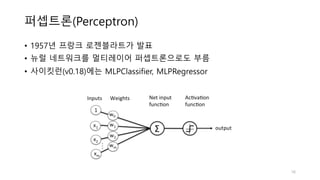
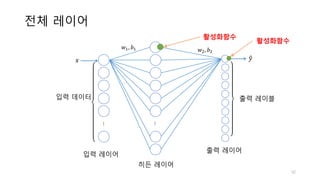
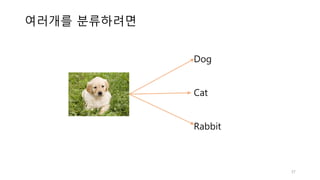
선형 회귀와 로지스틱회귀
• 선형 회귀분석은 연속된 숫자를 예측합니다.(Regression)
• 환율 가격 예측, 농작물 수확량 등
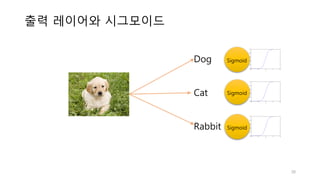
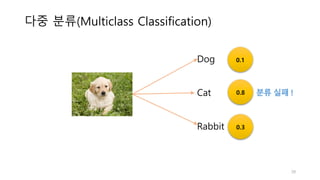
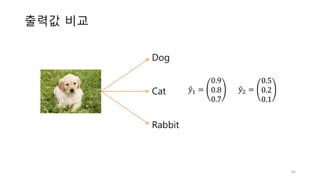
• 로지스틱 회귀는 미리 정의된 클래스 레이블을 예측합니다(Classification)
• 이진분류: 스팸분류, 암진단, 다중 분류: 손글씨 숫자 분류
4
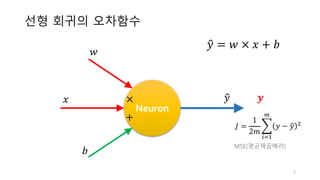
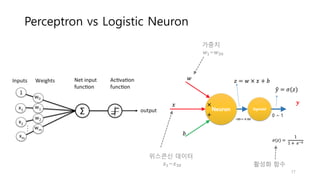
𝑦" = 𝑤 × 𝑥 + 𝑏
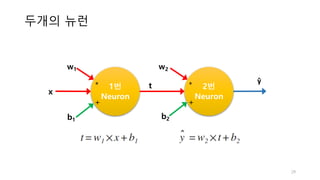
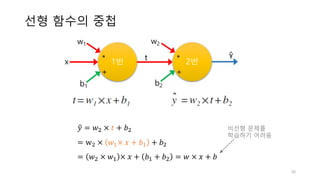
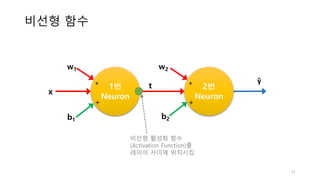
학습
• 여기서는 예를간단히 하기위해 학습 데이터로 모델의 성능을
평가했습니다만 실전에서는 이렇게 해서는 안됩니다
prediction 의 모든 원
소에 적용, 0.5보다 크
면 True, 작으면 False[569, 1] 크기
5000번 학습하면서
손실함수 값 기록
92% 정확도
13
14.
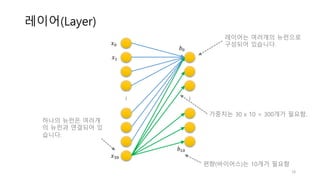
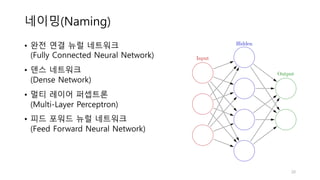
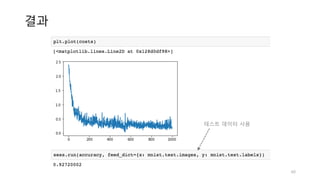
정리
• 선형 회귀
•회귀 모델입니다.
• 선형 회귀의 대표적인 비용함수는 MSE(mean square error)입니다.
• 경사하강법을 사용하여 점진적으로 최적의 값을 찾았습니다.
• 특성이 많을 경우 성능이 뛰어나며 대량의 데이터셋에도 잘 동작합니다.
• 로지스틱 회귀
• 분류 모델 입니다.
• 이진 분류의 경우 시그모이드 함수의 결과가 0.5 보다 높을 때는 True, 그 이하는
False 로 분류합니다.
• 시그모이드 함수를 사용한 로지스틱 회귀의 비용함수 미분의 결과는 선형 회귀와 동
일합니다.
14
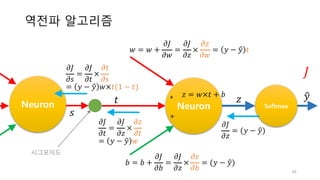
SGD, mini-batch GD
•Batch 그래디언트 디센트
• 전체 훈련 데이터를 사용
• 가장 좋은 방법, 대규모 데이터 셋에 적용하기 힘
듬
• SGD(Stochastic Gradient Descent):
• 훈련 데이터 하나씩 사용
• 빠른 학습 가능, 노이즈 데이터로 인해 변동이 큼
• mini-batch GD
• 훈련 데이터를 조금씩 나누어 사용
• Batch 와 SGD의 절충안으로 일정 개수의 데이터
를 이용하여 학습
50







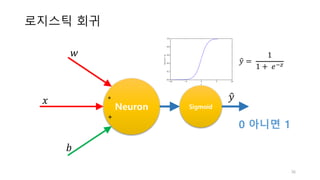
![로지스틱 회귀 학습
10
Neuron Sigmoid
𝑥 ×
+
𝒚𝑦"
𝑤 = 𝑤 + ∆𝑤 = 𝑤 +
1
𝑚
(𝑦 − 𝑦")𝑥
𝑏 = 𝑏 + ∆𝑏 = 𝑏 +
1
𝑚
(𝑦 − 𝑦")
(𝑦 − 𝑦")
𝐽 = −
1
𝑚
/[𝑦𝑙𝑜𝑔 𝑦" + 1 − 𝑦 log (1 − 𝑦")]
2
345
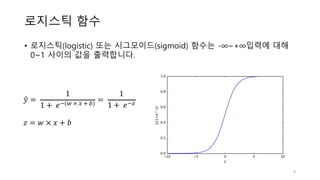
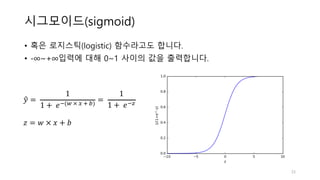
𝑦" = 𝜎(𝑧) =
1
1 + 𝑒:?𝑧 = 𝑤 × 𝑥 + 𝑏](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-10-320.jpg)
![로지스틱 회귀 예제
11
0.2
0.6
⋯
0.1
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
0.1
⋮
0.3
=
1.5
5.9
⋮
0.7
+ 0.1 =
1.6
6.0
⋮
0.8
30개 가중치
569개 샘플
𝑥 × 𝑊 + 𝑏 = 𝑦"
[569, 30] x [30, 1] = [569, 1] + [1] = [569, 1]
1개 편향(bias)30개 특성
569개 결과
(logits)](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-11-320.jpg)

![학습
• 여기서는 예를 간단히 하기위해 학습 데이터로 모델의 성능을
평가했습니다만 실전에서는 이렇게 해서는 안됩니다
prediction 의 모든 원
소에 적용, 0.5보다 크
면 True, 작으면 False[569, 1] 크기
5000번 학습하면서
손실함수 값 기록
92% 정확도
13](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-13-320.jpg)



![로직스틱의 행렬 계산
22
...𝑥Z
𝑥5
𝑥YZ
𝑏Z
𝑥5
0.6
⋯
𝑥YZ
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
𝑤5
⋮
𝑤YZ
=
1.5
5.9
⋮
0.7
+ 0.1 =
1.6
6.0
⋮
0.8
30개 가중치:
569개 샘플에
모두 적용
569개 샘플
𝑥 × 𝑊 + 𝑏 = 𝑧
[569, 30] x [30, 1] = [569, 1] + [1] = [569, 1]
1개 편향(bias):
569개 샘플에 모두 적용
(브로드캐스팅)30개 특성
569개 결과
(logits)](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-22-320.jpg)
![뉴런의 계산식
23
A
B
C
a
b
𝑤[
𝑤[]
𝑤[^
𝑏[
𝑎 = 𝐴×𝑤[ + 𝐵×𝑤[] + 𝐶×𝑤[^ + 𝑏[
𝑨 𝑩 𝑪 ×
𝒘 𝒂𝑨
𝒘 𝒂𝑩
𝒘 𝒂𝑪
+ 𝒃 𝒂 = (𝒂)
행렬 곱으로 표현 가능](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-23-320.jpg)
![행렬 표현
24
A
B
C
a
b
𝑤[
𝑤[]
𝑤[^
𝑏[
𝑎 = 𝐴×𝑤[ + 𝐵×𝑤[] + 𝐶×𝑤[^ + 𝑏[
𝑏 = 𝐴×𝑤> + 𝐵×𝑤>] + 𝐶×𝑤>^ + 𝑏>
𝑨 𝑩 𝑪 ×
𝒘 𝒂𝑨 𝒘 𝒃𝑨
𝒘 𝒂𝑩 𝒘 𝒃𝑩
𝒘 𝒂𝑪 𝒘 𝒃𝑪
+ 𝒃 𝒂 𝒃 𝒃 = (𝒂 𝒃)](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-24-320.jpg)
![행렬 표현
25
A
B
C
a
b
𝑤>
𝑤>]
𝑤>^ 𝑏>
𝑎 = 𝐴×𝑤[ + 𝐵×𝑤[] + 𝐶×𝑤[^ + 𝑏[
𝑨 𝑩 𝑪 ×
𝒘 𝒂𝑨 𝒘 𝒃𝑨
𝒘 𝒂𝑩 𝒘 𝒃𝑩
𝒘 𝒂𝑪 𝒘 𝒃𝑪
+ 𝒃 𝒂 𝒃 𝒃 = (𝒂 𝒃)
𝑏 = 𝐴×𝑤> + 𝐵×𝑤>] + 𝐶×𝑤>^ + 𝑏>](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-25-320.jpg)
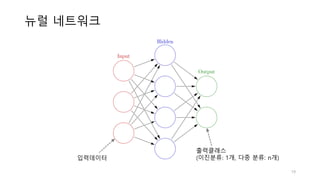
![레이어의 행렬 계산
26
𝑥5
0.6
⋯
𝑥YZ
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
𝑤5
5
⋮
𝑤YZ
5
⋱
𝑤5
5Z
⋮
𝑤YZ
5Z
=
1.5
5.9
⋮
0.7
⋱
1.1
0.2
⋮
0.5
+ 𝑏5 ⋯ 𝑏YZ =
1.2
2.9
⋮
1.7
⋱
1.6
2.2
⋮
4.1
569 x 10 크기
569개
샘플
𝑥 × 𝑊 + 𝑏 = 𝑧
[569, 30] x [30, 10] = [569, 10] + [10] = [569, 10]
10개 편향(bias)
30개 특성
569 x 10개 결과
(logits)
...
𝑥Z
𝑥5
𝑥YZ
𝑏Z
𝑏5Z
30 x 10개
가중치](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-26-320.jpg)



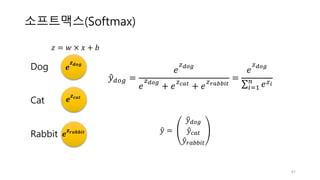
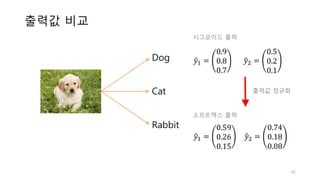
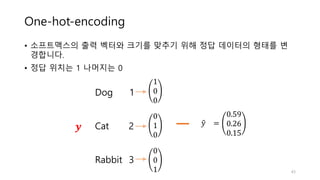
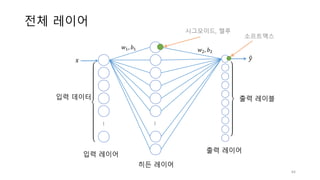

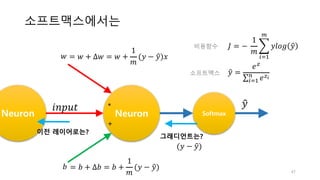
![로지스틱회귀의 그래디언트
Neuron Sigmoid
𝑥 ×
+
𝒚𝑦"
𝑤
𝑏
(𝑦 − 𝑦")
46
𝑦" = 𝜎(𝑧) =
1
1 + 𝑒:?
𝐽 = −
1
𝑚
/[𝑦𝑙𝑜𝑔 𝑦" + 1 − 𝑦 log (1 − 𝑦")]
2
345
비용함수
시그모이드](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-46-320.jpg)





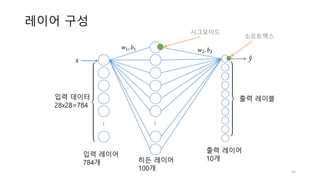

![첫번째 레이어
• 활성화 함수는 텐서의 차원에 영향을 미치지 않습니다.
56
100개 가중치
?개 샘플
𝑥 × 𝑊 + 𝑏 = 𝑠
𝑡 = 𝜎(𝑠)
[?, 784] x [784, 100] + [100] = [?, 100]
100개 편향(bias)
784개 특성
?개 결과
𝑥5
0.6
⋯
𝑥YZ
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
𝑤5
5
⋮
𝑤’“”
5
⋱
𝑤5
5ZZ
⋮
𝑤’“”
5ZZ
+ 𝑏5 ⋯ 𝑏5ZZ =
1.2
2.9
⋮
1.7
⋱
1.6
2.2
⋮
4.1](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-56-320.jpg)
![𝑡5
0.6
⋯
𝑡5ZZ
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
𝑤5
5
⋮
𝑤5ZZ
5
⋱
𝑤5
5Z
⋮
𝑤5ZZ
5Z
+ 𝑏5 ⋯ 𝑏5Z =
1.2
2.9
⋮
1.7
⋱
1.6
2.2
⋮
4.1
두번째 레이어
57
10개 가중치
?개 샘플
𝑡 × 𝑊 + 𝑏 = 𝑧
[?, 100] x [100, 10] + [10] = [?, 10]
10개 편향(bias)
100개 특성
?개 결과](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-57-320.jpg)
![학습 설정
58
argmax(y) = [?]
argmax(y_hat) = [?]
y = [?, 10]
z = [?, 10]
불리언을 숫자로 바꾸고
평균을 냅니다.
[True, False, True,... ] à [1.0, 0.0, 1.0, ...]
소프트맥스 통과전 : z
소프트맥스 통과후 : y_hat](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-58-320.jpg)
![미니 배치 훈련
59
100개씩 데이터 샘플링
x: [100, 784]
y: [100, 10]](https://image.slidesharecdn.com/3-170425110206/85/3-neural-networks-59-320.jpg)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)






![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)



![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)














![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)














![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181127072259-thumbnail.jpg?width=640&height=640&fit=bounds)









