Downloaded 28 times



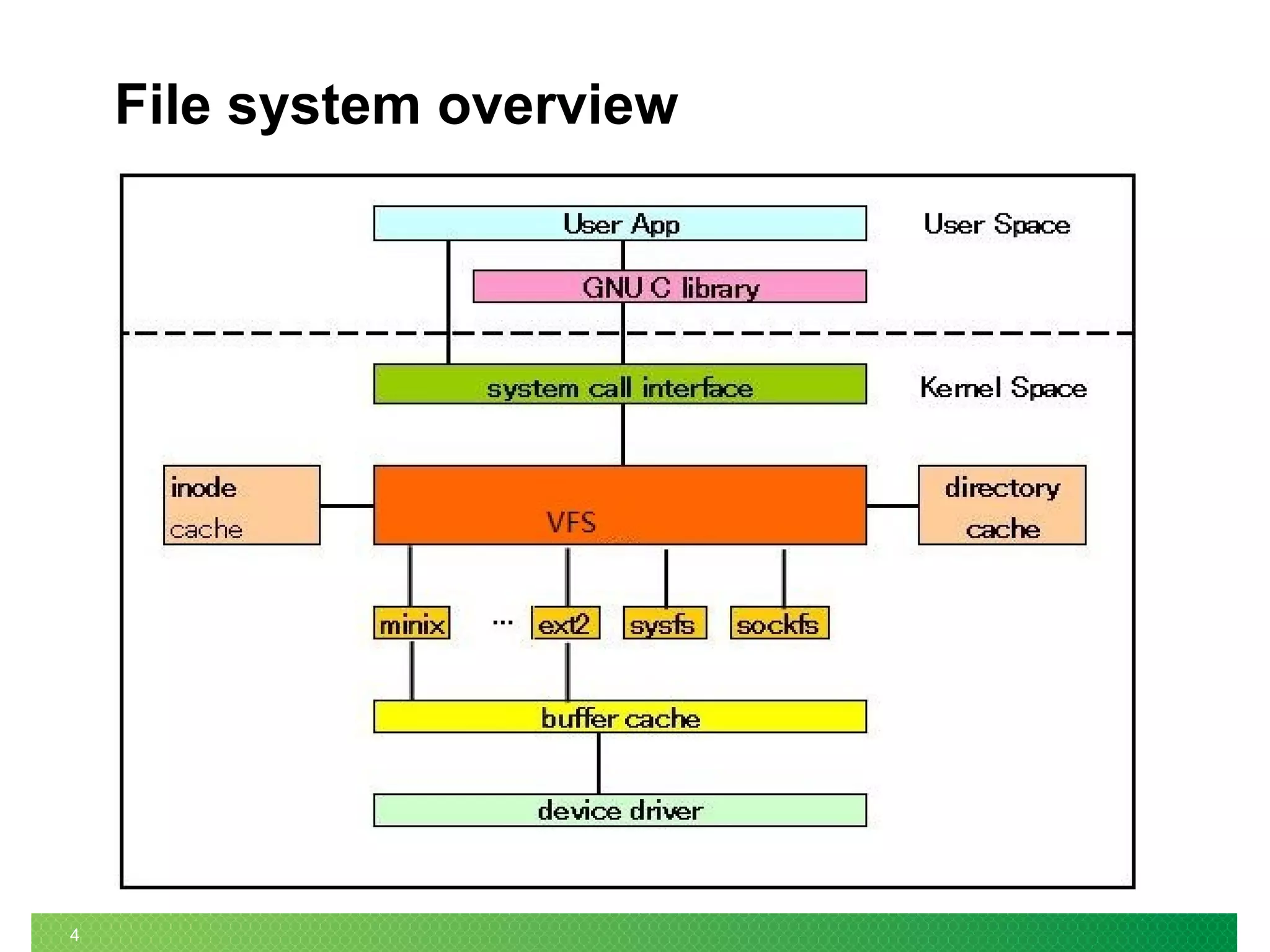
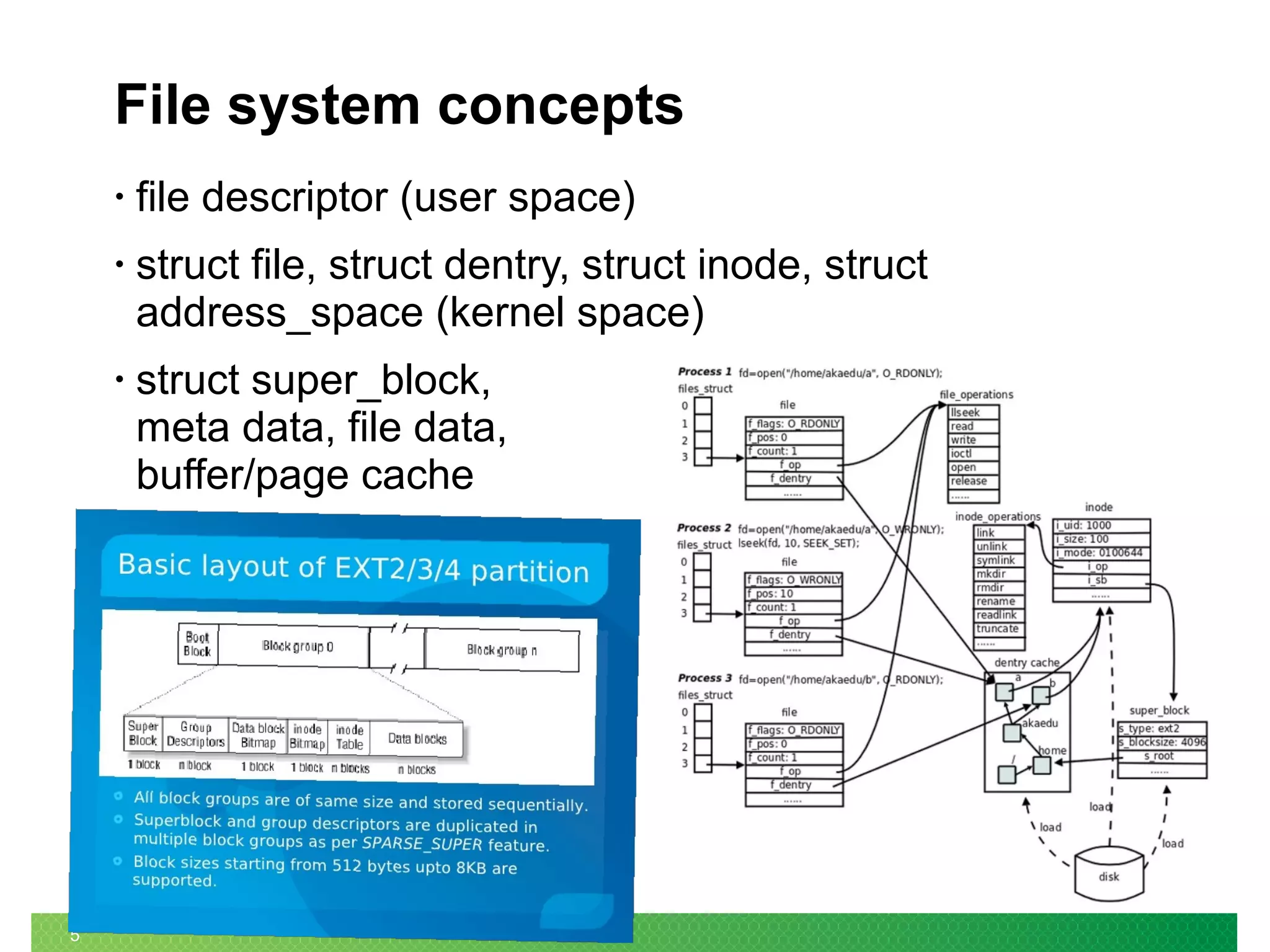



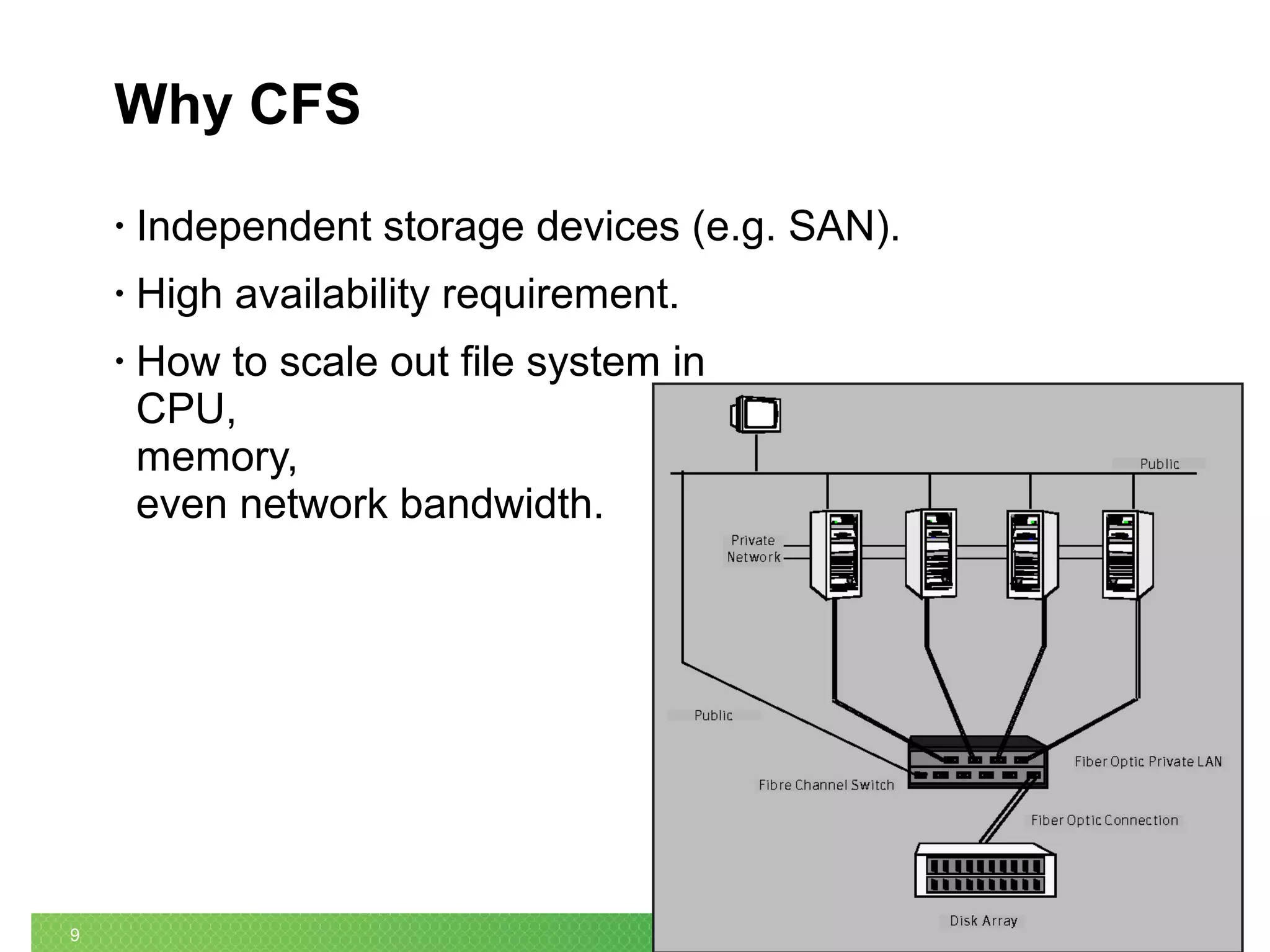




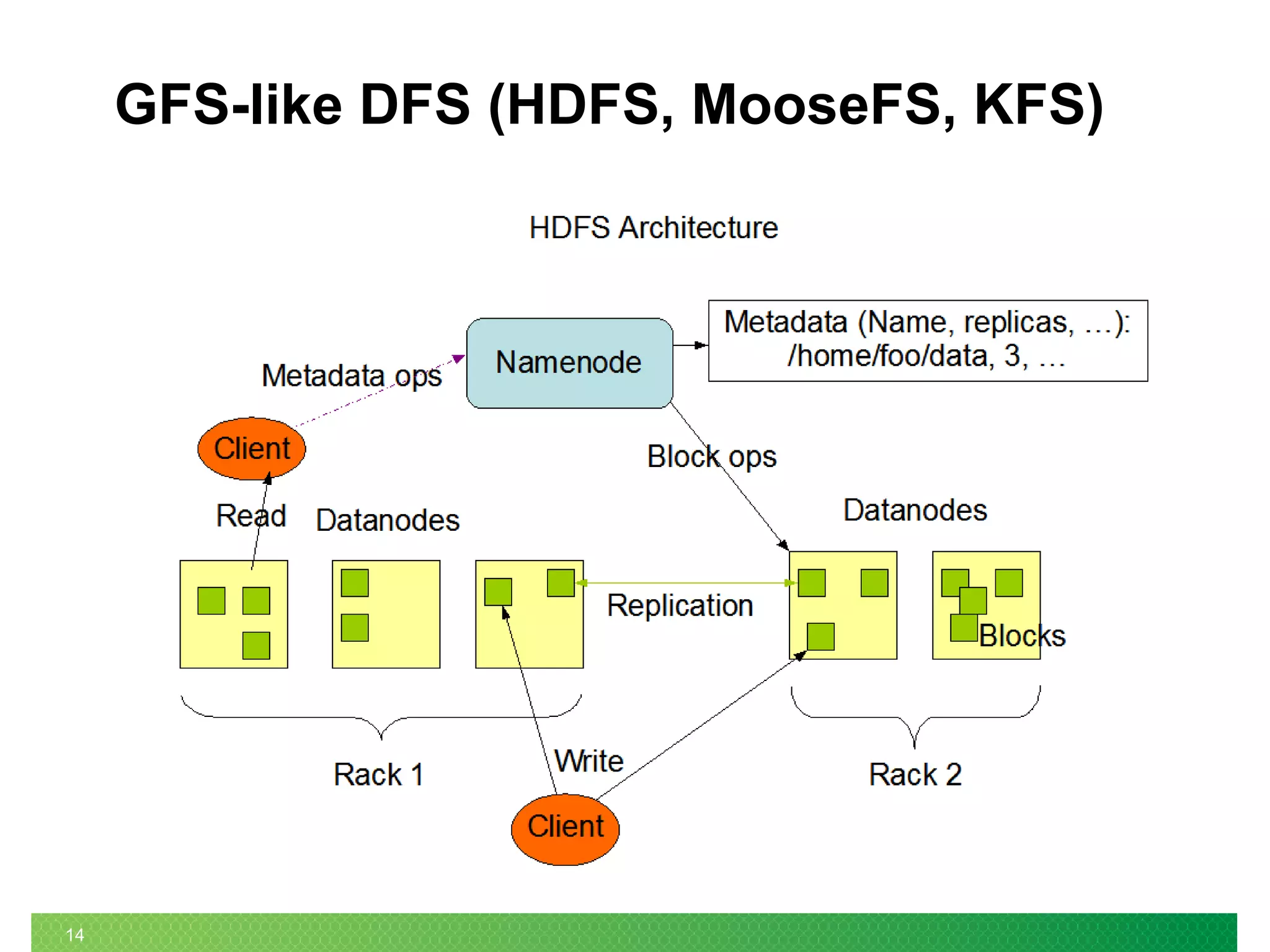





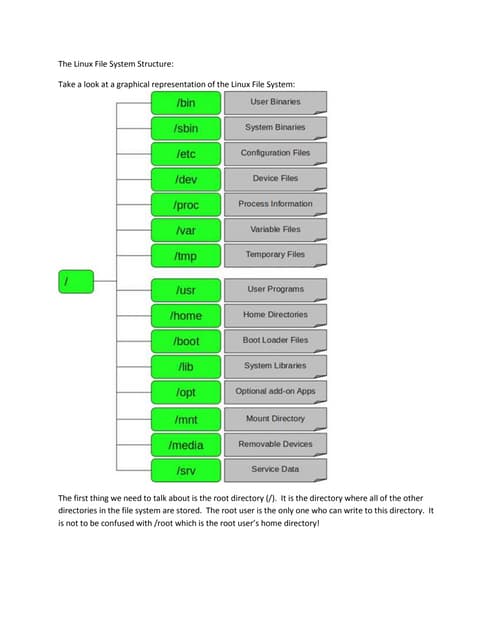
The document summarizes the evolution of Linux file systems from local to cluster to distributed systems. It discusses Ext2, Ext3, and Ext4 local file systems and improvements made to support larger file systems and reduce filesystem check times. It introduces cluster file systems used with shared storage for high availability and scaling compute and storage. Distributed file systems are described as scaling to unified storage across commodity hardware, with examples like HDFS based on the Google File System model with separate metadata and data servers. Current trends include further scaling out, flash technology use, and unified object/block/file storage.