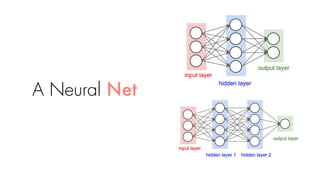
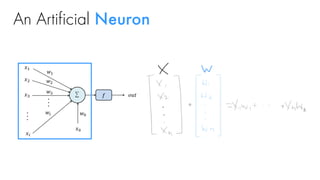
Loss functions
우리가 배울때,
얼마나 틀렸는지를 알아야 합니다. 그래야 얼만큼 고칠지를 알 수 있습니다.
정답지랑 비교해서 얼마나 틀렸는지를 통해 학습을 진행합니다.
따라서 최대한 틀리지 않게 학습해야 합니다.
= minimize the Loss
= Optimization
결국 어떤함수의최솟값찾기
출처: 하용호님 발표
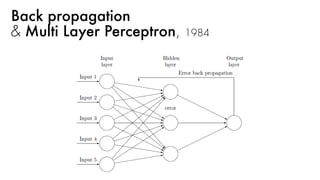
VanishingGradient
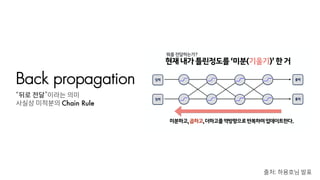
Back-prop에서 발생할 수 있는 문제
Layer가 많을수록 업데이트가 사라져간다
그래서 fitting이 잘 안 된다[underfitting]
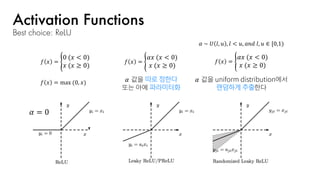
Best choice: ReLU
121.
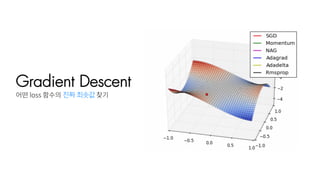
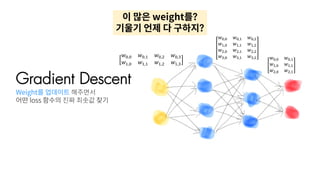
Gradient Descent
전체 Data를다 본 후 loss를 구해서
Weight를 업데이트 해주면서
어떤 loss 함수의 진짜 최솟값 찾기
전체 데이터를 다 보고
1 걸음 간다 (update)
이걸 m번 반복
BATCH
Gradient Descent
122.
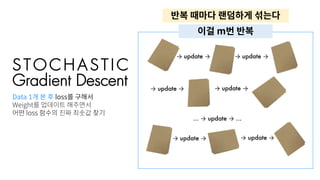
S T OC H A S T I C
Gradient Descent
Data 1개 본 후 loss를 구해서
Weight를 업데이트 해주면서
어떤 loss 함수의 진짜 최솟값 찾기
→ update → → update →
→ update → → update →
→ update → → update →
… → update → …
이걸 m번 반복
반복 때마다 랜덤하게 섞는다
123.
M I NI B AT C H
Gradient Descent
Data B개 본 후 평균 loss를 구해서
Weight를 업데이트 해주면서
어떤 loss 함수의 진짜 최솟값 찾기
→ update →
… → update → …
→ update →
→ update →→ update →
이걸 m번 반복
반복 때마다 랜덤하게 섞는다
GPU !
124.
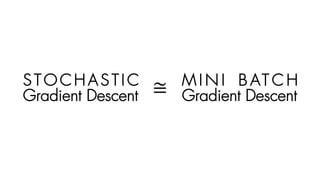
S T OC H A S T I C
Gradient Descent
M I N I B AT C H
Gradient Descent≅
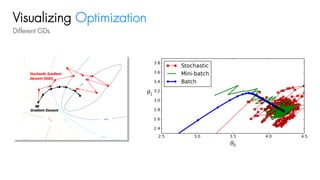
헷갈리기 쉬운 핵심용어들
•Epoch [이폭, 에픽]
• Mini-batch size
• Iteration
update →
… → update → …
update →
update →update →
이걸 m번 반복
반복 때마다 랜덤하게 섞는다
전체 데이터를 보는 걸 1바퀴라 했을 때, 몇 바퀴 돌 것인지 : m
하나의 mini-batch는 몇 개의 데이터로 이루어져있을지
대개 2의 제곱수: 16, 32, 64, …
전체 데이터 수와 mini-batch사이즈에 따라 자동으로 결정됨
=number of updates in 1 epoch
=number of mini-batches
딥러닝 모델 구축하기
•Dataset & DataLoader
• Model
• Loss function
⚬ MSE, Cross-entropy, KL-divergence 등등
• Optimizer
⚬ SGD, AdaGrad, RMSProp, Adam 등등
• Training & Testing
출처: DeepBrick
Facebook - TensorFlowKR
Community
Lectures
초짜대학원생 시리즈
https://brunch.co.kr/@kakao-it
http://kvfrans.com/
http://colah.github.io/
모두를 위한 머신러닝/딥러닝 강의
http://cs231n.stanford.edu/
3Blue1Brown 강의
Blogs
TA K E AWAYS
Sung
Kim























![Weight : [ 𝑤", 𝑤#, 𝑤$ ]](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-32-320.jpg)
![Input vector:
Weight vector: [ 𝑤", 𝑤#, 𝑤$ ]
[ 𝑥", 𝑥#, 𝑥$ ]
Input 벡터와 가중치 벡터의 내적](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-33-320.jpg)
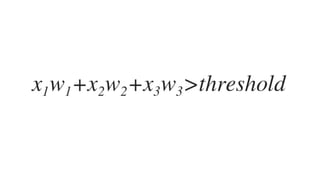
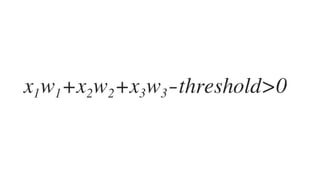
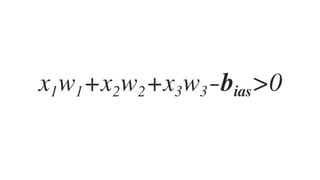
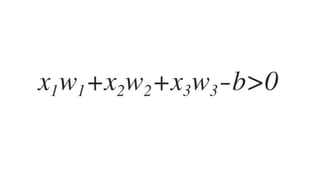
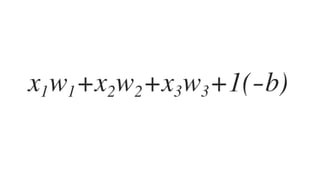
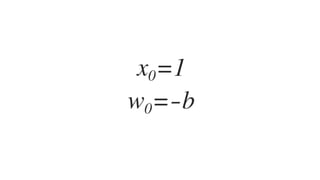
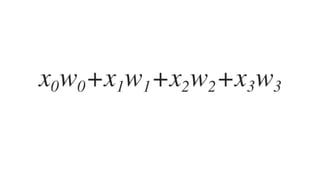
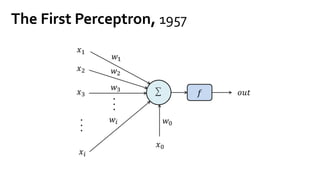











































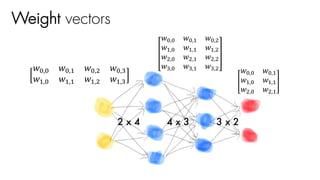
![𝑤J,J 𝑤J," 𝑤J,# 𝑤J,$
𝑤",J 𝑤"," 𝑤",# 𝑤",$
4 x 3 3 x 2
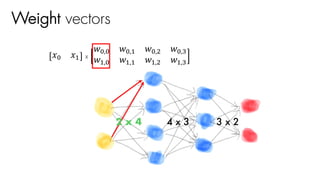
Weight vectors
𝑥J 𝑥"
2 x 4
= 1 x 4 행렬
[1 x 2] x [2 x 4]
x
activF(X 0 W1 +b1)](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-105-320.jpg)
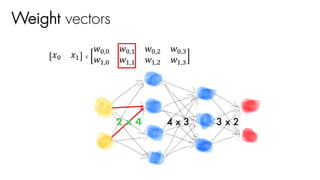
![𝑤J,J 𝑤J," 𝑤J,#
𝑤",J 𝑤"," 𝑤",#
𝑤#,J 𝑤#," 𝑤#,#
𝑤$,J 𝑤$," 𝑤$,#
2 x 4 4 x 3 3 x 2
[1 x 4 행렬 ] x = [1 x 3 행렬 ]
Weight vectors activF(activF(X 0 W1 +b1) 0 W2 +b2)](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-106-320.jpg)
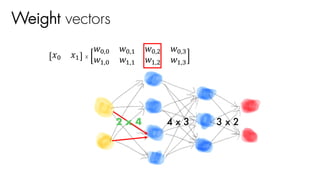
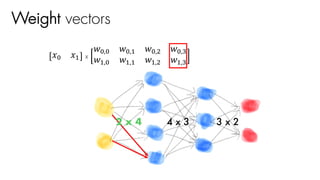
![2 x 4 3 x 2
[1 x 3 행렬 ]
Weight vectors
𝑤J,J 𝑤J,"
𝑤",J 𝑤","
𝑤#,J 𝑤#,"
= [1 x 2 행렬 ]x
4 x 3
activF(activF(activF(X 0 W1 +b1) 0 W2 +b2) 0 W3 +b3)](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-107-320.jpg)
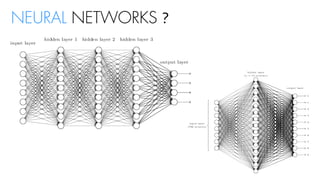
![NEURAL NETWORKS ?
[1 x 8]
[8 x 9] [9 x 9] [9 x 9]
[9 x 4]
[8 x 15] [15 x 10]](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-108-320.jpg)


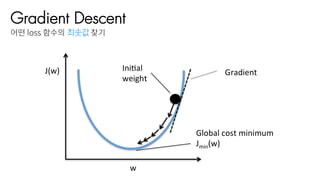
![어떤 loss 함수의 최솟값찾기
Gradient Descent
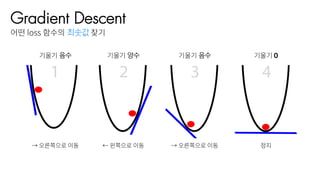
기울기 음수 기울기 양수
→ 오른쪽으로 이동 ← 왼쪽으로 이동
기울기 음수
→ 오른쪽으로 이동
기울기 0
정지
𝑤VWXYZ[X = 𝑤W[]^_V` − 𝛾 𝛻d 𝐿(𝑤)](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-113-320.jpg)
![𝑤VWXYZ[X = 𝑤W[]^_V` − 𝛾 𝛻d 𝐿(𝑤) Weight를 업데이트 해주면서
어떤 loss 함수의 진짜 최솟값 찾기
Gradient Descent
Learning Rate
한 걸음의 크기
Gradient
지금 w에서의 기울기](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-117-320.jpg)
![출처: 하용호님 발표
Vanishing Gradient
Back-prop에서 발생할 수 있는 문제
Layer가 많을수록 업데이트가 사라져간다
그래서 fitting이 잘 안 된다[underfitting]
Best choice: ReLU](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-120-320.jpg)


![𝑤VWXYZ[X = 𝑤W[]^_V` − 𝛾 𝛻d 𝐿(𝑤) Weight를 업데이트 해주면서
어떤 loss 함수의 진짜 최솟값 찾기
Gradient Descent
Learning Rate
한 걸음의 크기
Gradient
어느 방향
1.
2.](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-126-320.jpg)

![헷갈리기 쉬운 핵심용어들
• Epoch [이폭, 에픽]
• Mini-batch size
• Iteration
update →
… → update → …
update →
update →update →
이걸 m번 반복
반복 때마다 랜덤하게 섞는다
전체 데이터를 보는 걸 1바퀴라 했을 때, 몇 바퀴 돌 것인지 : m
하나의 mini-batch는 몇 개의 데이터로 이루어져있을지
대개 2의 제곱수: 16, 32, 64, …
전체 데이터 수와 mini-batch사이즈에 따라 자동으로 결정됨
=number of updates in 1 epoch
=number of mini-batches](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-129-320.jpg)




![딥러닝 모델 구축하기 [실습]
• Dataset & DataLoader
• Model
• Loss function
⚬ MSE, Cross-entropy, KL-divergence 등등
• Optimizer
⚬ SGD, AdaGrad, RMSProp, Adam 등등
• Training & Testing
출처: DeepBrick](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-135-320.jpg)







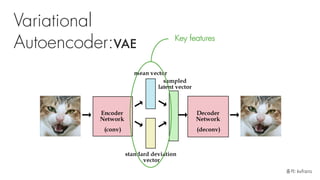




![Defense Model 2:
Convolutional VAE [conv_VAE]
28x28x1
28x28x10
14x14x16
7x7x28 128
256
20
128
256
7x7x16
14x14x10
28x28x6
28x28x1
Z_mu, Z_logvar
Sampled Epsilon
X. Yan et al., Attribute2Image: Conditional Image Generation from Visual Attributes. In ECCV, 2015.](https://image.slidesharecdn.com/nnfrombasicstopytorch-171109132539/85/Neural-Networks-Basics-with-PyTorch-154-320.jpg)





![Random Forest Intro [랜덤포레스트 설명]](https://cdn.slidesharecdn.com/ss_thumbnails/theforestslideshare-170924111713-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Neural Network Intro [인공신경망 설명]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkfinale-170924112506-thumbnail.jpg?width=640&height=640&fit=bounds)



![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Decision Tree Intro [의사결정나무]](https://cdn.slidesharecdn.com/ss_thumbnails/thetreeslideshare-170922160319-thumbnail.jpg?width=640&height=640&fit=bounds)