Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
モノビット エンジン
9,540 views
リアルタイムゲームサーバーの ベンチマークをとる方法
『リアルタイムゲームサーバーの ベンチマークをとる方法』をスライド化致しました。 ネットワークゲームを製作する際にご参考頂けますと幸いです。
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 13 times
1
/ 66
2
/ 66
3
/ 66
4
/ 66
5
/ 66
6
/ 66
7
/ 66
8
/ 66
9
/ 66
10
/ 66
11
/ 66
12
/ 66
13
/ 66
14
/ 66
15
/ 66
16
/ 66
17
/ 66
18
/ 66
19
/ 66
20
/ 66
21
/ 66
22
/ 66
23
/ 66
24
/ 66
25
/ 66
26
/ 66
27
/ 66
28
/ 66
29
/ 66
30
/ 66
31
/ 66
32
/ 66
33
/ 66
34
/ 66
35
/ 66
36
/ 66
37
/ 66
38
/ 66
39
/ 66
40
/ 66
41
/ 66
42
/ 66
43
/ 66
44
/ 66
45
/ 66
46
/ 66
47
/ 66
48
/ 66
49
/ 66
50
/ 66
51
/ 66
52
/ 66
53
/ 66
54
/ 66
55
/ 66
56
/ 66
57
/ 66
58
/ 66
59
/ 66
60
/ 66
61
/ 66
62
/ 66
63
/ 66
64
/ 66
65
/ 66
66
/ 66
More Related Content
PDF
本当は楽しいインターネット
by
Yuya Rin
PDF
ISPの向こう側、どうなってますか
by
Akira Nakagawa
PDF
Wakamonog6 “ISPのネットワーク”って どんなネットワーク?
by
Satoshi Matsumoto
PDF
BGP Unnumbered で遊んでみた
by
akira6592
PPTX
あなたのところに専用線が届くまで
by
Tomohiro Sakamoto(Onodera)
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PDF
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
PDF
OpenStack超入門シリーズ いまさら聞けないSwiftの使い方
by
Toru Makabe
本当は楽しいインターネット
by
Yuya Rin
ISPの向こう側、どうなってますか
by
Akira Nakagawa
Wakamonog6 “ISPのネットワーク”って どんなネットワーク?
by
Satoshi Matsumoto
BGP Unnumbered で遊んでみた
by
akira6592
あなたのところに専用線が届くまで
by
Tomohiro Sakamoto(Onodera)
事例で学ぶApache Cassandra
by
Yuki Morishita
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
OpenStack超入門シリーズ いまさら聞けないSwiftの使い方
by
Toru Makabe
What's hot
PPTX
FD.io VPP事始め
by
tetsusat
PDF
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
PDF
【Interop Tokyo 2023】ShowNetにおけるジュニパーネットワークスの取り組み
by
Juniper Networks (日本)
PDF
ML2/OVN アーキテクチャ概観
by
Yamato Tanaka
PDF
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
コスト最適化概論
by
RikiMakita
PDF
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
PDF
Kubernetes 基盤における非機能試験の deepdive(Kubernetes Novice Tokyo #17 発表資料)
by
NTT DATA Technology & Innovation
PPTX
サイバーエージェント様 発表「OpenStackのNWと物理の話」
by
VirtualTech Japan Inc.
PPTX
OpenStackで始めるクラウド環境構築入門 Havana&DevStack編
by
VirtualTech Japan Inc.
PDF
さくらのVPS で IPv4 over IPv6ルータの構築
by
Tomocha Potter
PDF
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
PDF
OpenStackを一発でデプロイ – Juju/MAAS - OpenStack最新情報セミナー 2015年2月
by
VirtualTech Japan Inc.
PDF
サポートスペシャリストが語るXenDesktop / XenApp環境での最速トラブルシューティング
by
Citrix Systems Japan
PDF
Telecom Infra Projectの取り組み -光伝送におけるハードとソフトの分離-
by
HidekiNishizawa
PDF
SAN デザイン講座
by
Brocade
PDF
Autoscaling Kubernetes
by
craigbox
PDF
TIME_WAITに関する話
by
Takanori Sejima
PDF
#ljstudy KVM勉強会
by
Etsuji Nakai
FD.io VPP事始め
by
tetsusat
MRU : Monobit Reliable UDP ~5G世代のモバイルゲームに最適な通信プロトコルを目指して~
by
モノビット エンジン
【Interop Tokyo 2023】ShowNetにおけるジュニパーネットワークスの取り組み
by
Juniper Networks (日本)
ML2/OVN アーキテクチャ概観
by
Yamato Tanaka
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
コスト最適化概論
by
RikiMakita
Apache Kafkaでの大量データ処理がKubernetesで簡単にできて嬉しかった話
by
MicroAd, Inc.(Engineer)
Kubernetes 基盤における非機能試験の deepdive(Kubernetes Novice Tokyo #17 発表資料)
by
NTT DATA Technology & Innovation
サイバーエージェント様 発表「OpenStackのNWと物理の話」
by
VirtualTech Japan Inc.
OpenStackで始めるクラウド環境構築入門 Havana&DevStack編
by
VirtualTech Japan Inc.
さくらのVPS で IPv4 over IPv6ルータの構築
by
Tomocha Potter
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
OpenStackを一発でデプロイ – Juju/MAAS - OpenStack最新情報セミナー 2015年2月
by
VirtualTech Japan Inc.
サポートスペシャリストが語るXenDesktop / XenApp環境での最速トラブルシューティング
by
Citrix Systems Japan
Telecom Infra Projectの取り組み -光伝送におけるハードとソフトの分離-
by
HidekiNishizawa
SAN デザイン講座
by
Brocade
Autoscaling Kubernetes
by
craigbox
TIME_WAITに関する話
by
Takanori Sejima
#ljstudy KVM勉強会
by
Etsuji Nakai
Similar to リアルタイムゲームサーバーの ベンチマークをとる方法
PDF
Ethernetの受信処理
by
Takuya ASADA
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
PDF
Linux packet-forwarding
by
Masakazu Asama
PDF
年の瀬リアルタイム通信サーバ勉強会
by
モノビット エンジン
PPTX
リアルタイムサーバー 〜Erlang/OTPで作るPubSubサーバー〜
by
Yugo Shimizu
PDF
CEDEC 2015 IoT向け汎用protocol MQTTのリアルタイムゲーム通信利用と実装、そして未来へ…
by
Drecom Co., Ltd.
PDF
Kyoto Tycoon Guide in Japanese
by
Mikio Hirabayashi
PPTX
ゲームの通信をつくる仕事はどうなるのだろう?
by
Kengo Nakajima
PDF
新しくなったモノビットエンジンを使って10万人規模のサーバを構築するノウハウを公開!2017年10月27日モノビットエンジン勉強会
by
モノビット エンジン
PPTX
システムパフォーマンス勉強会#8
by
shingo suzuki
PPTX
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ①
by
モノビット エンジン
PDF
VRライブ・コミュニケーションサービス「バーチャルキャスト」でのモノビットエンジンの採用事例と最新情報
by
モノビット エンジン
PDF
Cisco Connect Japan 2014: シスコ ユニファイド コミュニケーションのサーバ構築ファースト ステップ
by
シスコシステムズ合同会社
PDF
VRライブ・コミュニケーションサービス「バーチャルキャスト」でのモノビットエンジンの採用事例と最新情報 - モノビットエンジン - GTMF 2018 O...
by
Game Tools & Middleware Forum
PDF
【CEDEC2017】新しくなったモノビットエンジンを使って10万人規模のサーバを構築するノウハウを公開!
by
モノビット エンジン
PPTX
Aw svs trifortクラウド選びのポイント
by
Taimei Omata
PDF
【モノビットエンジン勉強会inサイバーコネクトツー】 第二部「MRS/MUN 10万接続サーバ構成実例」
by
モノビット エンジン
PDF
VIOPS06: マルチコア時代のコンピューティング活用術
by
VIOPS Virtualized Infrastructure Operators group ARCHIVES
PDF
【モノビットエンジン勉強会inサイバーコネクトツー】 第一部「モノビットエンジンVer2.0シリーズ概要」
by
モノビット エンジン
Ethernetの受信処理
by
Takuya ASADA
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
ネットワーク ゲームにおけるTCPとUDPの使い分け
by
モノビット エンジン
Linux packet-forwarding
by
Masakazu Asama
年の瀬リアルタイム通信サーバ勉強会
by
モノビット エンジン
リアルタイムサーバー 〜Erlang/OTPで作るPubSubサーバー〜
by
Yugo Shimizu
CEDEC 2015 IoT向け汎用protocol MQTTのリアルタイムゲーム通信利用と実装、そして未来へ…
by
Drecom Co., Ltd.
Kyoto Tycoon Guide in Japanese
by
Mikio Hirabayashi
ゲームの通信をつくる仕事はどうなるのだろう?
by
Kengo Nakajima
新しくなったモノビットエンジンを使って10万人規模のサーバを構築するノウハウを公開!2017年10月27日モノビットエンジン勉強会
by
モノビット エンジン
システムパフォーマンス勉強会#8
by
shingo suzuki
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ①
by
モノビット エンジン
VRライブ・コミュニケーションサービス「バーチャルキャスト」でのモノビットエンジンの採用事例と最新情報
by
モノビット エンジン
Cisco Connect Japan 2014: シスコ ユニファイド コミュニケーションのサーバ構築ファースト ステップ
by
シスコシステムズ合同会社
VRライブ・コミュニケーションサービス「バーチャルキャスト」でのモノビットエンジンの採用事例と最新情報 - モノビットエンジン - GTMF 2018 O...
by
Game Tools & Middleware Forum
【CEDEC2017】新しくなったモノビットエンジンを使って10万人規模のサーバを構築するノウハウを公開!
by
モノビット エンジン
Aw svs trifortクラウド選びのポイント
by
Taimei Omata
【モノビットエンジン勉強会inサイバーコネクトツー】 第二部「MRS/MUN 10万接続サーバ構成実例」
by
モノビット エンジン
VIOPS06: マルチコア時代のコンピューティング活用術
by
VIOPS Virtualized Infrastructure Operators group ARCHIVES
【モノビットエンジン勉強会inサイバーコネクトツー】 第一部「モノビットエンジンVer2.0シリーズ概要」
by
モノビット エンジン
More from モノビット エンジン
PDF
Unityネットワーク通信の基盤である「RPC」について、意外と知られていないボトルネックと、その対策法
by
モノビット エンジン
PDF
【CEDEC2019 】5G時代に対応した『モノビットエンジン5G』を初公開! HoloLens対応した通信クラウド最新情報も!
by
モノビット エンジン
PDF
【GCC18】PUBGライクなゲームをUnityだけで早く確実に作る方法 〜ひとつのUnity上でダミークライアントを100個同時に動かす〜
by
モノビット エンジン
PDF
モノビットエンジン と AWS と クラウドパッケージで 最強のリアルタイム・マルチプレイ環境を構築&運用
by
モノビット エンジン
PDF
【GCC2019】モノビットエンジンがついにクラウド化!しかし、インフラでまさかのAzureを利用!?本当に大丈夫なの?
by
モノビット エンジン
PDF
Linux も動く Microsoft Azure HoloLens にも対応した次世代マルチプレイミドルウェア〜モノビットエンジンクラウド〜にて採...
by
モノビット エンジン
PDF
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ②
by
モノビット エンジン
PDF
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ②
by
モノビット エンジン
PDF
VR/AR分野におけるモノビットエンジン活用事例と新スタンドアロンVRHMD(どっかんナゴヤ’18)
by
モノビット エンジン
PDF
マルチプレーヤーゲームにおける サーバロジック実装と、 VR空間コミュニケーションの実例 安田 京人(モノビットエンジンセミナー2017年4月)
by
モノビット エンジン
PDF
八百万クエストにおける MUN採用事例 MUN使用環境における課題と対策
by
モノビット エンジン
PDF
【CEDEC2015】リアルタイム通信アクションゲーム60分クッキング!〜1時間でゼロから本格的MOゲームを完成させるライブコーディングデモ〜
by
モノビット エンジン
PDF
Unity道場京都スペシャル3 モノビットエンジンでマルチプレイゲーム開発 ~はじめの一歩~
by
モノビット エンジン
PDF
「Monobit Revolution Server」のご紹介
by
モノビット エンジン
PDF
Vrcloud conference vol1_cedec2016
by
モノビット エンジン
PDF
GTMF2017 モノビットセッション資料(2)
by
モノビット エンジン
PDF
GTMF2016 VR対応も開始!国産のリアルタイム通信エンジン「モノビットエンジン」の最新事例紹介
by
モノビット エンジン
PPTX
GTMF2017 モノビットセッション資料(1)
by
モノビット エンジン
PDF
ゲーム&VR向けリアルタイム通信エンジンの新しい選択肢~性能、使い勝手、お値段すべて公開!本城 嘉太郎(モノビットエンジンセミナー2017年4月)
by
モノビット エンジン
PDF
【GTMF2015】モノビットMOエンジンforUnity ワークフロー解説
by
モノビット エンジン
Unityネットワーク通信の基盤である「RPC」について、意外と知られていないボトルネックと、その対策法
by
モノビット エンジン
【CEDEC2019 】5G時代に対応した『モノビットエンジン5G』を初公開! HoloLens対応した通信クラウド最新情報も!
by
モノビット エンジン
【GCC18】PUBGライクなゲームをUnityだけで早く確実に作る方法 〜ひとつのUnity上でダミークライアントを100個同時に動かす〜
by
モノビット エンジン
モノビットエンジン と AWS と クラウドパッケージで 最強のリアルタイム・マルチプレイ環境を構築&運用
by
モノビット エンジン
【GCC2019】モノビットエンジンがついにクラウド化!しかし、インフラでまさかのAzureを利用!?本当に大丈夫なの?
by
モノビット エンジン
Linux も動く Microsoft Azure HoloLens にも対応した次世代マルチプレイミドルウェア〜モノビットエンジンクラウド〜にて採...
by
モノビット エンジン
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ②
by
モノビット エンジン
【CEDEC2018】800万ダウンロードを達成した共闘ことばRPG 『コトダマン』でのモノビットエンジン採用実例と最新情報 ②
by
モノビット エンジン
VR/AR分野におけるモノビットエンジン活用事例と新スタンドアロンVRHMD(どっかんナゴヤ’18)
by
モノビット エンジン
マルチプレーヤーゲームにおける サーバロジック実装と、 VR空間コミュニケーションの実例 安田 京人(モノビットエンジンセミナー2017年4月)
by
モノビット エンジン
八百万クエストにおける MUN採用事例 MUN使用環境における課題と対策
by
モノビット エンジン
【CEDEC2015】リアルタイム通信アクションゲーム60分クッキング!〜1時間でゼロから本格的MOゲームを完成させるライブコーディングデモ〜
by
モノビット エンジン
Unity道場京都スペシャル3 モノビットエンジンでマルチプレイゲーム開発 ~はじめの一歩~
by
モノビット エンジン
「Monobit Revolution Server」のご紹介
by
モノビット エンジン
Vrcloud conference vol1_cedec2016
by
モノビット エンジン
GTMF2017 モノビットセッション資料(2)
by
モノビット エンジン
GTMF2016 VR対応も開始!国産のリアルタイム通信エンジン「モノビットエンジン」の最新事例紹介
by
モノビット エンジン
GTMF2017 モノビットセッション資料(1)
by
モノビット エンジン
ゲーム&VR向けリアルタイム通信エンジンの新しい選択肢~性能、使い勝手、お値段すべて公開!本城 嘉太郎(モノビットエンジンセミナー2017年4月)
by
モノビット エンジン
【GTMF2015】モノビットMOエンジンforUnity ワークフロー解説
by
モノビット エンジン
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
リアルタイムゲームサーバーの ベンチマークをとる方法
1.
リアルタイムゲームサーバーの ベンチマークをとる方法 (株)モノビット 取締役CTO 中嶋謙互
2.
ベンチマークの失敗パターン • マシンやネットワーク環境の性能を詳しく調べずに ミドルウェアやアプリケーションの性能を測定し、 意外な結果が出てしまい、原因がわからず混乱する ミドルウェアは、ハードウェアの性能以上の性能を実現できない。 アプリケーションは、ミドルウェアの性能以上の性能を実現できない。
3.
ベンチマークの手順 1.測定に使うハードウェアを用意する 2.ハードウェアの性能を測定する 3.ミドルウェアの性能を測定する 4.(アプリケーションの性能を測定する) 本資料ではおもに1~3を説明します。 2で納得できたら3へ、3で納得できたら4へと進むのが重要
4.
性能の指標 • スループット速度 :
ビット/秒 または メッセージ/秒 • 応答速度 : 秒 • 同時接続数 : 本
5.
用意するマシンのタイプ • 2または4コア、4または8GBRAMの汎用マシンがMRSに最適 • AWS •
日本ではm4/c4.largeまたはxlarge • 日本以外ではm5/c5 のlargeまたはxlarge • IDCFクラウド • M4,M8,L8など • GCE • n1-standard-2または standard-4など
6.
マシン構成 サーバー用 インスタンス m4.xlarge クライアント用 インスタンス1 m4.xlarge クライアント用 インスタンス1 m4.xlarge ・・・ 同じアベイラビリティゾーン(ロケーション)内に設置すること。 サーバー用を1台とし、 クライアント用は1台から始めて必要に応じて増やしていく
7.
AWSにおける通信帯域制限(実測) • 各インスタンスにおいて • m4,c4シリーズ(xlarge)
: 1.2Gbps • m5,c5シリーズ(xlarge) : 8Gbps iperf3などの標準ツールおよび 独自開発した libuv_bench, mrs_room_bench等のプログラムを使用。 m5,c5シリーズは東京ではまだ使用不可(2017)
8.
AWSにおけるパケット数制限(実測) • 各インスタンスにおいて • m4,c4シリーズ(xlarge) •
送受信合計15万 packets/sec • m5,c5シリーズ(xlarge) • 送受信合計92万、片道55万 packets/sec iperf3などの標準ツールおよび 独自開発した libuv_bench, mrs_room_bench等のプログラムを使用 m5,c5シリーズは東京ではまだ使用不可(2017)
9.
AWS以外における制限 • Google Compute •
7~8Gbpsらしい • IDCFクラウド • 1.9Gbps (実測), 40万パケット/sec • 他 • 環境や条件によりさまざま 多くのクラウドでは物理的に10Gbps Ethernetが使われているが、 そのワイヤスピードよりも低い制限がかかっている。
10.
ハードウェアの性能を測定(iperf3) サーバー用 インスタンス m4.xlarge 10.6.0.199 クライアント用 インスタンス1 m4.xlarge 10.6.0.135 sudo yum install
iperf3 インストール サーバーを起動 iperf3 -s クライアントを起動 iperf3 -c 10.6.0.199 NICが複数ある場合は、LAN通信用のIPアドレスを指定する必要がある。 172. や10. ではじまるアドレスはだいたいLAN用 クライアントから サーバに負荷をかける
11.
iperf3の結果 (TCP) @IDCFクラウド IDCFクラウド
L8での測定結果 (以下同様) サーバー。だいたい2Gbps受信 クライアント だいたい2Gbps送信 TCPはLinuxの輻輳制御アルゴリズムが使われるので、 特にオプションを設定しなくても自動的に可能な最高速度で送信される
12.
iperf3の結果 (UDP、安定) iperf3 -s
2>&1 | grep -v ORDER -u -b 2000M 受信側(サーバー)でUDPのOUT OF ORDERログメッセージが 大量に出力されるため、それ以外だけを表示。 OUT OF ORDERが全く出ないならそれがのぞましい。 AWSなら少ない。時間帯によっても異なる サーバー。だいたい2Gbps受信 クライアント だいたい2Gbps送信 -uでUDPを選択。 UDPは輻輳制御が働かないので、 どれだけの量を送信するかオプションで設定する。 上図では 2000Mbps ※IDCFクラウド L8での測定結果
13.
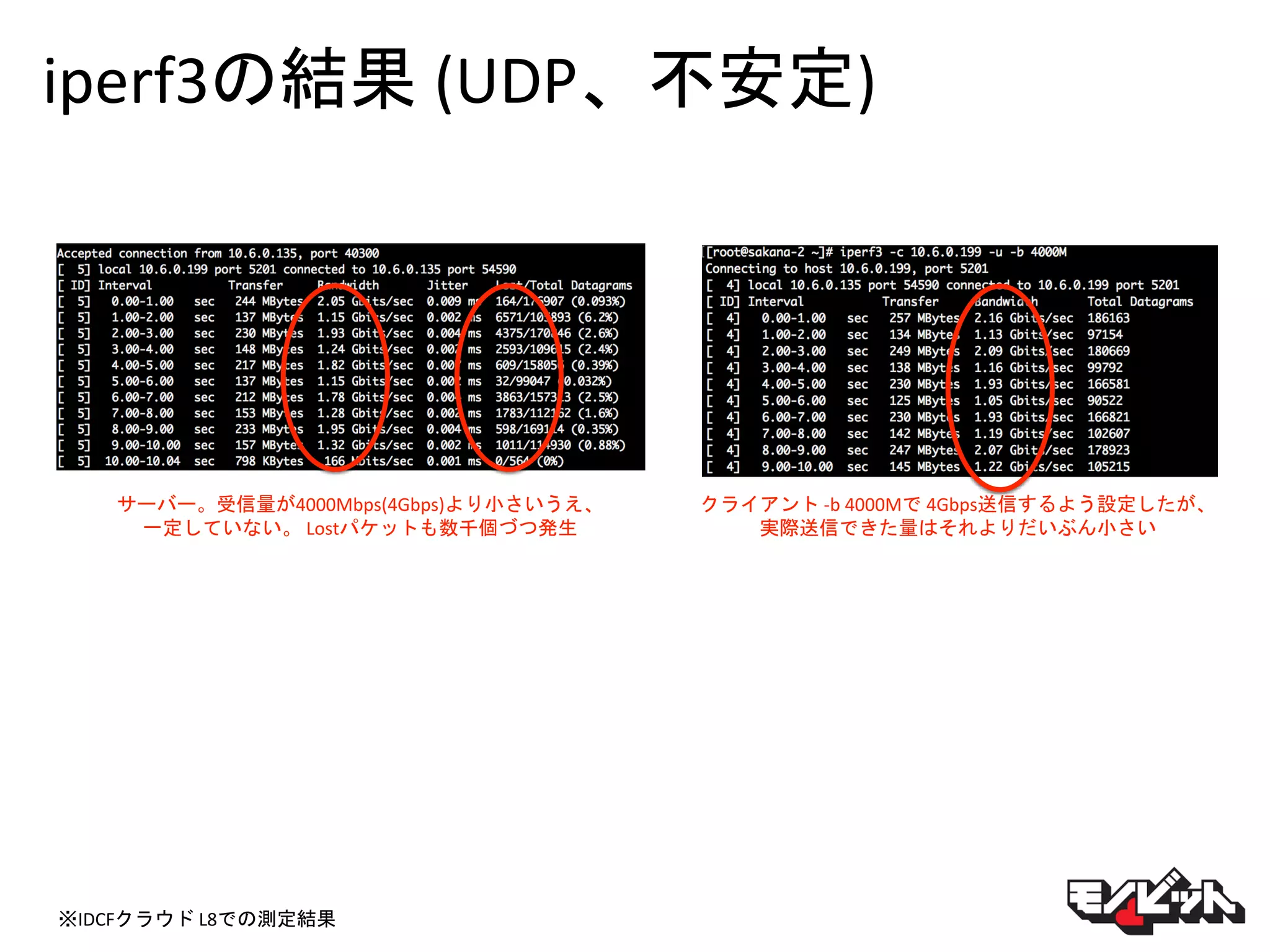
iperf3の結果 (UDP、不安定) サーバー。受信量が4000Mbps(4Gbps)より小さいうえ、 一定していない。 Lostパケットも数千個づつ発生 クライアント
-b 4000Mで 4Gbps送信するよう設定したが、 実際送信できた量はそれよりだいぶん小さい ※IDCFクラウド L8での測定結果
14.
iperf3の結果 (TCP、小パケット) TCPで1バイトづつ書き込み (-l
1オプション)した場合、 7Mbpsしか出ていないが これで正常(良好)な結果だと言える。 TCPで32バイトづつ書き込み。200Mbps程度に向上 ※IDCFクラウド L8での測定結果
15.
TCPパケットのサイズを確認する ※IDCFクラウド L8での測定結果 tcpdump -i
ens160 tcp port 5201 -c 100 • サーバ側においてtcpdumpコマンドを使い、iperf3が 使うTCP5201番のポートについて、100パケット分の 記録を取る。
16.
TCPパケットのサイズ ※IDCFクラウド L8での測定結果 iperf3は、writeシステムコールでTCPソケットに1バイトづつ書き込む。 Linux OSは、1バイトづつ書き込まれても、 一定時間以内の書き込みについては1つのパケットにまとめてしまう。 iperf3
-c 10.6.0.199 -l 1 iperf3 -c 10.6.0.199 -l 1 —no-delay —no-delayオプションを付けると、パケットサイズがかなり小さくなっているのがわかる
17.
iperf3の結果 (UDP、小パケット) -l 1で1バイトづつ送信。 UDPのサーバ側の出力。
1バイトづつの送信では、 2Mbps程度しか出ない ※IDCFクラウド L8での測定結果 -l 32 -b 100M で32バイトづつ送信。 100Mbps近いが、 ロス率が10%越えて不安定になっている。 これ以上速くは送れない
18.
UDPパケットのサイズ ※IDCFクラウド L8での測定結果 UDPでは、1バイトのペイロードをもつUDPデータグラムだけが送られている iperf3 -c
10.6.0.199 -u -l 1
19.
パケットサイズとスループットの関係 • アプリケーションデータの前後にヘッダなどが大量に付いているため、Ethernetおよ びIPネットワークでは、パケットサイズが小さいとスループットは大幅に落ちる • 参考: •
http://blogs.itmedia.co.jp/komata/2011/04/udp-8fa9.html • IPv4における最大パケットサイズ(MTU)は1500バイトのことが多い • OSの設定による
20.
ジャンボフレーム • 1500より大きいMTU設定をジャンボフレームと呼ぶ • 典型的には9000または9001バイト •
AWS • Amazon Linux : デフォルトでJumboフレーム有効(9001) • CentOS 7: t2シリーズでは自動的に9001になる • IDCFクラウド • CentOS 7 • デフォルトでJumboフレーム無効 (1500) • 上記以外 • 未調査
21.
MTUをifconfigで確認 Linode CentOS 7.3 デフォルトインストール AWS
CentOS 7.4 または AmazonLinux 2017.9 デフォルトインストール
22.
ゲームサーバーではジャンボフレームは不要 • ほとんどのパケットは、20バイト〜300バイト程度のちいさなパケット • ただし、たまにキャラのJSONデータが50KBとかまとめて送ることはある •
通信相手は、インターネットに散らばる何千という異なるホスト • 上記のような用途ではジャンボフレームは必要ない
23.
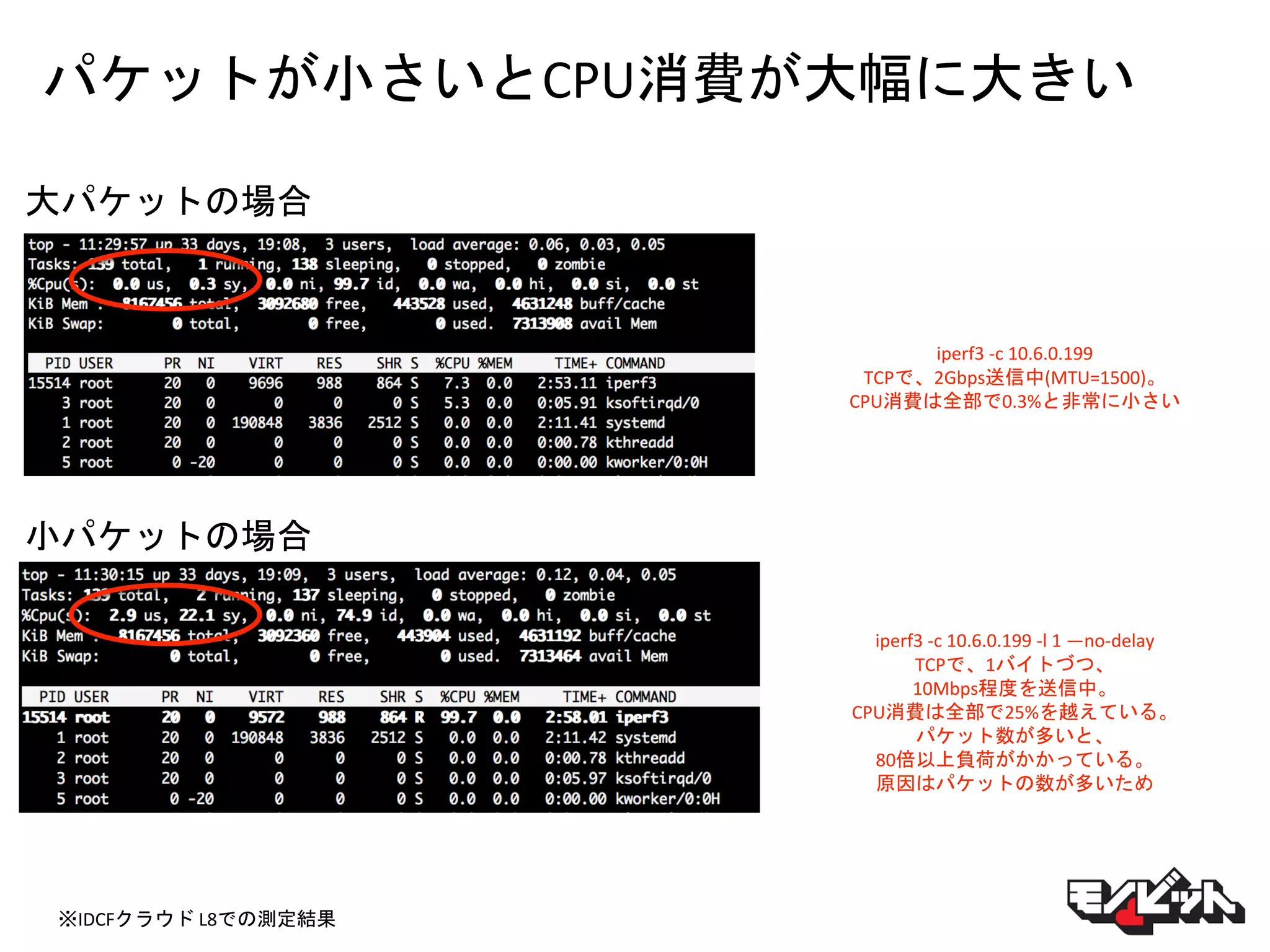
パケットが小さいとCPU消費が大幅に大きい iperf3 -c 10.6.0.199 TCPで、2Gbps送信中(MTU=1500)。 CPU消費は全部で0.3%と非常に小さい iperf3
-c 10.6.0.199 -l 1 —no-delay TCPで、1バイトづつ、 10Mbps程度を送信中。 CPU消費は全部で25%を越えている。 パケット数が多いと、 80倍以上負荷がかかっている。 原因はパケットの数が多いため 大パケットの場合 小パケットの場合 ※IDCFクラウド L8での測定結果
24.
毎秒のパケット数を調査する • pktcnt.rb という簡単なスクリプトを使う •
https://gist.github.com/kengonakajima/5a898c926ea5d6fd12428800f4718a1a 送信パケット数 受信パケット数 合計パケット数 送信バイト数 受信バイト数 合計バイト数 現在時刻 unixtime 平均パケット サイズ UDPで200バイトのデータで負荷をかけてみた場合。 ヘッダの分少し大きくなっている nethogsやdstatなどを併用してもOK
25.
ハードウェアの動作特性について だいたいわかったところで、 それより上位の層について調べ始める
26.
MRSの性能を測定する2つのツール • mrs_bench :
MRSのエコー性能を測定 • mrs_room_bench : ルームサーバー性能を測定
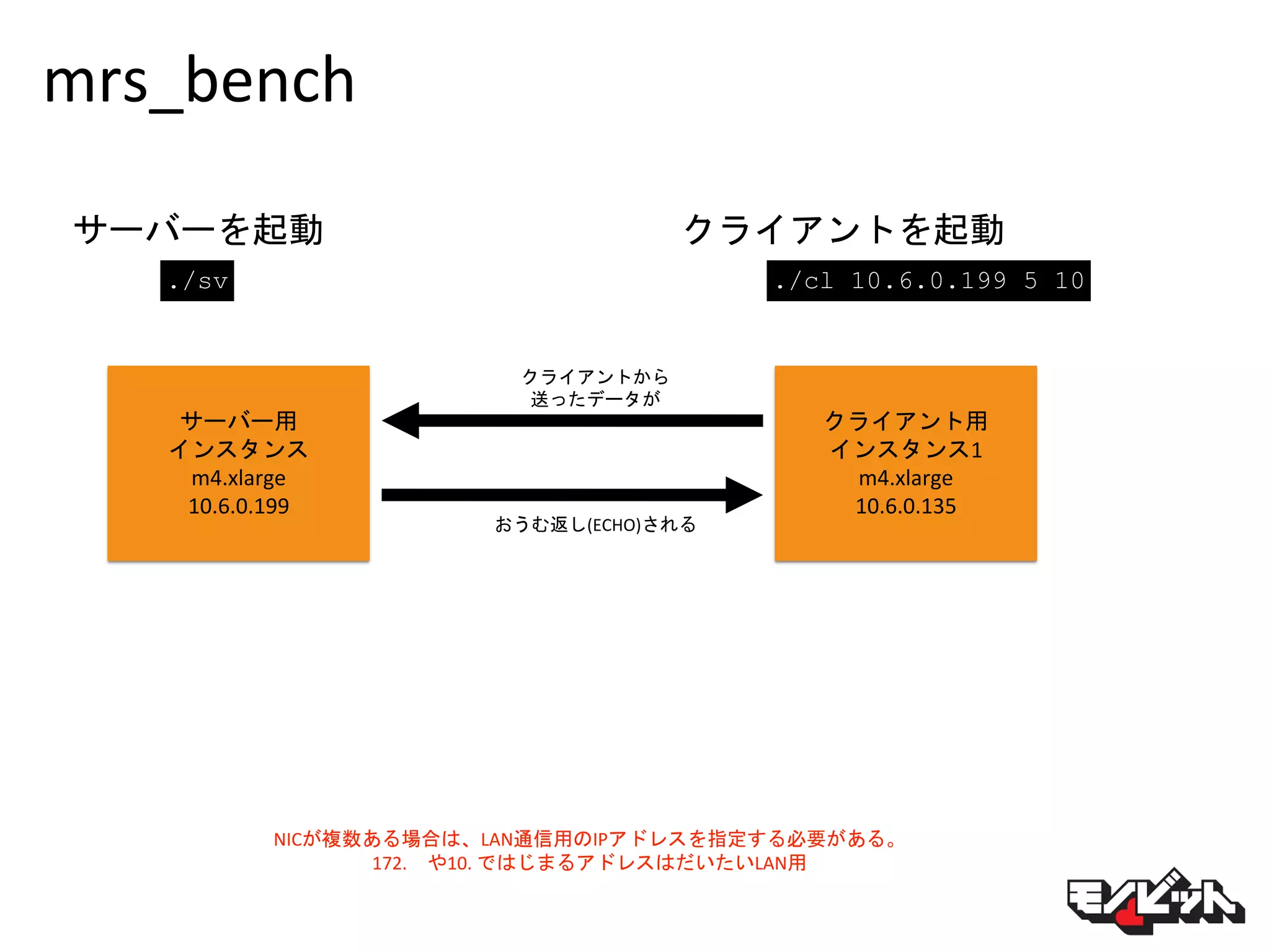
27.
mrs_bench サーバー用 インスタンス m4.xlarge 10.6.0.199 クライアント用 インスタンス1 m4.xlarge 10.6.0.135 サーバーを起動 ./sv クライアントを起動 ./cl 10.6.0.199 5
10 NICが複数ある場合は、LAN通信用のIPアドレスを指定する必要がある。 172. や10. ではじまるアドレスはだいたいLAN用 クライアントから 送ったデータが おうむ返し(ECHO)される
28.
mrs_bench の使い方 • 配布物はサーバとクライアントの両方を含む •
ビルド方法と起動方法 • 詳細は mrs_bench/README.md を参照 • 重要なクライアント起動時引数 • ./cl 10.6.0.199 10 1000 —size=40 —udp 10.6.0.199のサーバに対して同時10接続、1000ミリ秒に1回40バイトをUDPで送 信。 • サーバは引数なしで起動 (iperf3と同様) • 評価版の注意点 • 最大接続数が100に制限されている
29.
mrs_bench の出力凡例 • ログに小文字の”c”が連続するのは、接続に成功したしるし
dは切断 eはエラー • 性能評価 • 受信バイト数 : recvBのカッコ内、例の(0.3)が通信スループット Mbytes/secを示す。 Mbit/sは単純にこの値の8倍 • 受信メッセージ数: recvNの (9532)などが1秒間のメッセージ数を示す • RTTが通信遅延を示す 現在時刻 unixtime ループ回数 送信回数 受信回数(過去1秒) 同時接続数 切断数 エラー数 受信Miバイト数 (過去1秒) 往復時間 平均ms 最大ms 最小ms 最新ms
30.
mrs_benchのスループット(TCP) コマンドライン recvN recvB
(MiB) スループット Mbit/sec ipv4 pkts/sec send+recv ./cl 10.6.0.199 10 1 約9500 0.3 2.4Mbps 19100 ./cl 10.6.0.199 100 1 約95000 2.9 19.2Mbps 190000 ./cl 10.6.0.199 100 1 —size=100 約94000 10.1 80.8Mbps 190000 ./cl 10.6.0.199 100 1 —size=500 約94000 45 360Mbps 190000 ./cl 10.6.0.199 100 1 —size=1000 約93000 90 720Mbps 190000 ./cl 10.6.0.199 100 1 —size=2000 約89000 177 1.4Gbps 375000 ./cl 10.6.0.199 100 1 —size=3000 約89000 247 1.97Gbps 400000 ./cl 10.6.0.199 100 1 —size=4000 不定 不定 不定 400000 ※IDCFクラウド L8での測定結果 size=3000より大きくするとエラーが増えて、結果が不安定になる。 1.97Gbpsで、かつ40万パケット/秒 という出力は iperf3で測定したハードウェア限界に一致。 MRSがこのマシン環境での制限速度いっぱいまで使い切った
31.
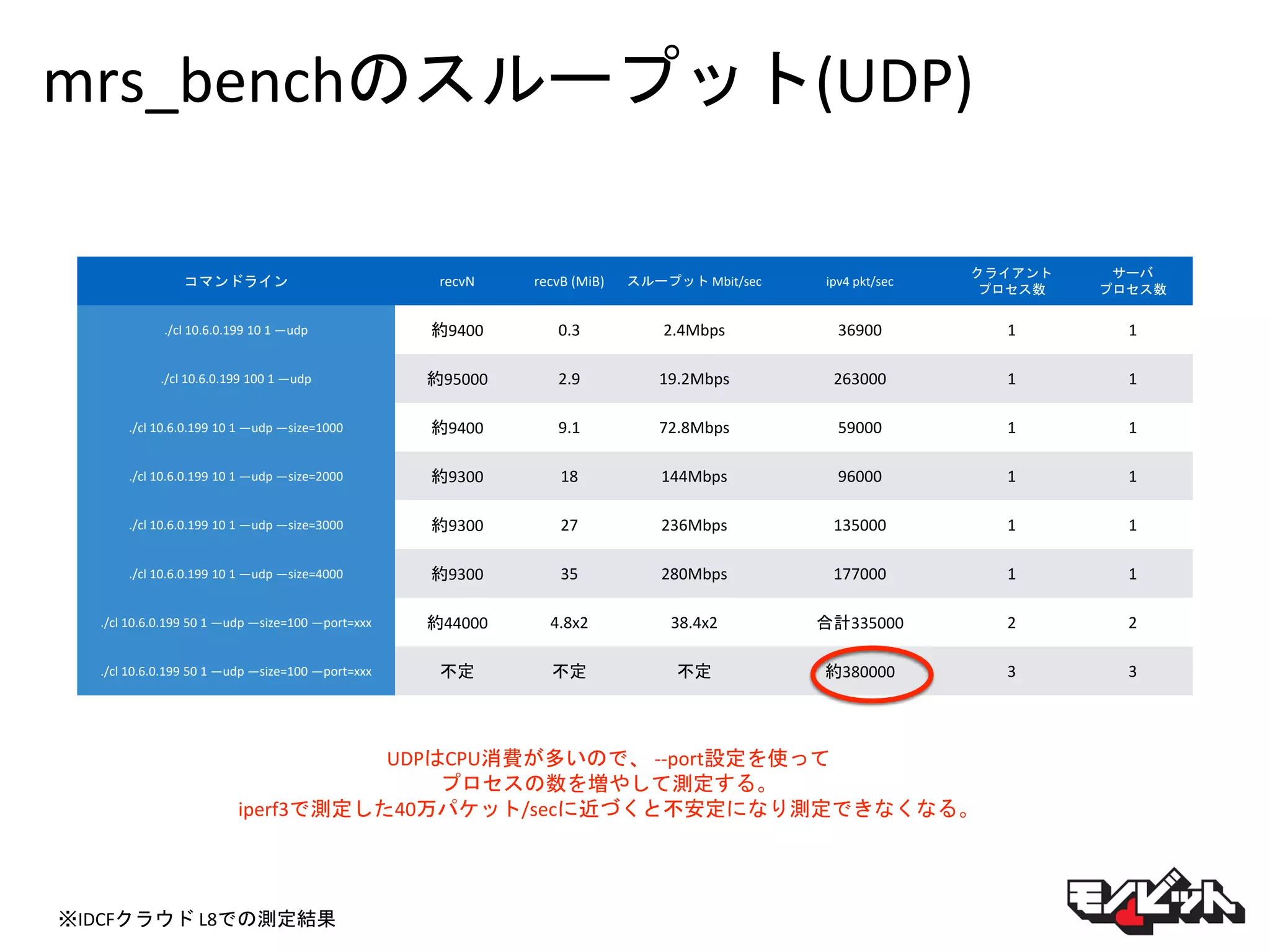
mrs_benchのスループット(UDP) コマンドライン recvN recvB
(MiB) スループット Mbit/sec ipv4 pkt/sec クライアント プロセス数 サーバ プロセス数 ./cl 10.6.0.199 10 1 —udp 約9400 0.3 2.4Mbps 36900 1 1 ./cl 10.6.0.199 100 1 —udp 約95000 2.9 19.2Mbps 263000 1 1 ./cl 10.6.0.199 10 1 —udp —size=1000 約9400 9.1 72.8Mbps 59000 1 1 ./cl 10.6.0.199 10 1 —udp —size=2000 約9300 18 144Mbps 96000 1 1 ./cl 10.6.0.199 10 1 —udp —size=3000 約9300 27 236Mbps 135000 1 1 ./cl 10.6.0.199 10 1 —udp —size=4000 約9300 35 280Mbps 177000 1 1 ./cl 10.6.0.199 50 1 —udp —size=100 —port=xxx 約44000 4.8x2 38.4x2 合計335000 2 2 ./cl 10.6.0.199 50 1 —udp —size=100 —port=xxx 不定 不定 不定 約380000 3 3 ※IDCFクラウド L8での測定結果 UDPはCPU消費が多いので、 --port設定を使って プロセスの数を増やして測定する。 iperf3で測定した40万パケット/secに近づくと不安定になり測定できなくなる。
32.
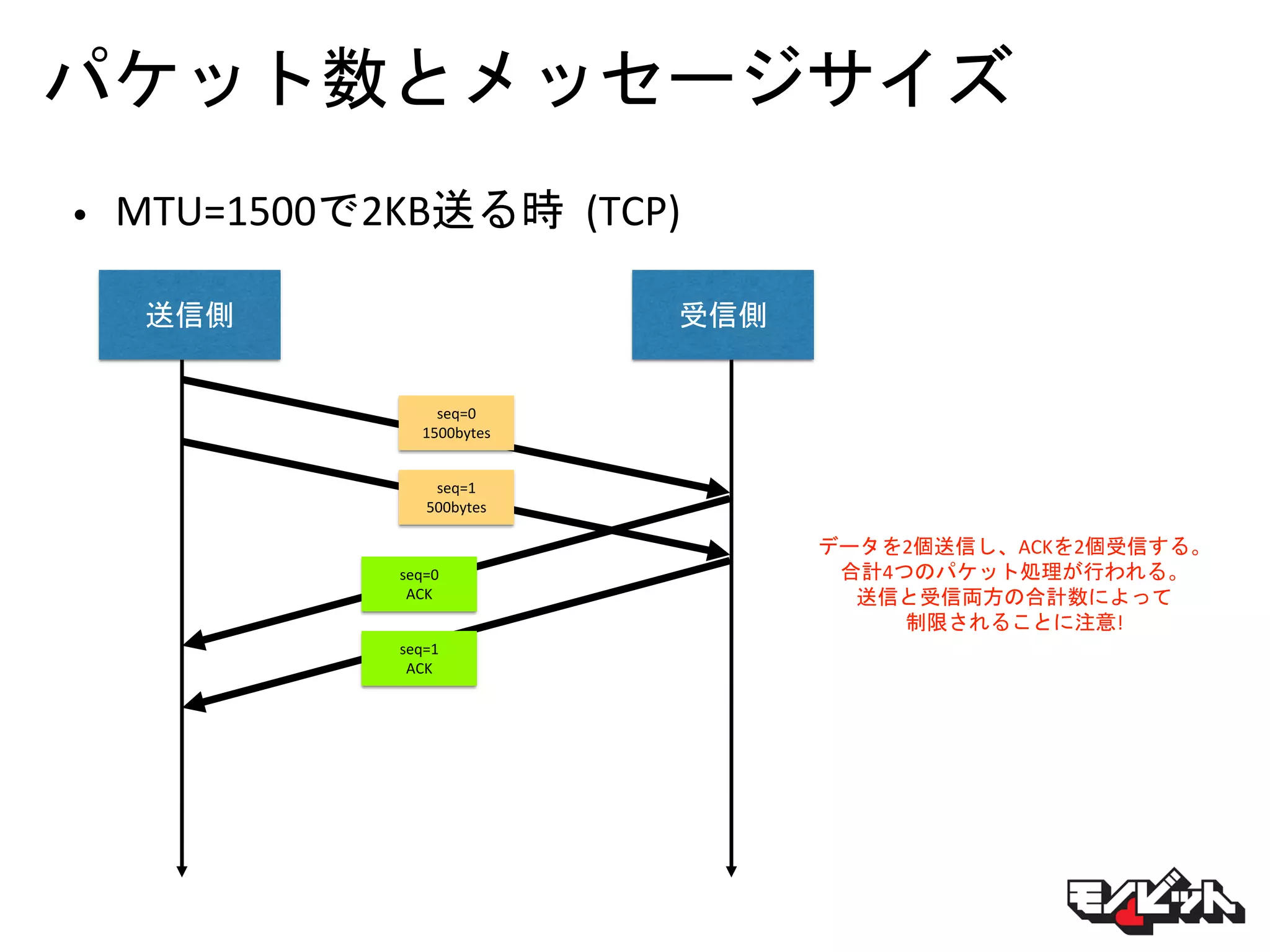
パケット数とメッセージサイズ • MTU=1500で2KB送る時 (TCP) 送信側
受信側 seq=0 1500bytes seq=1 500bytes seq=0 ACK seq=1 ACK データを2個送信し、ACKを2個受信する。 合計4つのパケット処理が行われる。 送信と受信両方の合計数によって 制限されることに注意!
33.
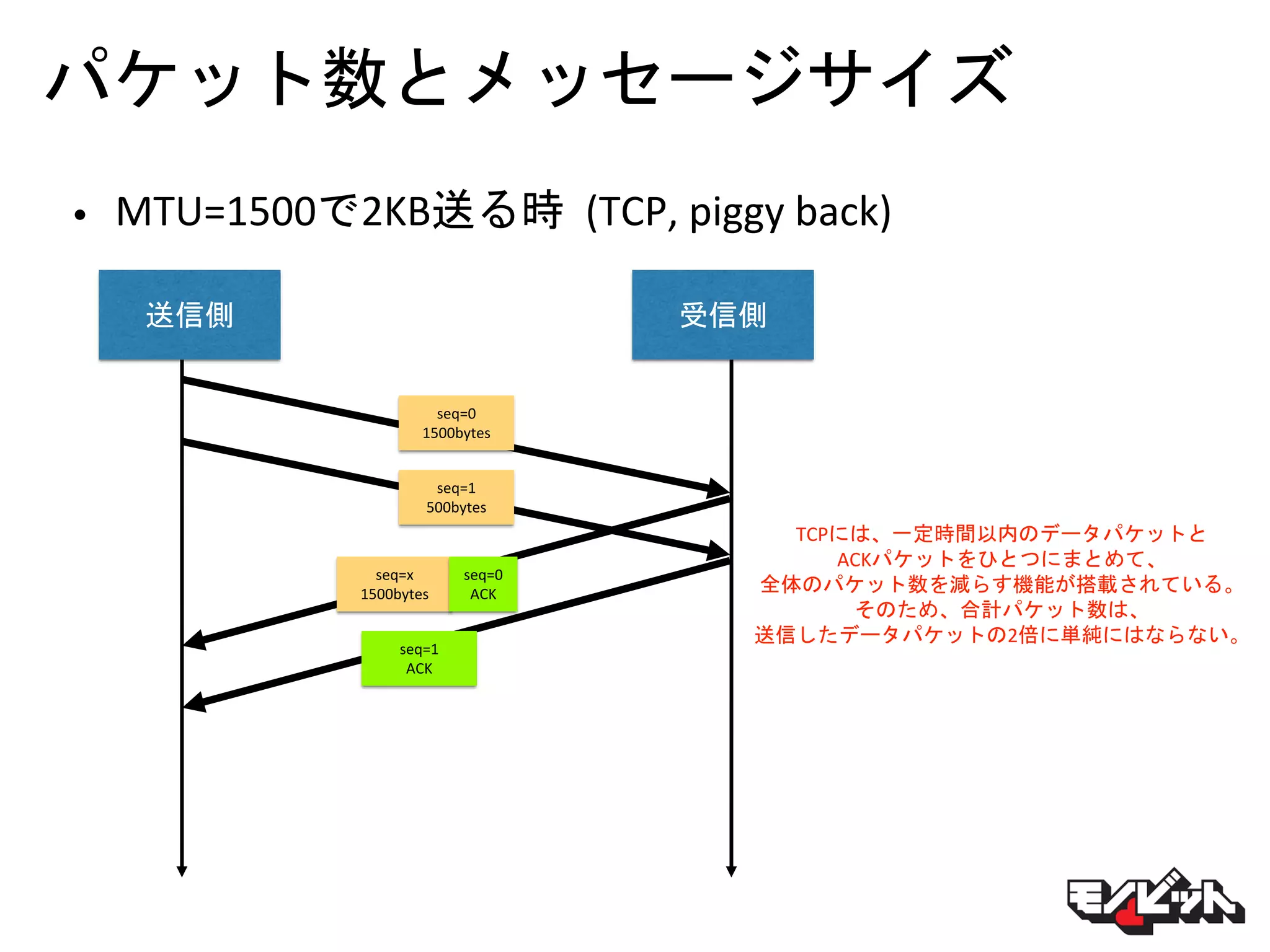
パケット数とメッセージサイズ • MTU=1500で2KB送る時 (TCP,
piggy back) 送信側 受信側 seq=0 1500bytes seq=1 500bytes seq=1 ACK TCPには、一定時間以内のデータパケットと ACKパケットをひとつにまとめて、 全体のパケット数を減らす機能が搭載されている。 そのため、合計パケット数は、 送信したデータパケットの2倍に単純にはならない。 seq=x 1500bytes seq=0 ACK
34.
パケット数とメッセージサイズ • RUDP で2KB送る時
MTU=576 送信側 受信側 seq=0 576bytes seq=1 576bytes MRSでは、RUDPの「パスMTUブラックホール」 を回避するためにMTUを576に固定している。 そのため、2KB送るときに合計8個のパケットが送信される。 TCPに比べてパケットの数が2倍になっている。 またRUDPにはpiggy back機能はない seq=0 ACK seq=2 576bytes seq=3 272bytes seq=1 ACK seq=2 ACK seq=3 ACK RUDPのパケット数は、 TCPのだいたい1.5倍〜2倍
35.
mrs_benchの暗号化能力 • MRSのブロック暗号アルゴリズム(AES)は、一般的な XeonなどのCPUの1コアあたり約30~60Mbytes/secの 処理能力を持つ。
36.
mrs_benchのスループット(TCP+暗号) コマンドライン recvN recvB
(MiB) スループット Mbit/sec サーバCPU 1スレッドの専有度 クライアント プロセス数 サーバ プロセス数 ./cl 10.6.0.199 10 1 —encrypt 約9400 0.3 2.4Mbps 5% 1 1 ./cl 10.6.0.199 10 1 —encrypt —size=1000 約9400 9.1 72.8Mbps 35% 1 1 ./cl 10.6.0.199 10 1 —encrypt —size=2000 約9300 18 144Mbps 68% 1 1 ./cl 10.6.0.199 10 1 —encrypt —size=3000 約9300 24 192Mbps 82% 1 1 ./cl 10.6.0.199 10 1 —encrypt —size=4000 不定 不定 不定 99% 1 1 ※IDCFクラウド L8での測定結果 IDCFのL8マシンでは、1プロセス(1スレッド)では約200Mbps (送受信の両方を暗号化しているので、2倍の400Mbps) が限界となっていることがわかる
37.
ゲームにおける暗号通信の必要性 • 必要 (トラフィックの5%以下) •
ログイン認証、ショップ、アチーブメントなど • 不必要 (トラフィックの95%以上) • MOBの座標更新、カメラ向き更新、GUIイベント送信、ボ イスチャットデータなど MRSでは、パケットごとに暗号の有効・無効を制御できるため、 通信の負荷容量設計においては暗号通信によるCPU消費増大は無視してよい。
38.
サーバー性能の飽和状態を知る方法 • プロセスごとの飽和状態 • マシン全体の飽和状態 •
どちらもtopで見る : CPU % • TCPの場合 : netstatで見る 暗号化したり、メッセージを極端に小さくしたりすると 環境による通信の速度制限に到達する前に サーバーの性能は飽和する。
39.
作業風景 topとpktcntを常に表示 クライアントプロセスログ サーバープロセスログ クライアント側マシンtop pktcnt.rbパケット数出力 サーバー側マシンtop
40.
topの見方 一つのsvプロセスが飽和 svプロセスの負荷が100% これはCPUコア1個(1スレッド分)を使い切っていることを示す。 これ以上このプロセスの性能は上がらない。 マシン全体の 負荷は 22.3
+ 2.7 = 25%程度 このマシンは4コアなので、同様のsvをあと3個増やせば性能は4倍になる。 MRSリアルタイムサーバーの場合は、だいたい単純計算でOK
41.
topの見方 svが8個ある場合 サーバーが8プロセス起動していて、 CPUはそれぞれ50%程度 4コアマシンなので、だいたい飽和してるとわかる マシン全体の 負荷はここでわかる。 合計で85%に近く、 そろそろ飽和している
42.
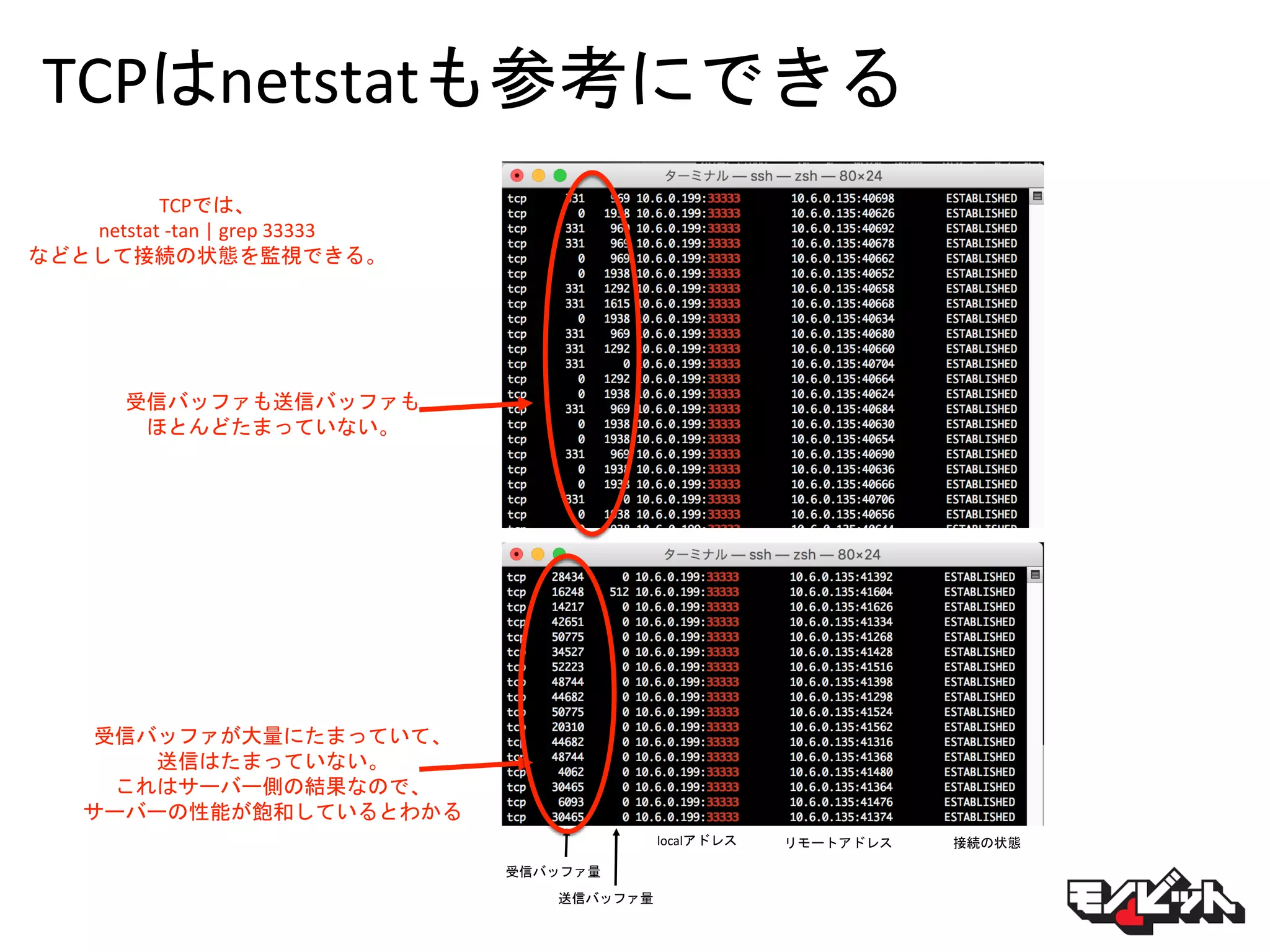
TCPはnetstatも参考にできる TCPでは、 netstat -tan |
grep 33333 などとして接続の状態を監視できる。 送信バッファ量 localアドレス リモートアドレス 受信バッファ量 接続の状態 受信バッファも送信バッファも ほとんどたまっていない。 受信バッファが大量にたまっていて、 送信はたまっていない。 これはサーバー側の結果なので、 サーバーの性能が飽和しているとわかる
43.
サーバーの性能が飽和しない時 • 接続数を増やしてもサーバーのCPU消費量が上がらなくなったら? • だいたいの場合はクライアントの性能が飽和している。 •
TCPであればnetstatのrecv-qがクライアント側で貯まる。 • UDPであればクライアントの送信エラーが表示される。 • よりコア数の多いマシンを使うか、マシンを増やして解決。
44.
mrs_room_bench • MRSを用いて実装されたリアルタイム同期サーバー のmrs_roomをベンチマークするためのクライアン トプログラム • ベンチマーク対象となる
mrs_roomのサーバープロ グラムも mrs_room_benchに含まれている(バージョ ン不一致を防ぐため)
45.
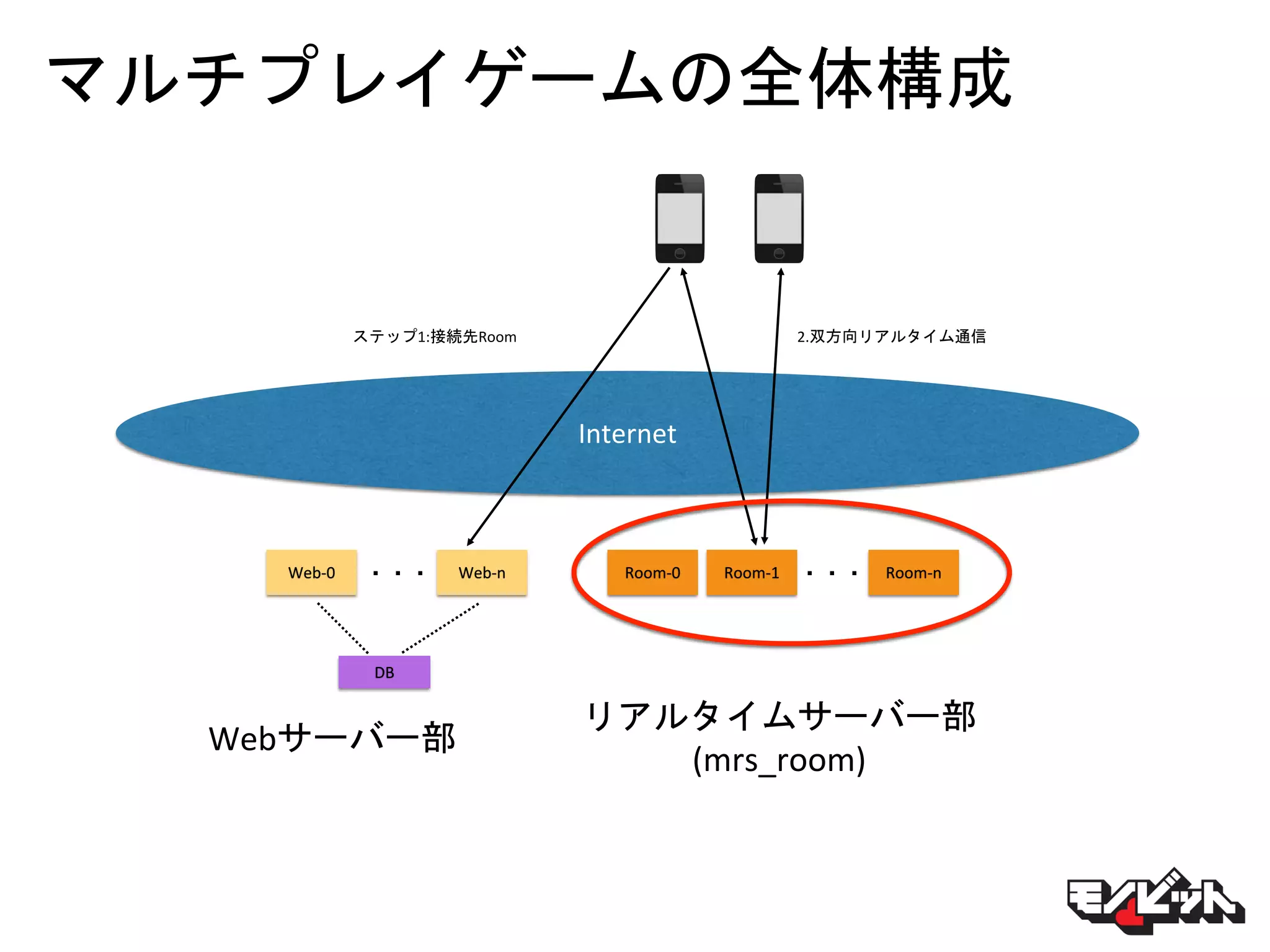
マルチプレイゲームの全体構成 DB Web-0 Internet Web-n Room-0 Room-1
・・・ Room-n・・・ 2.双方向リアルタイム通信ステップ1:接続先Room Webサーバー部 リアルタイムサーバー部 (mrs_room)
46.
1.ひとつのクライアントからUDPまたはTCPのデータ(パケット)を受信する 2.複数のクライアントに対してそのパケットを転送する 3.「部屋(ルーム)」の単位でそれを行う 4.1つのサーバープロセスが多数のルームを管理する mrs_room の機能 サーバープロセスdata A B C D data data data
47.
mrs_room における送信パターン • 標準 •
broadcast : 自分も含めて全員に送る • othercast : 自分以外に送る • manycast : 指定した複数に送る • unicast : 指定した相手だけに送る • ownercast : 部屋の所有者だけに送る • 拡張する場合 • nearcast : 近くの相手だけに送る • condcast : 条件を満たす相手だけに送る • etc..
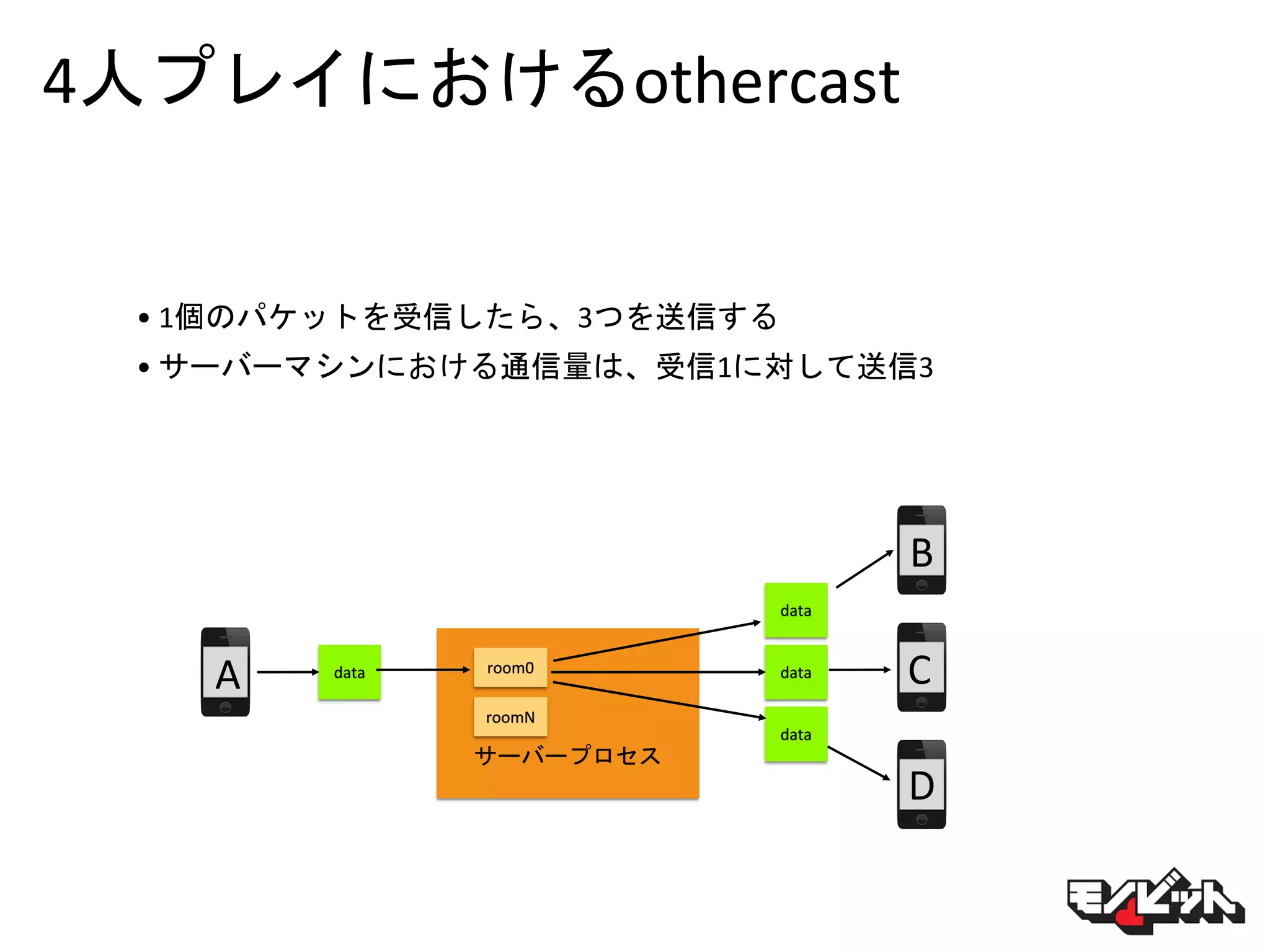
48.
4人プレイにおけるothercast • 1個のパケットを受信したら、3つを送信する • サーバーマシンにおける通信量は、受信1に対して送信3 サーバープロセス data A B C D data data data room0 roomN
49.
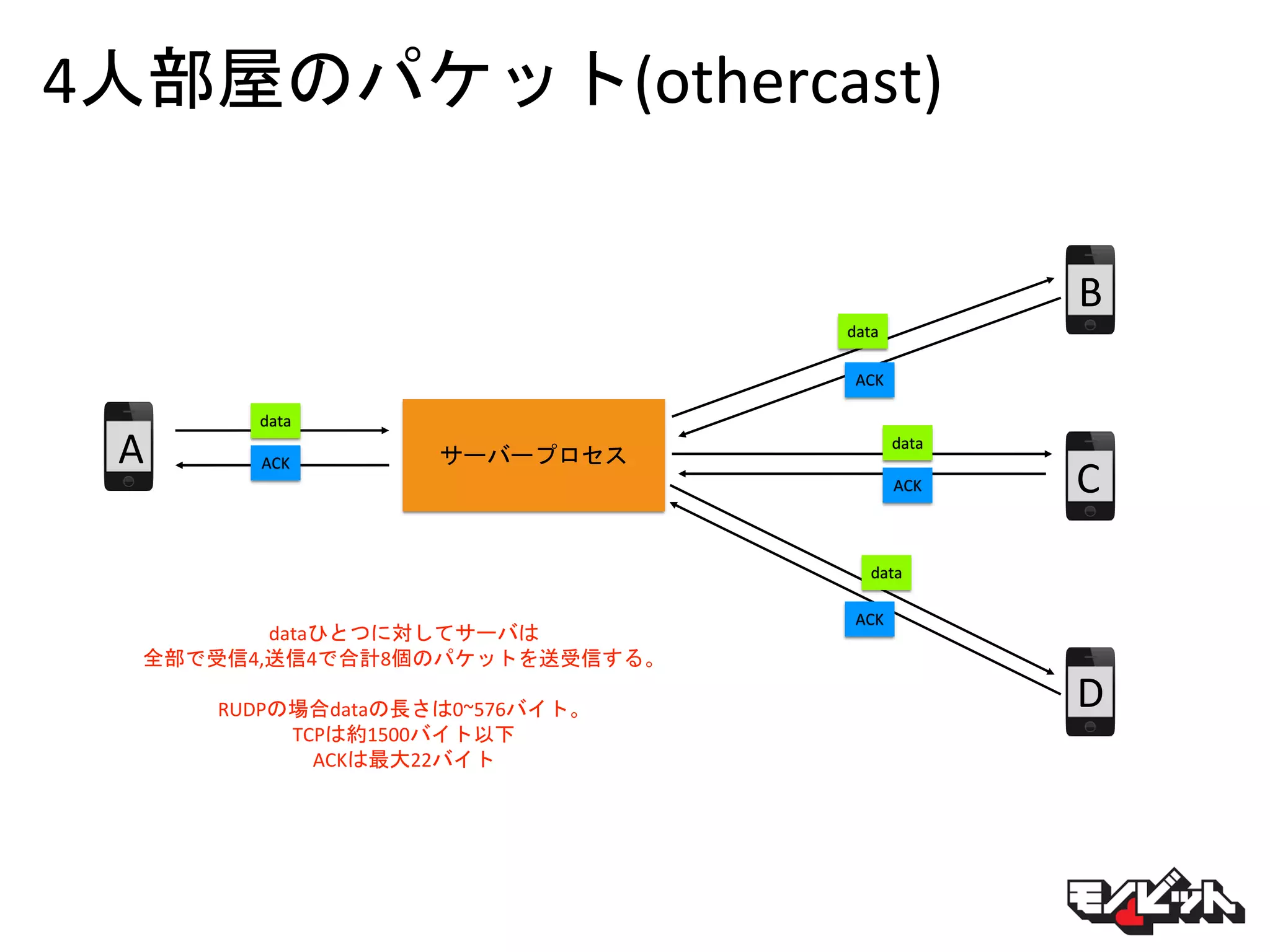
4人部屋のパケット(othercast) サーバープロセス data A B C D ACK data ACK data ACK data ACK dataひとつに対してサーバは 全部で受信4,送信4で合計8個のパケットを送受信する。 RUDPの場合dataの長さは0~576バイト。 TCPは約1500バイト以下 ACKは最大22バイト
50.
4コアマシンの典型的な構成 サーバーマシン sv0 sv1 sv2 sv3 sv4 sv5 room0 room1 ・・・・・・・・・ room2 ・・・ roomN
・・・ roomN roomN roomN roomN ・・・・・ 1台のインスタンスに 6〜8個のサーバプロセスを置く 1個のサーバプロセスが 500〜2000の部屋をホストし、 合計で5000〜10000程度の 同時接続数に対応
51.
インスタンスは何個必要か? • 1台の4コアマシンに可能な入力 • 帯域幅の限界
: 1.2Gbps〜8Gbps • パケット数の限界 : 合計15万〜90万/sec • 暗号 : 送受信合計で 50Mbytes/sec • 上記の入力上限を超えるごとに1台必要 全部でどれだけの通信が必要かは、完全にゲーム内容による
52.
ゲーム内容によるとはいえ、 最初は詳しい仕様が決まっていないもの。 大ざっぱに考えたらOK
53.
1インスタンスがホストできる同時接続数 • 適当に仮定を置く • メッセージサイズ:200バイトに固定。ちょっと長いけど。 •
暗号化通信のコストは無視でOK • 送り方は othercastに固定。だいたいのゲームはこれでOK • 通信モデルはホストーゲスト型(ホスト役以外全員がゲスト)に固定 • 部屋の参加人数によらず、ホストが1送ったらほかの全員が1受信する • マシンは AWSの m4 (15万packet/sec, 1.2Gbps)と仮定 • ACKパケットは必ず発生すると仮定
54.
1インスタンスがホストできる同時接続 サーバへの送信 /sec/CCU サーバからの送信 /sec/CCU サーバでの 合計パケット数 /sec/CCU ACKも含めた パケ数 バイト数 15万pkt/sec での限界 CCU 1.2Gbpsでの 限界CCU ターン制ゲーム 1msg/sec 1 1 2
4 400 37500 375000 低速少量アクション クラッシュ系、 パズルやスポーツゲームなど 5msg/sec 5 5 10 20 2k 7500 75000 高速大量アクション MOBAやRTS,物理があるFPSな ど 30msg/sec 30 30 60 120 12k 1250 12500 可能なCCUの小さい方を採用する。 ゲームではパケットが小さいので、 だいたいいつもパケット数の制限が帯域の制限よりきつい
55.
•まとめると •ターン制ゲームは37500CCU(同時接続) •低速少量アクションは 7500 •高速大量アクションは1250 •安全係数を0.5程度掛けると •ターン制ゲームは 18750 •低速少量アクションは
3750 •高速大量アクションは625 1インスタンスがホストできる同時接続
56.
1024以上のCCUに対応するための設定 • TCPを使う場合は2つの制限が問題になりやすい • ユーザアカウントあたりの最大ソケット数 •
ローカルポート数 • 負荷テストを行うときは、UDPのクライアント側で も上記の問題は起きる
57.
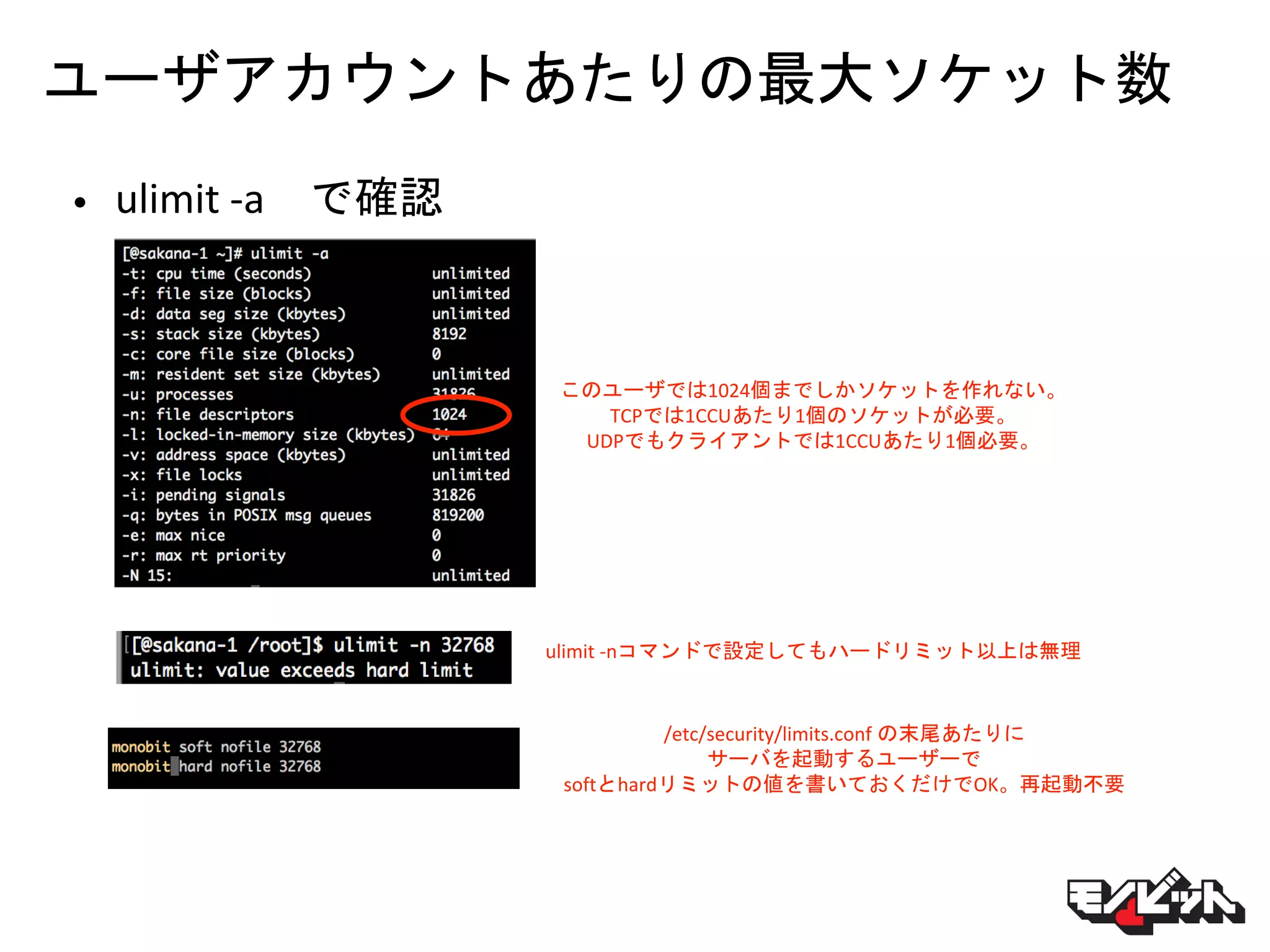
ユーザアカウントあたりの最大ソケット数 • ulimit -a
で確認 このユーザでは1024個までしかソケットを作れない。 TCPでは1CCUあたり1個のソケットが必要。 UDPでもクライアントでは1CCUあたり1個必要。 ulimit -nコマンドで設定してもハードリミット以上は無理 /etc/security/limits.conf の末尾あたりに サーバを起動するユーザーで softとhardリミットの値を書いておくだけでOK。再起動不要
58.
ローカルポート数の枯渇 • TCPまたはUDPのソケットを作ると、localポート番号が1個割り当てられる • CentOSやAmazon
Linuxの設定では、デフォルトで32768から60999までの28232個が使 われる。 • 28232個を超える数のソケットを作ることができない。 • Linuxカーネルの設定を変更することもできるが、推奨しない。 • インスタンスあたりCCUは28232よりだいぶ小さい数、 できれば10000〜15000以下で計画するのが良い。 • そのためにxlargeではなくlargeタイプを使うのも良い案となる。
59.
1インスタンスあたりの容量計画(最終案) サーバでの 合計パケット数 /sec/CCU ACKも含めた パケ数 15万pkt/secでの 限界CCU 安全マージン0.5 インスタンスタイプ ターン制ゲーム 1msg/sec 2 4
37500 18750 4コアマシン1台分を、 2コアマシン2台に分ける(9375CCU) 低速少量アクション クラッシュ系、 パズルやスポーツゲームなど 5msg/sec 10 20 7500 3750 4コアマシンでOK 高速大量アクション MOBAやRTS,物理があるFPSなど 30msg/sec 60 120 1250 625 4コアマシンでOK これで負荷テストで確認したいだいたいの性能の目標が得られた。 あてずっぽうの負荷テストを避けられる。
60.
mrs_room_benchの内容 • 配布物はサーバとクライアントの両方を含む • ビルド方法と起動方法 •
詳細は mrs_room_bench/README.md を参照 • サーバーを起動するには ./sv とするだけ • クライアントを起動する方法は後述 • 評価版の注意点 • 最大接続数が100に制限されている
61.
clプロセス mrs_room_bench 1:1構成 svプロセス user0 room0 room1 roomN user1 user2 user3 userN … … user4 user5 svプロセスにたいして clプロセスが多数のユーザーのかわりとなって負荷をかける ルームあたりのユーザー数は設定できる svもclも複数化できる
62.
mrs_room_bench 1:n構成 room0 room1 room2 … サーバーよりクライアントのほうが処理負荷が高くなるので、 svプロセスの最大性能が知りたい場合は、 1個に対してクライアント複数から負荷をかける必要がある sv cl0 cl1 user0 user1 user2 user3 user4 user5 user6 user7
63.
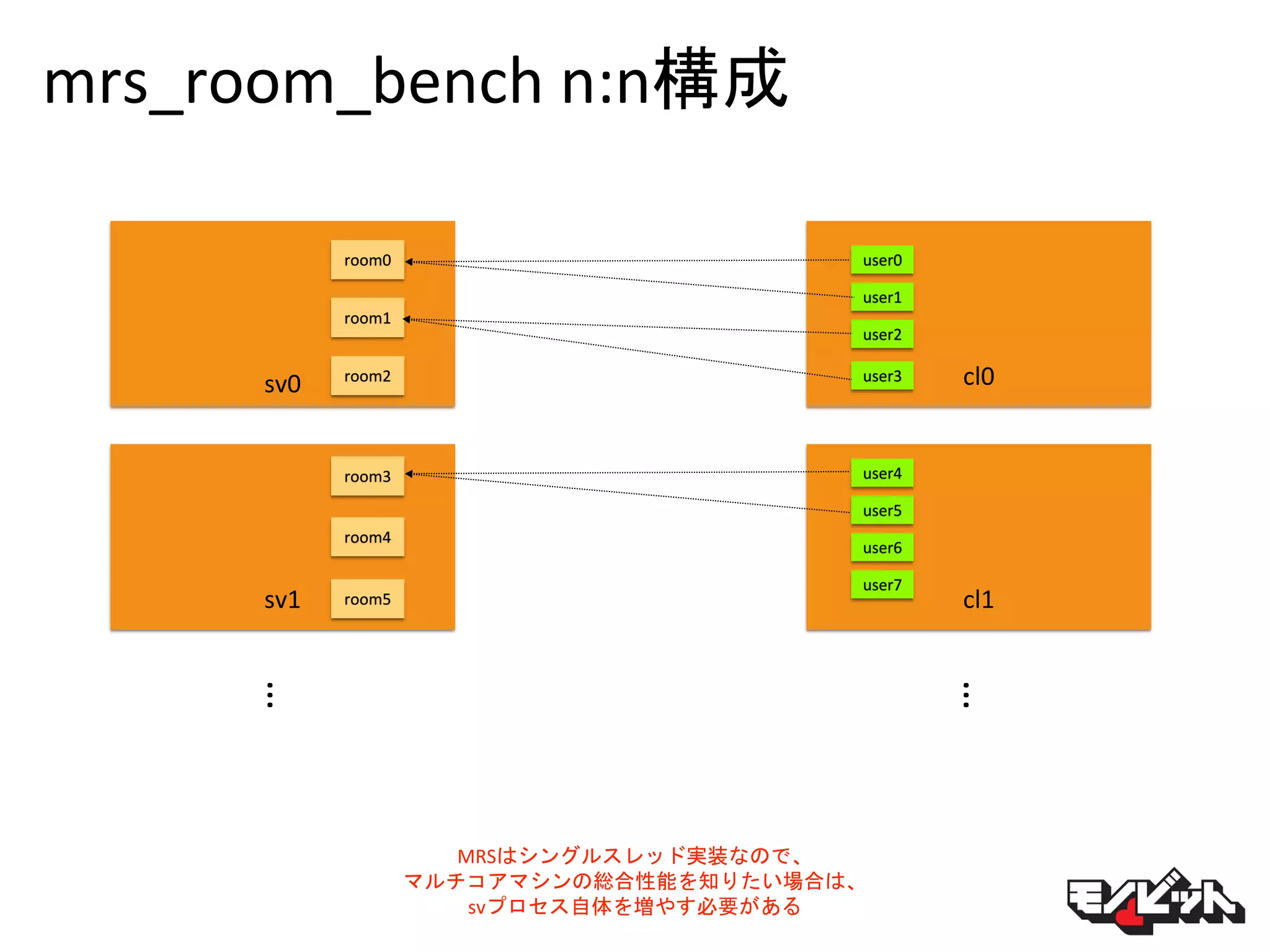
mrs_room_bench n:n構成 room0 room1 room2 … MRSはシングルスレッド実装なので、 マルチコアマシンの総合性能を知りたい場合は、 svプロセス自体を増やす必要がある sv0 room3 room4 room5sv1 … cl0 cl1 user0 user1 user2 user3 user4 user5 user6 user7
64.
mrs_room_benchの起動 • レポジトリのmany.shを修正して起動する • ADDR
: 接続先サーバーのIPアドレス • PROTO : 使用プロトコル。 TCP, UDP, WS, WSSのいずれか • N : 同時接続数。4の倍数がのぞましい(部屋あたり4人なので) • SIZE : メッセージサイズ。1以上64K以下、通常は32や200、大きい場合は5000〜10K以内で試す • ENC : 暗号化するかどうか。1なら有効、0なら無効 • INTERVAL : メッセージ送信間隔ミリ秒 • UNRELIABLE : UDPの場合これを1にすると信頼性なしモードで送信 • CREATEINTERVAL : ユーザーを新規作成する頻度。100ミリ秒を指定すると100ミリ秒ごとに新規接続をする
65.
mrs_room_benchの出力凡例 ここまで、毎秒10本づつCCUを増加させている ここから、負荷が安定している 現在時刻 unixtime pid ループ回数 クライアント数 (CCU) 送信間隔
送ったバイト数 受信バイト数(MiB) • manysv.sh では複数のサーバーをポート番号を変えながら同時に起動できる。 • 他にもオプションはたくさんあるので、 mrs_room_bench/README.mdを参照して下さい。
66.
mrs_room_benchのよくあるエラー • サーバーでのJOIN_ROOM_ERROR連発 mrs_room_benchのcliプログラムをctrl-cで止めてから、 30秒たたないと部屋が削除されないので再び作ることができないことが原因。 mrs_roomサーバーを再起動するか30秒待ってクリアされるかどちらかが必要。 「エラーで困ったらsv再起動」
Download