Download to read offline


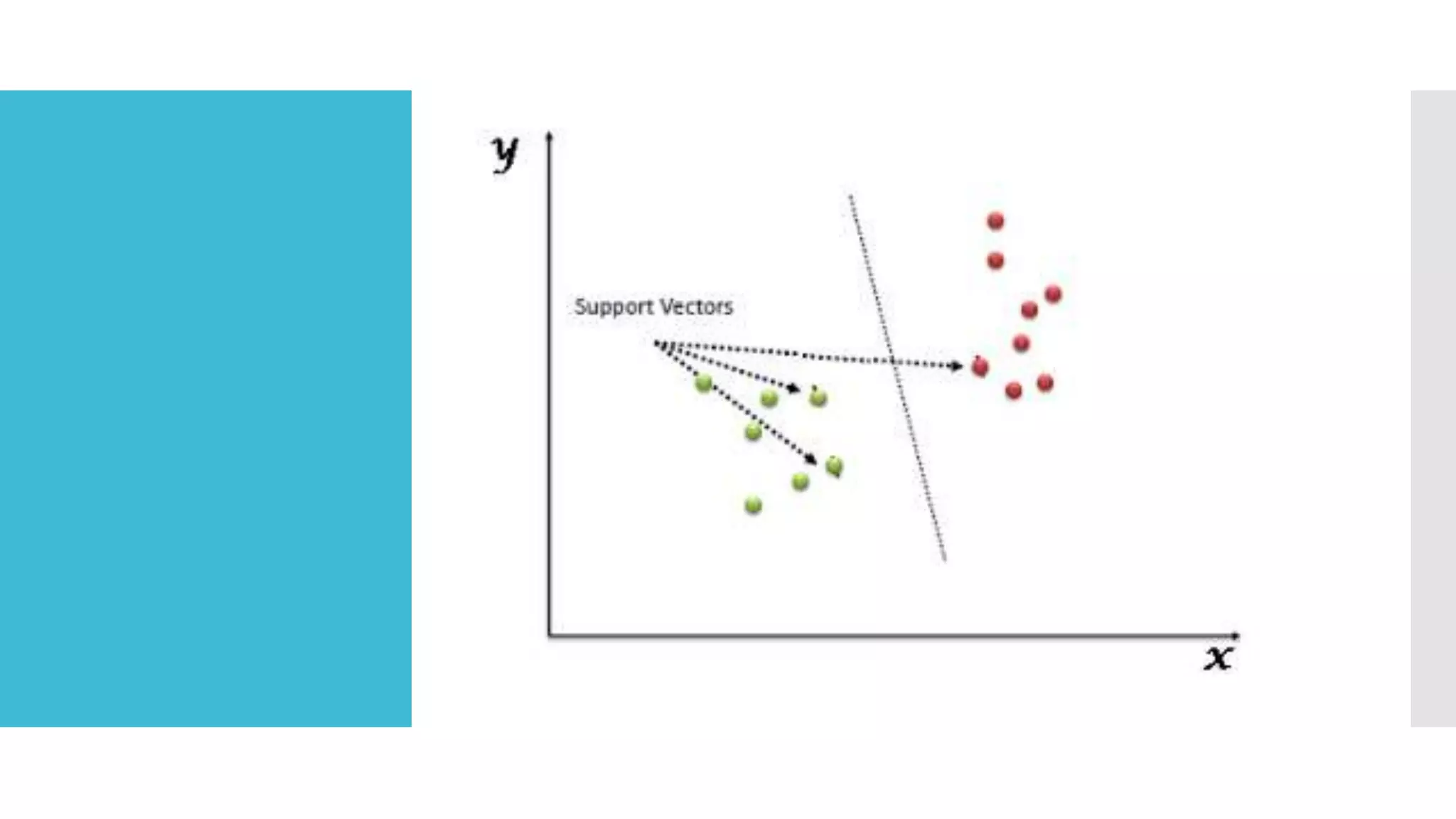

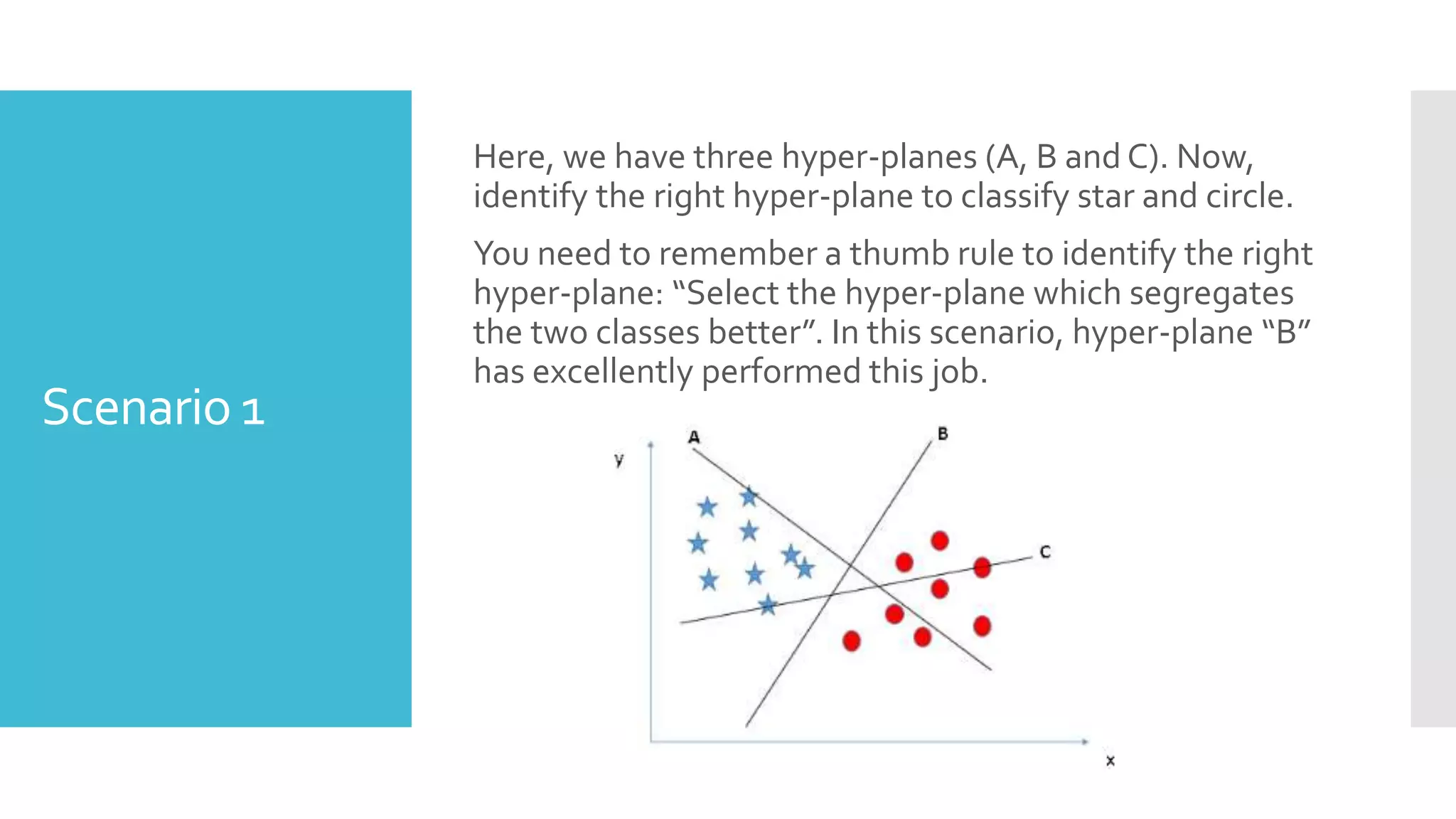
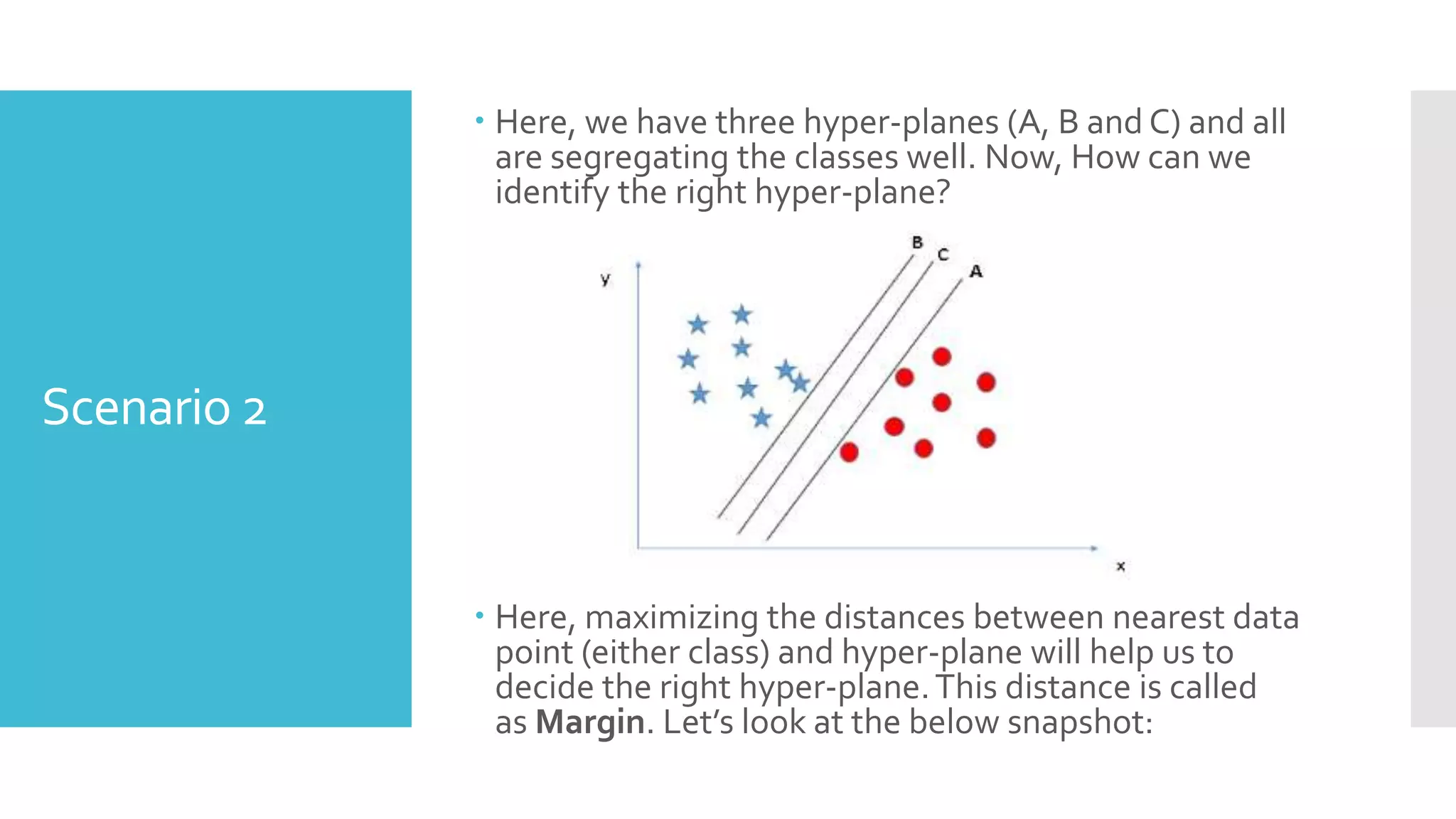
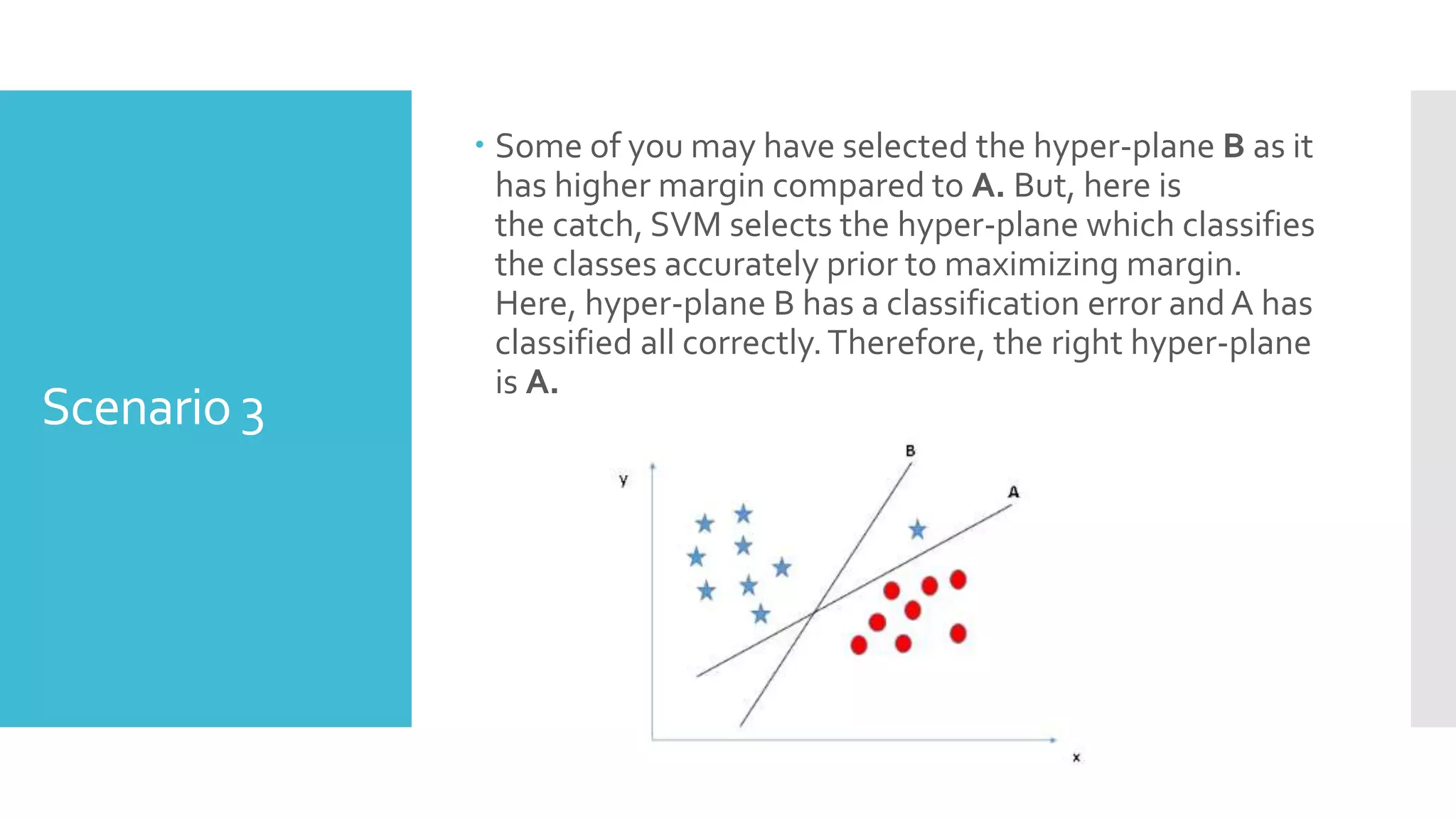
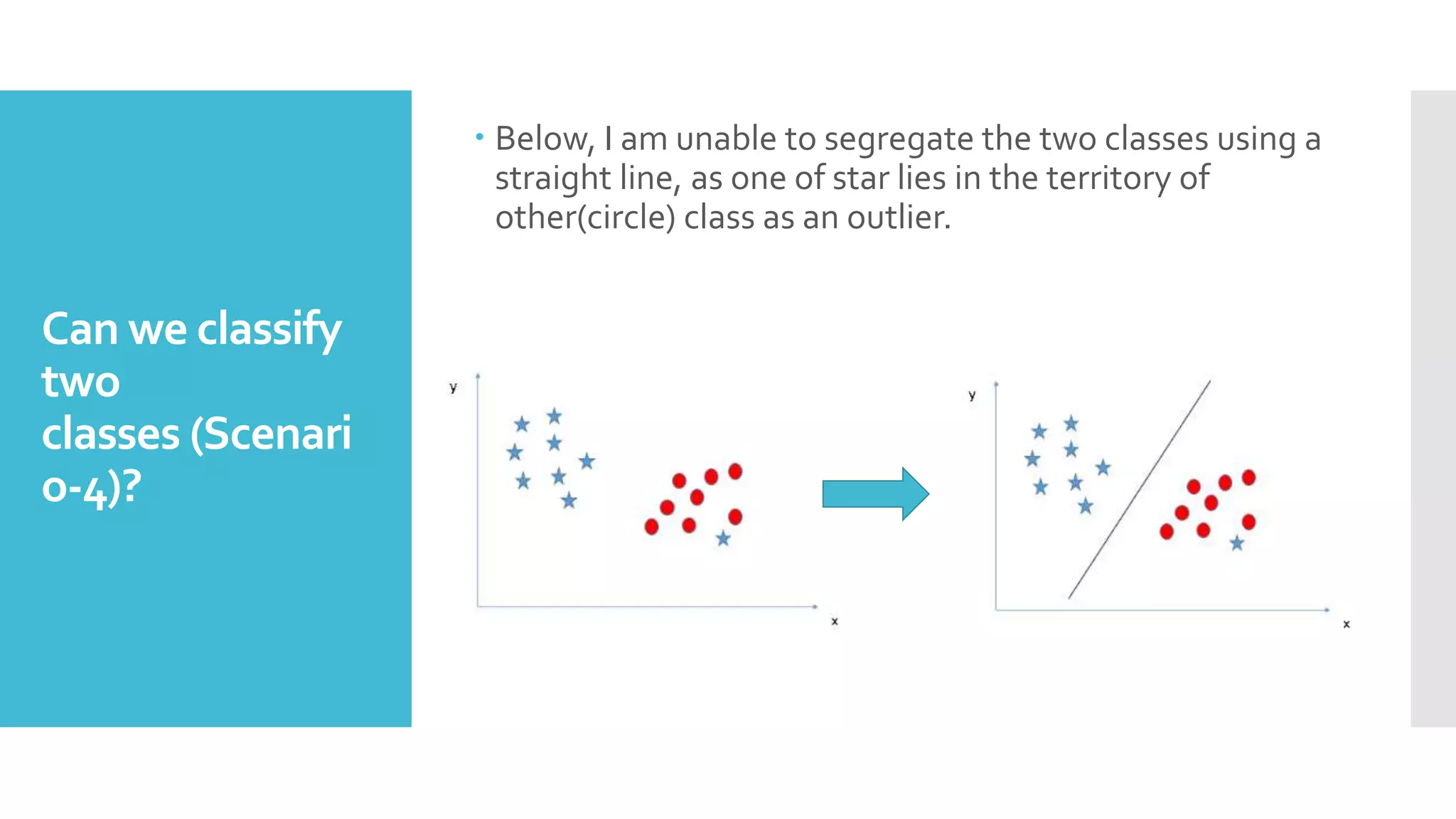
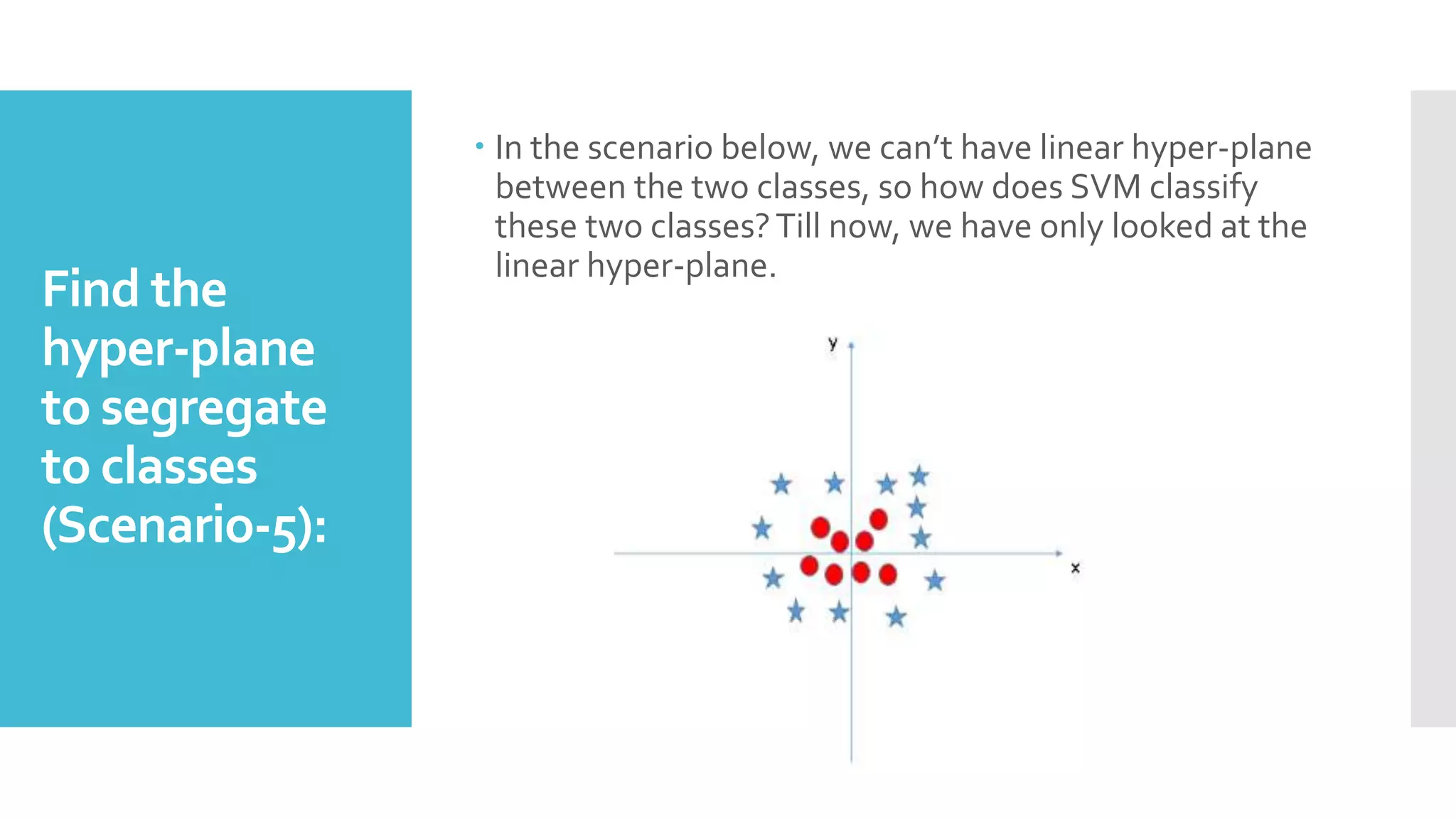
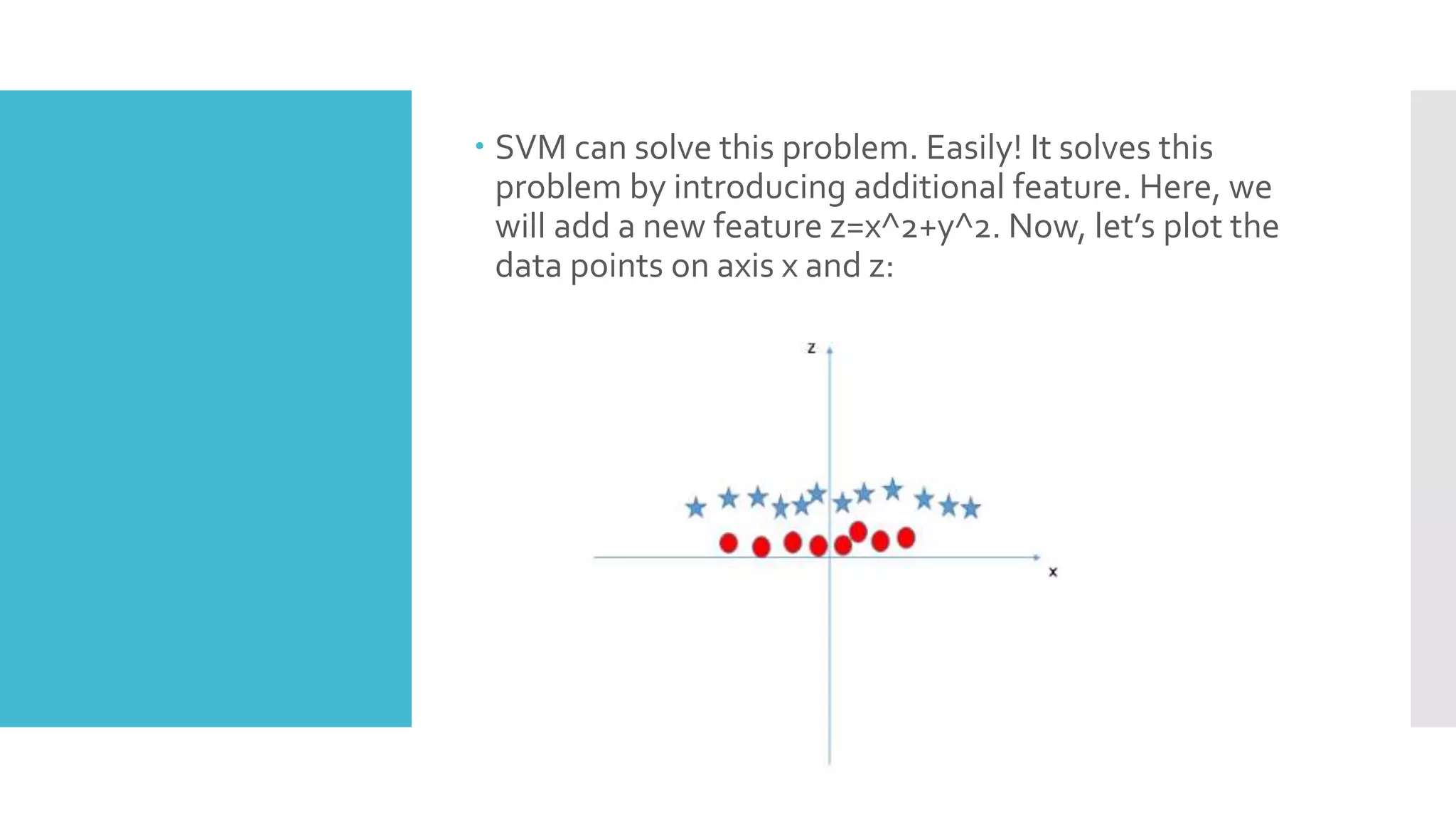




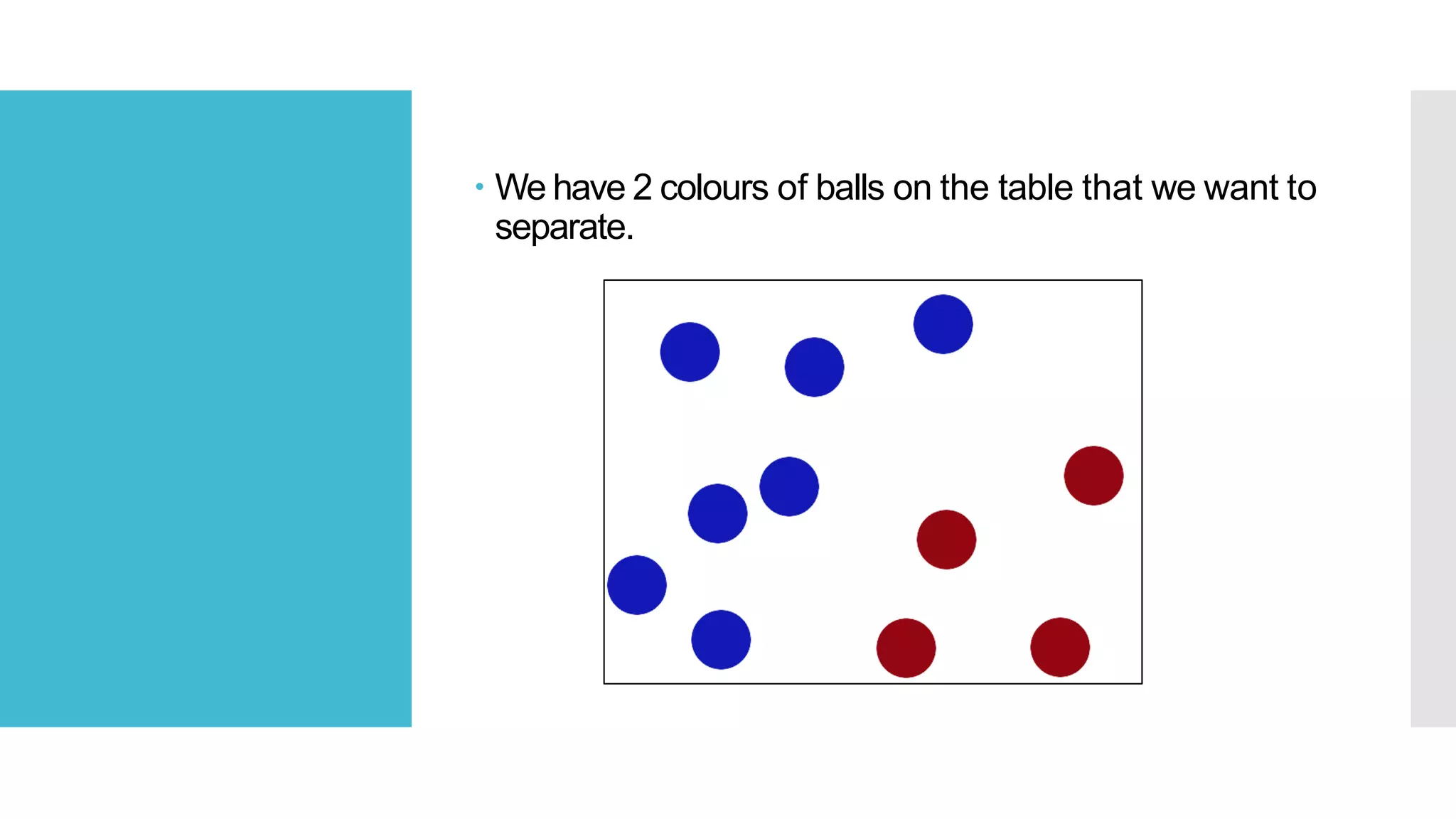
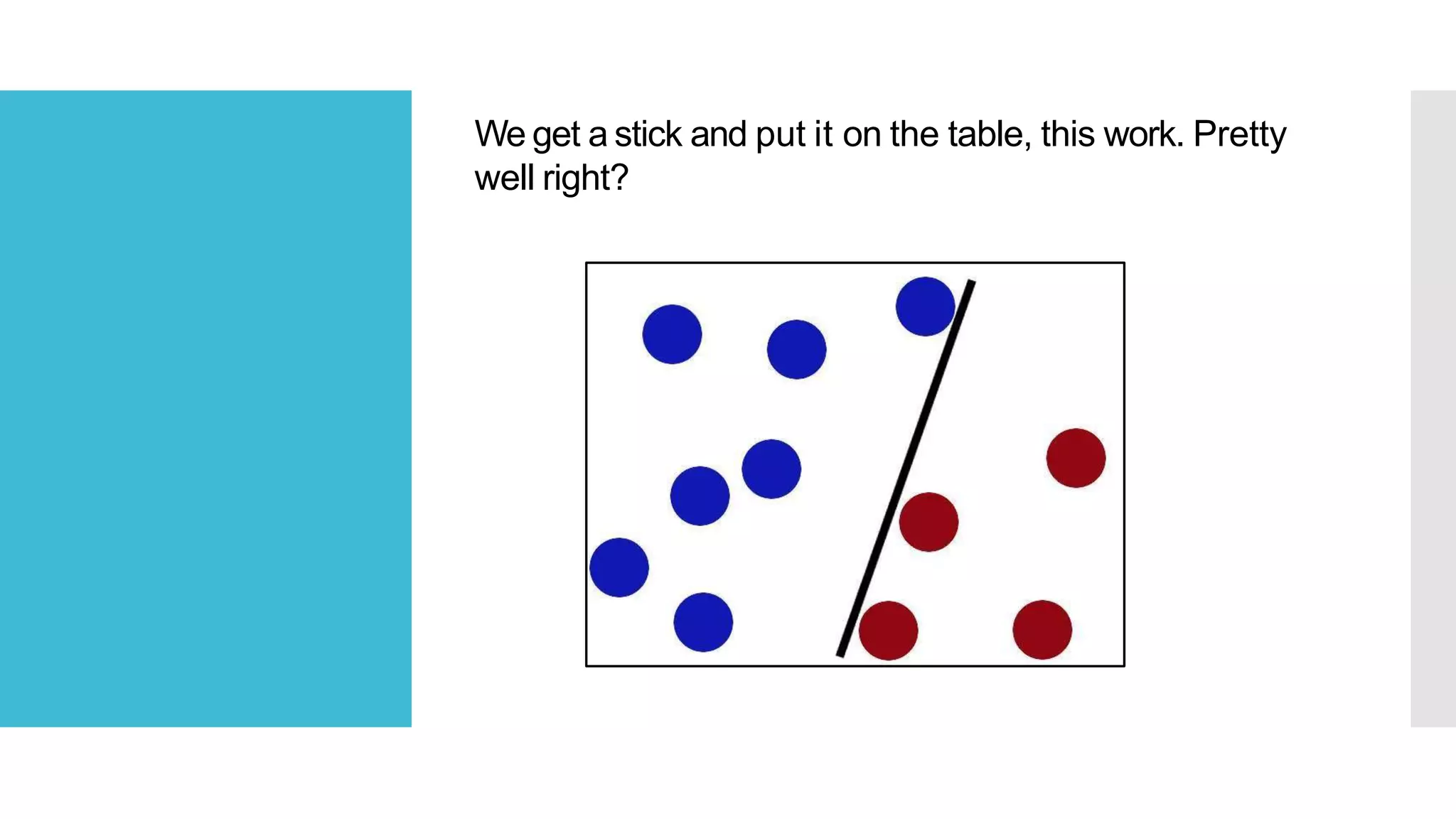
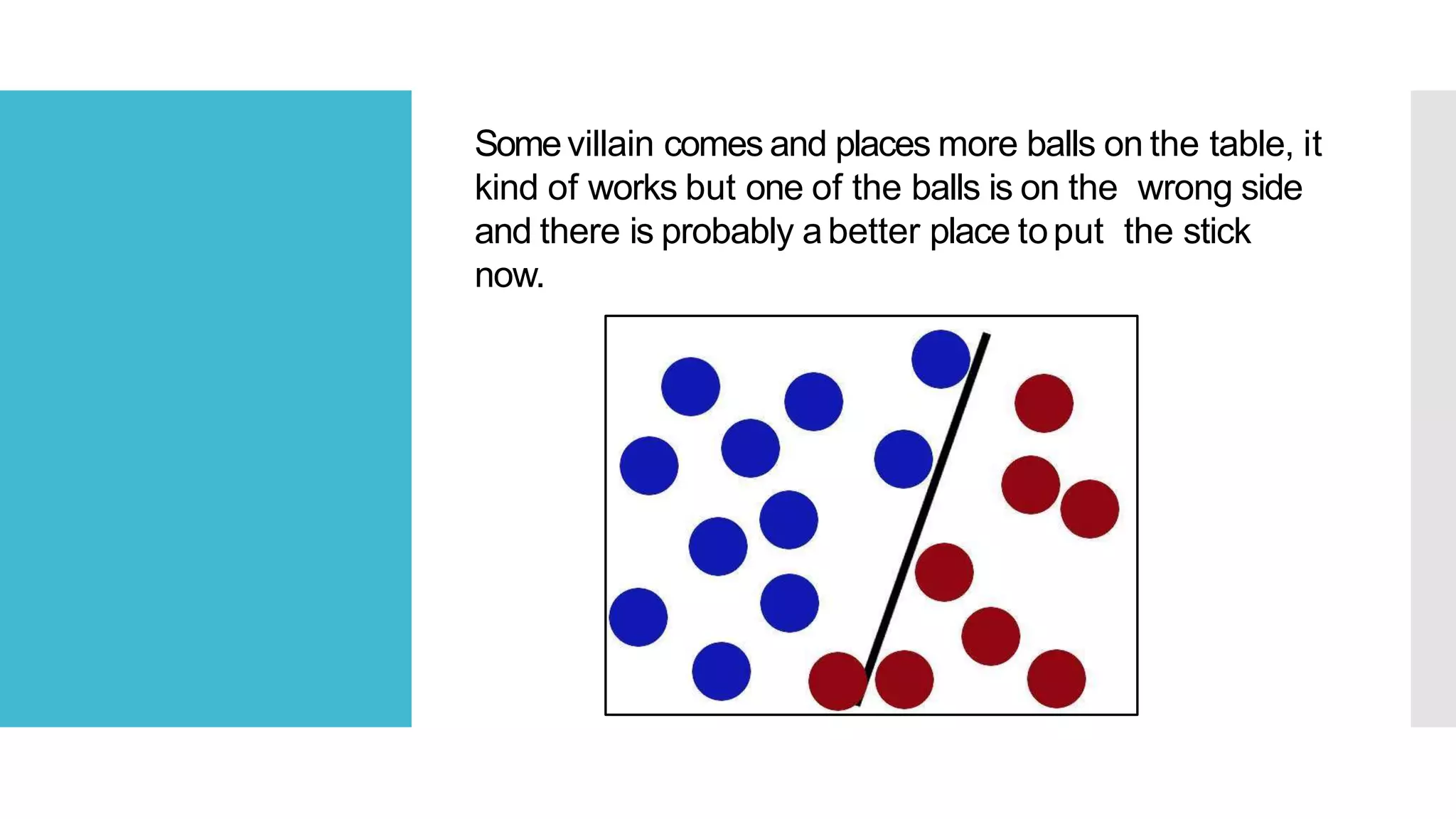
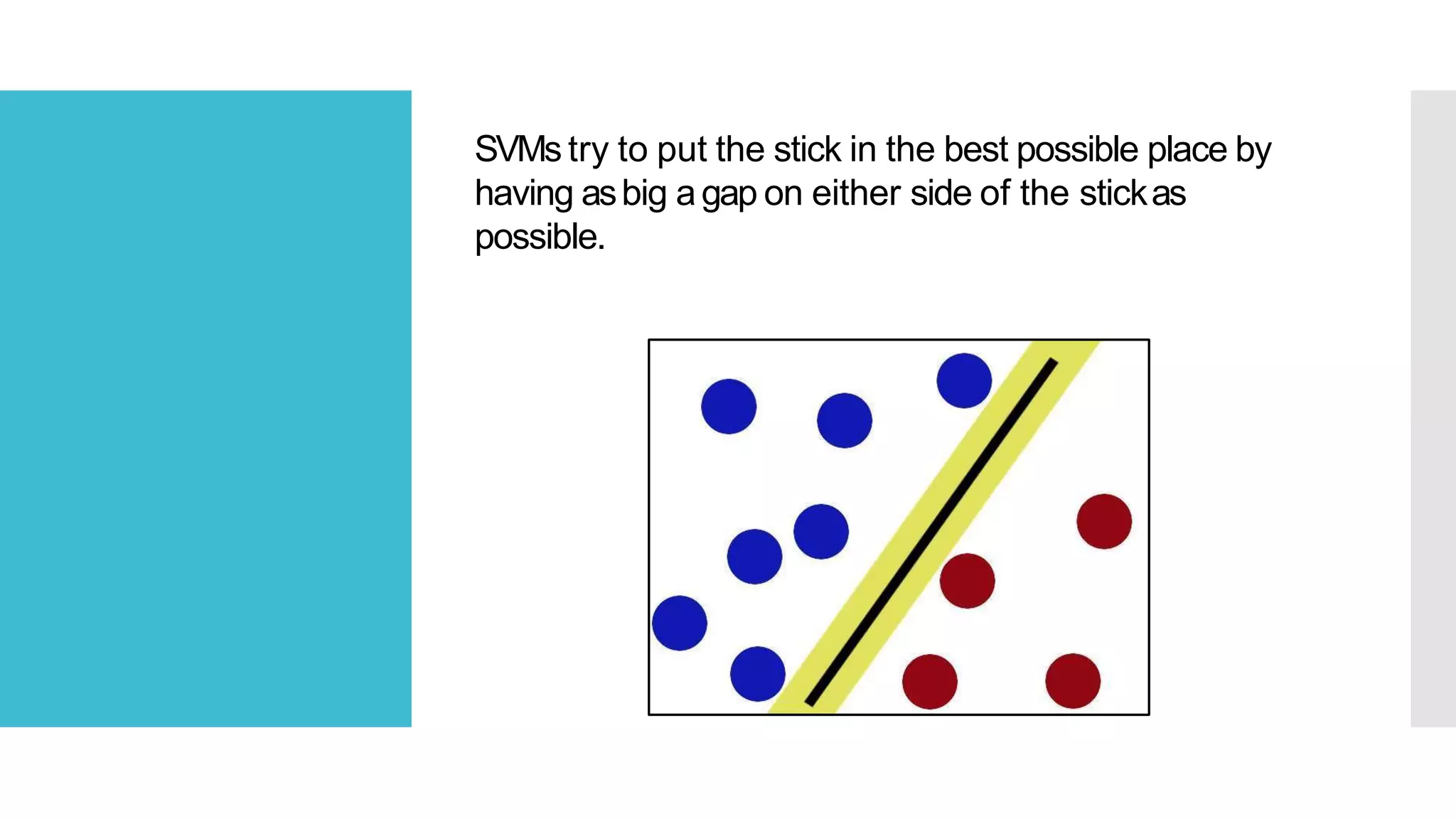


SVM is a classification algorithm that plots each data point in n-dimensional space based on its features. It finds the optimal hyperplane that separates all data points of one class from another class with the maximum margin. The hyperplane maximizes the margin by maximizing the distance between data points of both classes that are closest to the hyperplane. Non-linear classification is possible by applying kernel tricks that map data into higher dimensional spaces where a linear hyperplane can be found to perform the classification.













![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)