7
개요
개 요
빅데이터를 활용하는 가장 대표적인 예는 개인화 상품 추천 시스템
추천 시스템은 다양한 방법으로 구현할 수 있는데, 이 중 협업 필터링과
연관 규칙이 가장 많이 활용
하둡은 크게 하둡 분산 파일 시스템과 맵리듀스로 구분
하둡을 기반으로 한 다양한 오픈 소스 프로젝트가 등장했는데 이를 통
칭하여 하둡 에코 시스템이라 함.
8.
8
개요
협업 필터링과연관 규칙을 이용한 추천 시스템과 하둡 에코시스템
• 협업 필터링과 머하웃
– 협업 필터링은 추천 시스템 중 가장 인기가 많은 기법, 사용자 기반과 아이템
기반으로 구분
– 협업은 일부 사용자 아닌 많은 사용자의 경험을 최대한 활용한다는 의미
– 협업 필터링의 기본 입력 데이터 항목에는 평가 점수가 있음
– 필터링은 인터넷 정보 홍수에 대한 해결책 의미
– 협업 필터링 기법을 적용한 가장 유명한 기술이 바로 머하웃
– 머하웃은 자바 프로그래밍 언어로 구현된 추천 시스템 라이브러리이기 때문
에 개발하려면 자바 프로그래밍 언어와 클래스의 사용법 필요
9.
9
개요
• 연관 규칙과피그, 하이브, 샤크
– 연관 규칙은 구매 이력을 토대로 상품간의 관계를 알아내 추천하는 것으로, 장
바구니 분석 기법이라고도 함.
– 동시에 구매한 상품 조합의 빈도수를 계산하는 것을 시작으로 지지도, 신뢰도,
향상도를 계산해야 하므로 이에 대한 계산식과 알고리즘에 대한 이해가 있어
야 함.
– 상품 간의 빈도수 계산을 위해 메모리가 상당히 많이 필요하고 실행 시간도 길
어 상품 수가 적은 경우에만 적용이 가능하지만 하둡 기반의 분산 병렬 처리
시스템이용하면 연관 규칙 이용 대용량 데이터 쉽고 빠르게 처리 가능
10.
10
개요
• 웹 서비스와스쿱
– 웹 서비스를 위해서는 웹 서버, 웹 프로그래밍 언어, 관계형 데이터베이스가
필요하며, 하둡에 저장된 데이터를 관계형 데이터베이스로 전송하는 기능도
필요
– 이러한 기능을 지원하는 하둡 에코시스템이 바로 스쿱이다. 스쿱은 관계형 데
이터베이스의 데이터를 하둡 분산 파일 시스템으로 가져오는 기능도 지원
16
연관 규칙
연관규칙 기법과 피그, 하이브를 이용한 구현
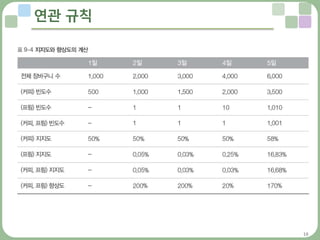
연관 규칙 기법의 원리
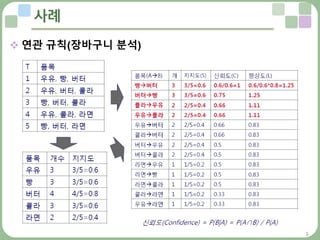
• 연관 규칙은 구매 이력을 토대로 상품간의 관계를 알아내 추천하는 기법
• 계산식
– 아이템 = A, B
– 트랜잭션 = 장바구니 = T
– 트랜잭션 수 = N(T)
– 상품 A 빈도수 = N(A)
– 상품 B 빈도수 = N(B)
– (A∩B)의 지지도Support = P(A∩B) = N(A∩B) / N(T)
– (A∩B)의 신뢰도Confidence = P(B|A) = P(A∩B) / P(A)
– (A∩B)의 향상도Lift = P(B|A) / P(B) = P(A∩B) / P(A)P(B)
17.
17
연관 규칙
• 계산식의용어와 지지도, 신뢰도, 향상도의 의미
– 아이템 : 아이템 A는 사용자가 구매하거나 선택한 아이템이고, 아이템 B는 아
이템 A를 선택한 사용자에게 추천할 아이템 목록
– 트랜잭션 : 트랜잭션을 쉽게 설명할 수 있는 용어로 바꾸면 바로 장바구니
– 지지도 : 지지도의 계산은 단일 아이템이나 아이템 조합의 빈도수를 장바구니
수로 단순히 나누어 주면 됨
– 신뢰도 : 커피를 구매한 사용자들 중에서 우유도 구매한 사용자들의 비율
– 향상도 :두 아이템 조합의 신뢰도를 아이템 B의 지지도로 나눈 값
➊ 새로운 상품이 나와서 처음 팔리면 빈도수는 1이고 향상도는 높게 나타난다.
➋ 구매자가 점차 늘면 빈도수는 증가하고 향상도는 그에 비례하여 떨어진다.
➌ 그러면 쇼핑몰에서 연관 규칙의 계산 결과를 이용할 때 향상도 값이 높은 것을
신상품 목록으로 보여준다.
➍ 향상도의 의미를 앞으로 더 많이 팔릴 상품으로 여긴다.
19
연관 규칙
• 연관규칙의설계
– 가장 기본적인 아이템 연관 규칙 적용
– 특정 아이템 A를 선택한 고객에게 추천할 아이템 B 목록에서 우선순위를 구하
기 위해 지지도, 신뢰도, 향상도 계산
– 다이어그램을 통해 데이터의 흐름 파악 : 의사코드로 작성한 후 피그 언어를
사용해 다이어그램을 완성
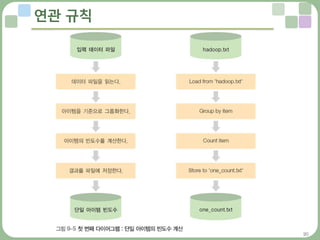
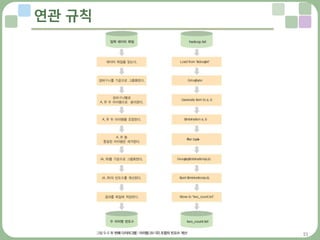
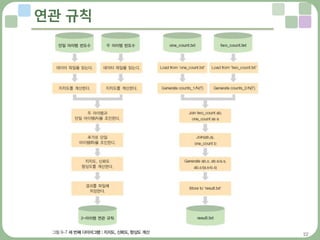
– 연관 규칙의 계산은 크게 세 단계로 구분
» 첫 번째는 아이템 A의 빈도수 계산, 두 번째는 아이템 A와 아이템 B의 조합에 대한
빈도수 계산, 마지막은 두 아이템 (A∩B)의 지지도, 신뢰도,향상도를 계산
24
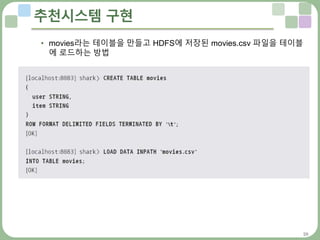
추천시스템 구현
추천시스템의 구현
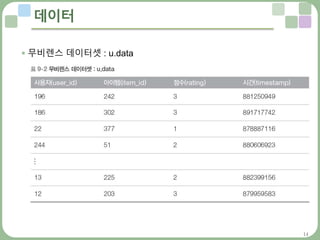
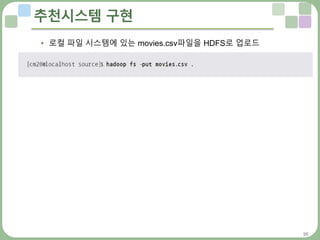
데이터 준비하기 : u.data
• 앞에서 언급한 무비렌스의 u.data를 입력 데이터로 사용
• 연관 규칙은 트랜잭션과 아이템 항목만 필요한데, 이 파일에서 트랜잭션
항목은 바로 사용자 아이디
• 연관 규칙에 필요한 상수인 트랜잭션 수는 데이터셋의 사용자 수
31
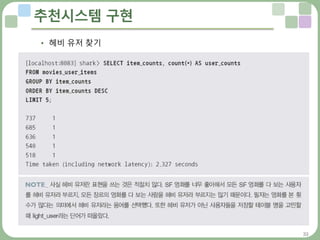
추천시스템 구현
아이템(A∩B) 조합의 빈도수 계산하기 : 샤크
• 아이템 (A∩B) 조합의 빈도수 계산 시 중간 단계에서 레코드 수 급증
• 맵리듀스는 데이터를 잘게 쪼개고 다수의 머신에서 분산 병렬 처리되므로
• 대용량 데이터를 처리할 수 있는 장점이 있지만,
• 최소 단위의 태스크 작업은 절대 한 머신의 컴퓨팅 자원 한도를 초과 불가
32.
32
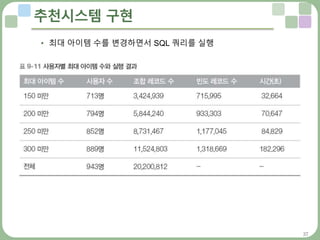
추천시스템 구현
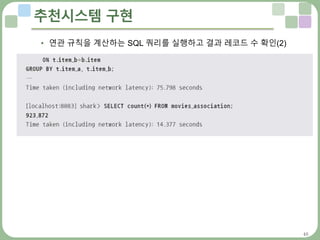
• 100K데이터셋의 빈도수를 계산하기 전에 중간 단계의 레코드 수를 확인
• 먼저 장바구니(사용자)별 아이템 수를 계산하기 위해 임시 테이블을 생성
• 조합 레코드 수를 확인하는 쿼리 실행
39
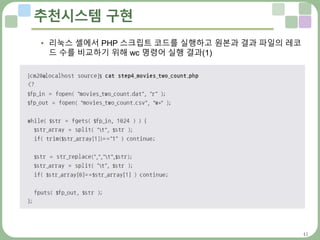
추천시스템 구현
연관규칙 계산하기 : PHP와 샤크
• 아이템 A와 동일한 아이템 B를 제거하고, 빈도수가 너무 적은 레코드도
추천 시스템에 도움이 되지 않으므로 이를 삭제하는 기능을 함께 구현
• 이 기능 외에도 추가요청이 있을 수 있으므로 SQL 쿼리로 그 기능을 구현
하는 것보다는 쉽게 변경할 수 있는 PHP스크립트 사용
47
추천시스템 구현
데이터내보내기 : 스쿱
• 웹 서비스로 추천 시스템 구현하는 단계로 넘어가기 전에 하둡에 저장된
결과 데이터를 MySQL로 내보내는 작업 실시
• 먼저 스쿱으로 하이브 테이블의 데이터를 MySQL로 내보내기 전에
MySQL에 결과 데이터를 저장할 테이블을 미리 생성
49
추천시스템 구현
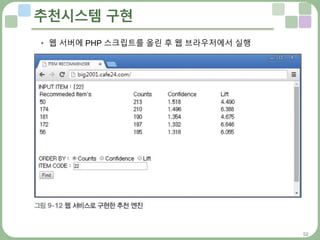
웹서비스로 추천 기능 구현하기 : PHP
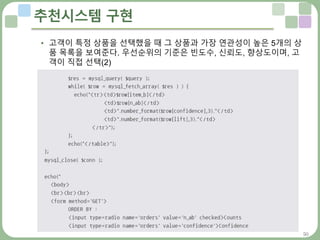
• 사용자에게 좋은 상품을 추천하는 과정
• 고객이 특정 상품을 선택했을 때 그 상품과 가장 연관성이 높은 5개의 상
품 목록을 보여준다. 우선순위의 기준은 빈도수, 신뢰도, 향상도이며, 고
객이 직접 선택(1)
50.
50
추천시스템 구현
• 고객이특정 상품을 선택했을 때 그 상품과 가장 연관성이 높은 5개의 상
품 목록을 보여준다. 우선순위의 기준은 빈도수, 신뢰도, 향상도이며, 고
객이 직접 선택(2)
51.
51
추천시스템 구현
• 고객이특정 상품을 선택했을 때 그 상품과 가장 연관성이 높은 5개의 상
품 목록을 보여준다. 우선순위의 기준은 빈도수, 신뢰도, 향상도이며, 고
객이 직접 선택(3)



![# 경력
- 국민대학교 빅데이터경영MBA과정 겸임교수
- 숙명여자대학교 빅데이터센터 연구소장
- ‘12~’16 : 충북대학교 비즈니스데이터융합학과 교수
- ‘00~’11 : 닷컴솔루션 대표
# 저서 및 역서
- [실전 하둡 운용 가이드] 한빛미디어, 2013.07
- [빅데이터 컴퓨팅 기술] 한빛아카데미, 2014.06
- [비주얼 컴플렉시티] 한빛미디어, 2016.04
- [하둡완벽가이드 개정4판] 한빛미디어, 2017.03
장형석 교수](https://image.slidesharecdn.com/201710-171027114238/85/slide-2-320.jpg)




































![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [개미야 뭐하니?팀] : 투자자의 반응을 이용한 실시간 등락 예측(feat. 카프카)](https://cdn.slidesharecdn.com/ss_thumbnails/06-220124105013-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [투니버스] : 스파크 기반 네이버 웹툰 댓글 수집 및 분석](https://cdn.slidesharecdn.com/ss_thumbnails/random-230809123044-ba4ea828-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [#인스타툰 팀] : 해시태그 기반 인스타툰 추천 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728125517-c1a27331-thumbnail.jpg?width=640&height=640&fit=bounds)




![[우리가 데이터를 쓰는 법] 좋다는 건 알겠는데 좀 써보고 싶소. 데이터! - 넘버웍스 하용호 대표](https://cdn.slidesharecdn.com/ss_thumbnails/3-160416163055-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)





![[시스템종합설계].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3doit-220608124356-ea37a6e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [직행복] : 실시간 로그 처리 기반 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124036-52794fc9-thumbnail.jpg?width=640&height=640&fit=bounds)












![[PYCON Korea 2018] Python Application Server for Recommender System](https://cdn.slidesharecdn.com/ss_thumbnails/20180818pyconapplicationserverforrecommendersystematkakaorev3-180819041338-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PYCON Korea 2018] Python Application Server for Recommender System](https://cdn.slidesharecdn.com/ss_thumbnails/20180818pyconapplicationserverforrecommendersystematkakaorev3-180820011512-thumbnail.jpg?width=640&height=640&fit=bounds)











![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)