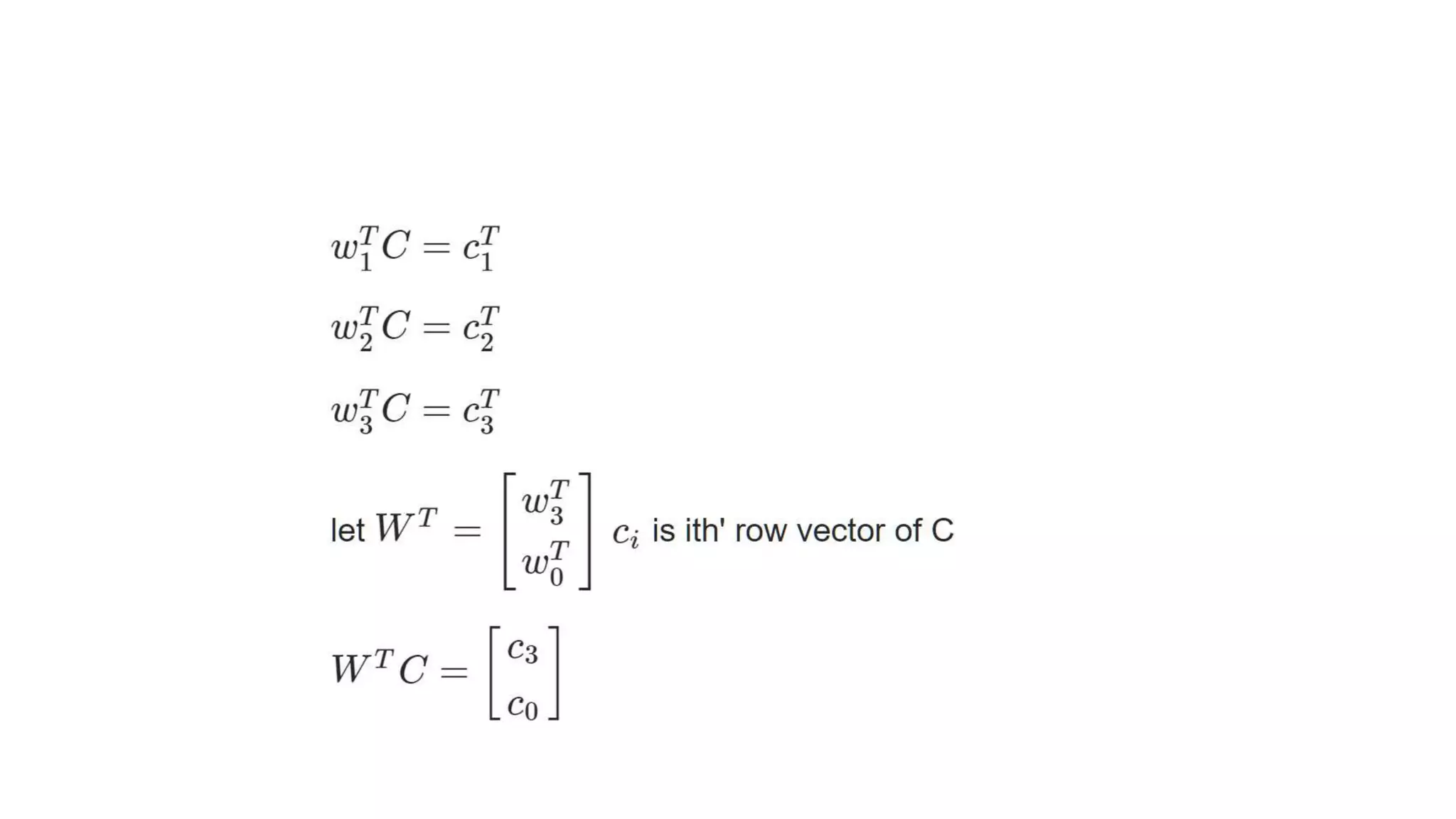
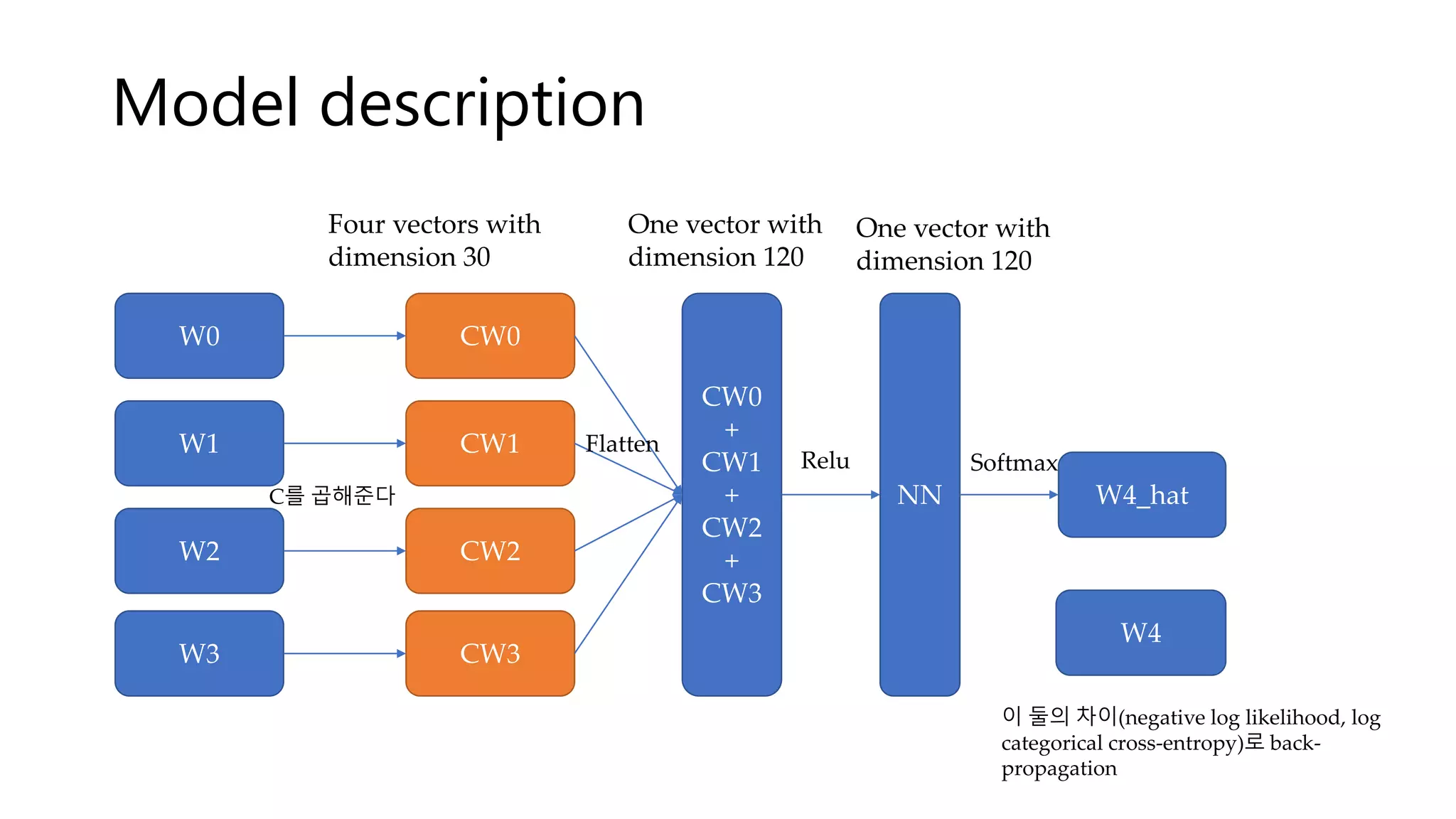
This document summarizes a presentation on word vectorization using neural networks. It introduces Keras as a deep learning library, provides background on word encoding, and describes a model that learns vector representations of words from n-grams such that similar words have similar vectors. The model is implemented with Keras and results show some words with syntactic or semantic similarity have similar vectors, while others like adjectives do not. Further improvements are discussed like using different neural network architectures, larger datasets, and better visualization.
































![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)







![[AAAI 2019 tutorial] End-to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/aaai2019tutorialend-to-endgoal-orientedquestionansweringsystems-190128122117-thumbnail.jpg?width=640&height=640&fit=bounds)





![[系列活動] 資料探勘速遊 - Session4 case-studies](https://cdn.slidesharecdn.com/ss_thumbnails/session4-case-studies-170114072124-thumbnail.jpg?width=640&height=640&fit=bounds)
















































