More Related Content

PDF

PDF
Firebase Test Lab 無料枠を使ってみました。 
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PDF
Function Level Analysis of Linux NVMe Driver 
PDF
CentOS Linux 8 の EOL と対応策の検討 
PDF
ニュースパスのクローラーアーキテクチャとマイクロサービス 
PDF

PDF
Cgroups, namespaces, and beyond: what are containers made from? (DockerCon Eu... What's hot

PPTX
Monetdb basic bat operation 
PDF
PostgreSQL: XID周回問題に潜む別の問題 
PDF

PDF
The Open vSwitch and OVN Projects 
PDF
PowerShellを使用したWindows Serverの管理 
PPTX

PPTX

PDF

PDF

PPTX
A comparative study of Clustering for Gene expression data in Bioinformatics 
PDF
Rhel cluster gfs_improveperformance 
PDF
福岡大学における公開用NTPサービス事例(LACNOG2019発表資料日本語版) 
PDF
PostgreSQLのgitレポジトリから見える2022年の開発状況(第38回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
Coffee Infographic - How to Make the Best Pour Over Coffee at Home 
PPTX

PDF

PPTX
Cephfs Snapshot Mirroring 
PDF

PDF
UniProt and the Semantic Web 
PPT
Viewers also liked

PDF
いろいろ考えると日本語の全文検索もMySQLがいいね! 
PDF

PDF

PDF

PDF

PDF
普通のWebエンジニアに学ぶ テーブル設計指南書 
PDF

PDF

PDF

PPTX
クローラを作る技術と設計 (毎週のハンズオン勉強会資料) 
PDF
全文検索サーバ Fess 〜 全文検索システム構築時の悩みどころ 
PDF
MySQL Casual Talks Vol.4 「MySQL-5.6で始める全文検索 〜InnoDB FTS編〜」 
PDF

PDF
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩- 
PPTX
Elasticsearch+nodejs+dynamodbで作る全社システム基盤 
PDF
Pythonによるwebアプリケーション入門 - Django編- 
PDF
最強オブジェクト指向言語 JavaScript 再入門! 
PPTX

PDF
Similar to PHPで全文検索エンジンをつくるまで

PPT
Mohawk presentation-gdg-kobe 
PDF
PostgreSQLとPGroongaで作るPHPマニュアル高速全文検索システム 
PDF
self made Fulltext search first_step 
PDF
YAPC::Asia 2014 - 半端なPHPDisでPHPerに陰で笑われないためのPerl Monger向け最新PHP事情 
PDF
2014年を振り返る 今年の技術トレンドとDockerについて 
PPTX

PDF

PDF
45分で理解する webクローリング入門 斉藤之雄 
PDF
PHPでPostgreSQLとPGroongaを使って高速日本語全文検索! 
ODP

PDF

PDF

PDF
MySQL・PostgreSQLだけで作る高速でリッチな全文検索システム 
PPTX
Webクローリング&スクレイピングの最前線 公開用 
PDF
Building document with the Sphinx public edtion More from 優之 田中

PDF
CloudFormationを活用したリソース管理と環境構築の自動化 
PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
PHPで全文検索エンジンをつくるまで
- 1.
- 2.
- 3.
本資料の対象者
こんな人に向けて話します。
•全文検索エンジンなにそれ?
• PHPしかわからんけど、興味ある!
• 独学したけど、挫折しちゃった。。
詳しい方はぜひ間違ってる点など指摘頂けると助かりま
す!
14年12月3日水曜日
- 4.
- 5.
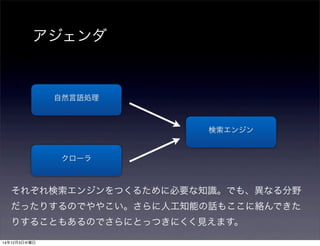
アジェンダ
検索エンジン
自然言語処理
クローラ
それぞれ検索エンジンをつくるために必要な知識。でも、異なる分野
だったりするのでややこい。さらに人工知能の話もここに絡んできた
りすることもあるのでさらにとっつきにくく見えます。
14年12月3日水曜日
- 6.
- 7.
- 8.
1-(1) 自然言語処理
•わかち書き
語の区切りに空白をはさんで記述することをわかち書き
といいます。つまり 日本語はわかち書き、英語は違いま
すね。英語はわかち書きではないので、空白をつかえば
語を区切っていくことが容易にできそうですね。
でも日本語は、、うまく語を区切ると難しいですよね。
というわけで形態素解析のお話しにいきましょう。
14年12月3日水曜日
- 9.
1-(1) 自然言語処理
•形態素解析
さあ困った、ということで日本語の文法の知識(文法の
ルールの集まり)や辞書(品詞等の情報付きの単語リス
ト)を情報源として用い形態素(日本語で意味を持つ最小
単位)に分割することを"形態素解析"といいます。
形態素解析をするとどうなるか、こんな感じです。
※Mecabを使用したサンプルです. Mecabについては後述.
14年12月3日水曜日
- 10.
- 11.
- 12.
1-(1) 自然言語処理
Mecab=> 名詞,固有名詞,組織,,,,
の => 助詞,連体化,,,,,の,ノ,ノ
テスト => 名詞,サ変接続,,,,,テスト,テスト,テスト
です => 助動詞,,,*,特殊・デス,基本形,です,デス,
デス
14年12月3日水曜日
- 13.
- 14.
- 15.
1-(1) 自然言語処理
•Mecab
オープンソースの日本語形態素解析エンジンで品詞情報
を利用した解析・推定を行うことができます。MeCabは
Googleが公開した大規模日本語n-gramデータの作成にも
使用されています。
セットアップもけっこう簡単。インストール手順につい
ては下記を参照。
MecabをEC2上にインストールする
14年12月3日水曜日
- 16.
1-(1) 自然言語処理
•まとめ
自然言語処理のざっくり基本的なお話しはこの程度で。
今回はMecabを使用した全文検索エンジンを実装する前提
でしたので形態素解析のお話しのみ駆け足でしました
が、もちろん分かち書きの言語を分割するのは別の方法
もあります(n-gram解析など)。
奥が深い分野ですのでぼくもまだまだ勉強中。。
14年12月3日水曜日
- 17.
- 18.
- 19.
1-(2) クローラー
んじゃどう実装してるの、てなりますが実際にみてみる
のが早いと思いますので今回は下記2例を紹介します。
• Wgetでクローラー
• Twitterのクローリング(API経由)
というわけでお話をしていきますが、 クローラーは設定
次第で短時間に大量のリクエストを任意のサービス、サ
ーバにおくることになります。そのあたりをしっかり理
解して実装していってください。
14年12月3日水曜日
- 20.
1-(2) クローラー
•Wgetでクローラー
Wgetはなにかしらのサーバセットアップするときに使用
したことあるかと思います。有名なダウンローダーです
ね。
$ wget http://hogehoge/test.txt
て感じで気軽にダウンロードできますよね。このWgetが
なんでクローラーかというと、再帰ダウンロード機能が
あるから!
14年12月3日水曜日
- 21.
1-(2) クローラー
•Wgetでクローラー
“再帰ダウンロード”とは任意のページ内のURLリンク先も
ダウンロードするよ、てこと。使い方はこんな感じ。
$ wget -r -l2 http://hogehoge/test.html
“-r”が再帰ダウンロードすることを指定し、-l(数字)で最
初のページからリンク先を辿る回数を指定します。(幅優
先探索ですね)
14年12月3日水曜日
- 22.
1-(2) クローラー
•Wgetでクローラー
というわけで、“再帰ダウンロード”のおかげで、Wgetは
ダウンロードしたHTMLを解析してリンク抽出まで可能な
のでWgetは立派なクローラーとして機能しそうですね。
ぜひ試しにWgetでクローリングしてみてください!
さて次はTwitterのクローリングのお話。
14年12月3日水曜日
- 23.
1-(2) クローラー
•Twitterのクローリング
Wgetを使ったクローリングで気づいたと思いますが、ク
ローラーを作るときに必要なのがHTMLの解析処理。でも
今回は下記理由からAPI経由でのクローリングを行いま
す。
• HTML解析はやっぱり手間
• サイトがかわったら解析処理の修正もいる
• HTMLだと収集可能なデータが限定(Twitterの場合)
14年12月3日水曜日
- 24.
1-(2) クローラー
•Twitterのクローリング
というわけでTwitter APIを使用したクローラーを作るので
すが、 Twitter APIを使用したドキュメントは数多くあるの
で詳細は割愛します。
ソースはこんな感じでできますのでぜひお試しください.
14年12月3日水曜日
- 25.
1-(2) クローラー
•まとめ
なんとなく感じたと思いますが、クローラーはクローラ
ーでまた別の分野、てくらい掘り下げるといろいろでて
くる奥深いもの。
・どうクロールする?
・負荷は?
・ログイン画面とかあったらどないする?
とかね。いろいろ調べてみるとこれまたおもしろい。
14年12月3日水曜日
- 26.
- 27.
2 全文検索エンジンの開発
やっとここまできましたwでもいままでの自然言語処
理、クローラーの部分て全文検索エンジンを作りはじめ
るのに実は必要な知識だったりします。
で今回作ってみる全文検索エンジンですが、
• PHP
• MySQL
• Mecab
て環境でいきます。この方がイメージつく方多いのでい
いかと思います。
14年12月3日水曜日
- 28.
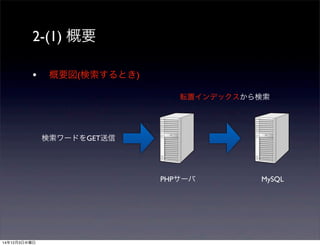
2-(1) 概要
•概要図(検索するとき)
PHPサーバMySQL
検索ワードをGET送信
転置インデックスから検索
14年12月3日水曜日
- 29.
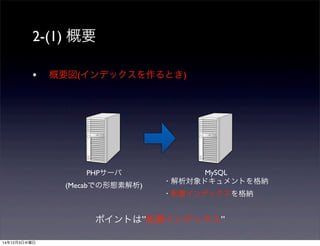
2-(1) 概要
•概要図(インデックスを作るとき)
PHPサーバ
(Mecabでの形態素解析)
MySQL
・解析対象ドキュメントを格納
・転置インデックスを格納
ポイントは”転置インデックス”
14年12月3日水曜日
- 30.
2-(1) 概要
•転置インデックス
ざっくりいうと"本の索引"みたいなもの。はてなキーワ
ード"転置インデックス"の説明がわかりやすい。例えば
下記のようなものが転置インデックス。
単語ドキュメントID
Pearl 1, 2, 304 ...
Perl 1, 5, 10, 12, 15 ...
Python 5, 10, 32 ...
14年12月3日水曜日
- 31.
2-(1) 概要
•転置インデックス
転置インデックスのテーブルを作成しておくことで検索
したいワードがきまればそれに紐づくドキュメントはす
ぐわかるよね、ということです。
で、このテーブル"転置インデックス"をつくるために前述
の形態素解析(Mecab)を使用していく、ということ。
14年12月3日水曜日
- 32.
- 33.
- 34.
- 35.
- 36.
参考文献
• PHPによる機械学習(PHPで、ていうのがとっつきやすくいい本でした。
Mecabについても詳しいです。)
• 検索エンジン自作入門~手を動かしながら見渡す検索の舞台裏(非常に難
解ですが良書ですね。)
• Rubyによるクローラー開発技法 巡回・解析機能の実装と21の運用例(ク
ローラーのお話が詳しいかつRubyなのでよみやすいですね。あと実例が
豊富なのもうれしい。)
• [Web開発者のための]大規模サービス技術入門(Perlでの全文検索エンジ
ン開発の章があります。)
14年12月3日水曜日


































![参考文献
• PHPによる機械学習(PHPで、ていうのがとっつきやすくいい本でした。
Mecabについても詳しいです。)
• 検索エンジン自作入門~手を動かしながら見渡す検索の舞台裏(非常に難
解ですが良書ですね。)
• Rubyによるクローラー開発技法 巡回・解析機能の実装と21の運用例(ク
ローラーのお話が詳しいかつRubyなのでよみやすいですね。あと実例が
豊富なのもうれしい。)
• [Web開発者のための]大規模サービス技術入門(Perlでの全文検索エンジ
ン開発の章があります。)
14年12月3日水曜日](https://image.slidesharecdn.com/php-141203055255-conversion-gate02/85/PHP-36-320.jpg)