Download as PDF, PPTX










![© 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved.
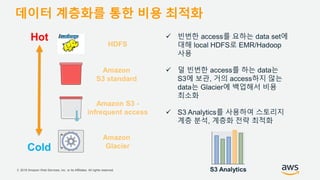
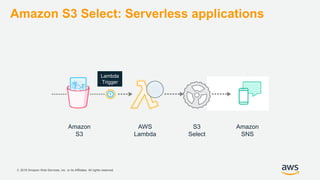
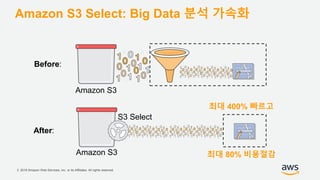
Amazon S3 Select: Serverless MapReduce
Before
200 seconds and 11.2 cents
# Download and process all keys
for key in src_keys:
response = s3_client.get_object(Bucket=src_bucket,
Key=key)
contents = response['Body'].read()
for line in contents.split('n')[:-1]:
line_count +=1
try:
data = line.split(',')
srcIp = data[0][:8]
….
After
95 seconds and costs 2.8 cents
# Select IP Address and Keys
for key in src_keys:
response = s3_client.select_object_content
(Bucket=src_bucket, Key=key, expression =
‘SELECT SUBSTR(obj._1, 1, 8), obj._2 FROM
s3object as obj’)
contents = response['Body'].read()
for line in contents:
line_count +=1
try:
….
1/5의 비용으로 2배 빠른 수행](https://image.slidesharecdn.com/buildingyourdatalakeonaws-jmmoon-181010090953/85/Data-Lake-AWS-26-320.jpg)



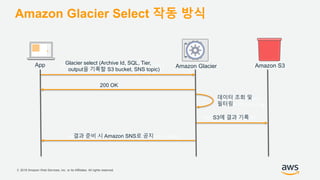

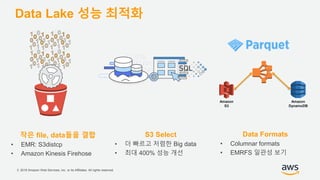

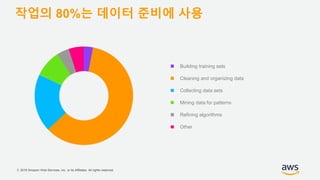

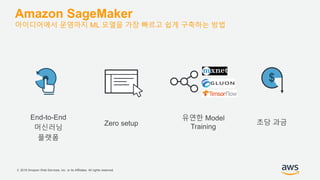

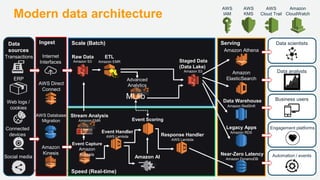
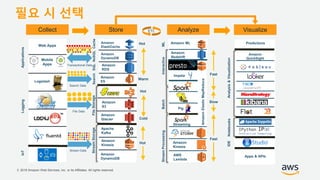
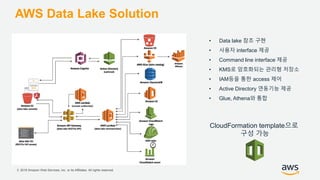



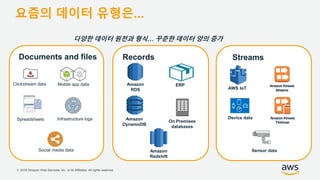
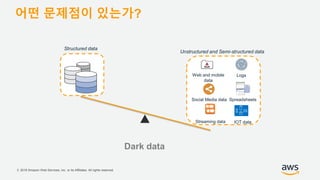
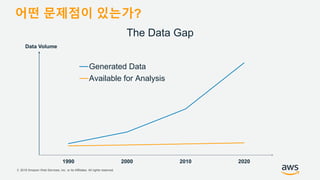
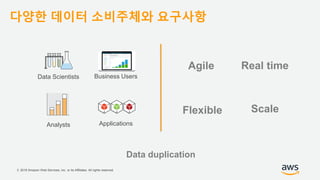
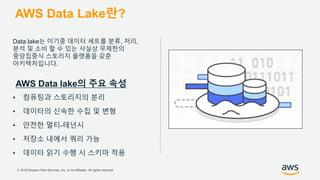
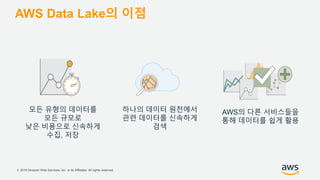
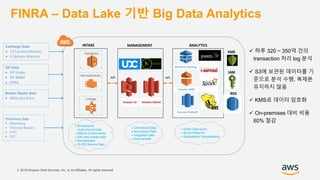
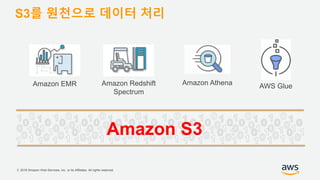
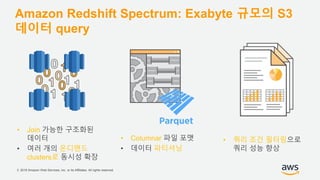
기업들은 데이터로부터 insight를 얻기 위해서 부단한 노력을 하고 있습니다. 이를 위해 조직의 데이터를 한 곳에 모아서 보관하는 Data Lake의 구축은 데이터 분석을 위한 중심으로 자리잡고 있습니다. 본 세션에서는 AWS에서 S3를 활용하여 민첩하고 비용효율적인 Data Lake를 구축하는 방법을 소개합니다. 또한 이를 기반으로 AWS의 다양한 데이터 분석 서비스와 연동하는 법을 살펴봅니다. 대상 : 빅 데이터 및 데이터 분석 담당자, AWS 기반 데이터 분석에 관심 있는 모든 분 발표자 : 문종민 솔루션즈 아키텍트, AWS







![[AWS Builders] AWS와 함께하는 클라우드 컴퓨팅](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudcomputingchoelkang-190305081301-thumbnail.jpg?width=640&height=640&fit=bounds)
![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)



