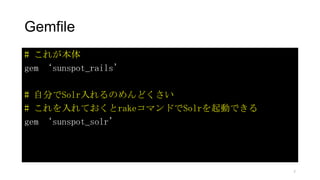
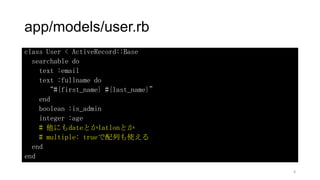
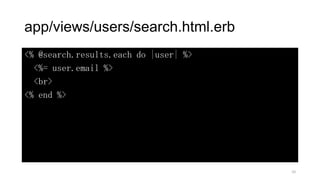
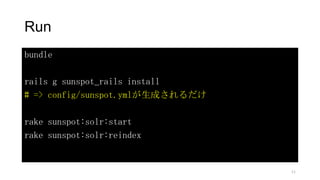
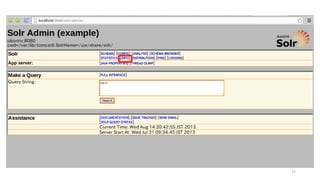
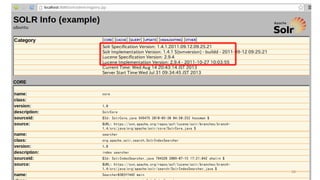
app/models/user.rb
class User <ActiveRecord::Base
searchable do
text :email
text :fullname do
“#{first_name} #{last_name}”
end
boolean :is_admin
integer :age
# 他にもdateとかlatlonとか
# multiple: trueで配列も使える
end
end
8
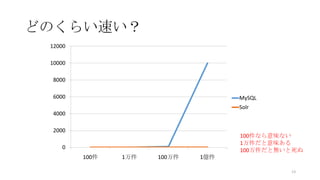
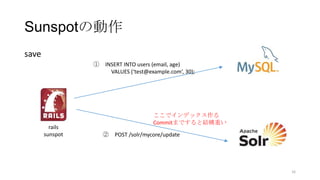
Sunspotの動作
save
① INSERT INTOusers (email, age)
VALUES (‘test@example.com’, 30);
rails
sunspot ② POST /solr/mycore/update
ここでインデックス作る
Commitまですると結構重い
16
17.
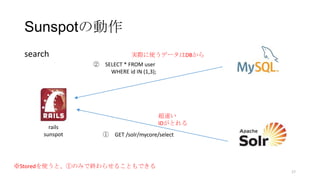
Sunspotの動作
search
② SELECT *FROM user
WHERE id IN (1,3);
rails
sunspot ① GET /solr/mycore/select
超速い
IDがとれる
17
実際に使うデータはDBから
※Storedを使うと、①のみで終わらせることもできる