







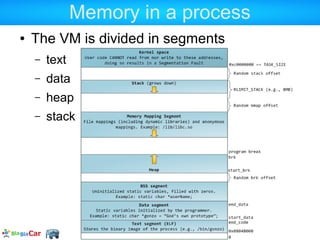
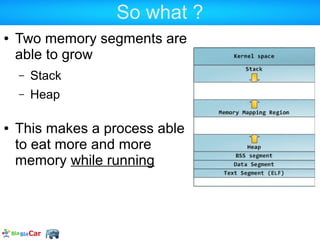









![ZendMM in PHP user land
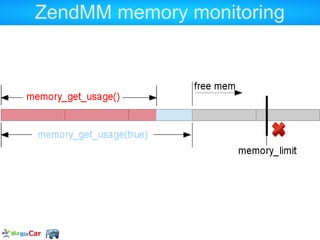
memory_limit (INI setting)
memory_get_usage(true)
Returns the size of all the allocated segments
memory_get_usage()
Returns the occupied size in all the allocated
segments
memory_get_[peak]_usage([real])
Returns the max memory that has been
allocated/used. Could have been freed meantime](https://image.slidesharecdn.com/allowedmemorysizeexhausted-130125100721-phpapp02/85/Understanding-PHP-memory-26-320.jpg)



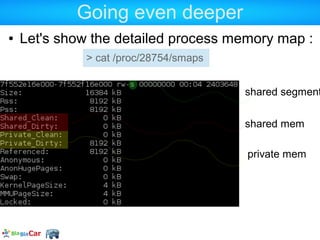
![Massif details
94.52% (2,534,247B) (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
->39.11% (1,048,576B) 0x87A7BB: zend_interned_strings_init (zend_string.c:48)
|
->17.70% (474,464B) 0x866449: _zend_hash_quick_add_or_update (zend_alloc.h:95)
| ->16.48% (441,936B) 0x85F66D: zend_register_functions (zend_API.c:2138)
|
->11.93% (320,000B) 0x878625: gc_init (zend_gc.c:124)
| ->11.93% (320,000B) 0x8585DF: OnUpdateGCEnabled (zend.c:82)
| ->11.93% (320,000B) 0x86E353: zend_register_ini_entries (zend_ini.c:208)](https://image.slidesharecdn.com/allowedmemorysizeexhausted-130125100721-phpapp02/85/Understanding-PHP-memory-33-320.jpg)













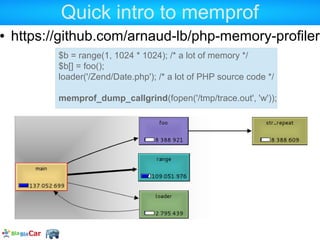














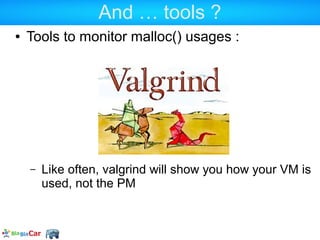
![Quick intro to memprof
https://github.com/arnaud-lb/php-memory-profiler
$b = range(1, 1024 * 1024); /* a lot of memory */
$b[] = foo();
loader('/Zend/Date.php'); /* a lot of PHP source code */
memprof_dump_callgrind(fopen('/tmp/trace.out', 'w'));](https://image.slidesharecdn.com/allowedmemorysizeexhausted-130125100721-phpapp02/85/Understanding-PHP-memory-64-320.jpg)


This document provides an overview of PHP memory usage and management. It introduces key concepts like the Zend Memory Manager (ZendMM), which handles memory allocation and freeing for each PHP request. The document demonstrates how to monitor memory usage from PHP using functions like memory_get_usage() and from the OS perspective using /proc. It also discusses potential memory issues like references and circular references, and how to track reference counts. The goal is to help understand and optimize PHP memory consumption.























































































