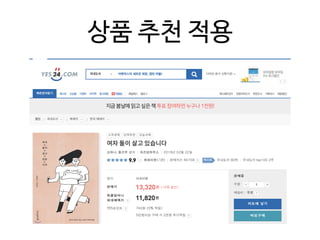
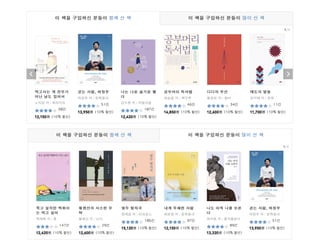
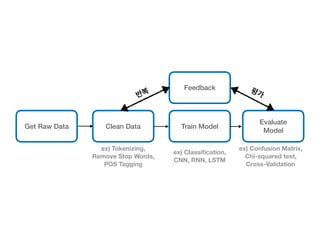
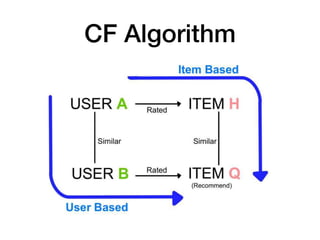
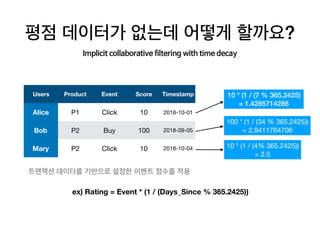
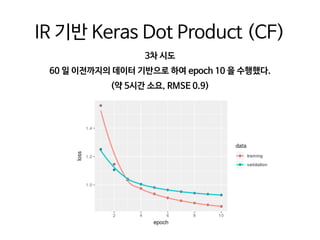
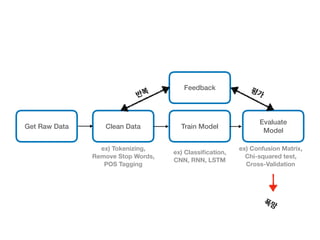
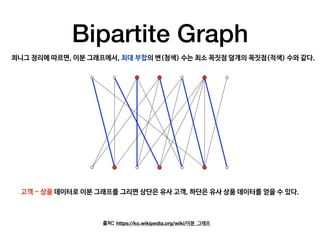
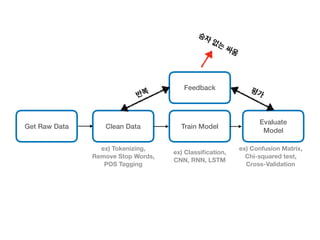
This document provides an overview of common steps in a machine learning workflow including getting raw data, cleaning data, training models, and evaluating models. It also includes examples of techniques used in each step such as tokenizing text, removing stop words, using neural networks like CNNs and RNNs for classification, and evaluating models with metrics like confusion matrices and cross-validation. Links are provided to external resources for further information.






























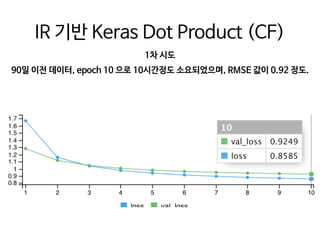
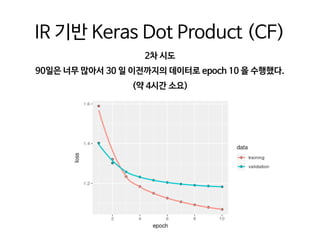
![from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import Row
ratings = spark.read.parquet('hdfs:///data/implicit-rating/2018-02-17')
(training, test) = ratings.randomSplit([0.8, 0.2])
als = ALS(maxIter=5, regParam=0.01, userCol="account_id", itemCol="product_id", ratingCol="rating",
coldStartStrategy="drop", implicitPrefs=True)
model = als.fit(training)
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("RMSE : " + str(rmse))
model.save(hdfs:///data/als/model/2018-02-19')
: https://github.com/jamenlong/ALS_expected_percent_rank_cv](https://image.slidesharecdn.com/awskrugjaecheolkim-190414132958/85/slide-44-320.jpg)







![Neo4J
(product1)<-[:hasProduct]-()-[:Bought]-(p2:Account)-[:Bought]-()-[:hasProduct]-
>(product2) WITH p1,p2, count(product1) as cnt, collect(product1) as SharedItems,
product2 WHERE not((p1)-[:Bought]-()-[:hasProduct]->(product2)) AND cnt > 2 RETURN
distinct product2 LIMIT 100](https://image.slidesharecdn.com/awskrugjaecheolkim-190414132958/85/slide-59-320.jpg)



















![[DevDay2019] Python Machine Learning with Jupyter Notebook - By Nguyen Huu Th...](https://cdn.slidesharecdn.com/ss_thumbnails/thongnguyen-devday2019pythonmlwithjupyternotebook-190408093340-thumbnail.jpg?width=640&height=640&fit=bounds)

































