Downloaded 15 times


















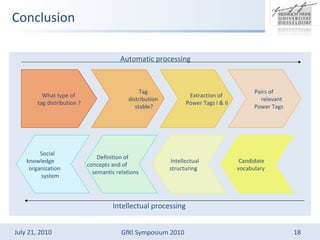



The document discusses social classification based on folksonomies, highlighting the importance of power tags derived from user-generated tagging. It outlines methods for automatically building social classifications and evaluating the relevance of tags, identifying issues such as subjective judgments in tag relevance. The study emphasizes that tag distributions stabilize over time, allowing for the effective extraction of relevant tags for categorization.





















































