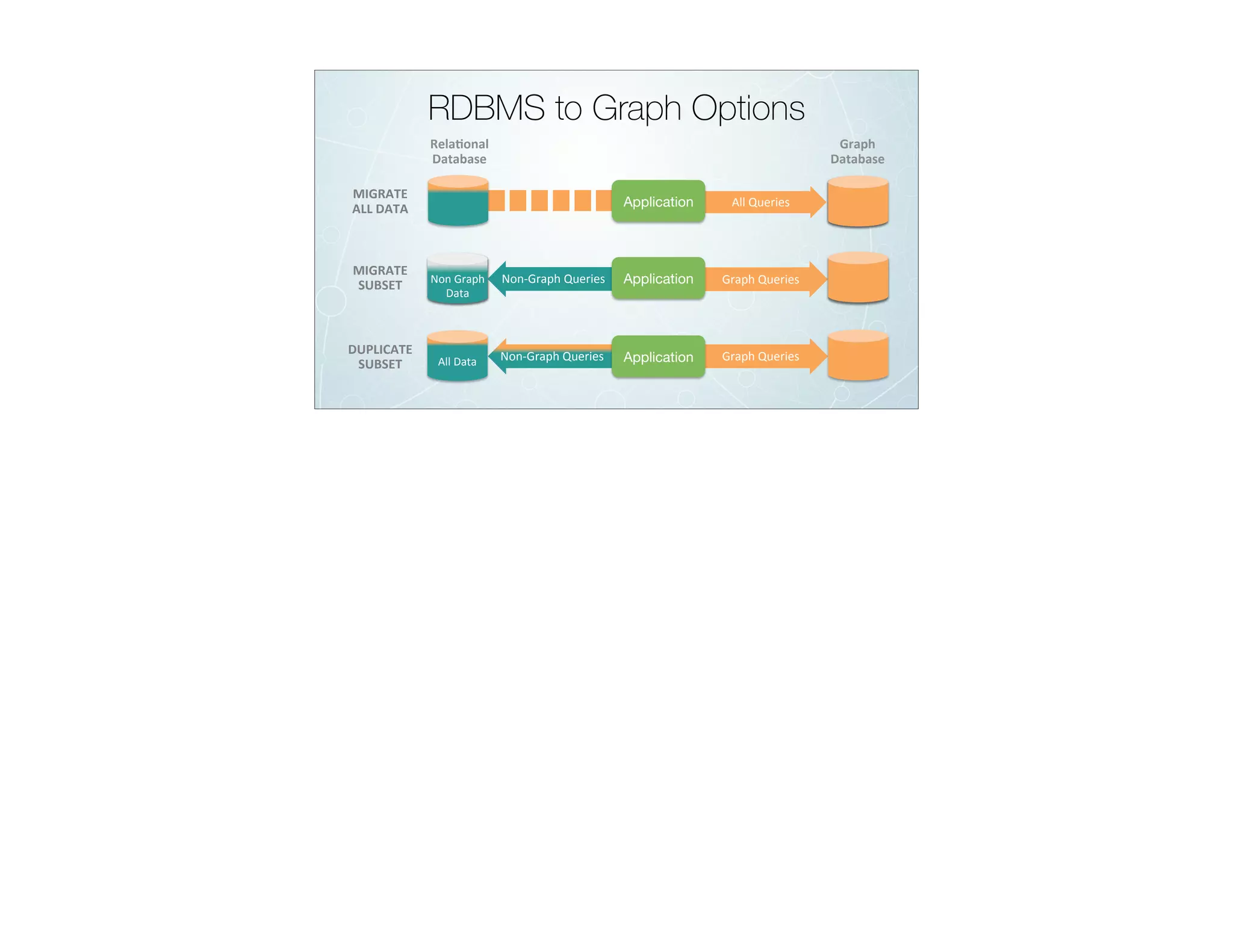
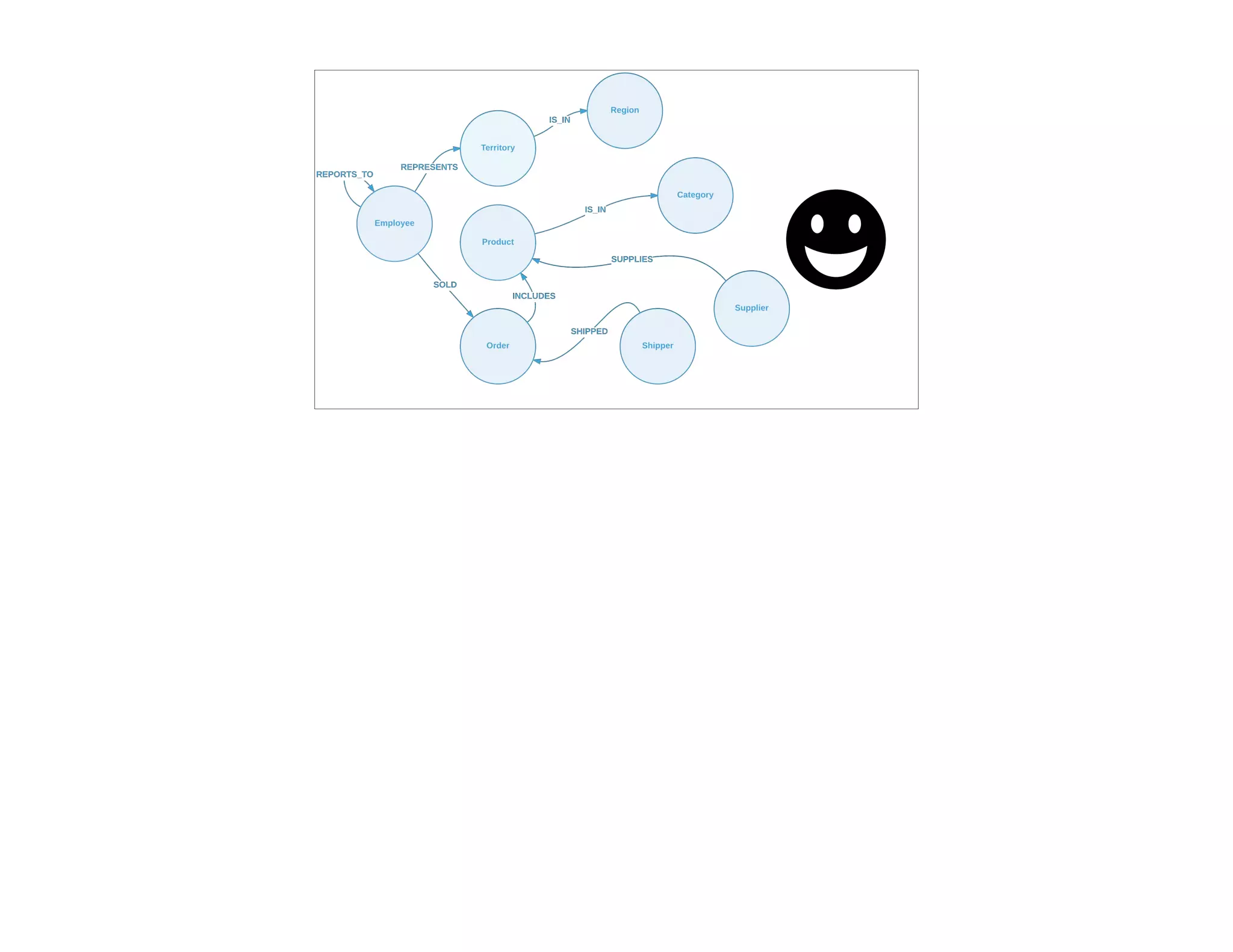
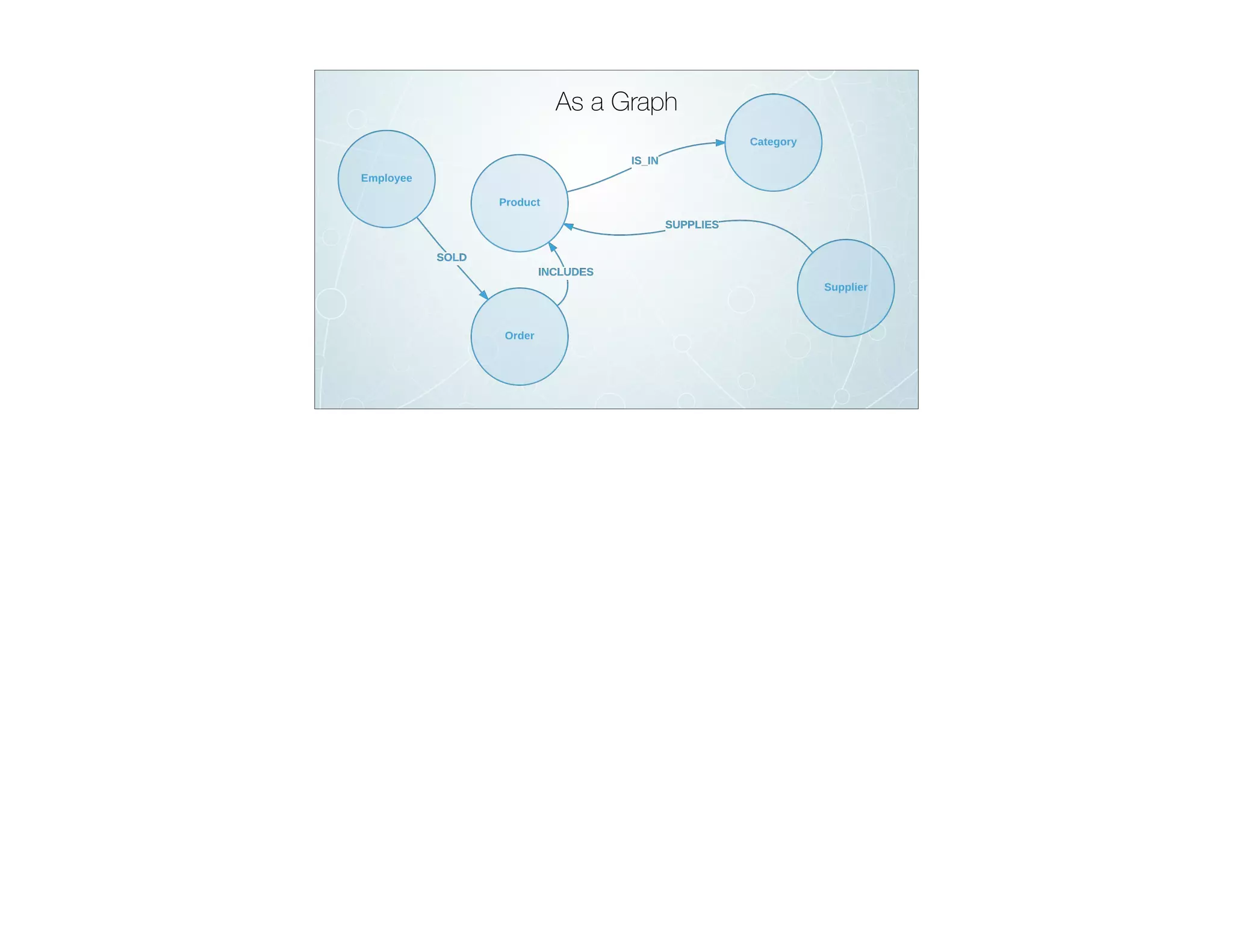
The document discusses the transition from traditional relational databases (RDBMS) to graph databases like Neo4j, highlighting the advantages such as improved data structuring, speed, and ease of querying complex relationships. It details the challenges of RDBMS, including the complexity of SQL joins and the inefficiency in managing relationships, contrasting this with the intuitive and agile querying capabilities of Neo4j. Various real-world use cases, including fraud detection and master data management, demonstrate the efficacy and growing adoption of graph databases in different industries.
















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














