Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Naoki Hayashi
PDF, PPTX
611 views
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
2018年3月修了の修士論文発表会の資料. Presentation for Defense of Master Thesis in 2018.
Science
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 59
2
/ 59
3
/ 59
4
/ 59
5
/ 59
6
/ 59
7
/ 59
8
/ 59
9
/ 59
10
/ 59
11
/ 59
12
/ 59
13
/ 59
14
/ 59
15
/ 59
16
/ 59
17
/ 59
18
/ 59
19
/ 59
20
/ 59
21
/ 59
22
/ 59
23
/ 59
24
/ 59
25
/ 59
26
/ 59
27
/ 59
28
/ 59
29
/ 59
30
/ 59
31
/ 59
32
/ 59
33
/ 59
34
/ 59
35
/ 59
36
/ 59
37
/ 59
38
/ 59
39
/ 59
40
/ 59
41
/ 59
42
/ 59
43
/ 59
44
/ 59
45
/ 59
46
/ 59
47
/ 59
48
/ 59
49
/ 59
50
/ 59
51
/ 59
52
/ 59
53
/ 59
54
/ 59
55
/ 59
56
/ 59
57
/ 59
58
/ 59
59
/ 59
More Related Content
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
Numpy scipyで独立成分分析
by
Shintaro Fukushima
PPTX
独立性基準を用いた非負値行列因子分解の効果的な初期値決定法(Statistical-independence-based efficient initia...
by
Daichi Kitamura
PPTX
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
PDF
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
PDF
決定木学習
by
Mitsuo Shimohata
変分ベイズ法の説明
by
Haruka Ozaki
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
Numpy scipyで独立成分分析
by
Shintaro Fukushima
独立性基準を用いた非負値行列因子分解の効果的な初期値決定法(Statistical-independence-based efficient initia...
by
Daichi Kitamura
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
決定木学習
by
Mitsuo Shimohata
What's hot
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
凸最適化 〜 双対定理とソルバーCVXPYの紹介 〜
by
Tomoki Yoshida
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
[DL輪読会]1次近似系MAMLとその理論的背景
by
Deep Learning JP
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
SVMについて
by
mknh1122
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
PDF
公平性を保証したAI/機械学習 アルゴリズムの最新理論
by
Kazuto Fukuchi
PDF
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
PPTX
コサイン類似度罰則条件付き半教師あり非負値行列因子分解と音源分離への応用
by
Kitamura Laboratory
PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
PDF
傾向スコアの概念とその実践
by
Yasuyuki Okumura
PDF
木と電話と選挙(causalTree)
by
Shota Yasui
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
凸最適化 〜 双対定理とソルバーCVXPYの紹介 〜
by
Tomoki Yoshida
ブラックボックス最適化とその応用
by
gree_tech
機械学習のためのベイズ最適化入門
by
hoxo_m
[DL輪読会]1次近似系MAMLとその理論的背景
by
Deep Learning JP
数学で解き明かす深層学習の原理
by
Taiji Suzuki
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
SVMについて
by
mknh1122
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
Deep Learning Lab 異常検知入門
by
Shohei Hido
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
不均衡データのクラス分類
by
Shintaro Fukushima
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
公平性を保証したAI/機械学習 アルゴリズムの最新理論
by
Kazuto Fukuchi
DARM勉強会第3回 (missing data analysis)
by
Masaru Tokuoka
コサイン類似度罰則条件付き半教師あり非負値行列因子分解と音源分離への応用
by
Kitamura Laboratory
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
by
Preferred Networks
傾向スコアの概念とその実践
by
Yasuyuki Okumura
木と電話と選挙(causalTree)
by
Shota Yasui
Similar to 修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
PPTX
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PPTX
【学会発表】LDAにおけるベイズ汎化誤差の厳密な漸近形【IBIS2020】
by
Naoki Hayashi
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
PRML 10.4 - 10.6
by
Akira Miyazawa
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PPTX
WAICとWBICのご紹介
by
Tomoki Matsumoto
PDF
20170422 数学カフェ Part2
by
Kenta Oono
PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
by
hirokazutanaka
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
Infomation geometry(overview)
by
Yoshitake Misaki
PDF
データマイニング勉強会3
by
Yohei Sato
PDF
Infinite SVM - ICML 2011 読み会
by
Shuyo Nakatani
PDF
201803NC
by
Naoki Hayashi
PDF
201703NC
by
Naoki Hayashi
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
PDF
How to study stat
by
Ak Ok
PDF
palla et al, a nonparametric variable clustering method
by
Zenghan Liang
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
【学会発表】LDAにおけるベイズ汎化誤差の厳密な漸近形【IBIS2020】
by
Naoki Hayashi
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PRML 10.4 - 10.6
by
Akira Miyazawa
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
WAICとWBICのご紹介
by
Tomoki Matsumoto
20170422 数学カフェ Part2
by
Kenta Oono
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
by
hirokazutanaka
PRML10-draft1002
by
Toshiyuki Shimono
bigdata2012ml okanohara
by
Preferred Networks
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Infomation geometry(overview)
by
Yoshitake Misaki
データマイニング勉強会3
by
Yohei Sato
Infinite SVM - ICML 2011 読み会
by
Shuyo Nakatani
201803NC
by
Naoki Hayashi
201703NC
by
Naoki Hayashi
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
How to study stat
by
Ak Ok
palla et al, a nonparametric variable clustering method
by
Zenghan Liang
More from Naoki Hayashi
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PPTX
情報統計力学のすすめ
by
Naoki Hayashi
PPTX
Bayesian Generalization Error and Real Log Canonical Threshold in Non-negativ...
by
Naoki Hayashi
PDF
201709ibisml
by
Naoki Hayashi
PDF
RPG世界の形状及び距離の幾何学的考察(#rogyconf61)
by
Naoki Hayashi
PPTX
RPG世界の形状及び距離の幾何学的考察(rogyconf61)
by
Naoki Hayashi
PPTX
すずかけはいいぞ
by
Naoki Hayashi
PDF
諸君,じゃんけんに負けたからといって落ち込むことはない.長津田にも飯はある.
by
Naoki Hayashi
PDF
IEEESSCI2017-FOCI4-1039
by
Naoki Hayashi
PPTX
Rogyゼミ7thスライドpublic
by
Naoki Hayashi
PPTX
ぼくのつくったこうだいさいてんじぶつ
by
Naoki Hayashi
PPTX
Rogyゼミスライド6th
by
Naoki Hayashi
PDF
Rogy目覚まし(仮)+おまけ
by
Naoki Hayashi
PPTX
Rogyzemi
by
Naoki Hayashi
PPT
Rogyゼミ2014 10
by
Naoki Hayashi
ベイズ統計学の概論的紹介
by
Naoki Hayashi
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
情報統計力学のすすめ
by
Naoki Hayashi
Bayesian Generalization Error and Real Log Canonical Threshold in Non-negativ...
by
Naoki Hayashi
201709ibisml
by
Naoki Hayashi
RPG世界の形状及び距離の幾何学的考察(#rogyconf61)
by
Naoki Hayashi
RPG世界の形状及び距離の幾何学的考察(rogyconf61)
by
Naoki Hayashi
すずかけはいいぞ
by
Naoki Hayashi
諸君,じゃんけんに負けたからといって落ち込むことはない.長津田にも飯はある.
by
Naoki Hayashi
IEEESSCI2017-FOCI4-1039
by
Naoki Hayashi
Rogyゼミ7thスライドpublic
by
Naoki Hayashi
ぼくのつくったこうだいさいてんじぶつ
by
Naoki Hayashi
Rogyゼミスライド6th
by
Naoki Hayashi
Rogy目覚まし(仮)+おまけ
by
Naoki Hayashi
Rogyzemi
by
Naoki Hayashi
Rogyゼミ2014 10
by
Naoki Hayashi
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
1.
非負値行列分解における 漸近的Bayes汎化誤差 林 直輝 (16M30250) 指導教官:渡邊澄夫
教授 12018/2/1 東工大修論発表
2.
目次 • 背景 • 主定理 •
実験と考察 • 結論 2018/2/1 東工大修論発表 2
3.
1. 背景 2018/2/1 東工大修論発表
3
4.
目次 • 背景 – 非負値行列分解 –
実対数閾値 – 研究目的 • 主定理 • 実験と考察 • 結論 2018/2/1 東工大修論発表 4
5.
NMFは広く応用されている • 非負値行列分解 (Non-negative
Matrix Factorization, NMF) は,複合データを解析するために様々な分野 で使われている機械学習手法である • 応用例 – 購買バスケットデータ → 購買解析 – 画像,音声,…… → 信号処理 – テキストデータ → テキストマイニング・解析 – マイクロアレイデータ → バイオインフォマティクス ↑ 知識・構造の発見 NMF: data → knowledge 2018/2/1 東工大修論発表 5
6.
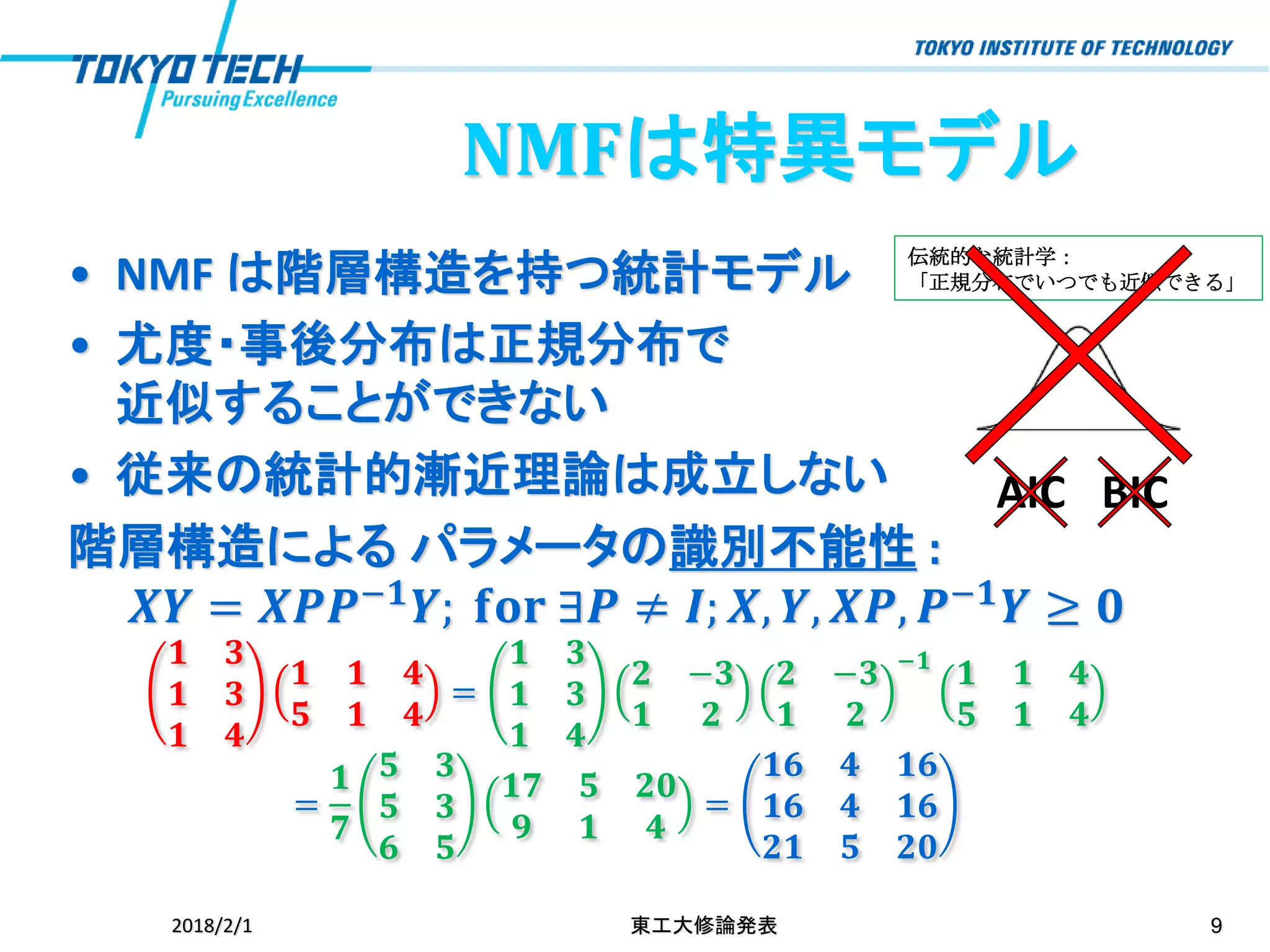
NMFは特異モデル • NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 2018/2/1 東工大修論発表 6 AIC BIC 伝統的な統計学: 「正規分布でいつでも近似できる」
7.
伝統的な統計学: 「正規分布でいつでも近似できる」 NMFは特異モデル • NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 2018/2/1 東工大修論発表 7 AIC BIC
8.
伝統的な統計学: 「正規分布でいつでも近似できる」 NMFは特異モデル • NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 2018/2/1 東工大修論発表 8 AIC BIC
9.
伝統的な統計学: 「正規分布でいつでも近似できる」• NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 階層構造による パラメータの識別不能性 : 𝑿𝒀 = 𝑿𝑷𝑷−𝟏 𝒀; 𝐟𝐨𝐫 ∃𝑷 ≠ 𝑰; 𝑿, 𝒀, 𝑿𝑷, 𝑷−𝟏 𝒀 ≥ 𝟎 𝟏 𝟑 𝟏 𝟑 𝟏 𝟒 𝟏 𝟏 𝟒 𝟓 𝟏 𝟒 = 𝟏 𝟑 𝟏 𝟑 𝟏 𝟒 𝟐 −𝟑 𝟏 𝟐 𝟐 −𝟑 𝟏 𝟐 −𝟏 𝟏 𝟏 𝟒 𝟓 𝟏 𝟒 = 𝟏 𝟕 𝟓 𝟑 𝟓 𝟑 𝟔 𝟓 𝟏𝟕 𝟓 𝟐𝟎 𝟗 𝟏 𝟒 = 𝟏𝟔 𝟒 𝟏𝟔 𝟏𝟔 𝟒 𝟏𝟔 𝟐𝟏 𝟓 𝟐𝟎 2018/2/1 東工大修論発表 9 AIC BIC NMFは特異モデル
10.
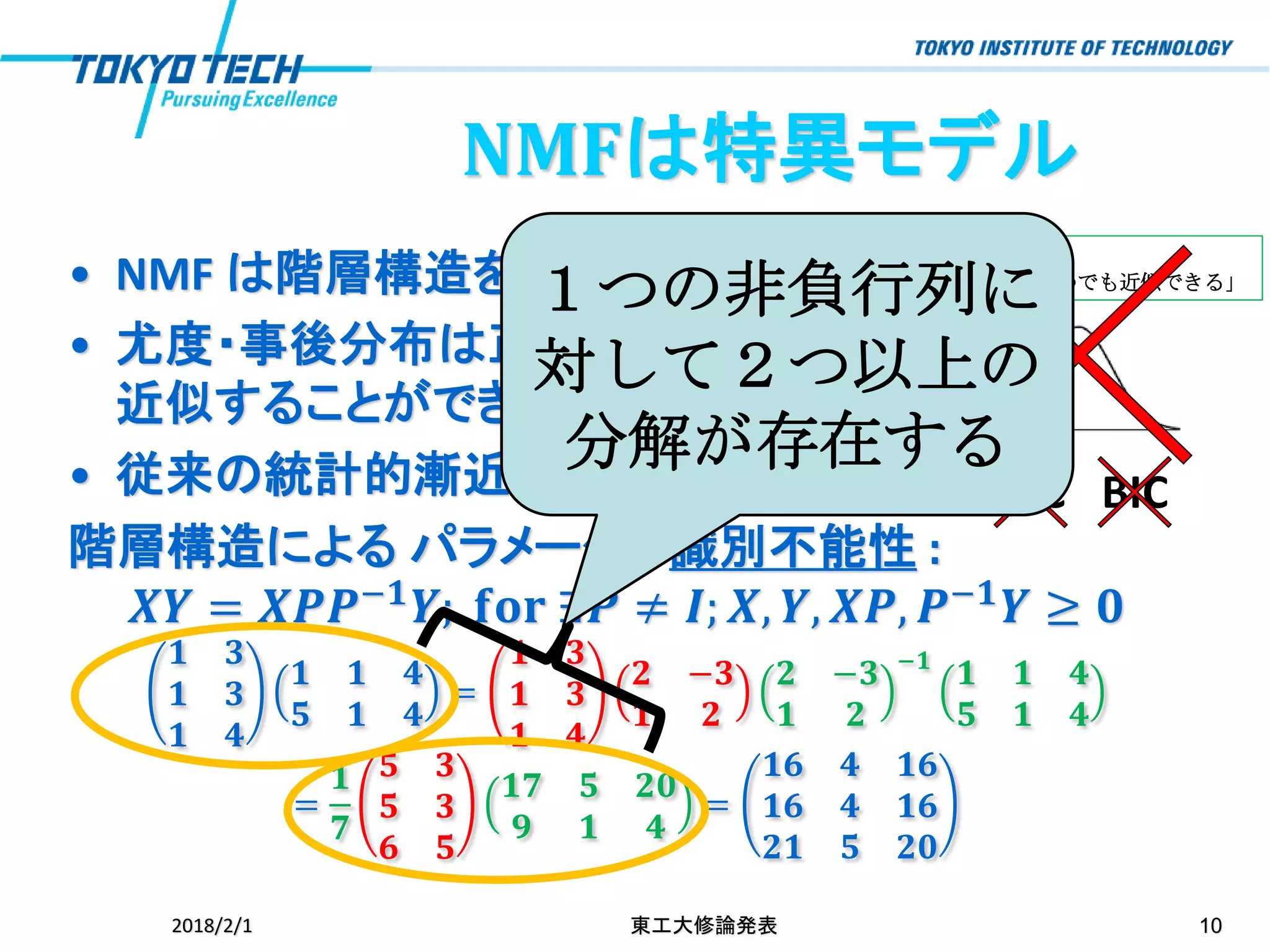
伝統的な統計学: 「正規分布でいつでも近似できる」• NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 階層構造による パラメータの識別不能性 : 𝑿𝒀 = 𝑿𝑷𝑷−𝟏 𝒀; 𝐟𝐨𝐫 ∃𝑷 ≠ 𝑰; 𝑿, 𝒀, 𝑿𝑷, 𝑷−𝟏 𝒀 ≥ 𝟎 𝟏 𝟑 𝟏 𝟑 𝟏 𝟒 𝟏 𝟏 𝟒 𝟓 𝟏 𝟒 = 𝟏 𝟑 𝟏 𝟑 𝟏 𝟒 𝟐 −𝟑 𝟏 𝟐 𝟐 −𝟑 𝟏 𝟐 −𝟏 𝟏 𝟏 𝟒 𝟓 𝟏 𝟒 = 𝟏 𝟕 𝟓 𝟑 𝟓 𝟑 𝟔 𝟓 𝟏𝟕 𝟓 𝟐𝟎 𝟗 𝟏 𝟒 = 𝟏𝟔 𝟒 𝟏𝟔 𝟏𝟔 𝟒 𝟏𝟔 𝟐𝟏 𝟓 𝟐𝟎 2018/2/1 東工大修論発表 10 AIC BIC 1つの非負行列に 対して2つ以上の 分解が存在する NMFは特異モデル
11.
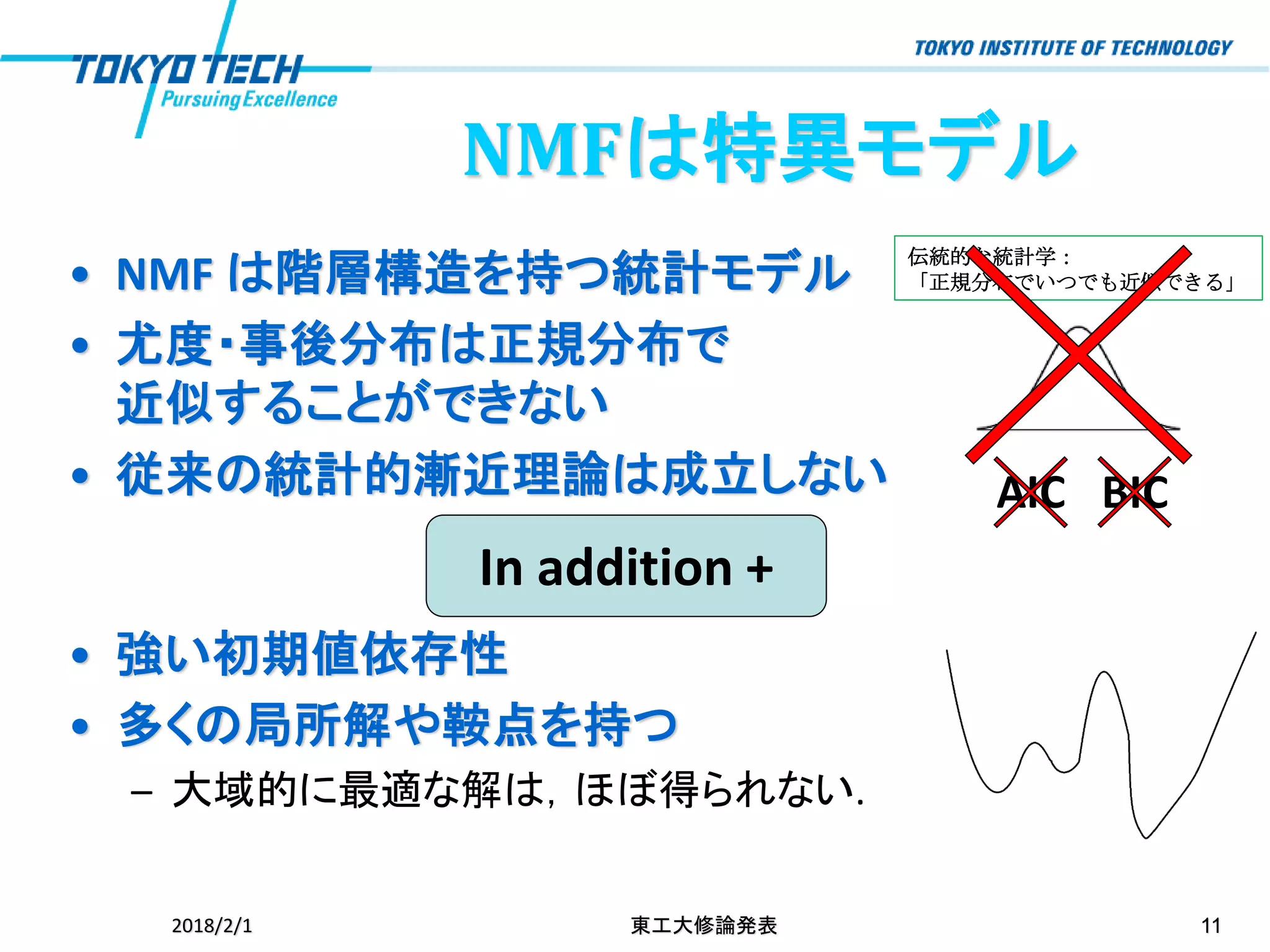
伝統的な統計学: 「正規分布でいつでも近似できる」• NMF は階層構造を持つ統計モデル •
尤度・事後分布は正規分布で 近似することができない • 従来の統計的漸近理論は成立しない 2018/2/1 東工大修論発表 11 • 強い初期値依存性 • 多くの局所解や鞍点を持つ – 大域的に最適な解は,ほぼ得られない. In addition + AIC BIC NMFは特異モデル
12.
• NMF は``data
→ knowledge’’として応用されている 2018/2/1 東工大修論発表 12 NMFの学習理論は未だない
13.
• NMF は``data
→ knowledge’’として応用されている • 数学的な構造は未解明 – 学習理論は構築されていない – 予測精度は明らかにされていない 数値計算の正しさは保証されない 理論的な制御変数・ハイパーパラメータの 調整方法は存在しない 2018/2/1 東工大修論発表 13 NMFの学習理論は未だない
14.
• NMF は``data
→ knowledge’’として応用されている • 数学的な構造は未解明 – 学習理論は構築されていない – 予測精度は明らかにされていない 2018/2/1 東工大修論発表 14 NMFの学習理論の構築は 理論と応用両面から重要 NMFの学習理論は未だない
15.
目次 • 背景 – 非負値行列分解 –
実対数閾値 – 研究目的 • 主定理 • 実験と考察 • 結論 2018/2/1 東工大修論発表 15
16.
• 一般に,[Watanabe, 2001] –
n をサンプルサイズ – Bayes汎化誤差を 𝑮 𝒏 とするとその平均値の漸近挙動は: 𝔼 𝑮 𝒏 = 𝝀 𝒏 + 𝒐 𝟏 𝒏 . • 主要項の係数𝝀 はモデル依存 • 𝝀 は実対数閾値(real log canonical threshold, RLCT) と呼ばれる 2018/2/1 東工大修論発表 16 RLCTと学習の関係は?
17.
Bayesは最尤より誤差が小さい • 階層的なモデルでは, 係数
𝝀 はBayes推定の場合 の方が最尤・事後確率最大化推定よりも小さい [Watanabe,2001 and 2009] • Bayes推定は汎化誤差を減らすために効果的 • 本研究ではBayes推定の枠組みでNMFを考える – NMFのBayes推定は [Cemgil, 2009] で提案されているが, 離散的な場合のみ.本研究では連続的な場合も扱う. 2018/2/1 東工大修論発表 17
18.
NMFのRLCTは未解明 • NMF は``data
→ knowledge’’として応用されている • 数学的な構造は未解明 – 学習理論は構築されていない – 予測精度は明らかにされていない ↑ 先述の課題は NMFのRLCTは未解明ということ 2018/2/1 東工大修論発表 18
19.
RLCTの定義と応用 • RLCTは``学習係数’’として特徴づけられる • 数学的な定義は以下の1変数複素函数を解析接続 したものの最大極の符号反転である: 𝜻
𝒛 = න𝑲 𝜽 𝒛 𝝋 𝜽 𝒅𝜽, ここで 𝑲 は真の分布から学習機械へのKL情報量で,𝝋 は事前分布である. • RLCTの理論値を用いるモデル選択手法が提案され ている[Drton, et al. 2017]. 2018/2/1 東工大修論発表 19
20.
RLCTの定義と応用 • RLCTは``学習係数’’として特徴づけられる • 数学的な定義は以下の1変数複素函数を解析接続 したものの最大極の符号反転である: 𝜻
𝒛 = න𝑲 𝜽 𝒛 𝝋 𝜽 𝒅𝜽, ここで 𝑲 は真の分布から学習機械へのKL情報量で,𝝋 は事前分布である. • RLCTの理論値を用いるモデル選択手法が提案され ている[Drton, et al. 2017]. 2018/2/1 東工大修論発表 20 sBIC (singular BIC)
21.
目次 • 背景 – 非負値行列分解 –
実対数閾値 – 研究目的 • 主定理 • 実験と考察 • 結論 2018/2/1 東工大修論発表 21
22.
研究目的 非負値行列分解(NMF)の数値計算結果の検証や理 論的な学習アルゴリズムの考案のために,その学習 理論の構築を目指して • 予測精度(汎化誤差)の理論値に着目 →実対数閾値(RLCT)に着目・これを解明 ※一般に予測と発見は異なるが,知識発見の確からしさ (自由エネルギーの漸近挙動)についてもRLCTは支配的 2018/2/1 東工大修論発表
22
23.
2. 主定理 2018/2/1 東工大修論発表
23
24.
目次 • 背景 • 主定理 –
NMFのBayes推定の枠組み – 主結果と証明 • 実験と考察 • 結論 2018/2/1 東工大修論発表 24
25.
定式化と設定 • データ行列: 𝑾
𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏) – 一般のため,複数(n>1)の行列の分解を考える. 2018/2/1 東工大修論発表 25 [Kohjima et al. 2016/6, modified] 𝑾𝑴 𝑵
26.
定式化と設定 • データ行列: 𝑾
𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏) – 一般のため,複数(n>1)の行列の分解を考える. • 真の分解: 𝑨; 𝑴 × 𝑯 𝟎, 𝑩; 𝑯 𝟎 × 𝑵 • 学習機械の分解: 𝑿; 𝑴 × 𝑯, 𝒀; 𝑯 × 𝑵 2018/2/1 東工大修論発表 26 [Kohjima et al. 2016/6, modified] 𝑾𝑴 𝑵 𝑯 𝟎 𝑵 𝑯 𝟎 𝑴 𝑨 𝑩
27.
定式化と設定 • データ行列: 𝑾
𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏) – 一般のため,複数(n>1)の行列の分解を考える. • 真の分解: 𝑨; 𝑴 × 𝑯 𝟎, 𝑩; 𝑯 𝟎 × 𝑵 • 学習機械の分解: 𝑿; 𝑴 × 𝑯, 𝒀; 𝑯 × 𝑵 • Bayes法の枠組みだとどうなるか? 2018/2/1 東工大修論発表 27 [Kohjima et al. 2016/6, modified] 𝑾𝑴 𝑵 𝑯 𝟎 𝑵 𝑯 𝟎 𝑴 𝑨 𝑩
28.
• 確率密度函数の記号定義 – 𝑞
𝑊 : 真の分布, – 𝑝 𝑊 𝑋, 𝑌 : 学習機械, – 𝑝∗ 𝑊 : Bayes予測分布, これらの定義域はEuclid空間. – 𝜑 𝑋, 𝑌 : 事前分布, – 𝑝 𝑋, 𝑌 𝑊 𝑛 : データが与えられたときの事後分布, これらの定義域はEuclid空間のコンパクト部分集合. 2018/2/1 東工大修論発表 28 定式化と設定 data parameter
29.
• 確率密度函数を 𝒒 𝑾
∝ 𝐞𝐱𝐩 − 𝟏 𝟐 𝑾 − 𝑨𝑩 𝟐 , 𝒑 𝑾 𝑿, 𝒀 ∝ 𝐞𝐱𝐩 − 𝟏 𝟐 𝑾 − 𝑿𝒀 𝟐 , とし,事前分布 𝝋 は真の分解 𝑨, 𝑩 の近傍で正かつ有 界であるとする. • 正規分布だけでなく指数分布やPoisson分布でも主定 理は成り立つ(考察で詳述). 2018/2/1 東工大修論発表 29 定式化と設定
30.
Bayes推定の枠組み • 事後分布は次で定義される: 𝒑 𝑿,
𝒀 𝑾 𝒏 = 𝟏 𝒁 𝒏 ෑ 𝒊=𝟏 𝒏 𝒑 𝑾𝒊 𝑿, 𝒀 𝝋 𝑿, 𝒀 . ここで 𝒁 𝒏 は正規化定数である. • Bayes予測分布は次で定義される: 𝒑∗ 𝑾 = න𝒑 𝑾 𝑿, 𝒀 𝒑 𝑿, 𝒀 𝑾 𝒏 )𝒅𝑿𝒅𝒀 . 2018/2/1 東工大修論発表 30
31.
Bayes推定の枠組み • Bayes汎化誤差は真の分布から予測分布への KL情報量によって定義される: 𝑮 𝒏
= න 𝒒 𝑾 𝐥𝐨𝐠 𝒒 𝑾 𝒑∗ 𝑾 𝒅𝑾. • 予測分布がデータ依存であるから,汎化誤差は確率 変数であり揺らいでいる. • データの取り方についての平均についての漸近挙動: 𝔼 𝑮 𝒏 = 𝝀 𝒏 + 𝒐 𝟏 𝒏 . 2018/2/1 東工大修論発表 31
32.
目次 • 背景 • 主定理 –
NMFのBayes推定の枠組み – 主結果と証明 • 実験と考察 • 結論 2018/2/1 東工大修論発表 32
33.
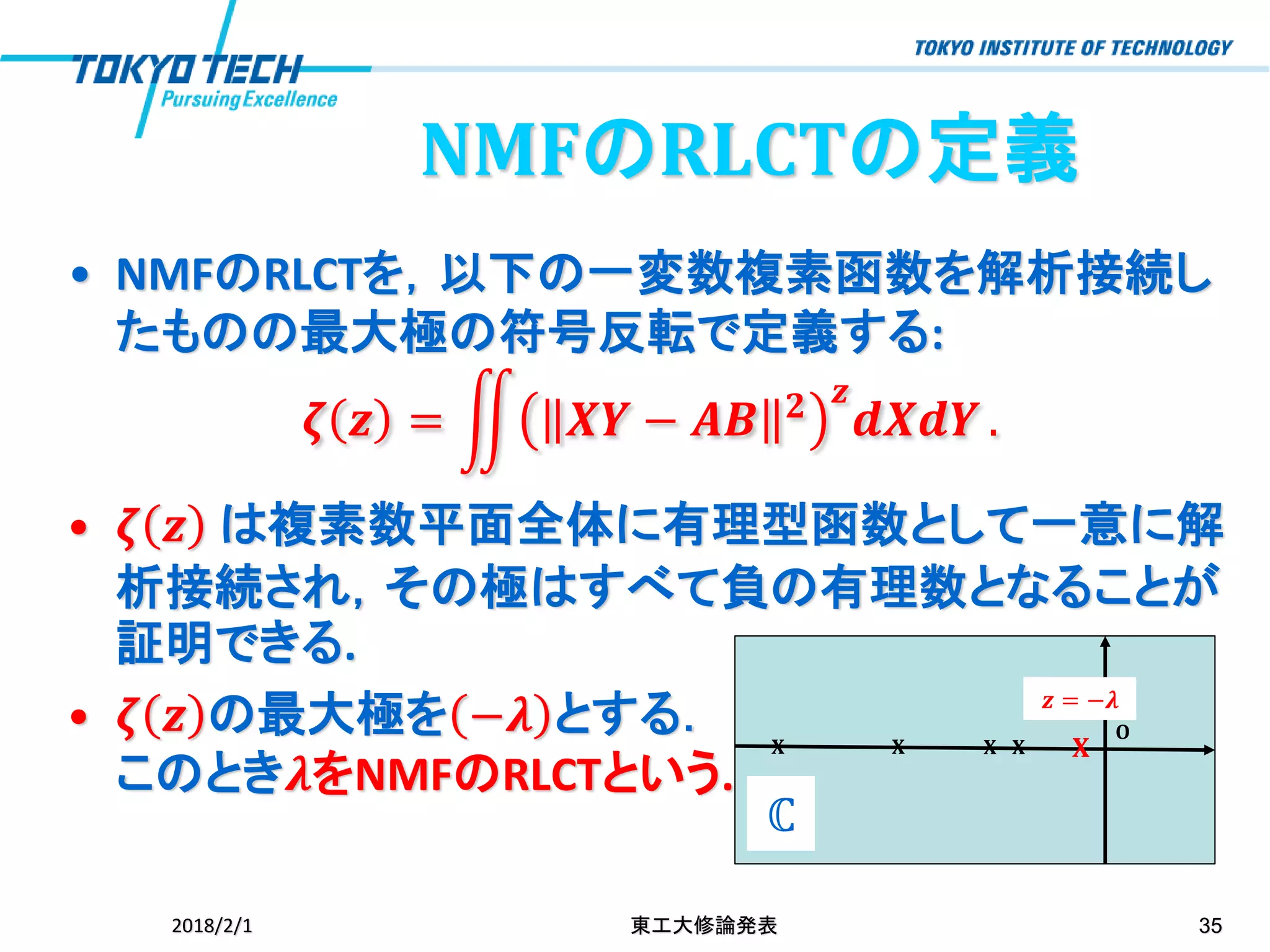
NMFのRLCTの定義 • NMFのRLCTを,以下の一変数複素函数を解析接続し たものの最大極の符号反転で定義する: 𝜻 𝒛
= ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 . 2018/2/1 東工大修論発表 33
34.
• NMFのRLCTを,以下の一変数複素函数を解析接続し たものの最大極の符号反転で定義する: 𝜻 𝒛
= ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 . • 𝜻 𝒛 は複素数平面全体に有理型函数として一意に解 析接続され,その極はすべて負の有理数となることが 証明できる. • 𝜻 𝒛 の最大極を −𝝀 とする. このとき𝝀をNMFのRLCTという. 2018/2/1 東工大修論発表 34 NMFのRLCTの定義
35.
• NMFのRLCTを,以下の一変数複素函数を解析接続し たものの最大極の符号反転で定義する: 𝜻 𝒛
= ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 . • 𝜻 𝒛 は複素数平面全体に有理型函数として一意に解 析接続され,その極はすべて負の有理数となることが 証明できる. • 𝜻 𝒛 の最大極を −𝝀 とする. このとき𝝀をNMFのRLCTという. 2018/2/1 東工大修論発表 35 NMFのRLCTの定義 𝐎 𝐗 𝐗 𝐗 𝐗 𝐗 𝒛 = −𝝀 ℂ
36.
• NMFのRLCT𝝀 は以下の不等式を満足する: 𝝀
≤ 𝟏 𝟐 𝑯 − 𝑯 𝟎 𝐦𝐢𝐧 𝑴, 𝑵 + 𝑯 𝟎 𝑴 + 𝑵 − 𝟐 + 𝜹 𝑯 𝟎 , ここで 𝜹 𝑯 𝟎 = ቊ 𝟏 (𝑯 𝟎 ≅ 𝟏, 𝐦𝐨𝐝 𝟐) 𝟎 (𝒐𝒕𝒉𝒆𝒓𝒘𝒊𝒔𝒆) . • 𝑯 = 𝑯 𝟎 = 𝟏 𝐨𝐫 𝟐 or 𝑯 𝟎 = 𝟎のとき,等号が成立する. 主定理 2018/2/1 東工大修論発表 36 Naoki Hayashi, Sumio Watanabe. "Upper Bound of Bayesian Generalization Error in Non-negative Matrix Factorization",Neurocomputing, Volume 266C, 29 November 2017, pp.21-28. (2017/4/27 accepted). Naoki Hayashi, Sumio Watanabe."Tighter Upper Bound of Real Log Canonical Threshold of Non-negative Matrix Factorization and its Application to Bayesian Inference." 2017 IEEE Symposium Series on Computational Intelligence (IEEE SSCI 2017), Honolulu, Hawaii, USA. Nov. 27 - Dec 1, 2017. (2017/11/28).
37.
• 𝑯 𝟎
= 𝟎 のときの厳密値を不等式評価で解明した. • 二乗誤差の零点が作る代数多様体の次元と 多項式イデアルの生成元に着目し, 𝑯 = 𝑯 𝟎 = 𝟏及び2のときの厳密値を解明した. – 最も非自明な箇所.非負値制約により代数多様体の次元の考 察が容易ではない. • 𝑯 = 𝑯 𝟎 の場合の上界を,上述の厳密値を用いながら 不等式評価で導出した. • 一般の場合の上界を, 𝑯 = 𝑯 𝟎 の場合の上界と𝑯 𝟎 = 𝟎 のときの厳密値を用いて導出した. □2018/2/1 東工大修論発表 37 Sketch of Proof
38.
3. 実験と考察 2018/2/1 東工大修論発表
38
39.
目次 • 背景 • 主定理 •
実験と考察 – 理論的な応用 – 数値実験と予想 • 結論 • (付録: 証明の概要) 2018/2/1 東工大修論発表 39
40.
汎化誤差をバウンドできる • 以下の漸近挙動を用いて,Bayes汎化誤差の上界を主 定理から直ちに導出できる: 𝔼 𝑮
𝒏 = 𝝀 𝒏 + 𝒐 𝟏 𝒏 . • 実際,次が成立する: 𝔼 𝑮 𝒏 ≤ 𝟏 𝟐𝒏 𝑯 − 𝑯 𝟎 𝐦𝐢𝐧 𝑴, 𝑵 + 𝑯 𝟎 𝑴 + 𝑵 − 𝟐 + 𝜹 𝑯 𝟎 + 𝒐 𝟏 𝒏 . – これは汎化誤差の理論値の範囲を示している. – すなわち数値計算の理論保証を与えている. • どのような分布の時に汎化誤差はバウンドされるか? 2018/2/1 東工大修論発表 40
41.
分布に関するロバスト性 • 主定理では行列の要素は正規分布に従うと仮定し ていた: 𝒒 𝑾
∝ 𝓝 𝑾 𝑨𝑩 , 𝒑 𝑾 𝑿, 𝒀 ∝ 𝓝 𝑾 𝑿𝒀 . • 他の確率分布に従うとき,主定理の不等式は成立 するだろうか? 2018/2/1 東工大修論発表 41
42.
分布に関するロバスト性 • 実際は,行列の要素がPoisson分布や指数分布に従う 場合でも,同じゼータ函数を用いて汎化誤差の議論が 可能なことが証明できる: 𝒒 𝑾
∝ 𝐏𝐨𝐢 𝑾 𝑨𝑩 , 𝒑 𝑾 𝑿, 𝒀 ∝ 𝐏𝐨𝐢 𝑾 𝑿𝒀 , 𝒒 𝑾 ∝ 𝐄𝐱𝐩𝐨 𝑾 𝑨𝑩 , 𝒑 𝑾 𝑿, 𝒀 ∝ 𝐄𝐱𝐩𝐨 𝑾 𝑿𝒀 , 𝜻 𝒛 = ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 . 2018/2/1 東工大修論発表 42 Even if We can use
43.
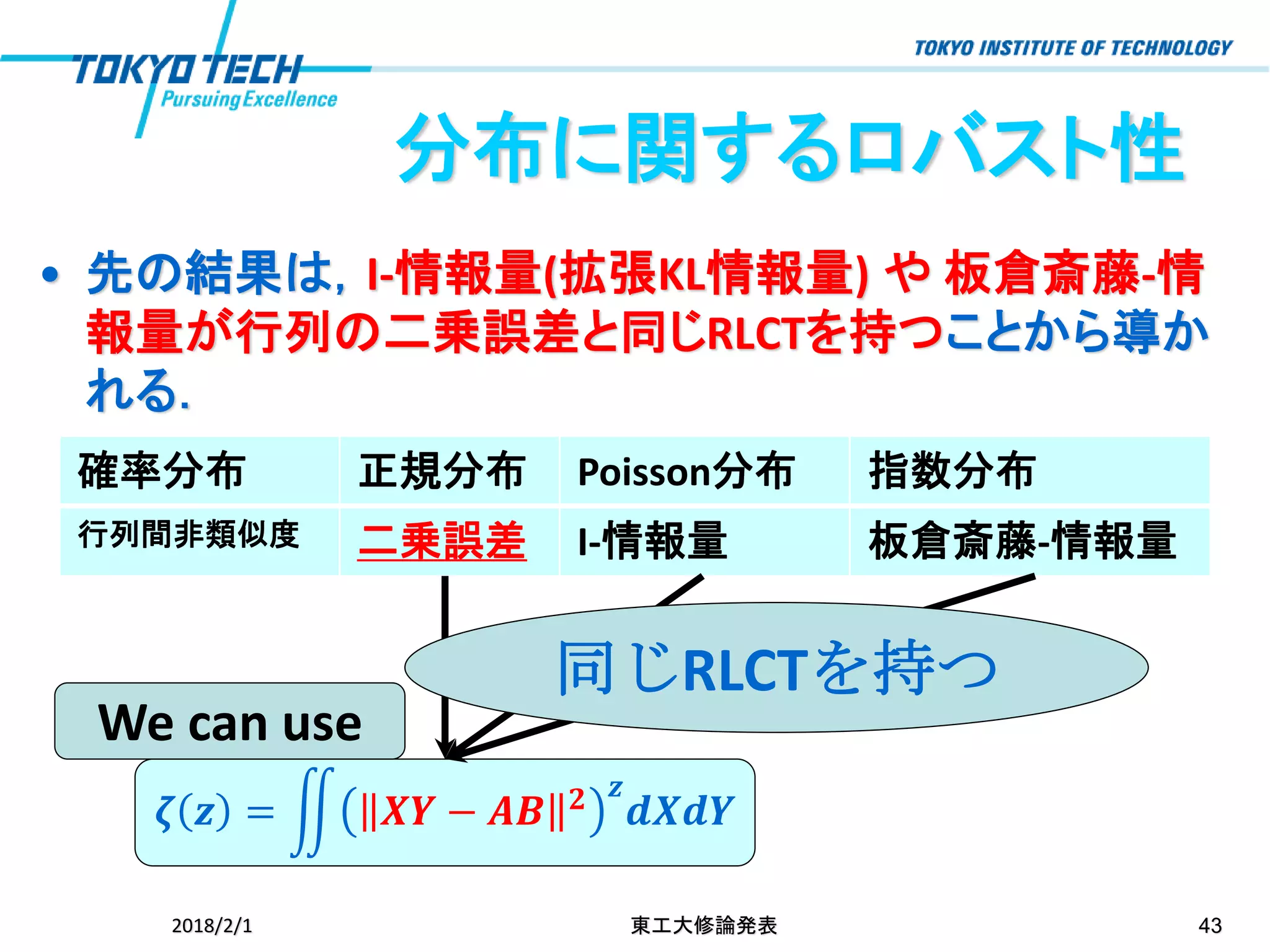
分布に関するロバスト性 • 先の結果は,I-情報量(拡張KL情報量) や
板倉斎藤-情 報量が行列の二乗誤差と同じRLCTを持つことから導か れる. 2018/2/1 東工大修論発表 43 確率分布 正規分布 Poisson分布 指数分布 行列間非類似度 二乗誤差 I-情報量 板倉斎藤-情報量 𝜻 𝒛 = ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 We can use 同じRLCTを持つ
44.
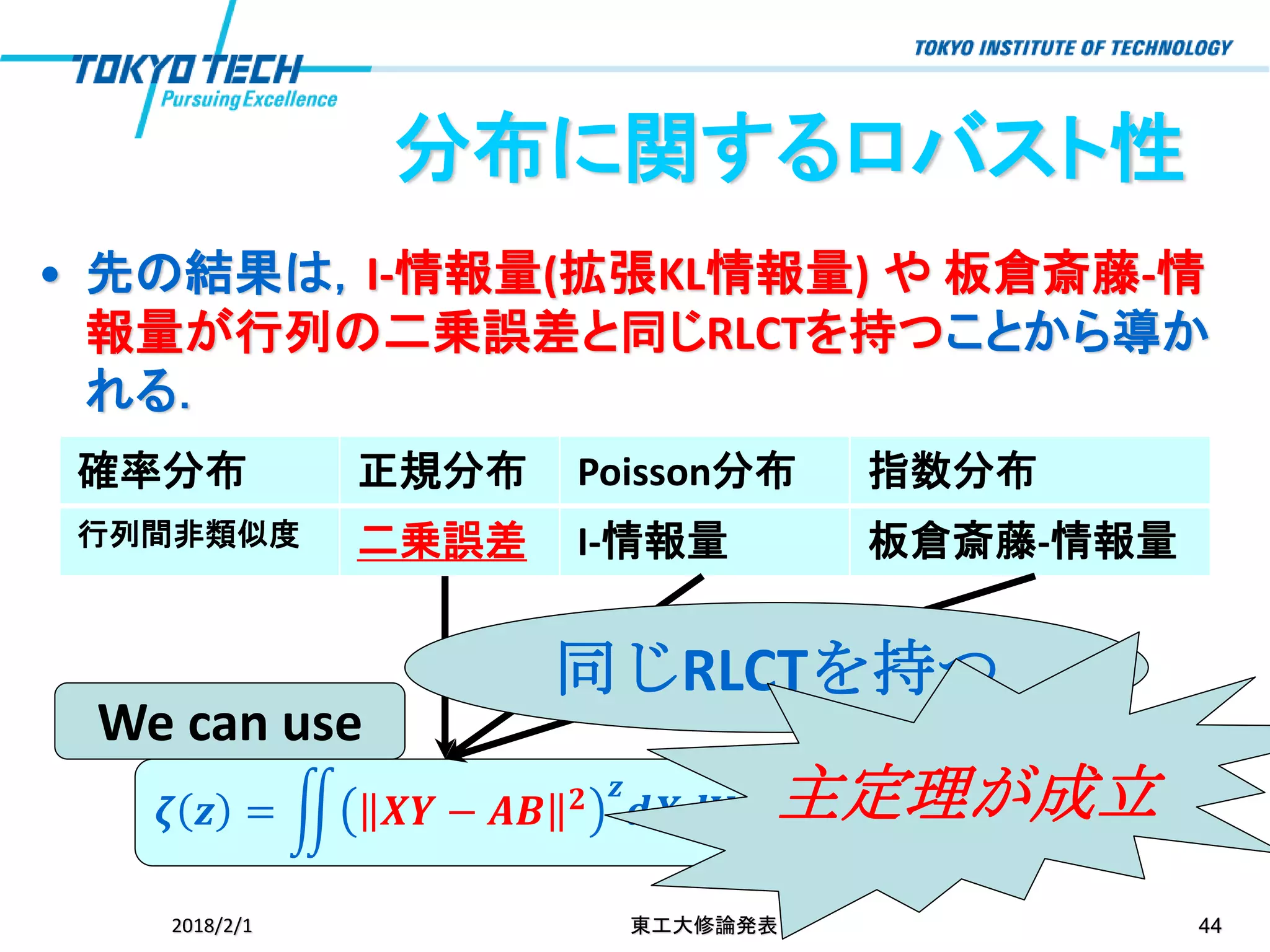
分布に関するロバスト性 • 先の結果は,I-情報量(拡張KL情報量) や
板倉斎藤-情 報量が行列の二乗誤差と同じRLCTを持つことから導か れる. 2018/2/1 東工大修論発表 44 確率分布 正規分布 Poisson分布 指数分布 行列間非類似度 二乗誤差 I-情報量 板倉斎藤-情報量 𝜻 𝒛 = ඵ 𝑿𝒀 − 𝑨𝑩 𝟐 𝒛 𝒅𝑿𝒅𝒀 We can use 同じRLCTを持つ 主定理が成立
45.
目次 • 背景 • 主定理 •
実験と考察 – 理論的な応用 – 数値実験と予想 • 結論 • (付録: 証明の概要) 2018/2/1 東工大修論発表 45
46.
• RLCTの厳密値を見積もるために数値実験を行った. – 加えて,非負値制約のない行列分解(縮小ランク回帰,RRR) のRLCTの厳密値との比較を行った. •
事後分布を解析的に計算することは困難. →Markov連鎖モンテカルロ法(MCMC) – Metropolis Hastings法によるMCMCを用いた. 2018/2/1 東工大修論発表 46 数値実験
47.
• 以下のケースで人工データを生成して実験した: – 1.
NMFのRLCTの厳密値が解明済み. – 2. 厳密値が不明で,かつ rank = rank+. – 3. 厳密値が不明で,かつ rank ≠ rank+. • rank+ : NMFの最小内部次元の理論値 – これ↑は非負値ランク(non-negative rank)と呼ばれる. – 一般に, rank+≧ rank . – min{rows, columns} ≦ 3 or rank ≦2 ⇒ rank =rank+である. – 実際,rank<rank+であるような非負値行列が存在する. 2018/2/1 東工大修論発表 47 非負値制約による「ランク」の違い
48.
• サンプルサイズはn=200 (パラメータ次元≦50) •
データセットをD=100個用意 → 各データセットから得た汎化誤差の算術平均を利用 𝔼 𝑮 𝒏 = 𝝀 𝒏 + 𝒐 𝟏 𝒏 → 𝝀 ≈ 𝒏𝔼 𝑮 𝒏 ≈ 𝒏 𝑫 𝒋=𝟏 𝑫 𝑮 𝒏 𝒋 • MCMC によるサンプルサイズはK=1,000 – Burn-in=20,000, thin=20, i.e. 合計の繰り返しは40,000. • 𝑮 𝒏の計算のために, T=20,000個のテストデータを生成し KL情報量を計算. • 合計: 100*(40,000+1,000*20,000) ≈ 𝑶 𝑫𝑲𝑻 2018/2/1 東工大修論発表 48 実験の条件設定
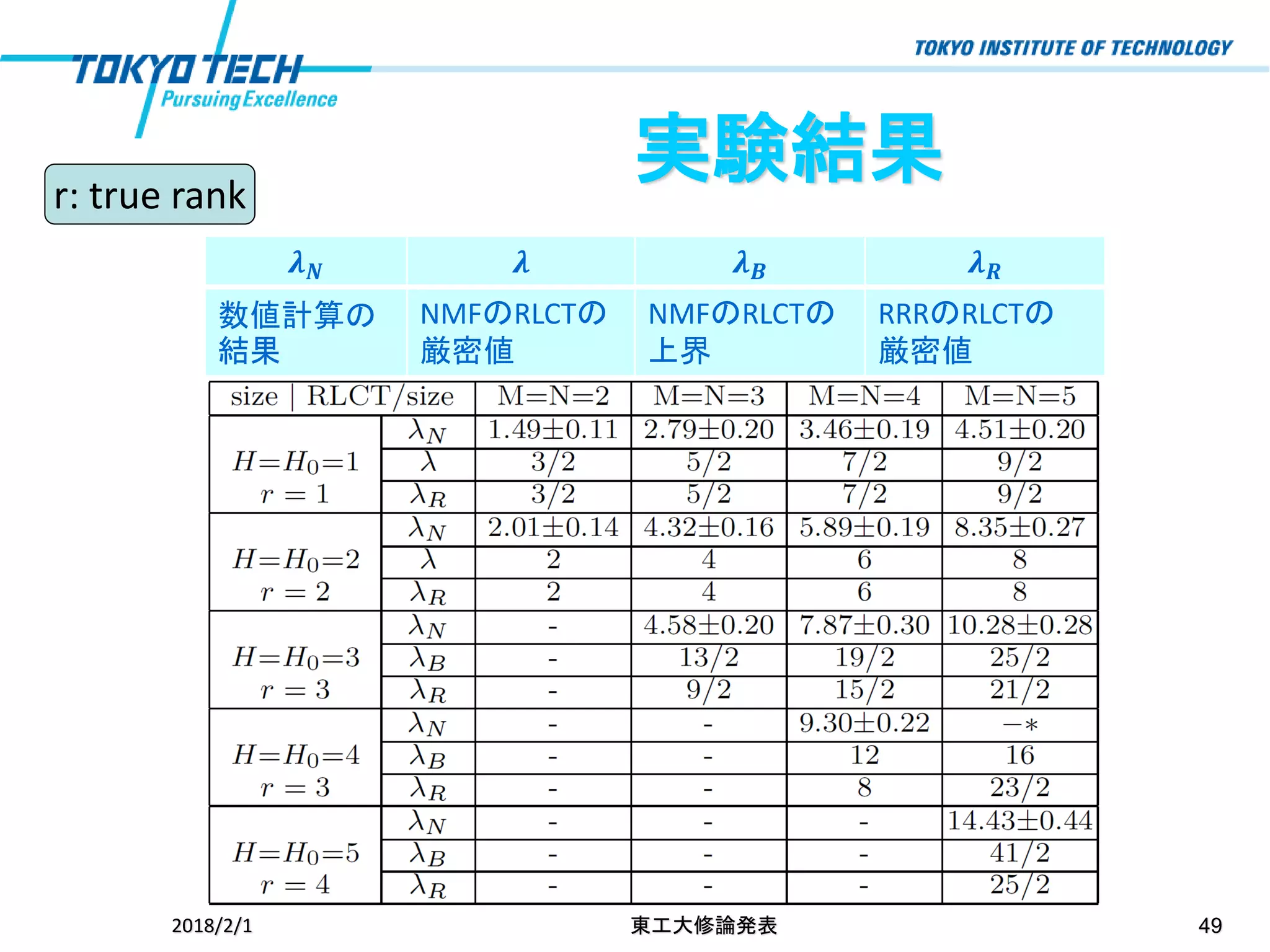
49.
2018/2/1 東工大修論発表 49 実験結果 𝝀
𝑵 𝝀 𝝀 𝑩 𝝀 𝑹 数値計算の 結果 NMFのRLCTの 厳密値 NMFのRLCTの 上界 RRRのRLCTの 厳密値 r: true rank
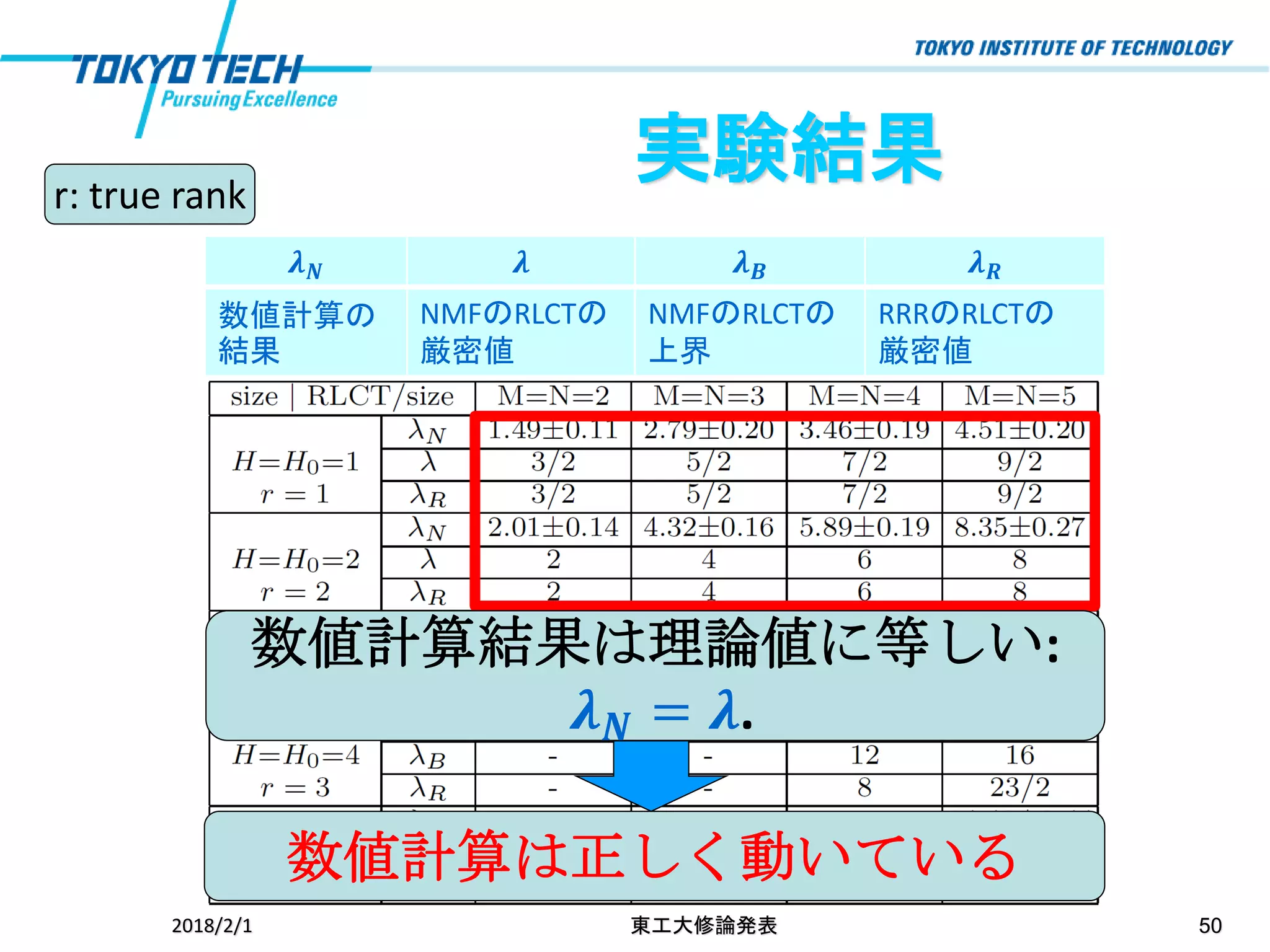
50.
2018/2/1 東工大修論発表 50 実験結果 数値計算結果は理論値に等しい: 𝝀
𝑵 = 𝝀. 数値計算は正しく動いている r: true rank 𝝀 𝑵 𝝀 𝝀 𝑩 𝝀 𝑹 数値計算の 結果 NMFのRLCTの 厳密値 NMFのRLCTの 上界 RRRのRLCTの 厳密値
51.
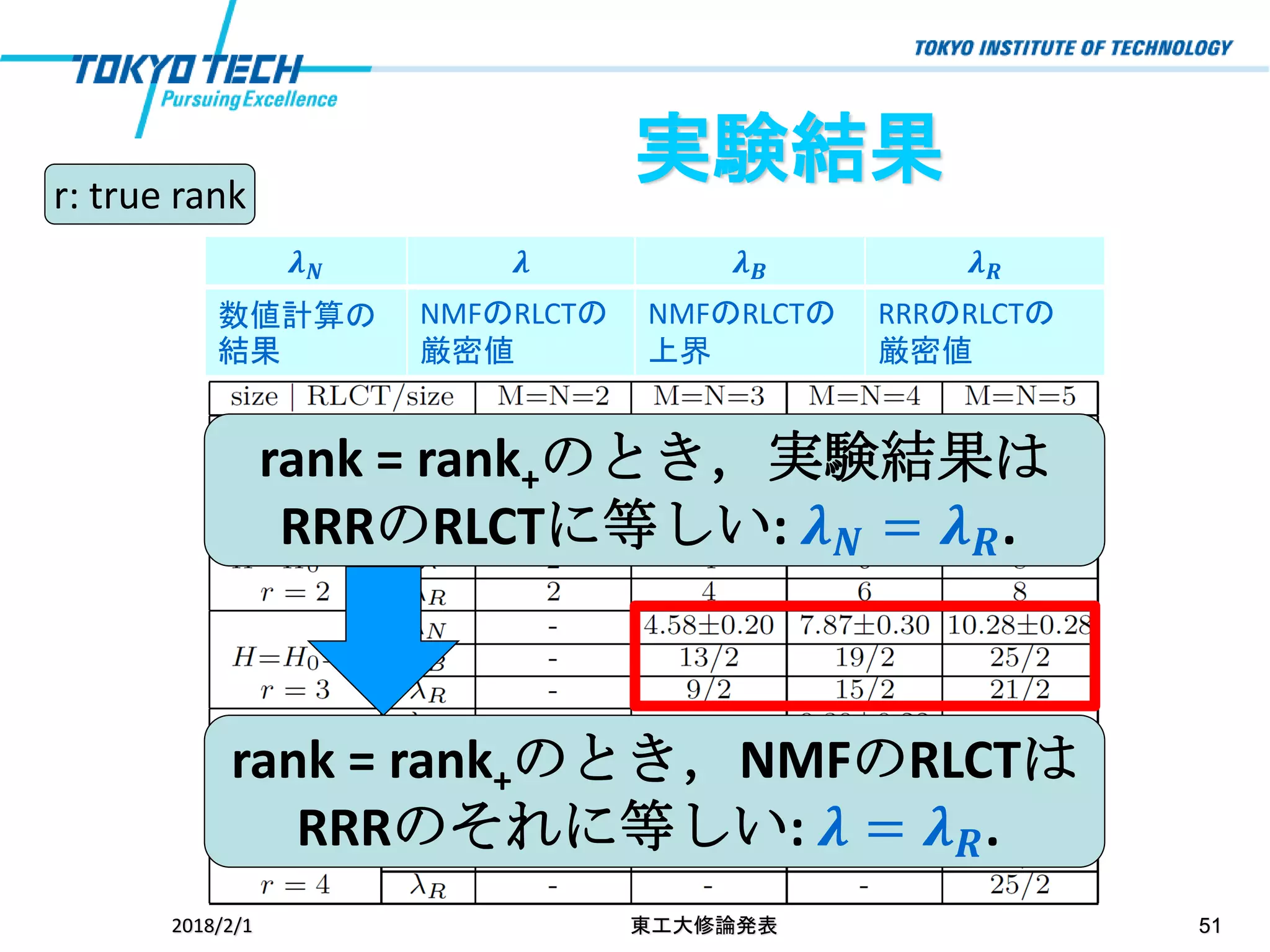
2018/2/1 東工大修論発表 51 実験結果r:
true rank rank = rank+のとき,実験結果は RRRのRLCTに等しい: 𝝀 𝑵 = 𝝀 𝑹. rank = rank+のとき,NMFのRLCTは RRRのそれに等しい: 𝝀 = 𝝀 𝑹. 𝝀 𝑵 𝝀 𝝀 𝑩 𝝀 𝑹 数値計算の 結果 NMFのRLCTの 厳密値 NMFのRLCTの 上界 RRRのRLCTの 厳密値
52.
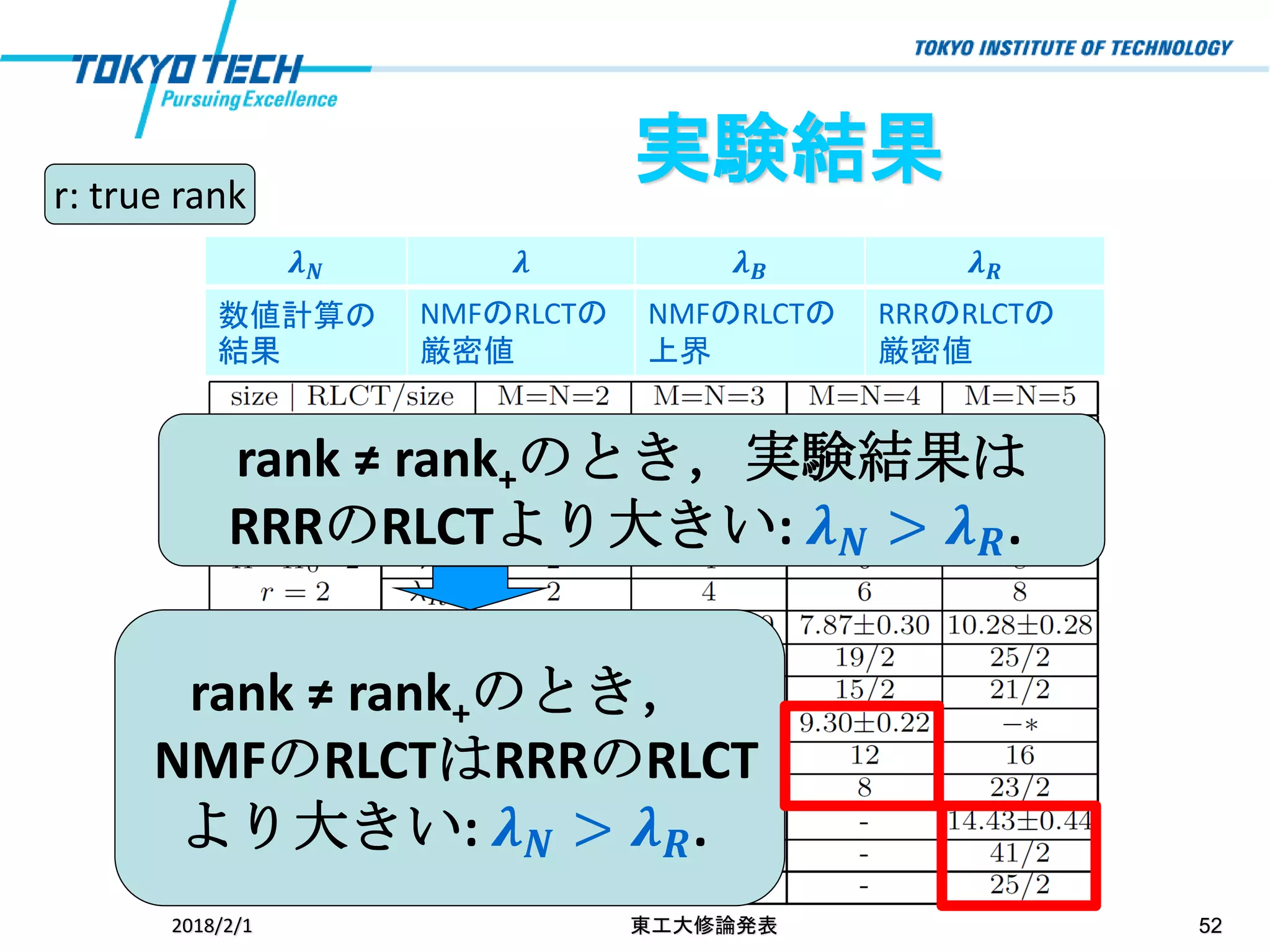
2018/2/1 東工大修論発表 52 実験結果r:
true rank rank ≠ rank+のとき,実験結果は RRRのRLCTより大きい: 𝝀 𝑵 > 𝝀 𝑹. rank ≠ rank+のとき, NMFのRLCTはRRRのRLCT より大きい: 𝝀 𝑵 > 𝝀 𝑹. 𝝀 𝑵 𝝀 𝝀 𝑩 𝝀 𝑹 数値計算の 結果 NMFのRLCTの 厳密値 NMFのRLCTの 上界 RRRのRLCTの 厳密値
53.
2018/2/1 東工大修論発表 53 NMFのRLCTの厳密値(予想)
54.
4. 結論 2018/2/1 東工大修論発表
54
55.
目次 • 背景 • 主定理 •
実験と考察 • 結論 2018/2/1 東工大修論発表 55
56.
• (主な貢献)非負値行列分解の実対数閾値の上界を理 論的に導出した. – この上界は非負値行列分解のBayes汎化誤差の理論上界と なり,数値計算結果の検証や適切な内部次元の設計に役立 てることができる. •
(補足的貢献)非負値行列分解の実対数閾値の数値的 な挙動を検証し,ランクと非負値ランクの違いに着目し てその厳密値の範囲を予想した: – ・ rank = rank+ ⇒ RLCT of NMF = RLCT of RRR. – ・ rank ≠ rank+ ⇒ RLCT of NMF > RLCT of RRR. 2018/2/1 東工大修論発表 56 結論
57.
• 雑誌論文 – Naoki
Hayashi, Sumio Watanabe. "Upper Bound of Bayesian Generalization Error in Non-Negative Matrix Factorization“, Neurocomputing, Volume 266C, 29 November 2017, pp.21- 28. (2017/4/27 accepted). • 国際会議 – Naoki Hayashi, Sumio Watanabe."Tighter Upper Bound of Real Log Canonical Threshold of Non-negative Matrix Factorization and its Application to Bayesian Inference“, 2017 IEEE Symposium Series on Computational Intelligence (IEEE SSCI 2017), Honolulu, Hawaii, USA. Nov. 27 - Dec 1, 2017. (2017/11/28). 2018/2/1 東工大修論発表 57 査読有り研究業績
58.
• 国内会議 – 林直輝,
渡邊澄夫. "非負値行列分解の実対数閾値とBayes学習への応用", 第19回情報論的学 習理論ワークショップ (IBIS2016), 信学技報, Vol.116, No.300, pp.215-220. (2016/11/17発表). – 林直輝, 渡邊澄夫. "非負値行列分解における実対数閾値の実験的考察", ニューロコンピューテ ィング研究会(NC), 信学技報, Vol.116, No.521, pp.85-90. (2017/3/13発表). – 林直輝, 中村文士. "特異Bayes情報量規準による混合正規分布のモデル選択における変分 Bayes法の実験的考察", 情報論的学習理論と機械学習(IBISML), 信学技報, Vol.117, No.211, pp.19-26. (2017/9/15発表). – 林直輝, 渡邊澄夫. "確率行列分解の実対数閾値とBayes学習への応用", 第20回情報論的学習 理論ワークショップ (IBIS2017), 信学技報, Vol.117, No.293, pp.23-30. (2017/11/9発表). • arXiv preprint – Naoki Hayashi, Sumio Watanabe. "Asymptotic Bayesian Generalization Error in a General Stochastic Matrix Factorization for Markov Chain and Bayesian Network", pp.1-36. (released on 2017/9/13, submitted to JMLR on 2017/12/4). 2018/2/1 東工大修論発表 58 査読無し研究業績
59.
• (主な貢献)非負値行列分解の実対数閾値の上界を理 論的に導出した. – この上界は非負値行列分解のBayes汎化誤差の理論上界と なり,数値計算結果の検証や適切な非負値ランクの設計に役 立てることができる. •
(補足的貢献)非負値行列分解の実対数閾値の数値的 な挙動を検証し,ランクと非負値ランクの違いに着目し てその厳密値の範囲を予想した: – ・ rank = rank+ ⇒ RLCT of NMF = RLCT of RRR. – ・ rank ≠ rank+ ⇒ RLCT of NMF > RLCT of RRR. 2018/2/1 東工大修論発表 59 結論
Download












![• 一般に,[Watanabe, 2001]
– n をサンプルサイズ
– Bayes汎化誤差を 𝑮 𝒏
とするとその平均値の漸近挙動は:
𝔼 𝑮 𝒏 =
𝝀
𝒏
+ 𝒐
𝟏
𝒏
.
• 主要項の係数𝝀 はモデル依存
• 𝝀 は実対数閾値(real log canonical
threshold, RLCT) と呼ばれる
2018/2/1 東工大修論発表 16
RLCTと学習の関係は?](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-16-2048.jpg)
![Bayesは最尤より誤差が小さい
• 階層的なモデルでは, 係数 𝝀 はBayes推定の場合
の方が最尤・事後確率最大化推定よりも小さい
[Watanabe,2001 and 2009]
• Bayes推定は汎化誤差を減らすために効果的
• 本研究ではBayes推定の枠組みでNMFを考える
– NMFのBayes推定は [Cemgil, 2009] で提案されているが,
離散的な場合のみ.本研究では連続的な場合も扱う.
2018/2/1 東工大修論発表 17](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-17-2048.jpg)

![RLCTの定義と応用
• RLCTは``学習係数’’として特徴づけられる
• 数学的な定義は以下の1変数複素函数を解析接続
したものの最大極の符号反転である:
𝜻 𝒛 = න𝑲 𝜽 𝒛 𝝋 𝜽 𝒅𝜽,
ここで 𝑲 は真の分布から学習機械へのKL情報量で,𝝋
は事前分布である.
• RLCTの理論値を用いるモデル選択手法が提案され
ている[Drton, et al. 2017].
2018/2/1 東工大修論発表 19](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-19-2048.jpg)
![RLCTの定義と応用
• RLCTは``学習係数’’として特徴づけられる
• 数学的な定義は以下の1変数複素函数を解析接続
したものの最大極の符号反転である:
𝜻 𝒛 = න𝑲 𝜽 𝒛 𝝋 𝜽 𝒅𝜽,
ここで 𝑲 は真の分布から学習機械へのKL情報量で,𝝋
は事前分布である.
• RLCTの理論値を用いるモデル選択手法が提案され
ている[Drton, et al. 2017].
2018/2/1 東工大修論発表 20
sBIC
(singular BIC)](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-20-2048.jpg)




![定式化と設定
• データ行列: 𝑾 𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏)
– 一般のため,複数(n>1)の行列の分解を考える.
2018/2/1 東工大修論発表 25
[Kohjima et al. 2016/6, modified]
𝑾𝑴
𝑵](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-25-2048.jpg)
![定式化と設定
• データ行列: 𝑾 𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏)
– 一般のため,複数(n>1)の行列の分解を考える.
• 真の分解: 𝑨; 𝑴 × 𝑯 𝟎, 𝑩; 𝑯 𝟎 × 𝑵
• 学習機械の分解: 𝑿; 𝑴 × 𝑯, 𝒀; 𝑯 × 𝑵
2018/2/1 東工大修論発表 26
[Kohjima et al. 2016/6, modified]
𝑾𝑴
𝑵 𝑯 𝟎 𝑵
𝑯 𝟎
𝑴 𝑨
𝑩](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-26-2048.jpg)
![定式化と設定
• データ行列: 𝑾 𝒏 = 𝑾 𝟏, … , 𝑾 𝒏 ; 𝑴 × 𝑵(× 𝒏)
– 一般のため,複数(n>1)の行列の分解を考える.
• 真の分解: 𝑨; 𝑴 × 𝑯 𝟎, 𝑩; 𝑯 𝟎 × 𝑵
• 学習機械の分解: 𝑿; 𝑴 × 𝑯, 𝒀; 𝑯 × 𝑵
• Bayes法の枠組みだとどうなるか?
2018/2/1 東工大修論発表 27
[Kohjima et al. 2016/6, modified]
𝑾𝑴
𝑵 𝑯 𝟎 𝑵
𝑯 𝟎
𝑴 𝑨
𝑩](https://image.slidesharecdn.com/hayashipptx-181009162226/75/Bayes-27-2048.jpg)






































![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)















![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


















