Download as PDF, PPTX













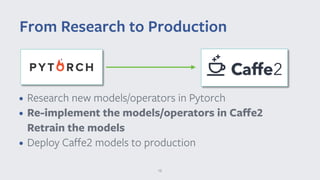















The document discusses the Caffe2 framework for mobile and embedded deep learning, highlighting its lightweight design optimized for performance across multiple platforms including Android and iOS. It addresses challenges in mobile fragmentation and the need for collaboration with vendors to enhance model performance, while also discussing strategies for benchmarking machine learning models. Caffe2's interoperability with other frameworks and its support for various hardware backends are emphasized as critical for production deployments.


















![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)




































































