HPE Apollo Systemファミリー
4
HPE Apollo 2000
HPE Apollo 4000 ファミリー
Scalable Multi-node
Storage Density
HPE Apollo 6000
HPE Apollo 8000
Rack-scale Efficiency
Warm-water Supercomputer
ワークロードに最適化されたモジュラー型サーバー
HPE Apollo 6500
2Uサーバートレイに8 GPU搭載
4Uシャーシに2サーバー・16 GPUを稼働
Tesla K80、M40、P100*をサポート
「電源の外出し」で熱と温度の課題に対処
Ultra-dense GPU Server
* Tesla P100は11月販売開始予定
New
5.
HPE Apollo 6500とは
Ultra-dense GPU Server
5
サーバー
HPE ProLiant XL270d Gen9
シャーシ
HPE Apollo d6500 chassis
外付けパワーサプライ
HPE Apollo 6000 Power Shelf
GPU×4枚
GPU×4枚
• 最大8 GPU搭載可能な2Uラックサーバー
• 1シャーシに2サーバーを搭載
• 実績豊富な「ProLiant」 (M/BはApollo 2000)
• サーバーノードは個別メンテナンス可
• 前面抜き挿し型サーバートレイ
• 前面アクセス ホットプラグドライブ
• 冗長性のホットプラグ冷却ファン
• HPE Apollo 6000 で実績豊富な
1.5U パワーシェルフ
4U
2U
ディープラーニングを念頭にGPU搭載密度を追及したマルチノードサーバー
6.
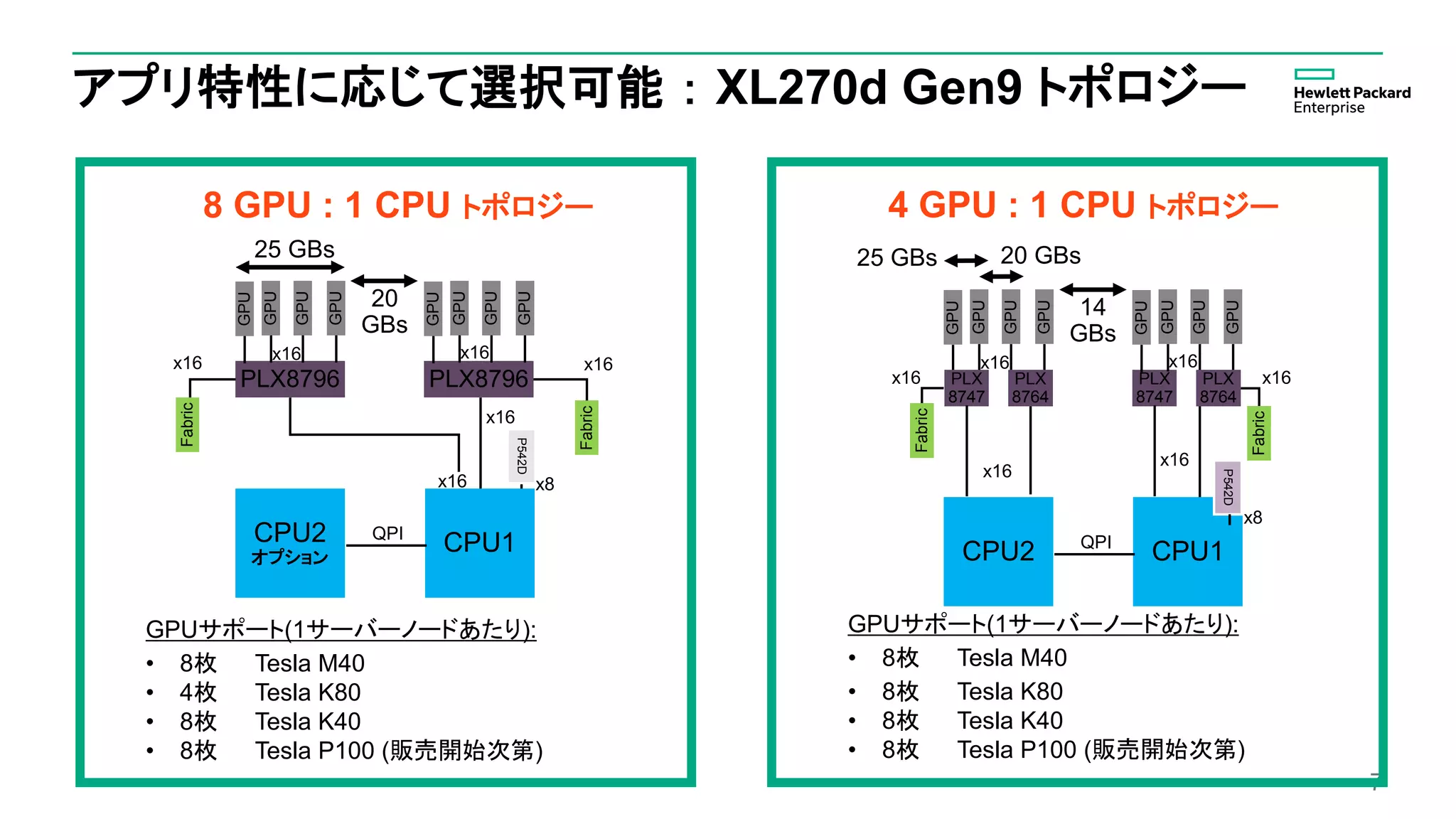
HPE ProLiant XL270dGen9 基本仕様
6
項目 仕様
ラック 奥行1,200mm ラック推奨
シャーシ HPE Apollo d6500 シャーシ (4U、2台のサーバートレイ、1シャーシ最大16 GPU稼働)
プロセッサー インテル Xeon プロセッサー E5-2600 v4 ファミリー
電源 HP Apollo 6000 パワーシェルフ
メモリ 16×2,400MHz DDR4 DIMM、最大容量1,024GB (16 x 64GB DIMM)
ネットワーク
オプション
• 2×1GbE シングルポート モジュール標準搭載
• 2×PCI Express x16 LPスロットにInfiniBand、OmniPath(リリース後)、Ethernet アダプタ搭載可能
(1Gb, 10Gb, 25GbE)
I/O スロット
1サーバートレイあたり8枚の350W GPUをサポー
• 1×PCI Express x8 メザニン型スロット (Smartアレイ用)
• 2×PCE Express x16 ロープロファイル スロット
ストレージ 最大8本のホットプラグ式 SFF SAS HFF/ SATA HDD/ SSD – 前面アクセスドライブ
アクセラレータ
• NVIDIA Tesla: K80, M40 (K40 ~ 9月予定) Pascal GPU (発表され次第)
• インテル Xeon Phi KNL (PCIe用発表され次第)
• AMD : FirePro S9150
管理 HP iLO 4, HP Advance Power Manager
OS Red Hat Enterprise Linux 6.7, 7.2, SLES 11 SP4, 12, MS Windows Server 2012 R2





















![[JANOG35.5] WhiteBox SW検証 ~サーバサイド編~](https://cdn.slidesharecdn.com/ss_thumbnails/janog35-5whiteboxnakano-150417035713-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)











![[SAPPORO CEDEC] サービスの効果を高めるグリー内製ツールの技術と紹介](https://cdn.slidesharecdn.com/ss_thumbnails/greetools-141130213632-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Red Hat Forum 2017] Ansible Towerの実践!!エンタープライズのInfrastructure as Codeの現在(イマ)](https://cdn.slidesharecdn.com/ss_thumbnails/redhatforumv04-171020081056-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)

















