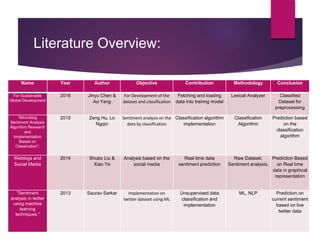
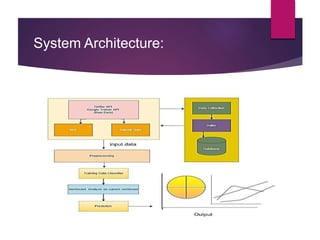
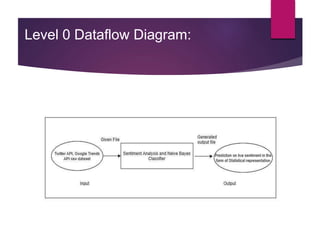
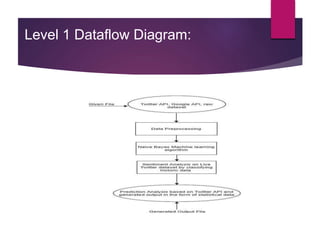
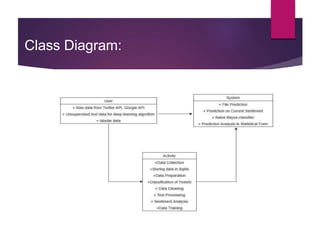
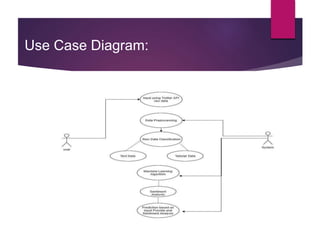
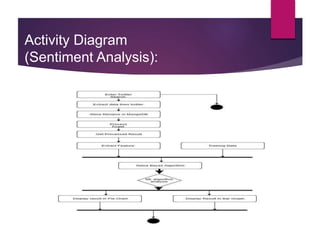
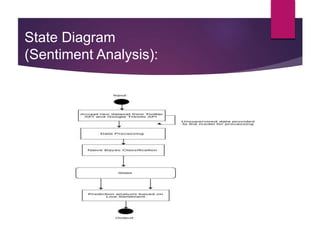
The document describes a project aimed at predicting political outcomes using text mining and deep learning on live Twitter data. It highlights the limitations of existing systems and proposes a new approach that combines sentiment analysis, data preprocessing, and machine learning techniques for real-time prediction. The system is designed to generate statistical reports and visualize trends, providing insights into public opinions on political leaders and activities.











![References :
1 Alexander Pak and Patrick Paroubek. "Twitter as a corpus for sentiment analysis and opinion mining". In
Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), may
2010.
2 Y. Yang and F. Zhou, "Microblog Sentiment Analysis Algorithm Research and Implementation Based on
Classication", 2015 14th International Symposium on Distributed Computing and Applications for Business
Engineering and Science (DCABES) ,2015.
3 P. D. Turney, "Thumbs up or thumbs down?: semantic orientationapplied to unsupervised classication of
reviews," presented at theProceedings of the 40th Annual Meeting on Association for Computational Linguistics,
Philadelphia, Pennsylvania,2002.
4 M. Taboada, J. Brooke, M. Toloski, K. Voll, and M. Stede,"Lexiconbased methods for sentiment analysis,"
Comput. Linguist., vol. 37, pp. 267-307, 2011.
5 "The Streaming APIs | Twitter Developers", dev.twitter.com, 2016. [Online]. Available:
https://dev.twitter.com/streaming/overview. [Accessed: 25-Apr- 2016].
6 Neethu, M. S., and R. Rajasree. "Sentiment analysis in twitter using machine learning techniques."
Computing, Communications and Networking Technologies (ICCCNT), 2013 Fourth International Conference
on. IEEE, 2013.](https://image.slidesharecdn.com/politicalpredictionanalysisusingtextmininganddeeplearning-200211154817/85/Political-prediction-analysis-using-text-mining-and-deep-learning-20-320.jpg)


































































