Machine Learning이란
“A computerprogram is said to learn from experience E with respect to some task T and some
performance measure P, if its performance on T, as measured by P, improves with experience E.”
- 프로그램 스스로 어떤 문제를 해결할 수 있도록 모델을 학습시키는 알고리즘의 통칭
- 해결해야 하는 문제와 상황에 따라 적절한 기법을 선택
- 학습의 기본 : ‘적용 평가 (피드백) 수정(업데이트)’의 반복
- 예측 (ex. 부동산 가격, 날씨 등)
- 분류 (ex. 이미지, 기사, 소비자 Segment 등)
- Linear Regression
- Logistic Regression
- Classification / Clustering
- Neural Network
3.
Supervised vs. UnsupervisedLearning
- 공부하는 방법은 크게 두 가지이다! : 누군가의 가이드를 받거나 나 혼자 죽어라 하거나
- Supervised Learning (지도학습)
내가 수학 문제를 맞게 풀었는지 틀렸는지 답안지를 보고 채점하는 것
Labeled Training Set이 주어진 학습법.
예를 들어, 1000개의 이미지를 가지고 이미지 분류하는 알고리즘을 학습시켜 나간다고 하면, 1번은
고양이 이미지라는 정답이 주어지기 때문에 모델에 따라 분류했을 때 1번을 자동차 이미지로 분류할
경우, 모델을 수정해야 한다는 피드백을 준다.
* Labeled Data : a group of samples that have been tagged with one or more labels (Wikipedia). 데이터에 대한 정보가 표시되어 있는
데이터 그룹을 나타낸다. 예를 들어, 이미지 분석에서, A는 고양이 이미지, B는 자동차 이미지라는 것을 미리 정리해놓은 데이터 그룹을
Labeled Data라고 한다. Labeled Data는 지도학습 기법에서 Training Set에 사용한다.
* Training Set : 학습시킨 모델의 정확도를 판단하기 위해서 보통 Training Set과 Test Set을 나눠서 평가한다. 1000개의 데이터가 있을 때
700개의 데이터(Training Set)로 모델을 학습시킨 다음, 해당 모델을 Test Set에 적용하여 정확도를 측정하는 것이다. Training Set에서는
정확도가 높던 모델이 Test Set에서는 정확도가 낮아진다면 모델이 특정 Training Set에만 맞춰서 학습되었다고 판단하고, 이를 Training
Set에 Over-fit 되었다고 한다.
4.
Supervised vs. UnsupervisedLearning
- Unsupervised Learning (비지도학습)
채점할 답안지가 없다!
모델을 데이터에 적용했을 때 결과값과 비교할 수 있는 정답이 없다. Labeled Data가 주어지지 않는다.
구글 뉴스를 예로 들면, 수많은 기사가 데이터로 주어지지만 ‘A 기사는 (가) 이슈에 대한 기사이고, B 기
사는 (나) 이슈에 대한 기사’라는 데이터 라벨은 주어지지 않는다. 하지만 비지도학습 기법을 사용해서
데이터 간의 연관성을 찾아내 자동으로 같은 이슈를 다루고 있는 여러 기사를 그룹핑해서 사용자에게
보여준다.
5.
Structured vs. UnstructuredData
- 분류되어 있는 데이터와 그렇지 않은 데이터
- 가장 많이 사용하는 예인 아파트 가격 예측 문제를 예로 생각해보자. 아파트 가격에 영향을 미칠
수 있는 요인들, 방 개수, 평수, 위치, 건물 높이, 가구수 등을 기준으로 각 아파트 세대의 데이터를
표시할 수 있다 (Structured Data).
- 하지만 글을 통해 글쓴이의 심리를 분석하는 문제가 있다고 가정하면, A라는 사람이 작성한 글 전
체가 데이터가 될 것인데, 텍스트 데이터의 경우 위와 같이 어떤 정돈된 형태로 구성하기 쉽지
않다 (Unstructured Data).
6.
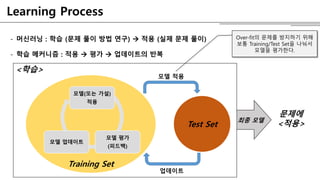
- 머신러닝 :학습 (문제 풀이 방법 연구) 적용 (실제 문제 풀이)
- 학습 메커니즘 : 적용 평가 업데이트의 반복
Training Set
<학습>
Learning Process
모델(또는 가설)
적용
모델 평가
(피드백)
모델 업데이트
최종 모델
문제에
<적용>Test Set
모델 적용
업데이트
Over-fit의 문제를 방지하기 위해
보통 Training/Test Set을 나눠서
모델을 평가한다.
7.
모델 평가 (손실함수, Loss Function)
- 설정한 모델을 적용하고 해당 모델이 효과적인지 판단하면서 학습이 진행되는데 과연 어떤 기준
으로 판단할 것인가
- 손실함수(Loss Function) : 현재의 모델로 예측한 결과값이 훈련 데이터의 ‘정답’과 얼마나 차이
나는지 구하는 함수, 값이 작을수록 성능이 좋은 모델이라는 것을 의미한다.
평균 제곱 오차 (Mean Squared Error, MSE)
교차 엔트로피 오차 (Cross Entropy Error, CEE)
8.
모델 업데이트 (GradientDescent)
- 사용한 모델을 평가한 이후 결과에 따른 피드백을 주는 것이 필요
- 피드백, 즉 모델을 업데이트 하는 방법은 여러 가지가 있지만 대부분의 기법은 가장 기본이 되는
경사하강법 (Gradient Descent)에서 파생된 것들로 이해할 수 있다.
- 학습의 목표는 손실함수 값을 최소화하는 것!
* 함수 그래프가 아래로 오목한 포물선일 때,
그래프의 기울기가 0인 지점이 함수의 최소값
모델이 복잡해질수록 손실함수 그래프 역시 복잡해지기 때문에 2차 함수 그래프처럼 기울기가 0인 지점을
쉽게 찾을 수 없다는 문제가 발생한다.
경사하강법(Gradient Descent)의 기본적인 아이디어는 이렇다.
우리가 학습을 할 때 복잡한 손실함수 그래프의 전체적인 모양은 알 수 없지만 적어도 현재 위치에서의
순간 기울기(Gradient, 미분 값)는 알 수 있기 때문에 기울기 방향으로 조금씩 내려간다면(Descent)
기울기가 0인 지점에 다다를 수 있을 것이다.
9.
경사하강법 (Gradient Descent)
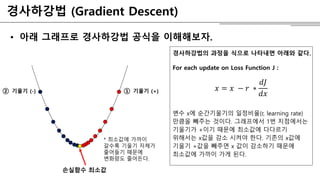
•아래 그래프로 경사하강법 공식을 이해해보자.
경사하강법의 과정을 식으로 나타내면 아래와 같다.
For each update on Loss Function J :
𝑥 = 𝑥 − 𝑟 ∗
𝑑𝐽
𝑑𝑥
변수 x에 순간기울기의 일정비율(r, learning rate)
만큼을 빼주는 것이다. 그래프에서 1번 지점에서는
기울기가 +이기 때문에 최소값에 다다르기
위해서는 x값을 감소 시켜야 한다. 기존의 x값에
기울기 +값을 빼주면 x 값이 감소하기 때문에
최소값에 가까이 가게 된다.
손실함수 최소값
① 기울기 (+)② 기울기 (-)
* 최소값에 가까이
갈수록 기울기 자체가
줄어들기 때문에
변화량도 줄어든다.
10.
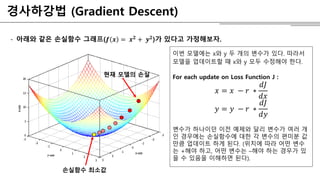
경사하강법 (Gradient Descent)
-아래와 같은 손실함수 그래프(𝒇 𝒙 = 𝒙 𝟐 + 𝒚 𝟐)가 있다고 가정해보자.
손실함수 최소값
현재 모델의 손실
이번 모델에는 x와 y 두 개의 변수가 있다. 따라서
모델을 업데이트할 때 x와 y 모두 수정해야 한다.
For each update on Loss Function J :
𝑥 = 𝑥 − 𝑟 ∗
𝑑𝐽
𝑑𝑥
𝑦 = 𝑦 − 𝑟 ∗
𝑑𝐽
𝑑𝑦
변수가 하나이던 이전 예제와 달리 변수가 여러 개
인 경우에는 손실함수에 대한 각 변수의 편미분 값
만큼 업데이트 하게 된다. (위치에 따라 어떤 변수
는 +해야 하고, 어떤 변수는 –해야 하는 경우가 있
을 수 있음을 이해하면 된다).








![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)















![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)























![[2012 2] 1주차 사회적경제 개요](https://cdn.slidesharecdn.com/ss_thumbnails/2012-21-120920113440-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2012 2] 1주차 사회적경제의 역사](https://cdn.slidesharecdn.com/ss_thumbnails/2012-21-120920112943-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)