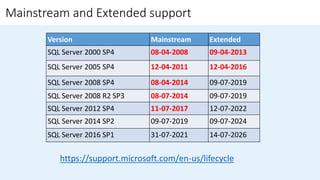
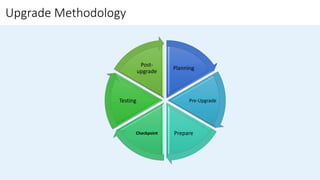
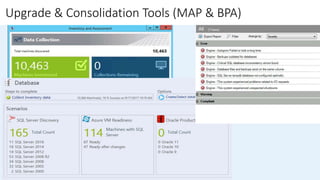
The document outlines the challenges organizations face in managing database infrastructure and emphasizes the importance of consolidation, which reduces the number of database servers to enhance efficiency and security. It details the benefits of consolidation, upgrade strategies for SQL Server, and the methodologies involved in planning and executing upgrades. Additionally, it highlights tools available for assessment and migration to ensure a smooth transition to newer SQL Server versions.