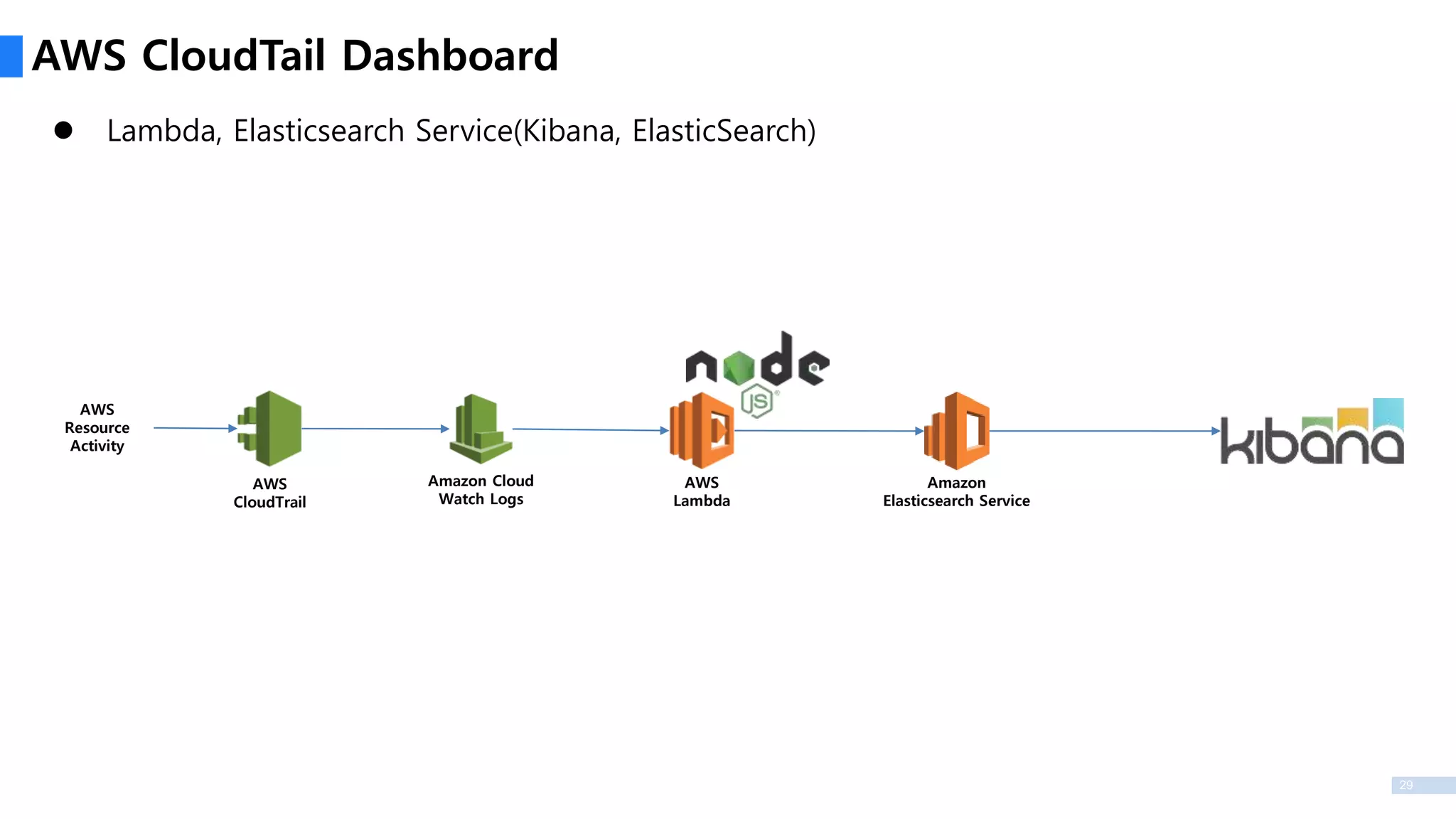
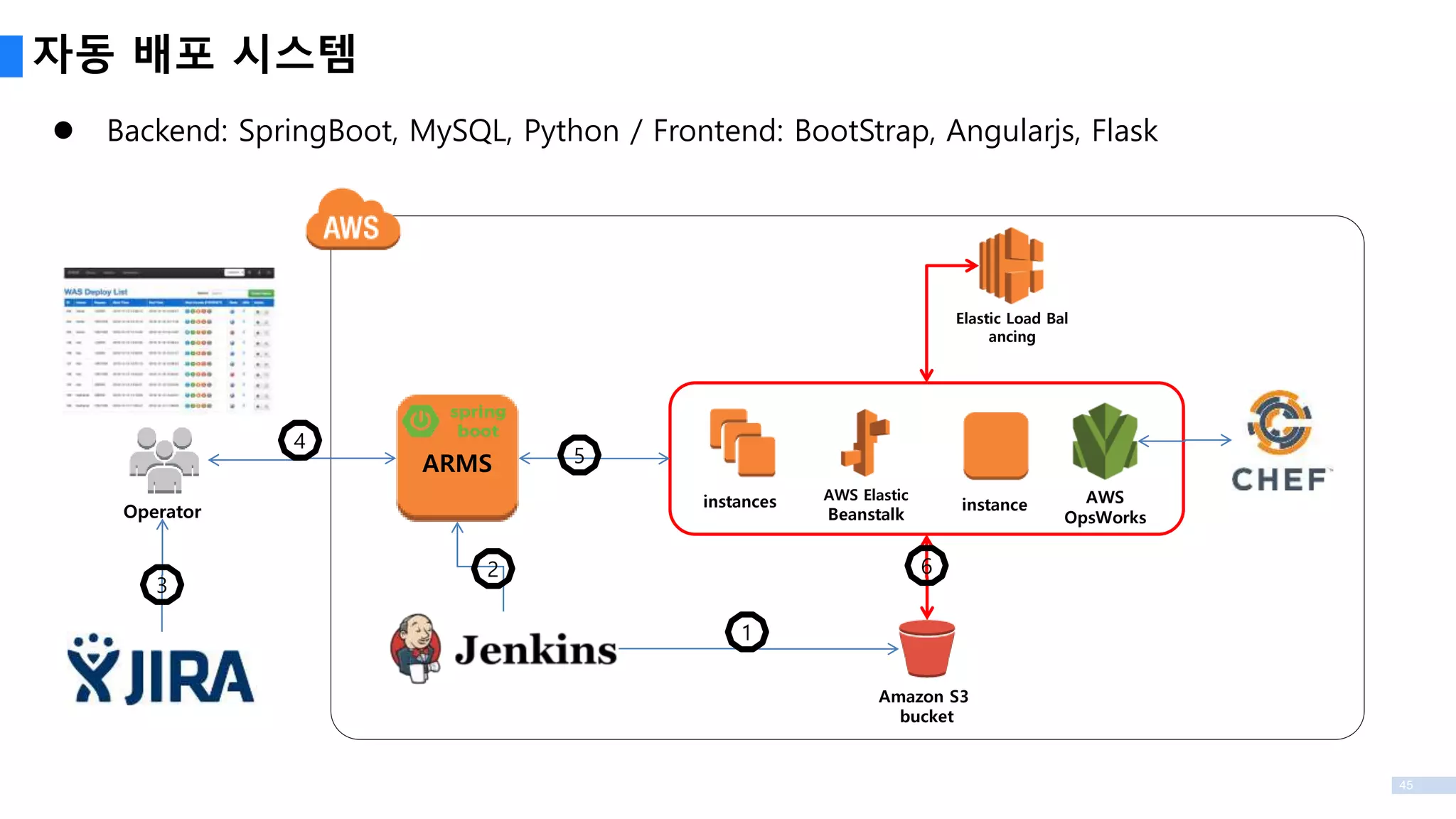
3
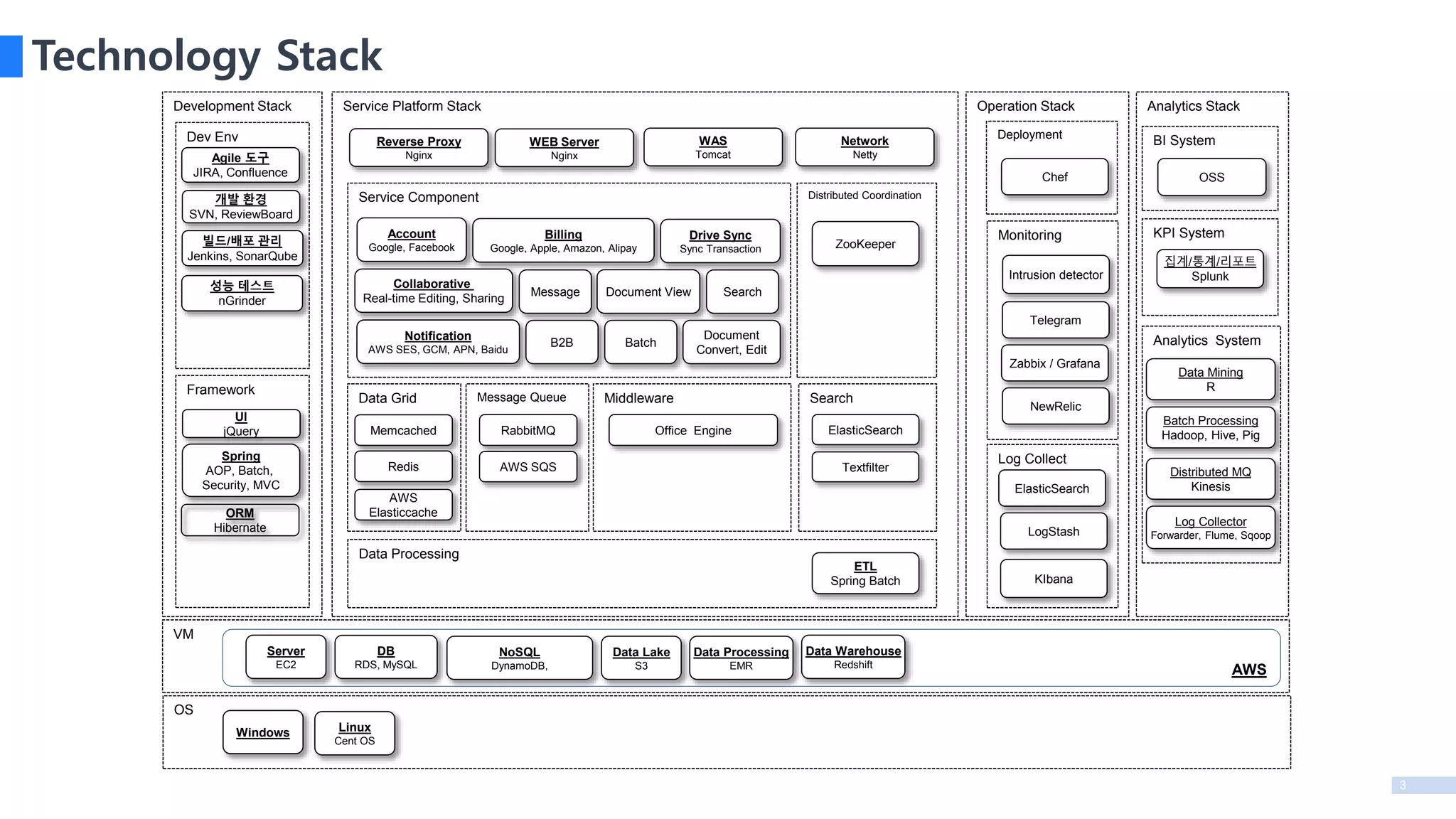
Technology Stack
VM
Service PlatformStack
Data Processing
Development Stack
Framework
Spring
AOP, Batch,
Security, MVC
Dev Env
개발 환경
SVN, ReviewBoard
성능 테스트
nGrinder
WEB Server
Nginx
WAS
Tomcat
Service Component
AWS
ETL
Spring Batch
Server
EC2
Data Lake
S3
ORM
Hibernate
Agile 도구
JIRA, Confluence
Data Processing
EMR
Data Warehouse
Redshift
DB
RDS, MySQL
OS
Windows Linux
Cent OS
UI
jQuery
빌드/배포 관리
Jenkins, SonarQube
Search
ElasticSearch
NoSQL
DynamoDB,
Middleware
Office Engine
Account
Google, Facebook
Billing
Google, Apple, Amazon, Alipay
Notification
AWS SES, GCM, APN, Baidu
Collaborative
Real-time Editing, Sharing
Reverse Proxy
Nginx
Document View
Data Grid
Distributed Coordination
ZooKeeper
Drive Sync
Sync Transaction
Memcached
Message Queue
RabbitMQ
AWS SQSRedis
B2B Batch
Message Search
Document
Convert, Edit
Operation Stack
Monitoring
Intrusion detector
Telegram
NewRelic
ElasticSearch
Log Collect
LogStash
KIbana
Deployment
Chef
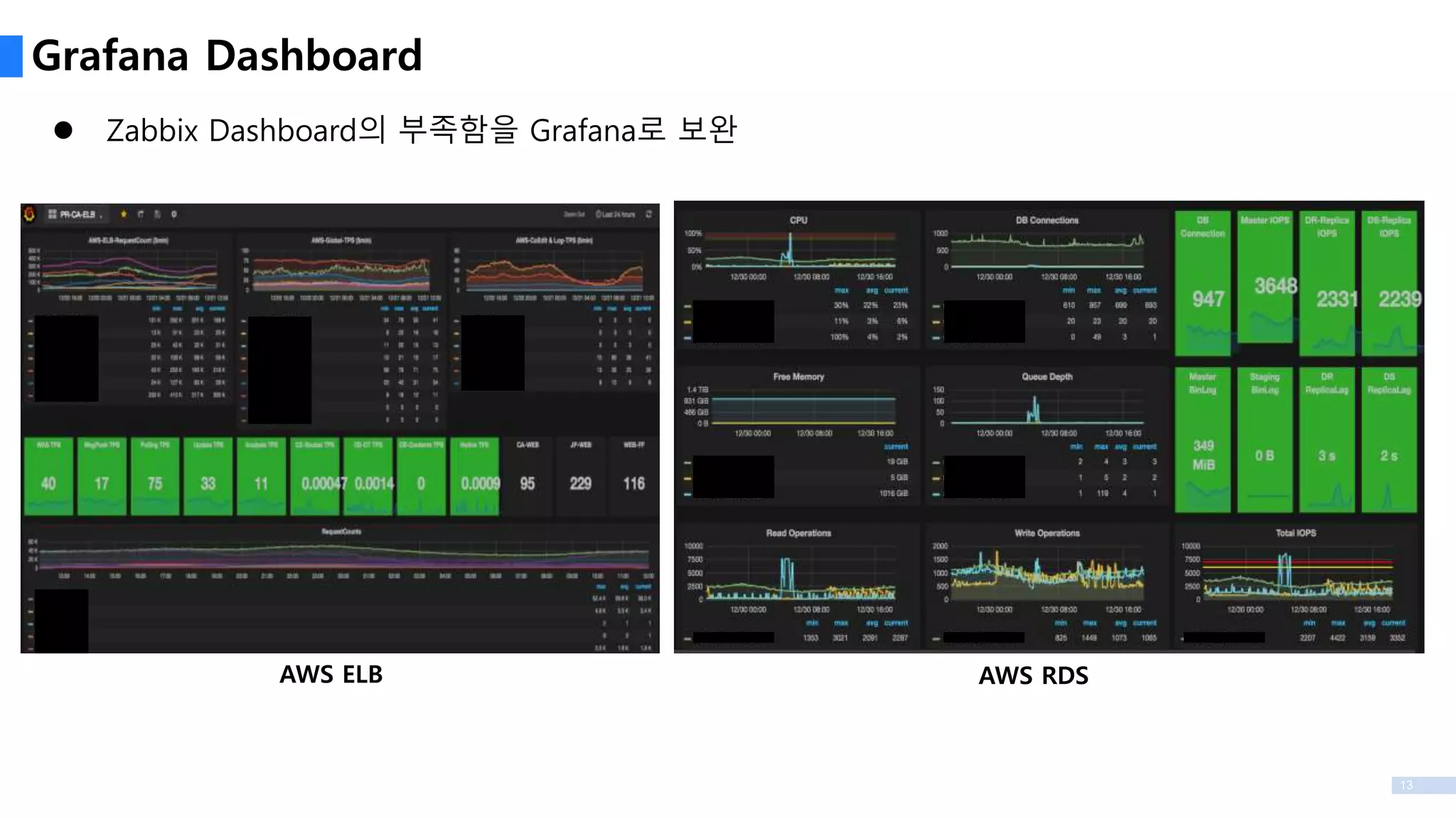
Zabbix / Grafana
Analytics Stack
Batch Processing
Hadoop, Hive, Pig
OSS
BI System
KPI System
집계/통계/리포트
Splunk
Log Collector
Forwarder, Flume, Sqoop
Analytics System
Distributed MQ
Kinesis
Data Mining
R
Textfilter
AWS
Elasticcache
Network
Netty
4.
4
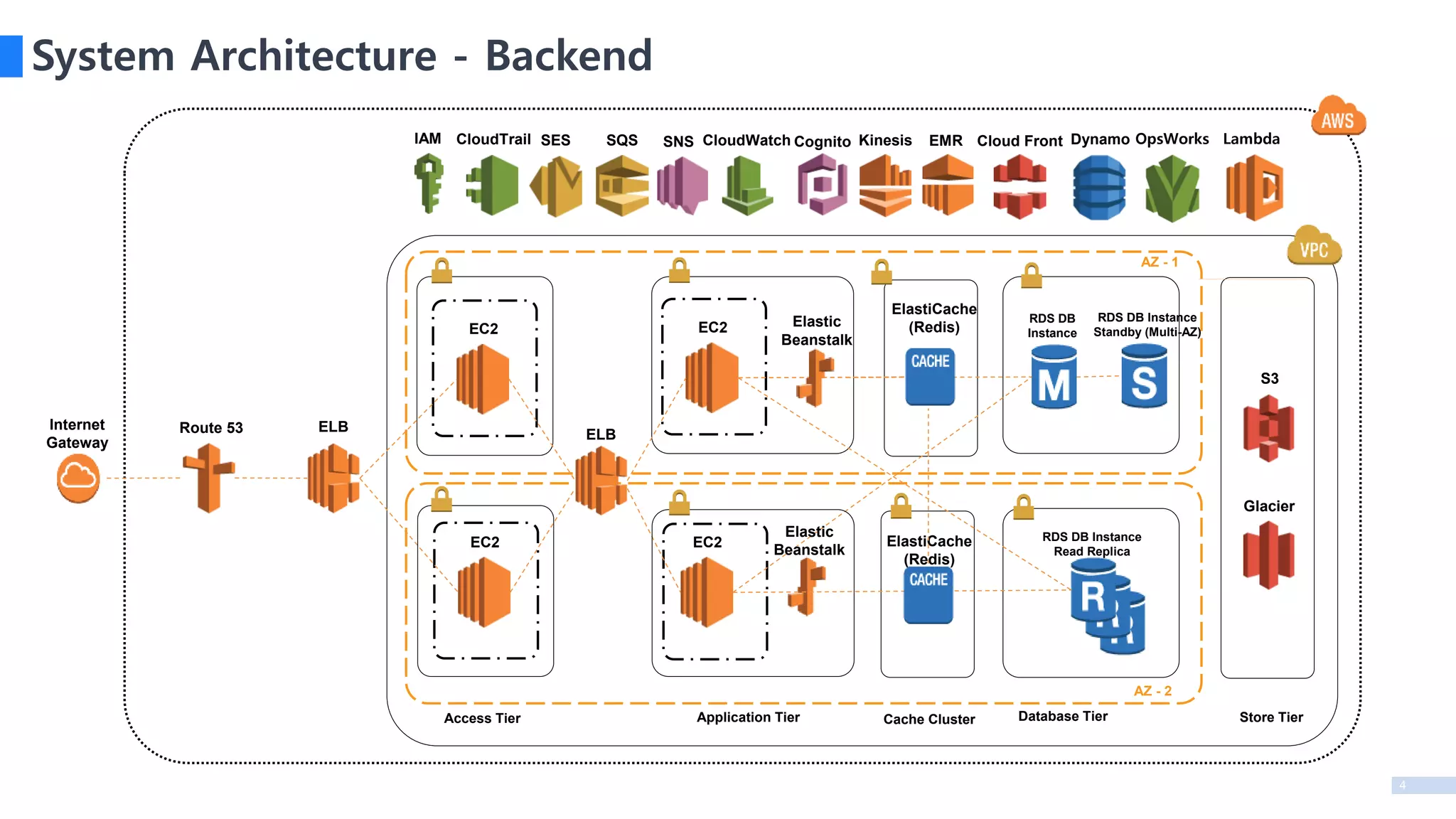
System Architecture -Backend
AZ - 1
AZ - 2
Access Tier
Internet
Gateway
Application Tier Database Tier
EC2
EC2
EC2
EC2
ELBRoute 53
S3
Glacier
RDS DB Instance
Standby (Multi-AZ)
RDS DB Instance
Read Replica
Cache Cluster Store Tier
Elastic
Beanstalk
ElastiCache
(Redis)
ELB
RDS DB
Instance
ElastiCache
(Redis)
Elastic
Beanstalk
SES SQS CloudWatch EMRKinesis Cloud FrontCognitoSNS DynamoCloudTrailIAM OpsWorks Lambda
5.
5
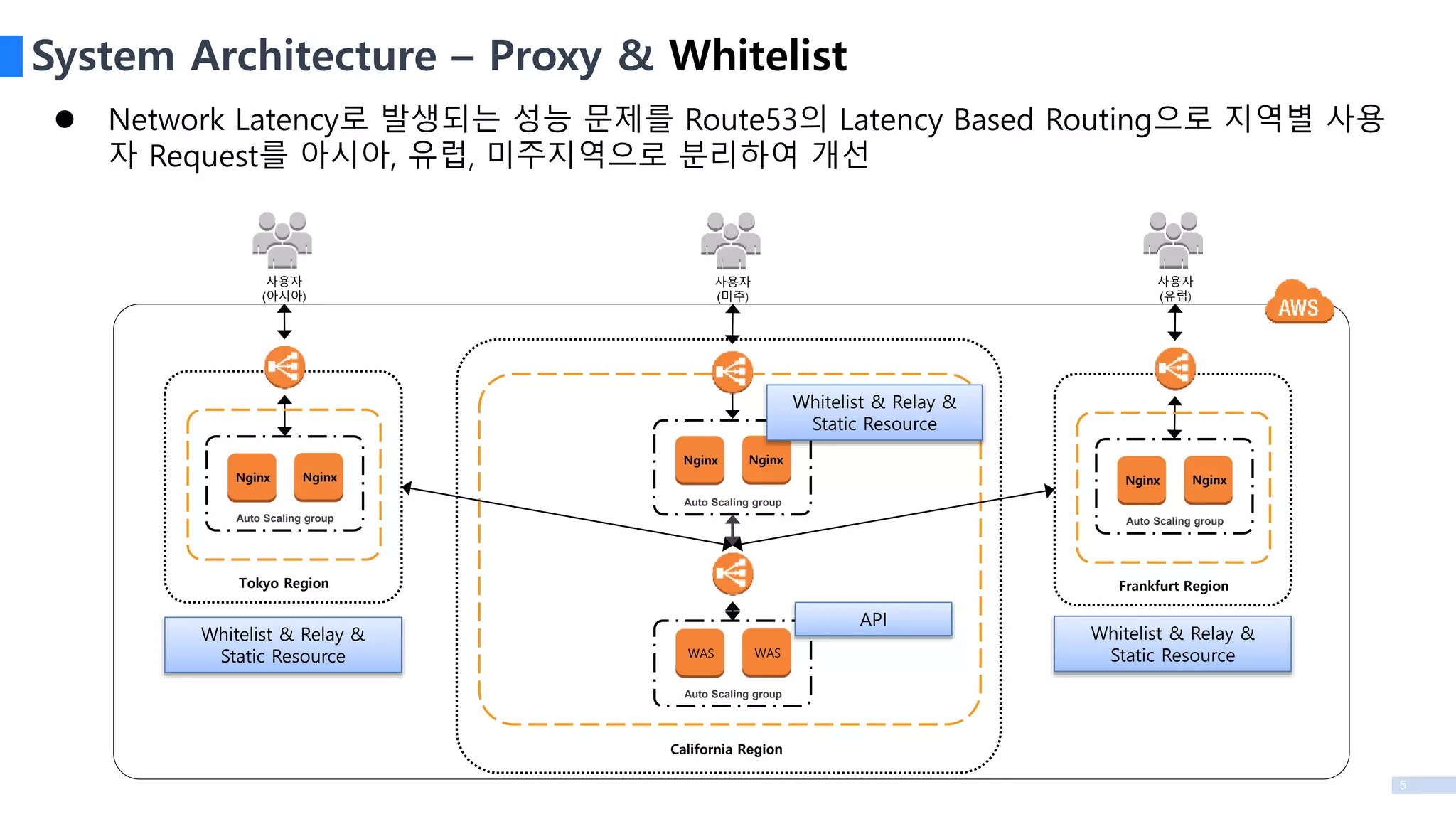
System Architecture –Proxy & Whitelist
Auto Scaling group
Nginx Nginx
Frankfurt Region
Auto Scaling group
Nginx Nginx
Auto Scaling group
WAS WAS
California Region
Auto Scaling group
Nginx Nginx
Tokyo Region
Whitelist & Relay &
Static Resource
Whitelist & Relay &
Static Resource
API
Whitelist & Relay &
Static Resource
Network Latency로 발생되는 성능 문제를 Route53의 Latency Based Routing으로 지역별 사용
자 Request를 아시아, 유럽, 미주지역으로 분리하여 개선
사용자
(아시아)
사용자
(미주)
사용자
(유럽)
6.
6
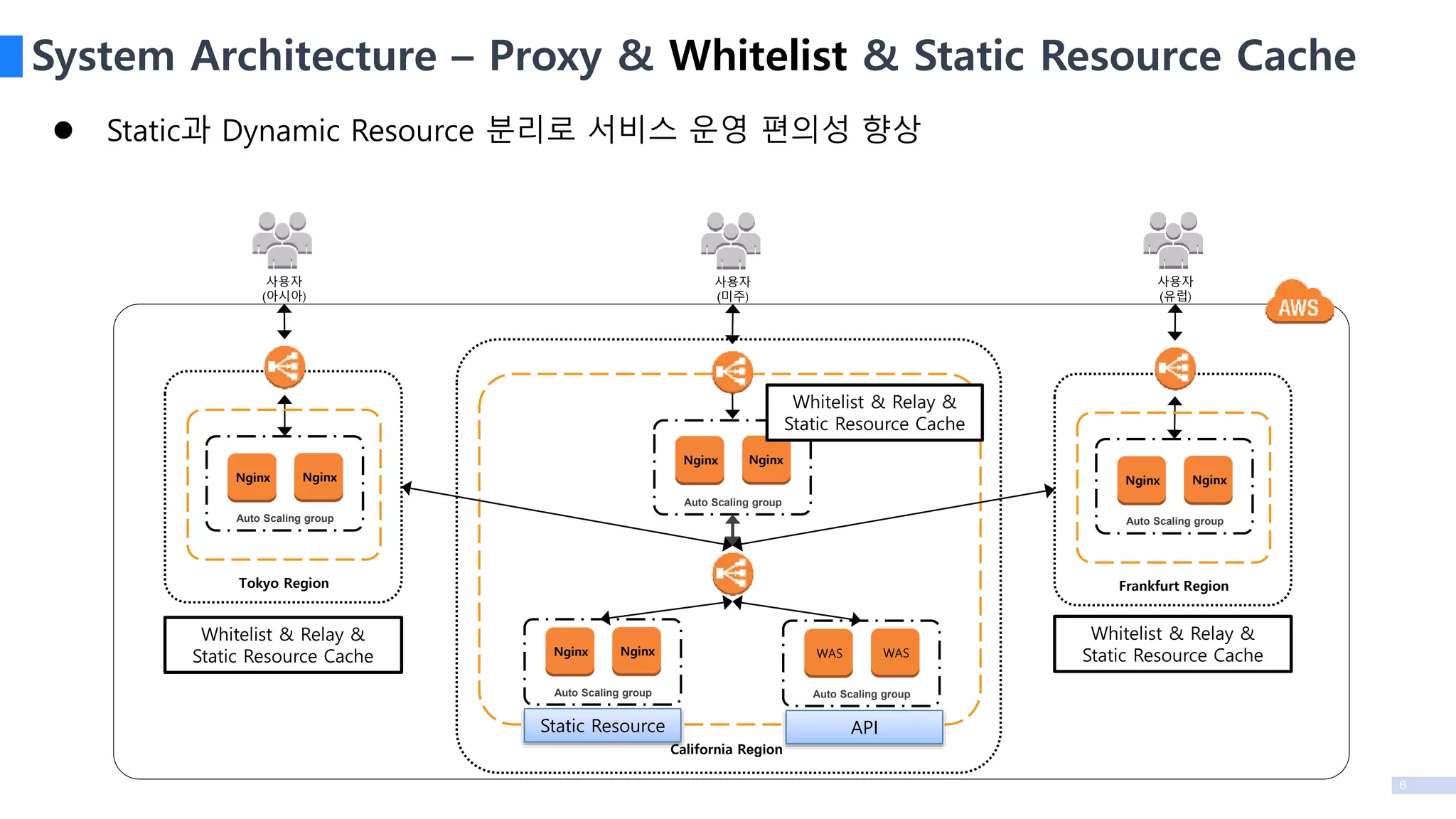
System Architecture –Proxy & Whitelist & Static Resource Cache
Auto Scaling group
Nginx Nginx
Frankfurt Region
Auto Scaling group
Nginx Nginx
Auto Scaling group
WAS WAS
California Region
Auto Scaling group
Nginx Nginx
Tokyo Region
Whitelist & Relay &
Static Resource Cache
Whitelist & Relay &
Static Resource Cache
API
Whitelist & Relay &
Static Resource Cache
사용자
(아시아)
사용자
(미주)
사용자
(유럽)
Auto Scaling group
Nginx Nginx
Static Resource
Static과 Dynamic Resource 분리로 서비스 운영 편의성 향상
7.
7
Static
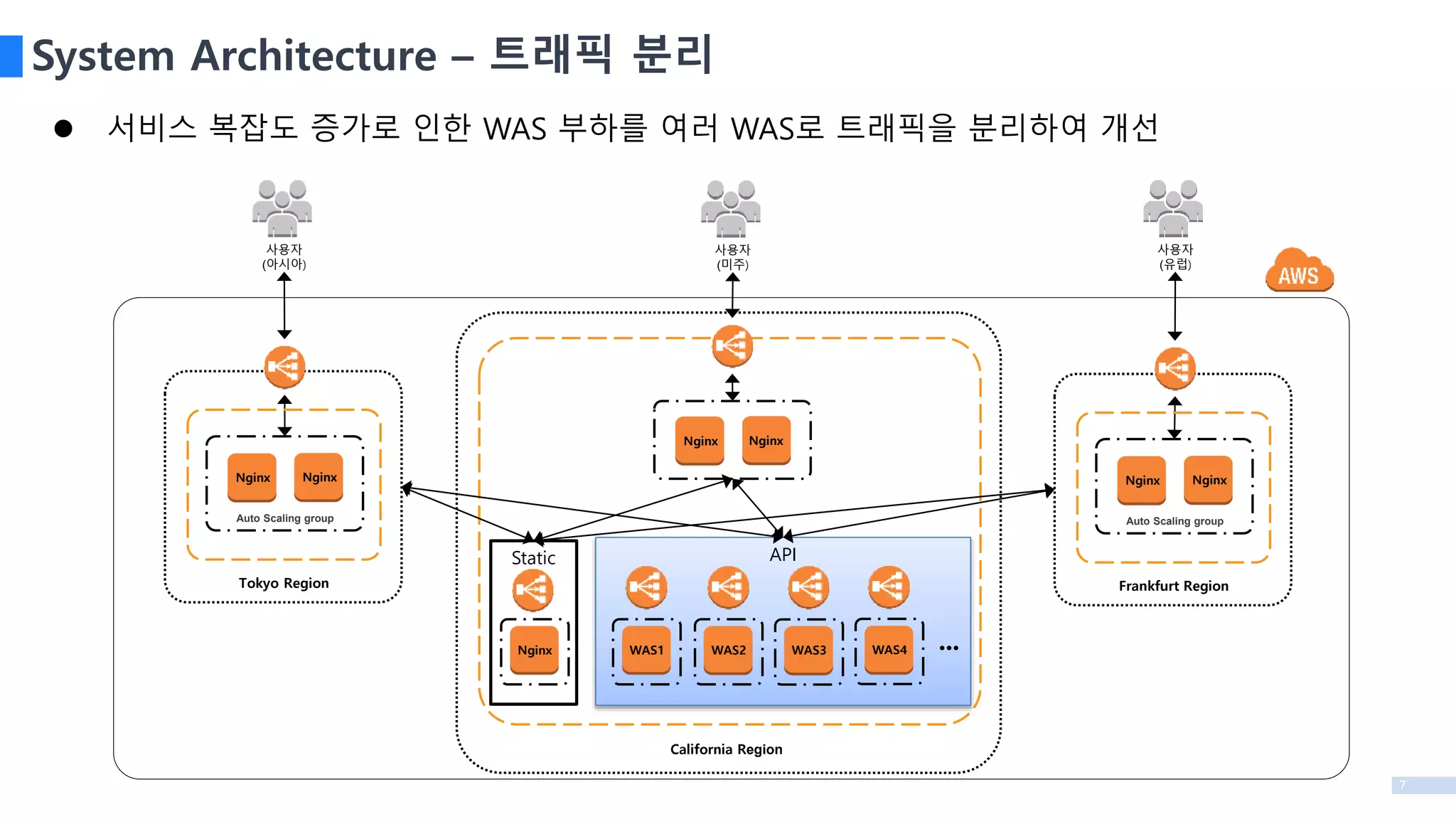
서비스 복잡도증가로 인한 WAS 부하를 여러 WAS로 트래픽을 분리하여 개선
System Architecture – 트래픽 분리
Auto Scaling group
Nginx Nginx
Frankfurt Region
Nginx Nginx
California Region
Auto Scaling group
Nginx Nginx
Tokyo Region
API
사용자
(아시아)
사용자
(미주)
사용자
(유럽)
Nginx WAS1 WAS2 WAS3 WAS4 •••
8.
8
Auto Scaling group
NginxNginx
Auto Scaling group
WAS WAS
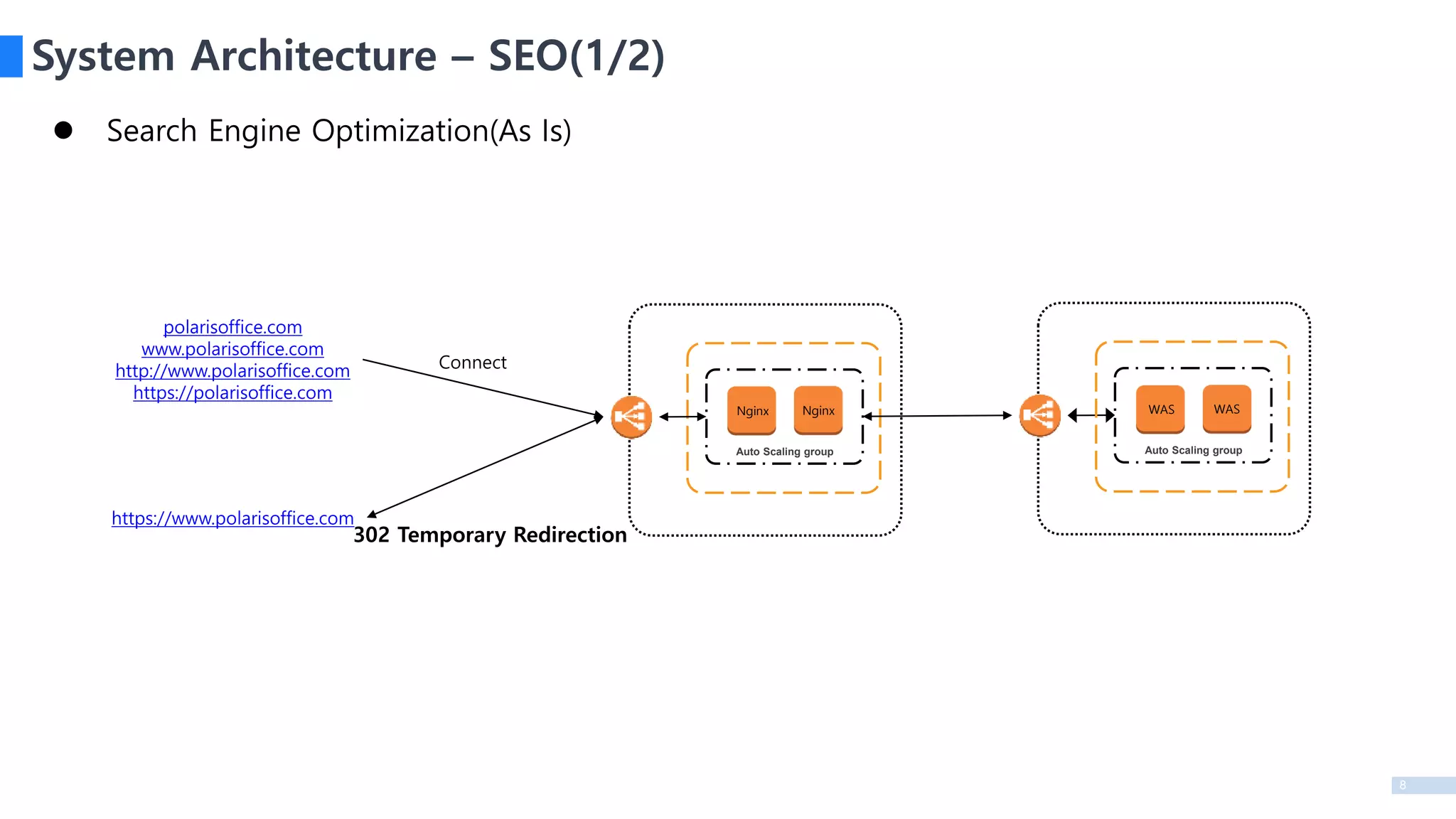
https://www.polarisoffice.com
polarisoffice.com
www.polarisoffice.com
http://www.polarisoffice.com
https://polarisoffice.com
Connect
302 Temporary Redirection
System Architecture – SEO(1/2)
Search Engine Optimization(As Is)
9.
9
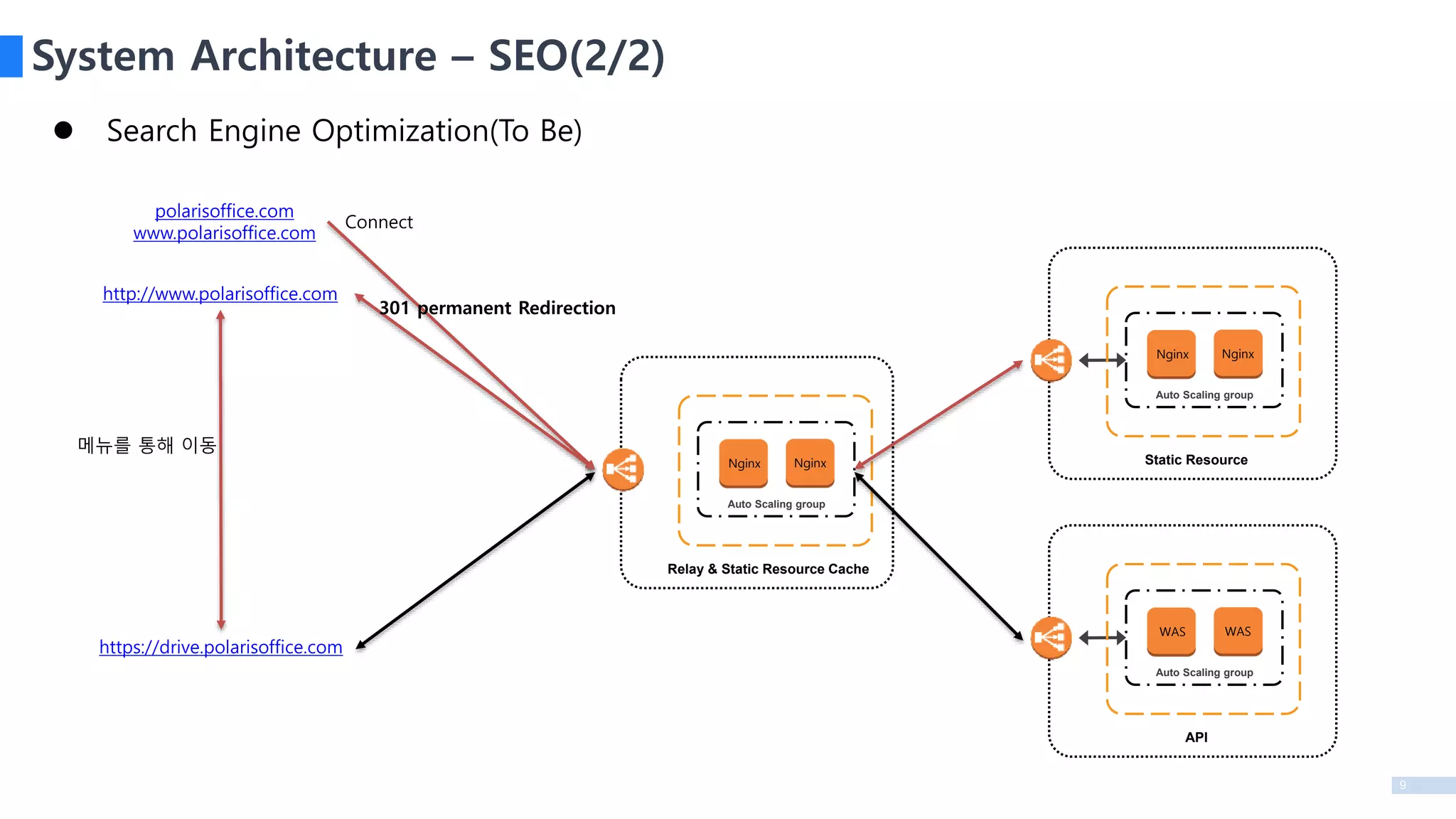
Search EngineOptimization(To Be)
System Architecture – SEO(2/2)
Auto Scaling group
Nginx Nginx
Relay & Static Resource Cache
Auto Scaling group
WAS WAS
API
http://www.polarisoffice.com
polarisoffice.com
www.polarisoffice.com
Connect
301 permanent Redirection
https://drive.polarisoffice.com
Auto Scaling group
Nginx Nginx
Static Resource
메뉴를 통해 이동
11
Update
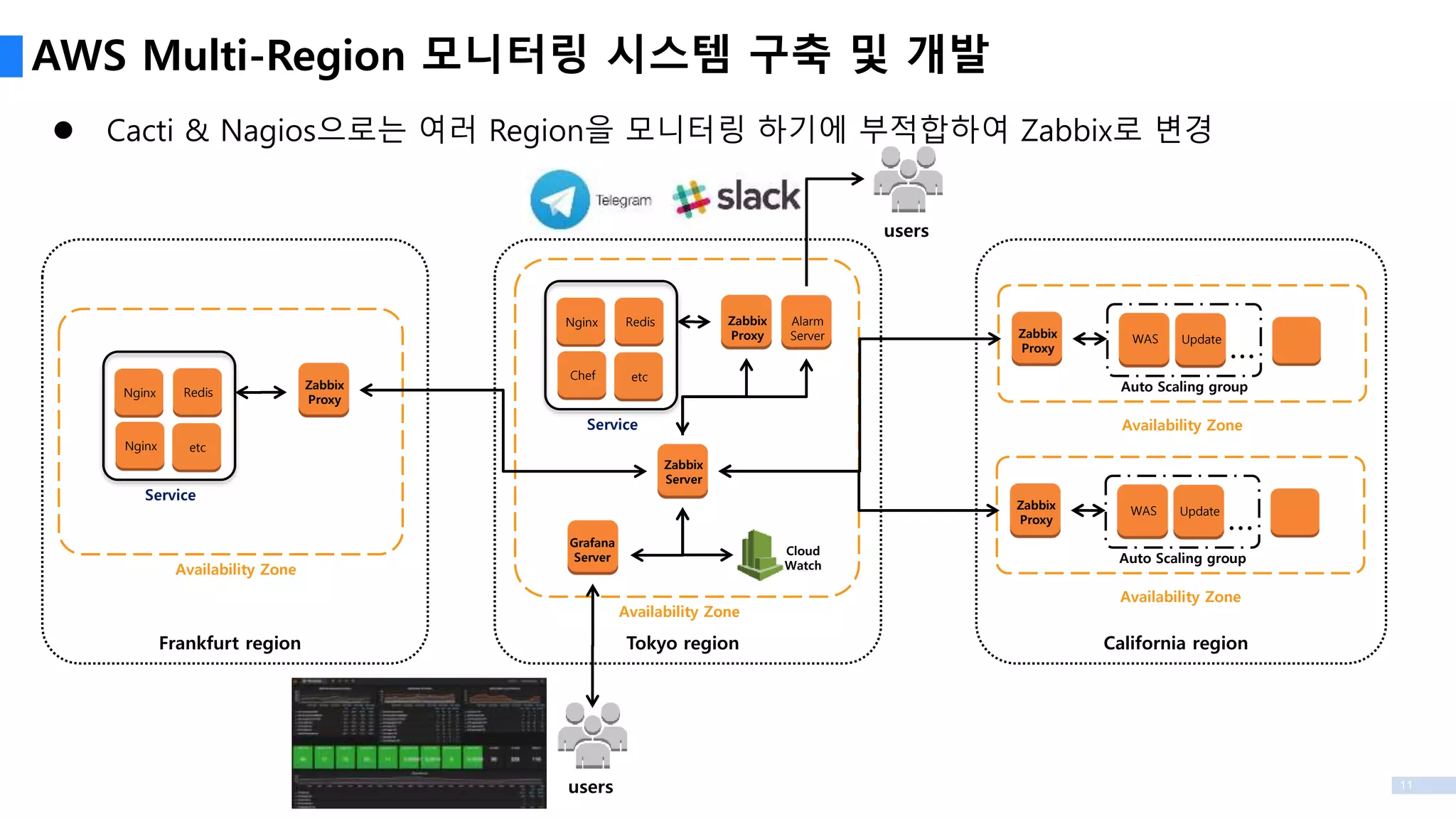
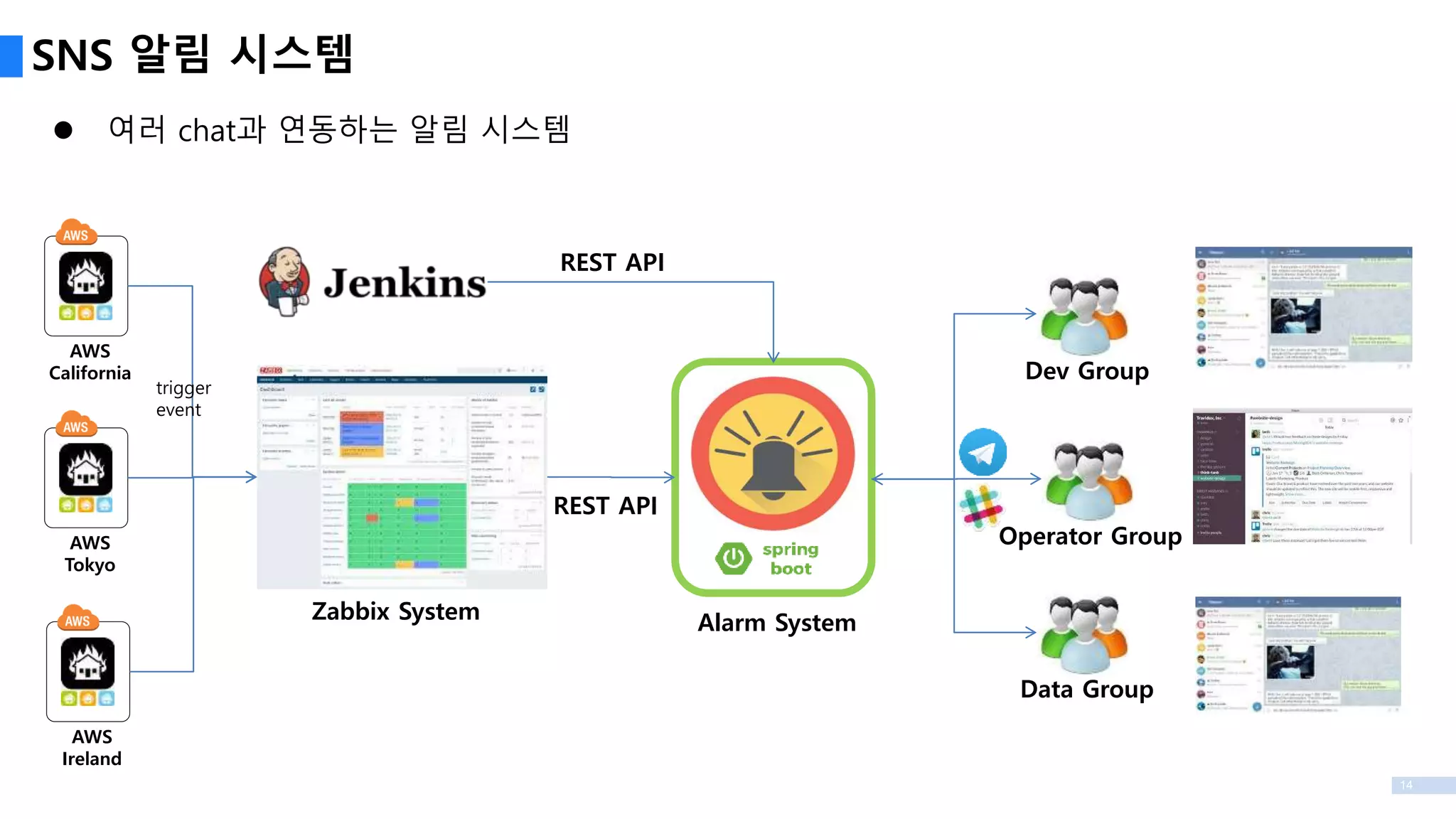
AWS Multi-Region 모니터링시스템 구축 및 개발
Frankfurt region Tokyo region California region
users
Availability Zone
Availability Zone
Cloud
Watch
Nginx Redis
Chef etc
Zabbix
Proxy
Service
Alarm
Server
Zabbix
Server
Grafana
Server
Availability Zone
WAS
Auto Scaling group
…
Zabbix
Proxy
Update
Availability Zone
WAS
Auto Scaling group
…
Zabbix
Proxy
Nginx Redis
Nginx etc
Zabbix
Proxy
Service
users
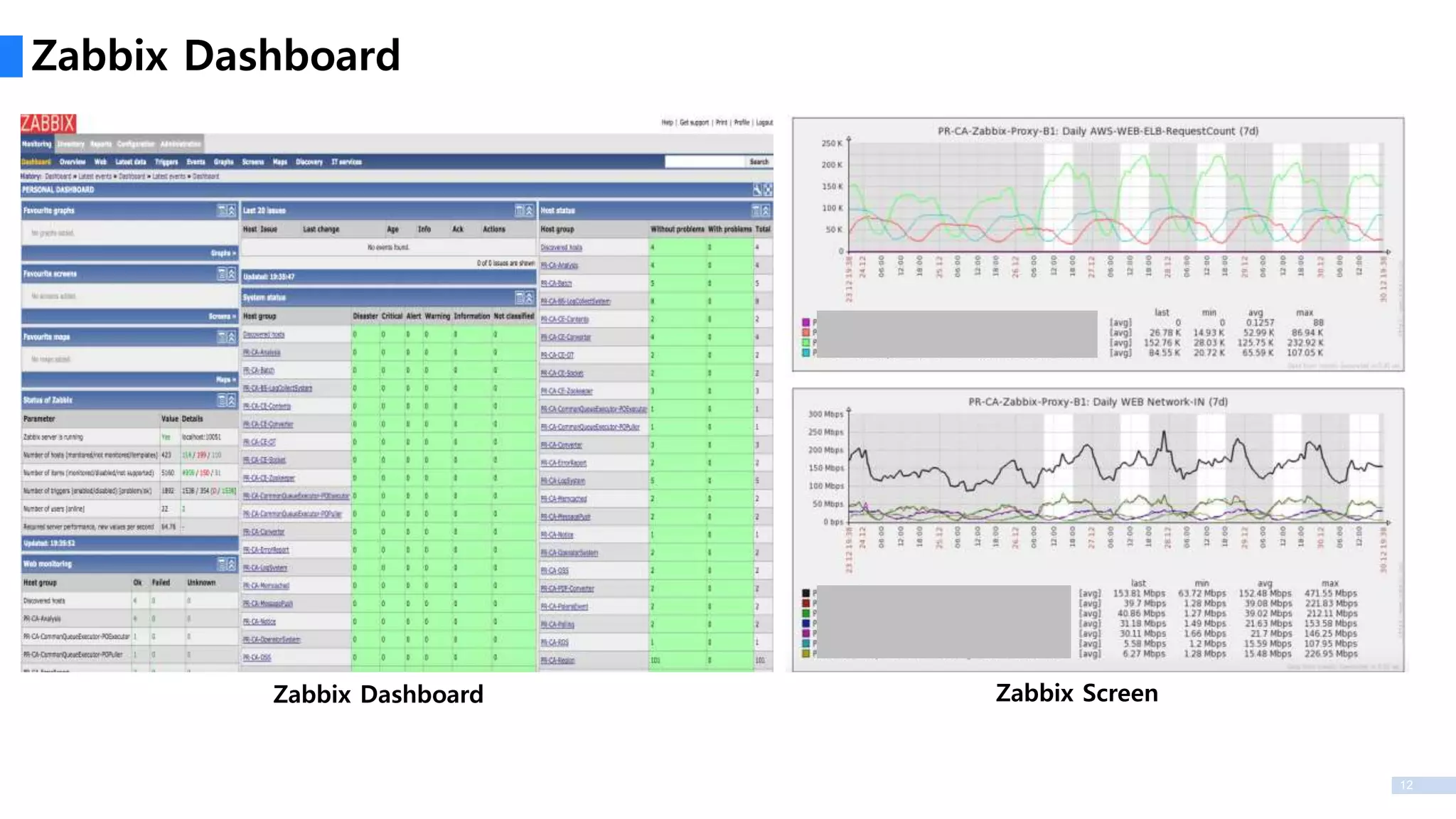
Cacti & Nagios으로는 여러 Region을 모니터링 하기에 부적합하여 Zabbix로 변경
16
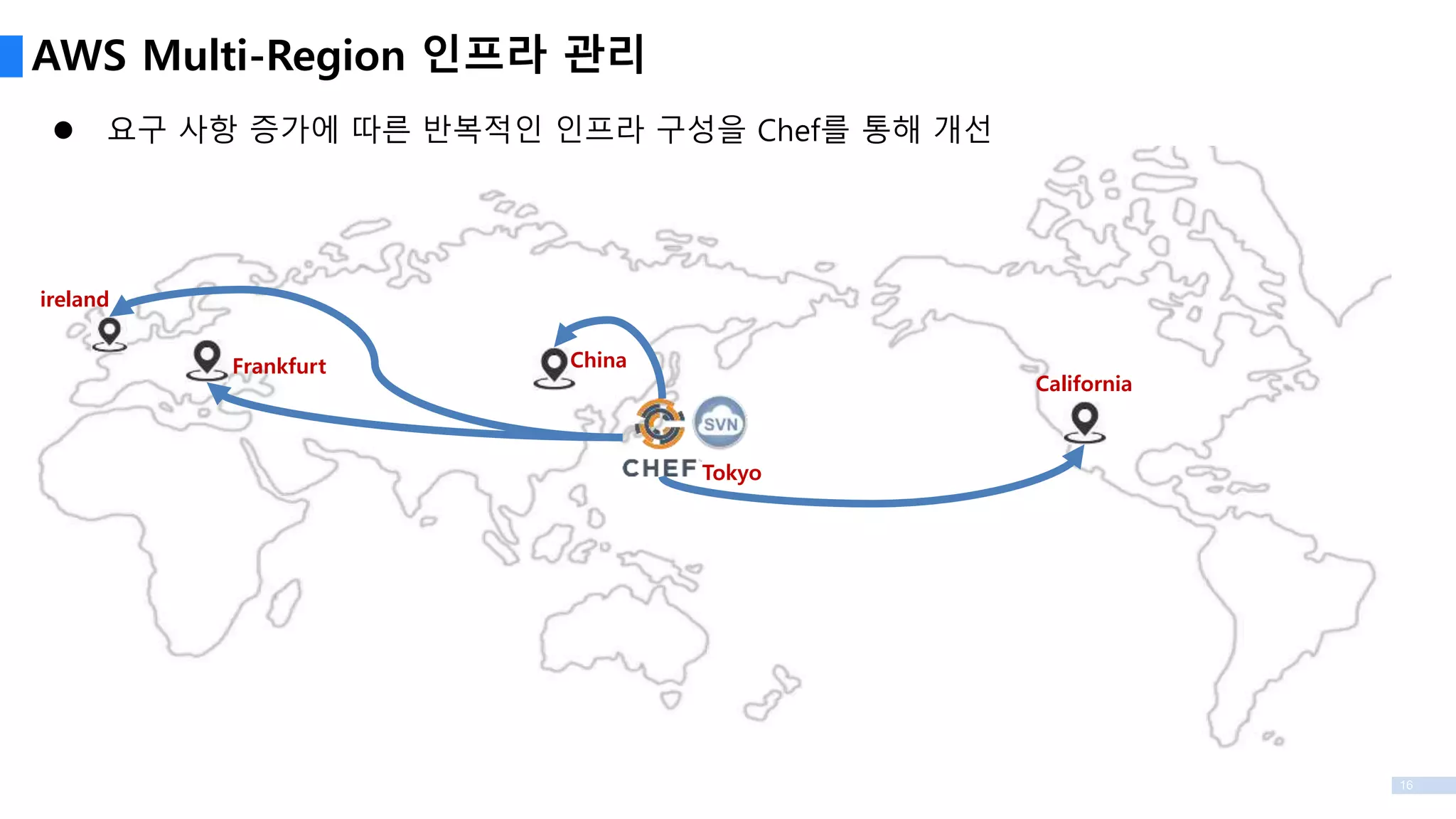
AWS Multi-Region 인프라관리
California
China
Tokyo
Frankfurt
ireland
요구 사항 증가에 따른 반복적인 인프라 구성을 Chef를 통해 개선
17.
17
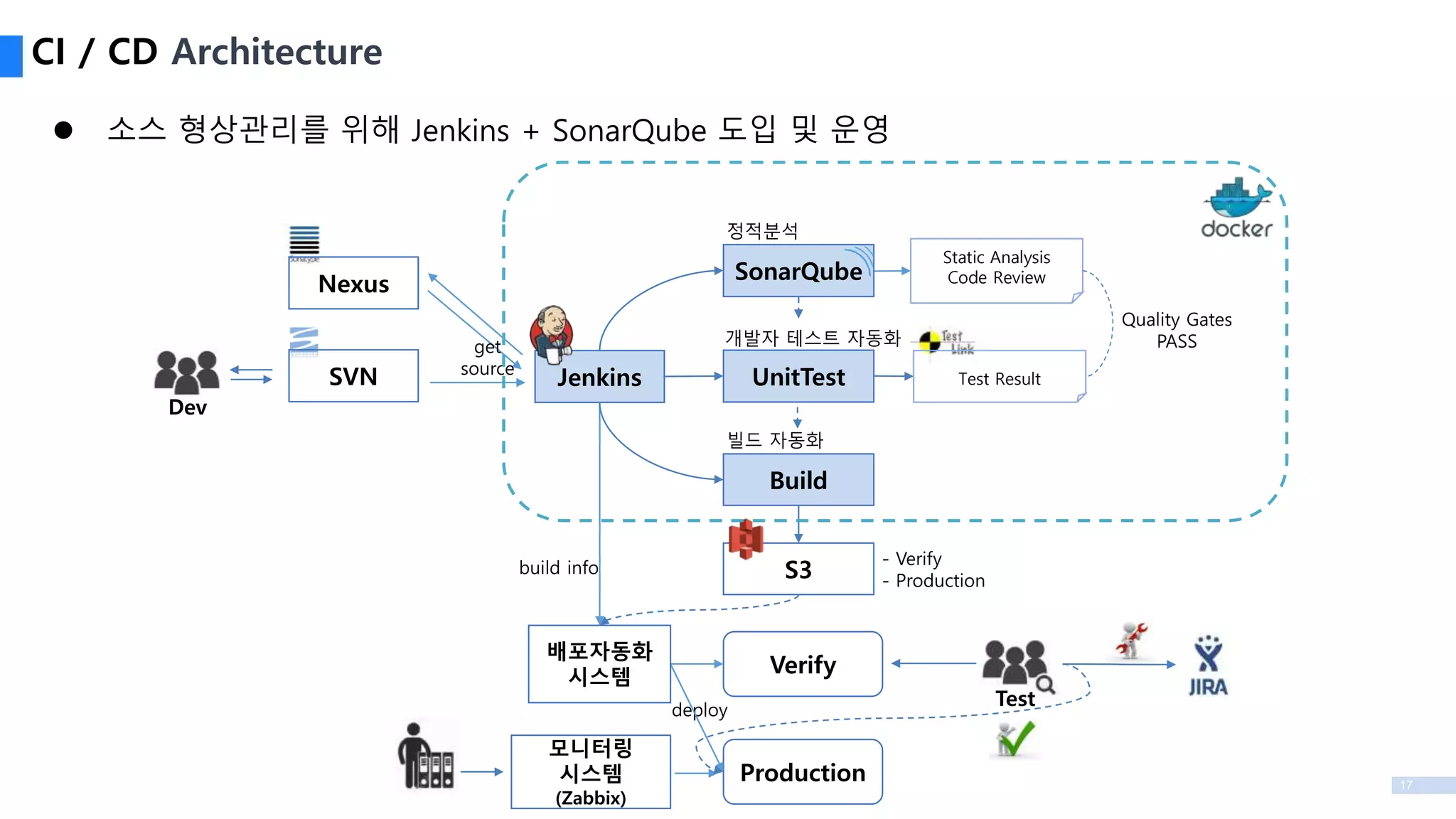
CI / CDArchitecture
Jenkins
Build
Verify
deploy
빌드 자동화
정적분석
Static Analysis
Code ReviewSonarQube
Production
모니터링
시스템
(Zabbix)
Dev
Test
Quality Gates
PASS
배포자동화
시스템
get
source
UnitTest
개발자 테스트 자동화
Test Result
S3build info - Verify
- Production
Nexus
SVN
소스 형상관리를 위해 Jenkins + SonarQube 도입 및 운영
18.
18
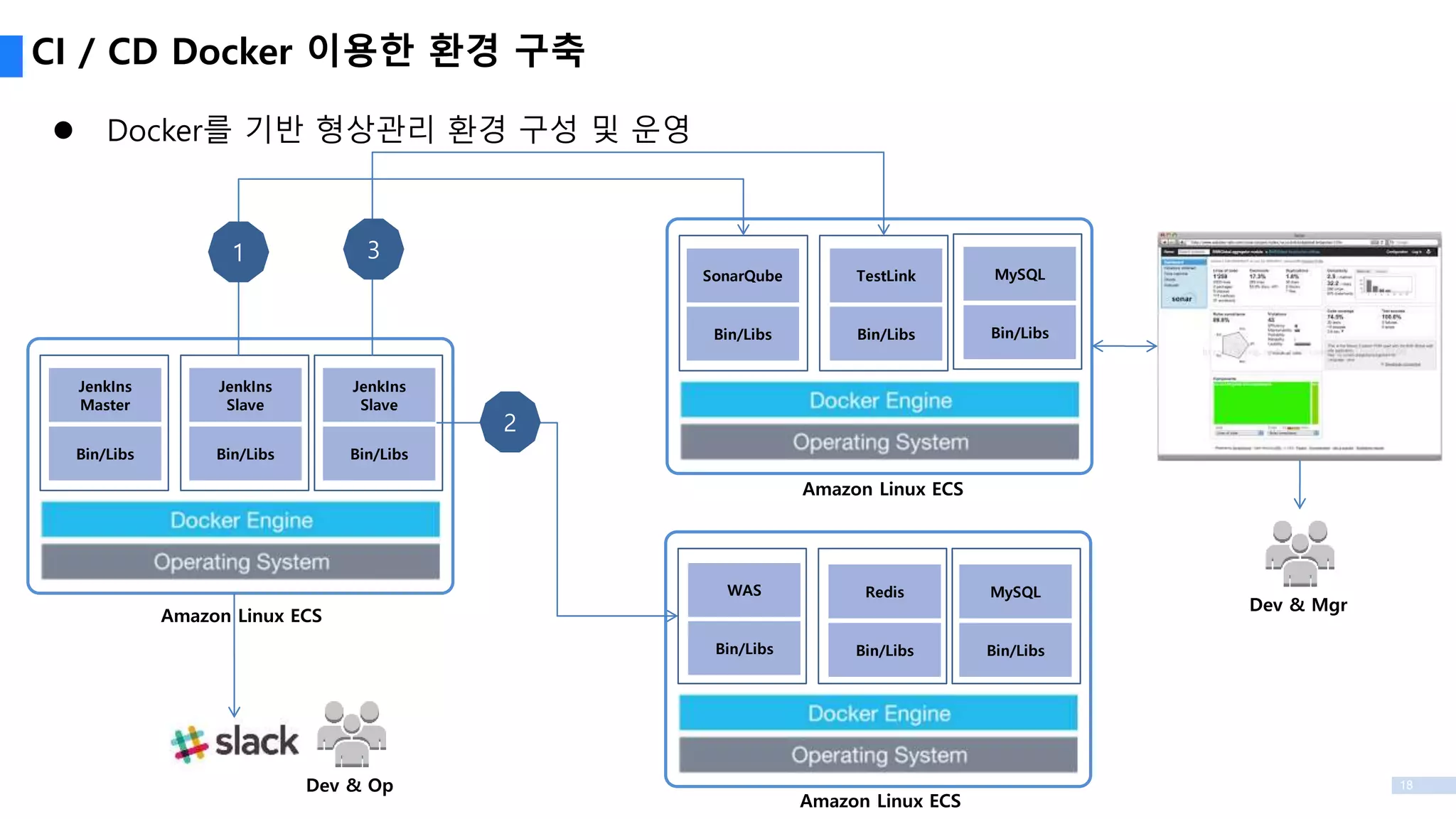
CI / CDDocker 이용한 환경 구축
Bin/Libs
JenkIns
Master
Bin/Libs
JenkIns
Slave
Bin/Libs
JenkIns
Slave
Bin/Libs
SonarQube
Bin/Libs
TestLink
Bin/Libs
MySQL
Bin/Libs
WAS
Bin/Libs
Redis
Bin/Libs
MySQL
Dev & Op
Dev & Mgr
Amazon Linux ECS
Amazon Linux ECS
Amazon Linux ECS
1
2
3
Docker를 기반 형상관리 환경 구성 및 운영
20
RDS 운영 현황
MAZ
Master
(active)
Master
(standby)
Replica-1
Replica-2
WAS
Update
Batch
EMR
Application
AvailabilityZone
California Region
Oregon Region
[Master]
db.r3.4xlarge : 16 vCore / 122GB
Storage : 3TB / 1,2000 IOPs
메인 서비스 및 Multi-AZ 구성
[Replica-1 / Replica-2]
db.m4.2xlarge : 8 vCore / 32GB
Storage : 3TB / 9,000 IOPs
용도 : Data Dump 및 Disaster Recovery
Disaster Recovery Replica-2는 Oregon에
구성되어 있으며, Batch Job 등, 비 실시간
서비스에서 주로 사용하고 있음
[Database 사용 현황]
Storage 현황 : 1.95 TB(Index 비율 : 37%)
CPU 현황 : 45%
IOPs 현황 : 6,000 IOPs
[주요 Table 현황]
Table 1 : Rows(21억), Data(626 GB)
Table 2 : Rows(12억), Data(671 GB)
21.
21
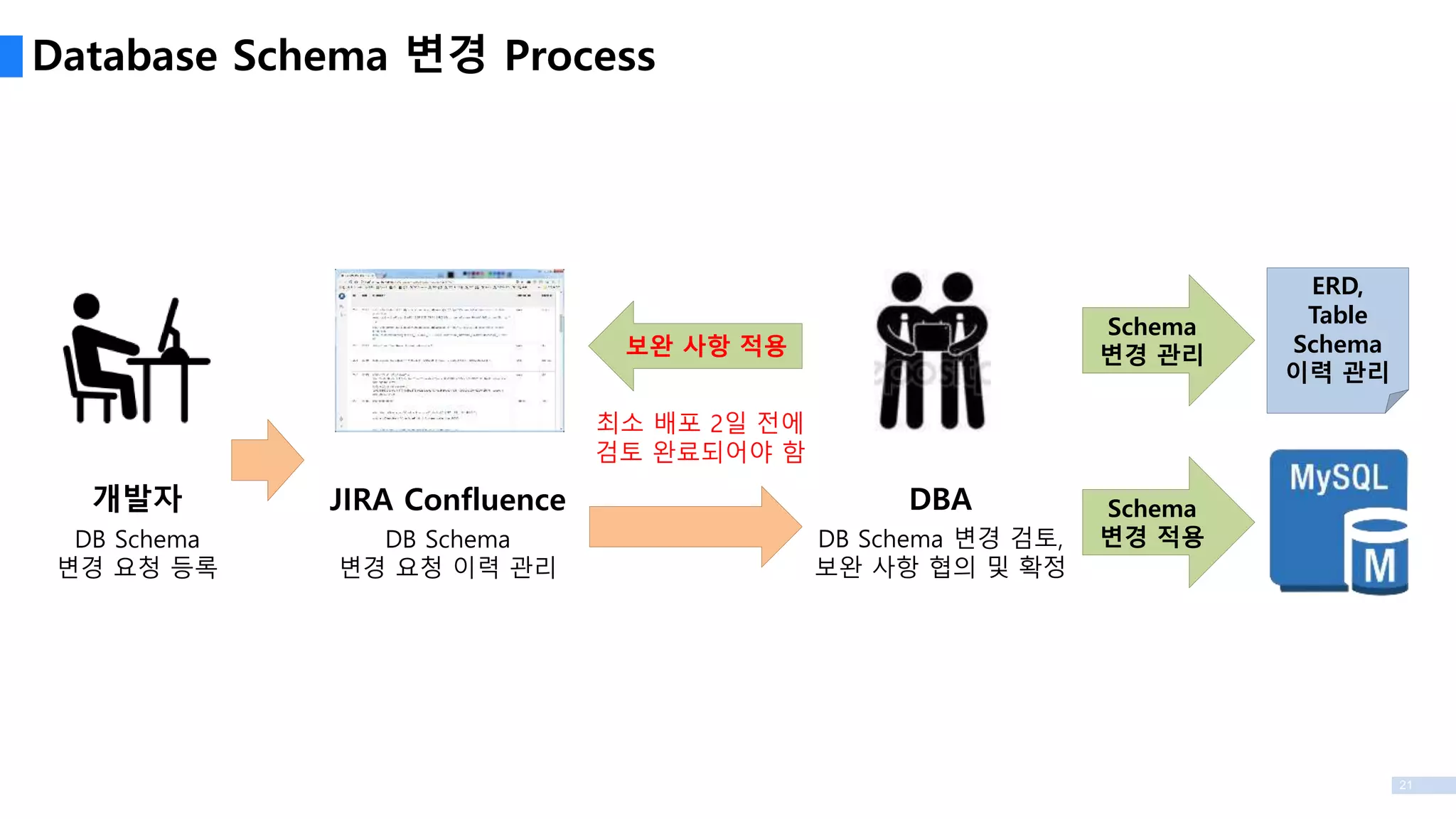
Database Schema 변경Process
개발자
DB Schema
변경 요청 등록
ERD,
Table
Schema
이력 관리
JIRA Confluence
DB Schema
변경 요청 이력 관리
DBA
DB Schema 변경 검토,
보완 사항 협의 및 확정
보완 사항 적용
Schema
변경 적용
Schema
변경 관리
최소 배포 2일 전에
검토 완료되어야 함
22.
22
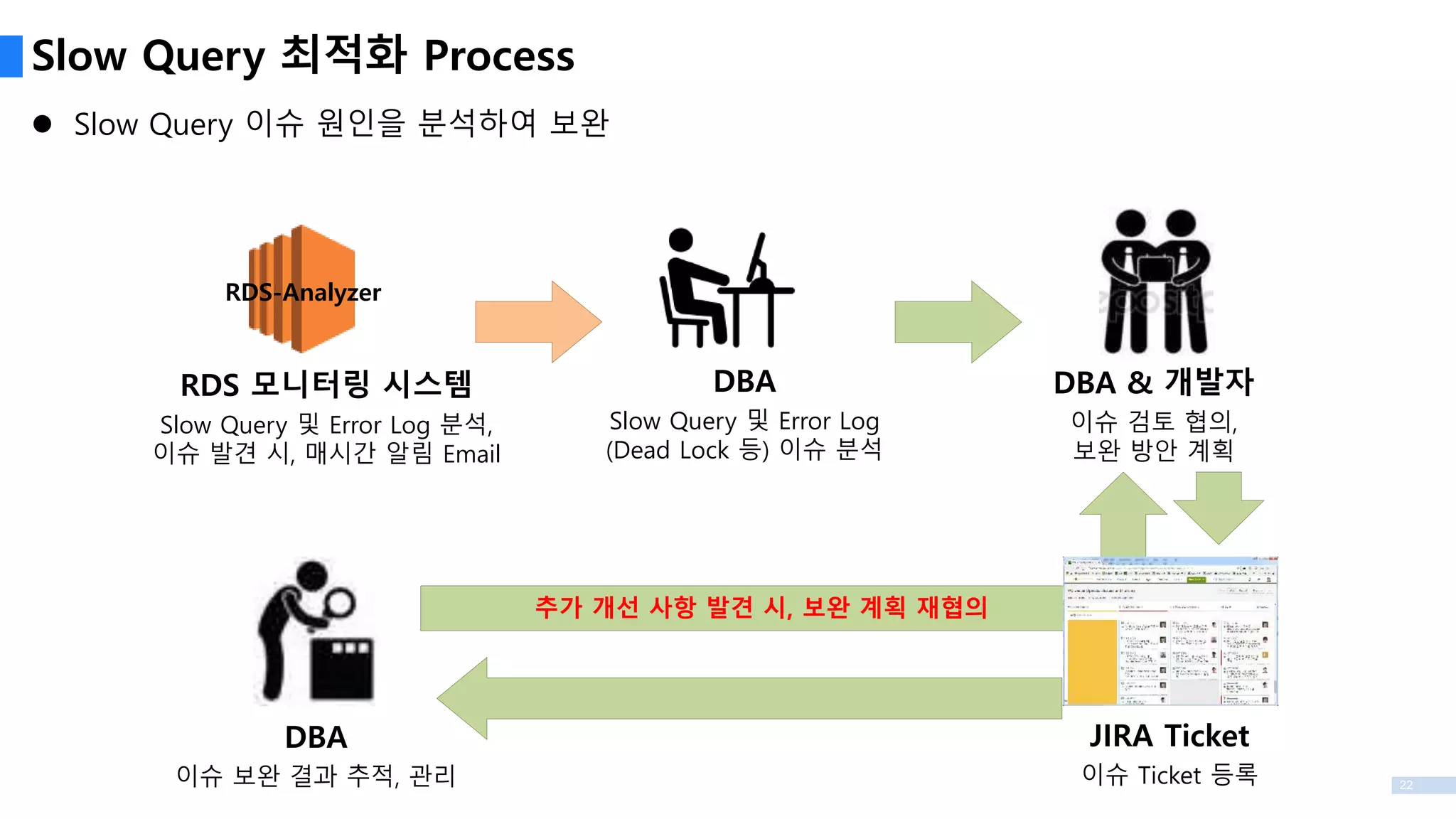
Slow Query 최적화Process
Slow Query 이슈 원인을 분석하여 보완
RDS 모니터링 시스템
Slow Query 및 Error Log 분석,
이슈 발견 시, 매시간 알림 Email
DBA
Slow Query 및 Error Log
(Dead Lock 등) 이슈 분석
DBA & 개발자
이슈 검토 협의,
보완 방안 계획
JIRA Ticket
이슈 Ticket 등록
DBA
이슈 보완 결과 추적, 관리
RDS-Analyzer
추가 개선 사항 발견 시, 보완 계획 재협의
23.
23
RDS 모니터링 시스템
Master
RDS-Analyze
RDS알림 Email 전송 시스템
Elasticsearch에서 1시간 전에 저장된
Data(Slowquery & Errorlog)를 가져온 후,
통계 분석 처리
통계 분석 결과와 Alarm Threshold 값 비교
조건을 충족하는 통계 자료에 대한
Alarm Email 정보 발송
Kibana4
(Slowquery, Errorlog, DBCP)
시간당, Slow Query 및 Error Log 수집
10초당, Process List 수집
수집 Data 가공 후, ES에 저장 Log Data 시각화
Elasticsearch
[Slow Query 정보]
Slow Query 수 및 Average / Max Query Time
Exanmined Row 총 합 및 Average / Max 수
[Error Log 정보]
Dead Lock 및 Aborted Connection 유형별 집계
Access Denided 정보 표시
[DBCP 정보]
계정 및 서버별, Active / Sleep Process List 정보
해당 정보는 계정별, 서버별로 통계가 표시되고 있으며,
최소 1초(DBCP 10초) 단위로 추적 가능함
24.
24
RDS 보안 시스템
Tadpole
Bastion
RDS
WAS
Batch
Message
Push
Application
Database
작업자
TadpoleAudit
mysql Console
접근 차단
KMS
[Database Audit]
Tedpole을 통해서만 Database 접근 가능
mysql Console은 원천적으로 차단시킴
Tedpole을 이용하여 모든 사용자 Log 관리
일반 사용자는 Select Query만 가능하며,
DML 권한은 DBA에게만 허용됨
DB 접근 계정은 일반 사용자, 운영 사용자,
DB 관리자, DBA 및 파트장으로 구분됨
[Data 보안]
KMS를 통하여 Data 암호화 보안 Key를
발급 받아 처리하고 있음
중요 Data에 대해 암호화시킴
1급 : 사용자 및 시스템 암호
2급 : 전화번호 및 Email 등 사용자 정보
3급 : 기타
KMS에서 보안 Key 발급
발급된 보안 Key로
중요 Data 암호화
25.
25
NoSQL(DynamoDB) 사용 현황
서비스 첫 해, 가입자 1천만명을 모집하면서 Database 부하 및 Storage 사용량이 급증하였고,
RDS 운영 비용도 크게 증가하였음
RDS 부하 분산 방안
향후 계획
File Data(670MB, 12억건) 처리를 위해 Couchbase 도입을 검토하였으나, 성능 및 AWS RDS 운영 비용과
비교하여 큰 이점이 없었음
향후 AWS Aurora를 사용하는 것이 최적의 대안이 될 것으로 판단하고 있음
• Data 이전 : Event 및 Read Position 등, 750MB, 20억건 이상
• 신규 Data 추가 : 총 15개 신규 테이블 NoSQL에 추가 구성
Query 복잡도가 낮은
Log성 Data, NoSQL 이전
26.
26
서비스 무중단 DatabaseSchema 변경 및 Data Migration
Trigger 기반 Solution은 Data 1억건이 초과할 경우, 거의 사용할 수 없음
Replication은 Index 변경, Column 추가 등, 단순 DB Schema 변경만 지원 가능
복제 후, Master RDS에 Multi-AZ을 설정하면, Storage 복제로 인한 심각한
Read/Write 성능 저하가 (7시간 이상) 발생함
AWS DMS 기능으로 성능 저하 방지 및 보다 복잡한 DB Schema 변경 (수평 및
수직 Partitioning) 작업도 가능하나, 아래 몇가지 주의 사항이 있음
Slave에서 복제 시, Data 누락 및 longtext의 복제 시간을 예측하기 어려움
대용량 Data 복제 시, Disk 공간의 확보가 필요함(24시간 Binary Log 유지)
서비스 무중단 DB Schema 변경 및 Data Migration 진행
초기(2014년)
최근(2016년)
향후 방안
28
진행한 사항
AWS 전체 리소스에 대한 자산 현황 파악
AWS Key Management System 활용한 DB 암호화 Key 관리
AWS CloudTrail을 통한 AWS Web Console에 접근 로그 관리
AWS IAM(user, role등)를 통한 AWS Resource에 대한 접근 제어 처리
각종 로그 보안 관리
리눅스 접근 보안 로그 관리
해야할 사항
지속적으로 변화하는 각종 계정 관리
리눅스 시스템에 대한 계정 관리(LAP, Active Directory 연동)
RDS(MySql)에 대한 로깅
ISO27001
30
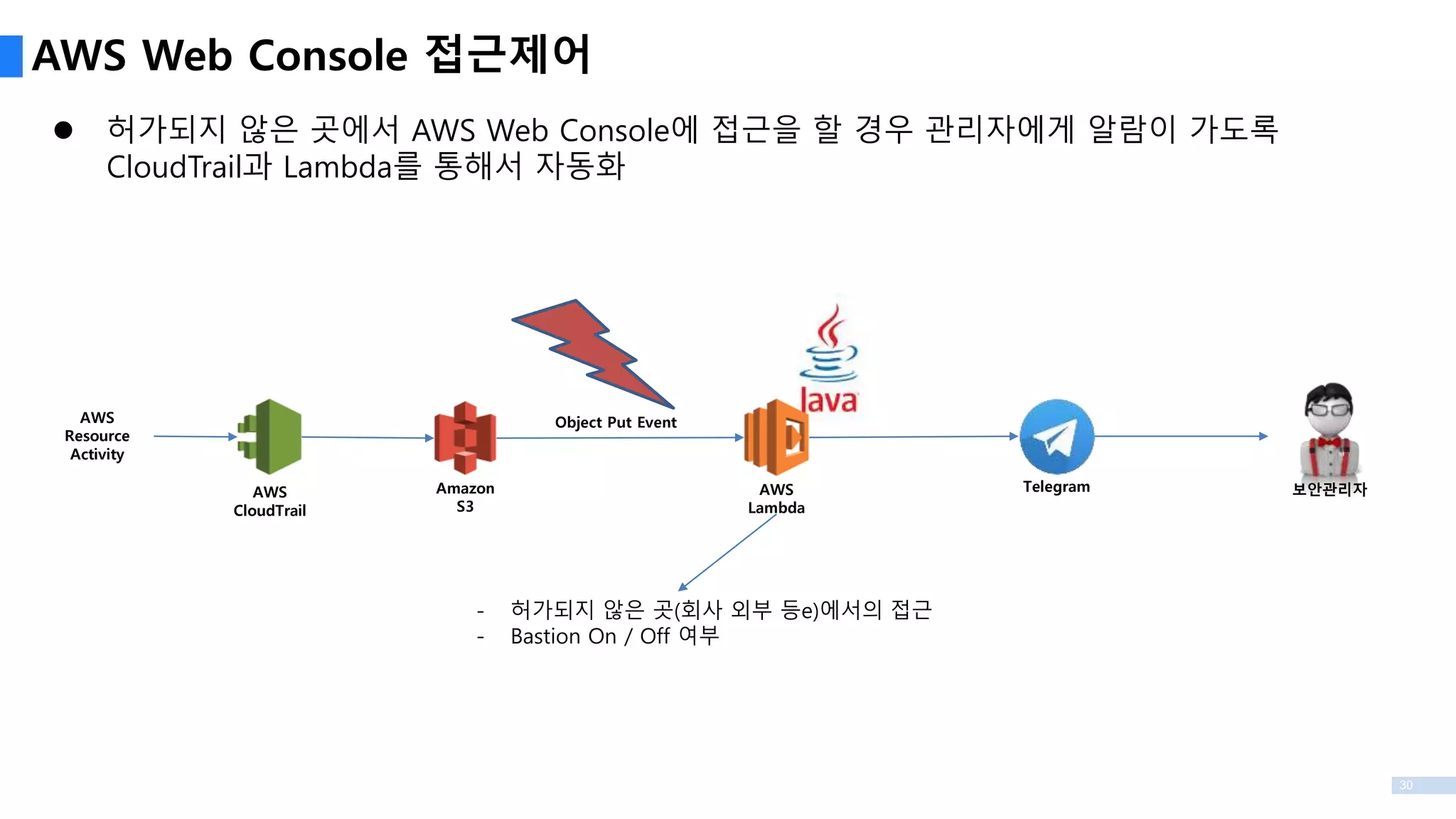
허가되지 않은곳에서 AWS Web Console에 접근을 할 경우 관리자에게 알람이 가도록
CloudTrail과 Lambda를 통해서 자동화
AWS Web Console 접근제어
AWS
CloudTrail
Amazon
S3
AWS
Lambda
AWS
Resource
Activity
Object Put Event
Telegram 보안관리자
- 허가되지 않은 곳(회사 외부 등e)에서의 접근
- Bastion On / Off 여부
31.
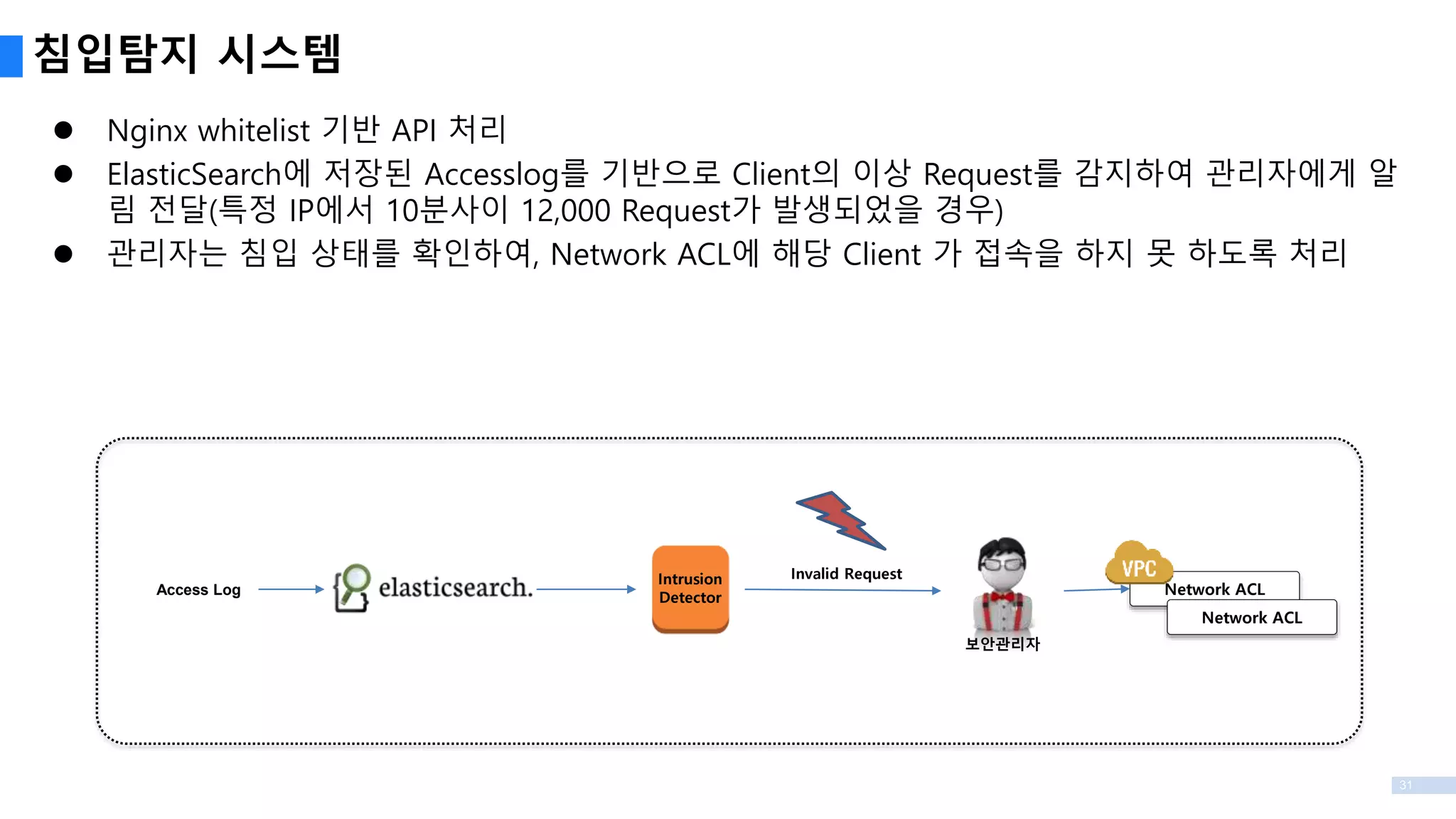
31
Nginx whitelist기반 API 처리
ElasticSearch에 저장된 Accesslog를 기반으로 Client의 이상 Request를 감지하여 관리자에게 알
림 전달(특정 IP에서 10분사이 12,000 Request가 발생되었을 경우)
관리자는 침입 상태를 확인하여, Network ACL에 해당 Client 가 접속을 하지 못 하도록 처리
침입탐지 시스템
Intrusion
Detector
Access Log
보안관리자
Network ACL
Network ACL
Invalid Request
32.
32
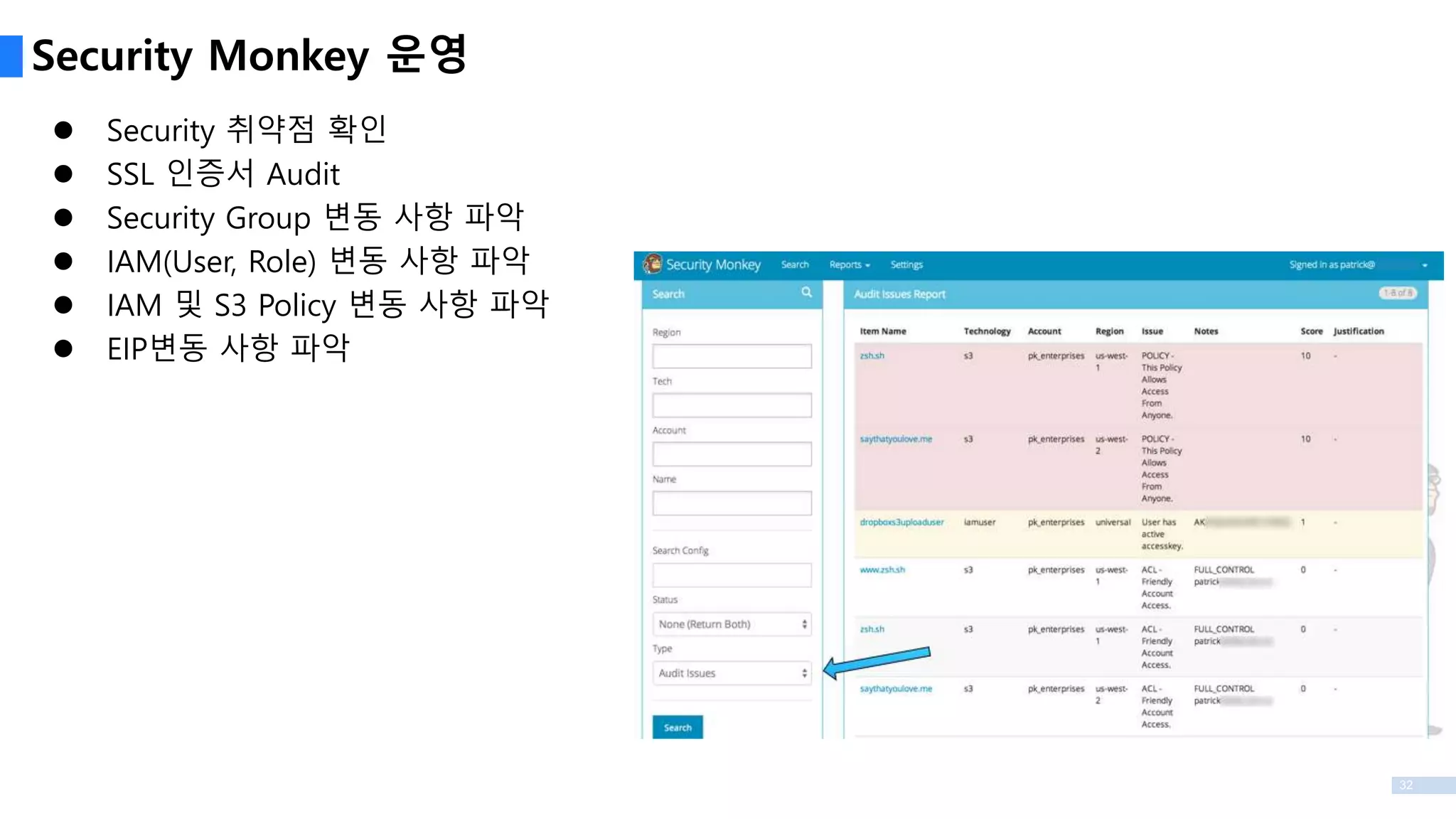
Security 취약점확인
SSL 인증서 Audit
Security Group 변동 사항 파악
IAM(User, Role) 변동 사항 파악
IAM 및 S3 Policy 변동 사항 파악
EIP변동 사항 파악
Security Monkey 운영
34
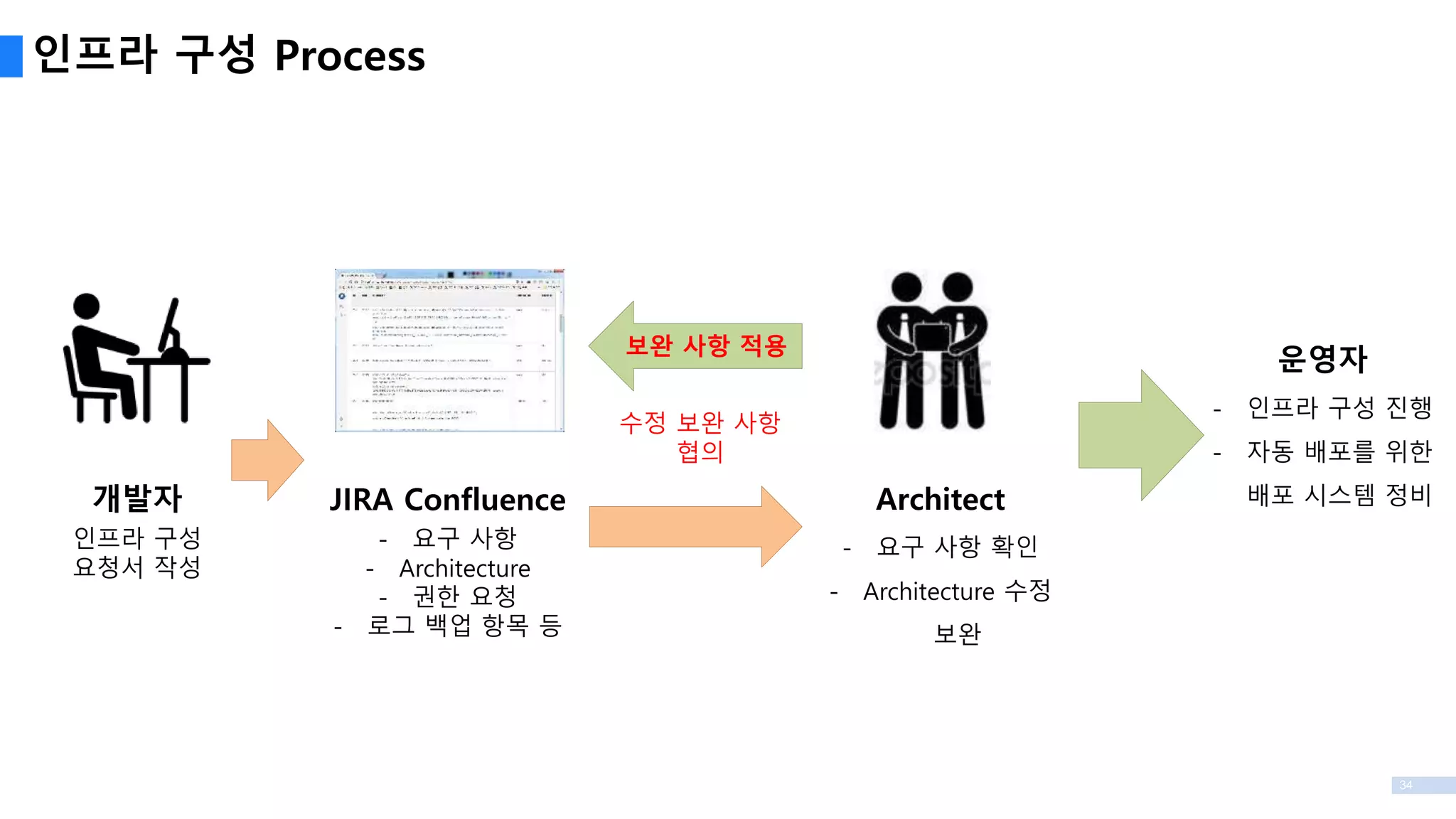
인프라 구성 Process
개발자
인프라구성
요청서 작성
JIRA Confluence
- 요구 사항
- Architecture
- 권한 요청
- 로그 백업 항목 등
Architect
- 요구 사항 확인
- Architecture 수정
보완
보완 사항 적용
수정 보완 사항
협의
운영자
- 인프라 구성 진행
- 자동 배포를 위한
배포 시스템 정비
35.
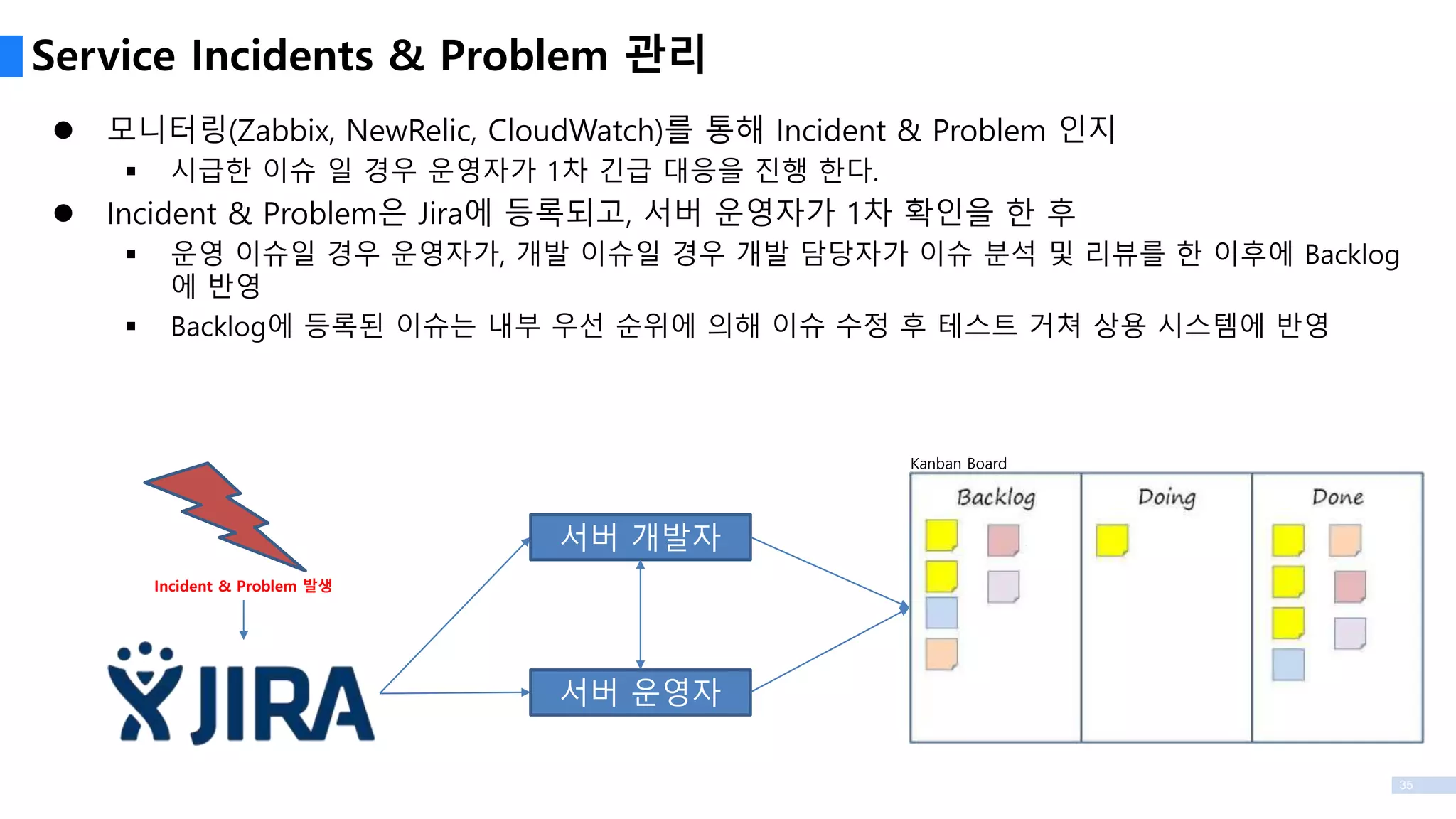
35
모니터링(Zabbix, NewRelic,CloudWatch)를 통해 Incident & Problem 인지
시급한 이슈 일 경우 운영자가 1차 긴급 대응을 진행 한다.
Incident & Problem은 Jira에 등록되고, 서버 운영자가 1차 확인을 한 후
운영 이슈일 경우 운영자가, 개발 이슈일 경우 개발 담당자가 이슈 분석 및 리뷰를 한 이후에 Backlog
에 반영
Backlog에 등록된 이슈는 내부 우선 순위에 의해 이슈 수정 후 테스트 거쳐 상용 시스템에 반영
Service Incidents & Problem 관리
Incident & Problem 발생
서버 운영자
서버 개발자
Kanban Board
46
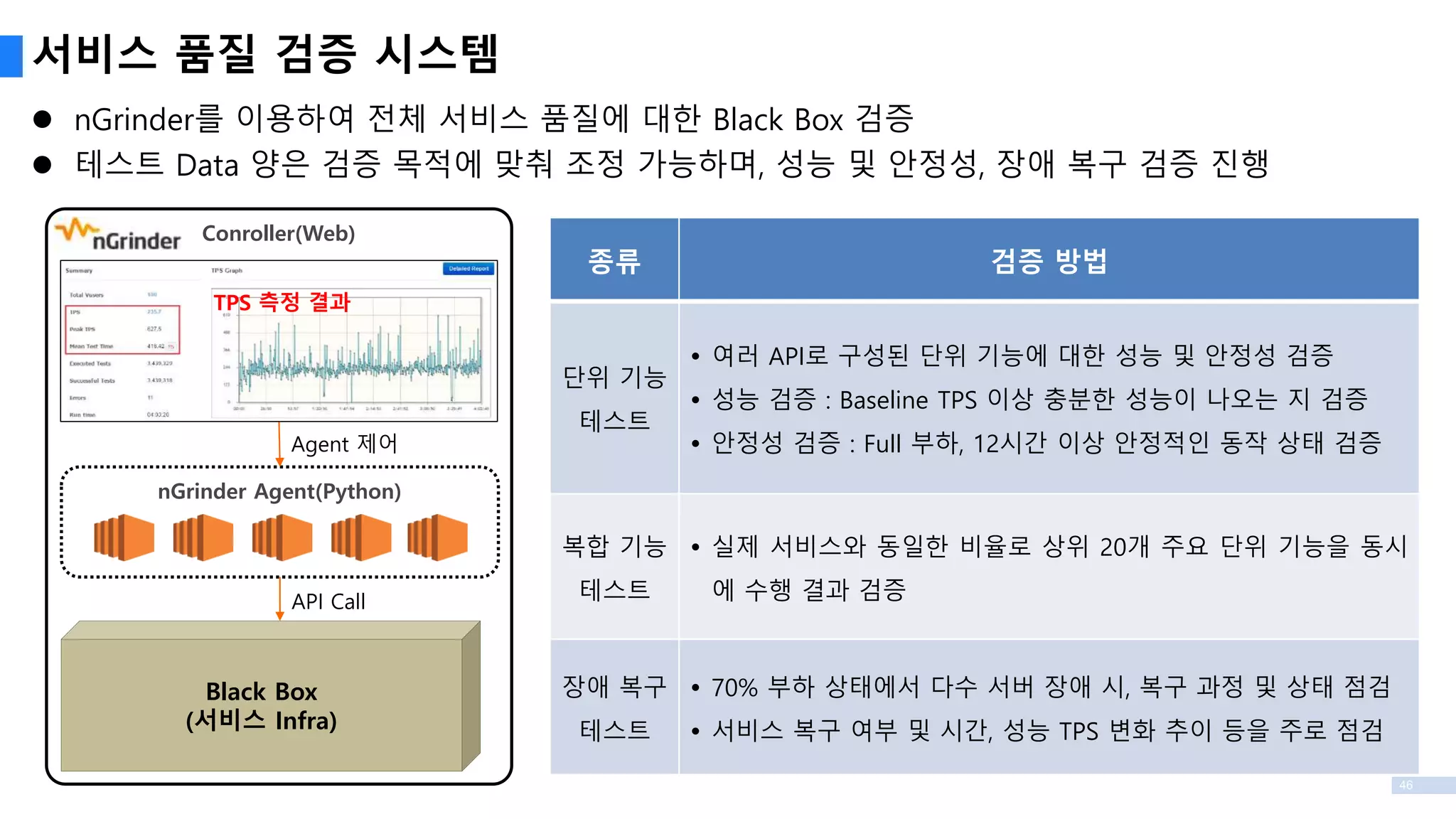
서비스 품질 검증시스템
nGrinder를 이용하여 전체 서비스 품질에 대한 Black Box 검증
테스트 Data 양은 검증 목적에 맞춰 조정 가능하며, 성능 및 안정성, 장애 복구 검증 진행
nGrinder Agent(Python)
Black Box
(서비스 Infra)
Conroller(Web)
API Call
TPS 측정 결과
Agent 제어
종류 검증 방법
단위 기능
테스트
여러 API로 구성된 단위 기능에 대한 성능 및 안정성 검증
성능 검증 : Baseline TPS 이상 충분한 성능이 나오는 지 검증
안정성 검증 : Full 부하, 12시간 이상 안정적인 동작 상태 검증
복합 기능
테스트
실제 서비스와 동일한 비율로 상위 20개 주요 단위 기능을 동시
에 수행 결과 검증
장애 복구
테스트
70% 부하 상태에서 다수 서버 장애 시, 복구 과정 및 상태 점검
서비스 복구 여부 및 시간, 성능 TPS 변화 추이 등을 주로 점검






![20
RDS 운영 현황
MAZ
Master
(active)
Master
(standby)
Replica-1
Replica-2
WAS
Update
Batch
EMR
Application
Availability Zone
California Region
Oregon Region
[Master]
db.r3.4xlarge : 16 vCore / 122GB
Storage : 3TB / 1,2000 IOPs
메인 서비스 및 Multi-AZ 구성
[Replica-1 / Replica-2]
db.m4.2xlarge : 8 vCore / 32GB
Storage : 3TB / 9,000 IOPs
용도 : Data Dump 및 Disaster Recovery
Disaster Recovery Replica-2는 Oregon에
구성되어 있으며, Batch Job 등, 비 실시간
서비스에서 주로 사용하고 있음
[Database 사용 현황]
Storage 현황 : 1.95 TB(Index 비율 : 37%)
CPU 현황 : 45%
IOPs 현황 : 6,000 IOPs
[주요 Table 현황]
Table 1 : Rows(21억), Data(626 GB)
Table 2 : Rows(12억), Data(671 GB)](https://image.slidesharecdn.com/bvjlqqjkqakjjdt1s5jx-signature-cf1b0f3d1d57e0a91c1e8dda4b98ce450e8d30537b49d0d13f2c2791d419e17a-poli-170306062442/75/slide-20-2048.jpg)
![23
RDS 모니터링 시스템
Master
RDS-Analyze
RDS 알림 Email 전송 시스템
Elasticsearch에서 1시간 전에 저장된
Data(Slowquery & Errorlog)를 가져온 후,
통계 분석 처리
통계 분석 결과와 Alarm Threshold 값 비교
조건을 충족하는 통계 자료에 대한
Alarm Email 정보 발송
Kibana4
(Slowquery, Errorlog, DBCP)
시간당, Slow Query 및 Error Log 수집
10초당, Process List 수집
수집 Data 가공 후, ES에 저장 Log Data 시각화
Elasticsearch
[Slow Query 정보]
Slow Query 수 및 Average / Max Query Time
Exanmined Row 총 합 및 Average / Max 수
[Error Log 정보]
Dead Lock 및 Aborted Connection 유형별 집계
Access Denided 정보 표시
[DBCP 정보]
계정 및 서버별, Active / Sleep Process List 정보
해당 정보는 계정별, 서버별로 통계가 표시되고 있으며,
최소 1초(DBCP 10초) 단위로 추적 가능함](https://image.slidesharecdn.com/bvjlqqjkqakjjdt1s5jx-signature-cf1b0f3d1d57e0a91c1e8dda4b98ce450e8d30537b49d0d13f2c2791d419e17a-poli-170306062442/75/slide-23-2048.jpg)
![24
RDS 보안 시스템
Tadpole
Bastion
RDS
WAS
Batch
Message
Push
Application
Database
작업자
Tadpole Audit
mysql Console
접근 차단
KMS
[Database Audit]
Tedpole을 통해서만 Database 접근 가능
mysql Console은 원천적으로 차단시킴
Tedpole을 이용하여 모든 사용자 Log 관리
일반 사용자는 Select Query만 가능하며,
DML 권한은 DBA에게만 허용됨
DB 접근 계정은 일반 사용자, 운영 사용자,
DB 관리자, DBA 및 파트장으로 구분됨
[Data 보안]
KMS를 통하여 Data 암호화 보안 Key를
발급 받아 처리하고 있음
중요 Data에 대해 암호화시킴
1급 : 사용자 및 시스템 암호
2급 : 전화번호 및 Email 등 사용자 정보
3급 : 기타
KMS에서 보안 Key 발급
발급된 보안 Key로
중요 Data 암호화](https://image.slidesharecdn.com/bvjlqqjkqakjjdt1s5jx-signature-cf1b0f3d1d57e0a91c1e8dda4b98ce450e8d30537b49d0d13f2c2791d419e17a-poli-170306062442/75/slide-24-2048.jpg)


































































![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Partner TechShift 2017] 클라우드 시대 기존 Legacy에서 벗어나는 방법](https://cdn.slidesharecdn.com/ss_thumbnails/6-171101053200-thumbnail.jpg?width=640&height=640&fit=bounds)





