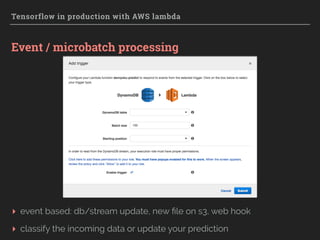
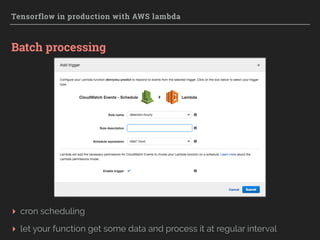
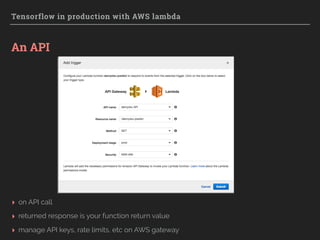
Downloaded 162 times













![Tensorflow in production with AWS lambda
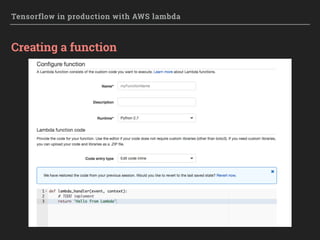
How to restore a TF model
▸ Restore the graph and variable values with a saver object
saver = tf.train.import_meta_graph(filename + '.meta')
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, filename)
pred = tf.get_collection('output')[0]
x = tf.get_collection('input')[0]
print("Model restored.")
# Do some work with the model
prediction = pred.eval({x: test_data})
python](https://image.slidesharecdn.com/tflambda-160915145842/85/Tensorflow-in-production-with-AWS-Lambda-20-320.jpg)

![Tensorflow in production with AWS lambda
A tensorflow calling lambda function
▸ Accepts a list of input vectors: multiple predictions
▸ Returns a list of predictions
import tensorflow as tf
filename = 'model-name.ckpt'
def lambda_handler(event, context):
saver = tf.train.import_meta_graph(filename + '.meta')
inputData = event['data']
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, filename)
pred = tf.get_collection('pred')[0]
x = tf.get_collection('x')[0]
# Apply the model to the input data
predictions = pred.eval({x: inputData})
return {'result': predictions.tolist()}
python](https://image.slidesharecdn.com/tflambda-160915145842/85/Tensorflow-in-production-with-AWS-Lambda-22-320.jpg)
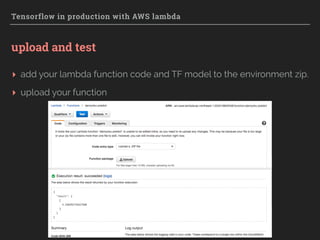



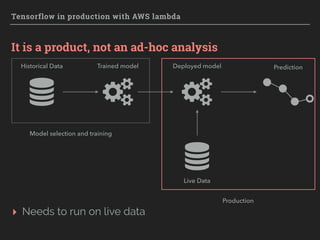
The document explores the integration of TensorFlow with AWS Lambda for deploying machine learning models in production, emphasizing scalability, resilience, and ease of maintenance. It discusses various deployment strategies, such as event-driven and batch processing, and provides practical steps for setting up a TensorFlow model environment on AWS. Key considerations include the absence of GPU support, model loading times, and infrastructure management cost reduction through serverless architecture.






























































