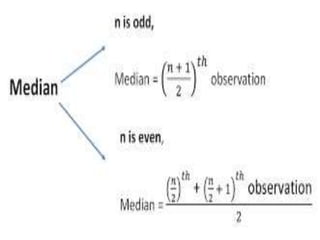
This document discusses various statistical parameters used in pharmaceutical research and development. It describes parameters like measures of central tendency (mean, median, mode), dispersion (variance, standard deviation), coefficient of dispersion, residuals, factor analysis, absolute error, mean absolute error, and percentage error of estimate. Measures of central tendency provide a summary of the central or typical values in a data set. Dispersion measures provide a way to quantify how spread out the data is from the central value. Other parameters like residuals, errors, and factor analysis are used to analyze relationships in complex data.