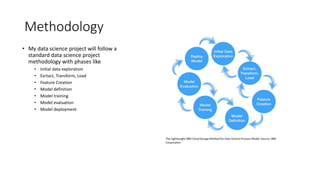
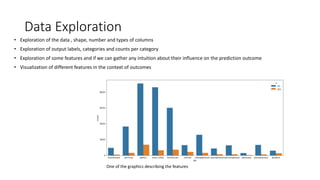
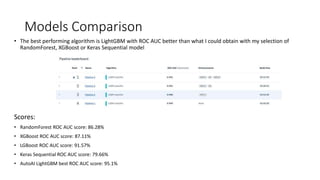
The document summarizes a data science project on bank marketing data using various tools in IBM Watson Studio. The project followed a standard methodology of data exploration, feature engineering, model selection, training and evaluation. Random forest, XGBoost, LightGBM and deep learning models were tested. LightGBM performed best with a 95.1% ROC AUC score from AutoAI hyperparameter tuning. The best model was deployed to IBM Watson Machine Learning for production use. Overall, the project demonstrated the effectiveness of the Watson Studio platform and tools in developing performant models from structured data.