Download as PDF, PPTX






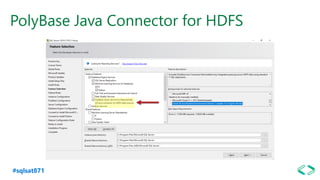

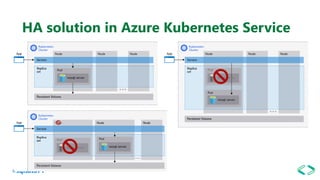
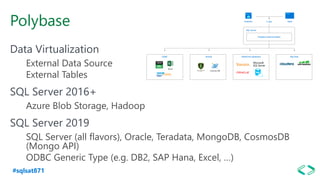
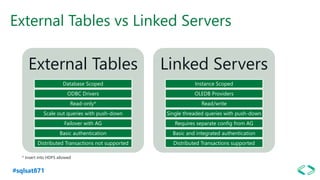
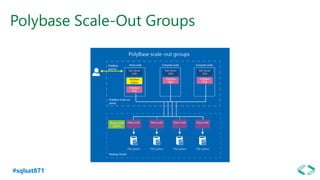
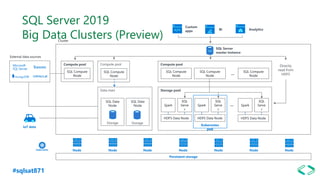










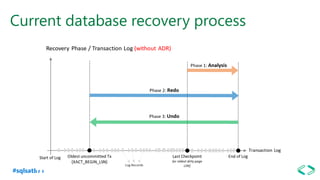
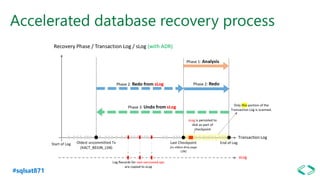



















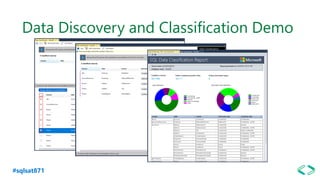






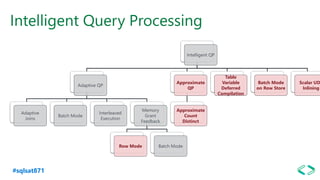







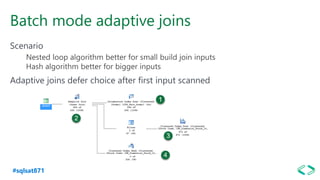

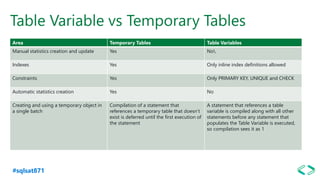











The document discusses SQL Server 2019 features and enhancements, highlighting key technical updates in areas such as installation, configuration, and performance tuning. It covers integration with Linux, the introduction of machine learning services, and improvements in data management, including enhanced availability groups and intelligent query processing. Additionally, it outlines functionalities related to security, compression, and extensibility, alongside new tools and services in the SQL Server ecosystem.










































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)








