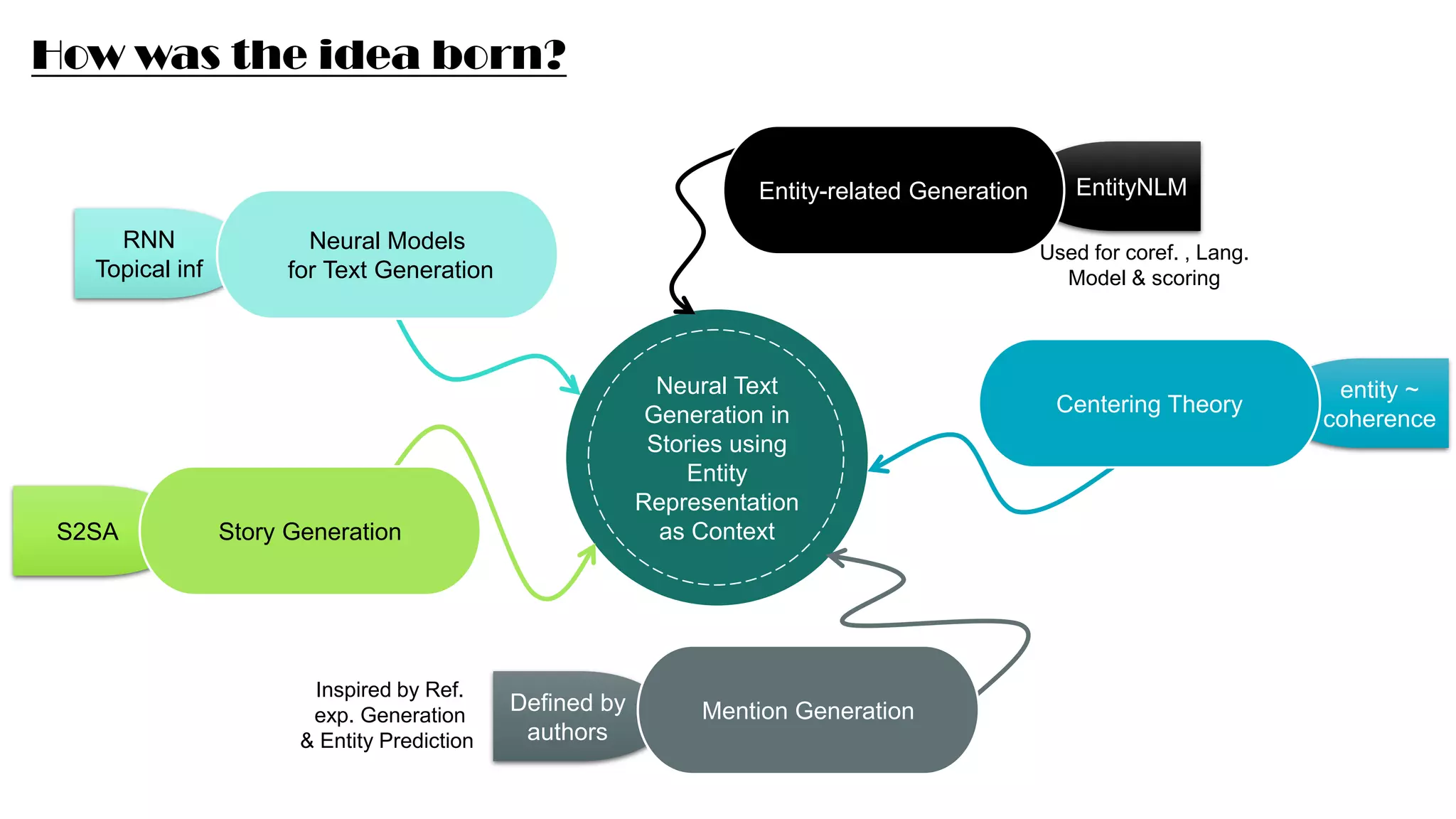
This presentation summarizes a neural entity-based text generation model called ENGEN. It combines three sources of contextual information - context from entities, content of the current sentence, and context from the previous sentence. The model assigns vector representations to entities that are updated each time an entity is mentioned. It was evaluated on three tasks: mention generation, pairwise sentence selection, and human evaluation of sentence generation. For mention generation, ENGEN performed better than baselines by leveraging entity representations. For sentence selection, S2SA performed best due to importance of local context. In human evaluation, ENGEN was rated better than S2SA for 27 out of 50 passages due to its ability to model coreference and generate coherent new entities.