Download as PDF, PPTX


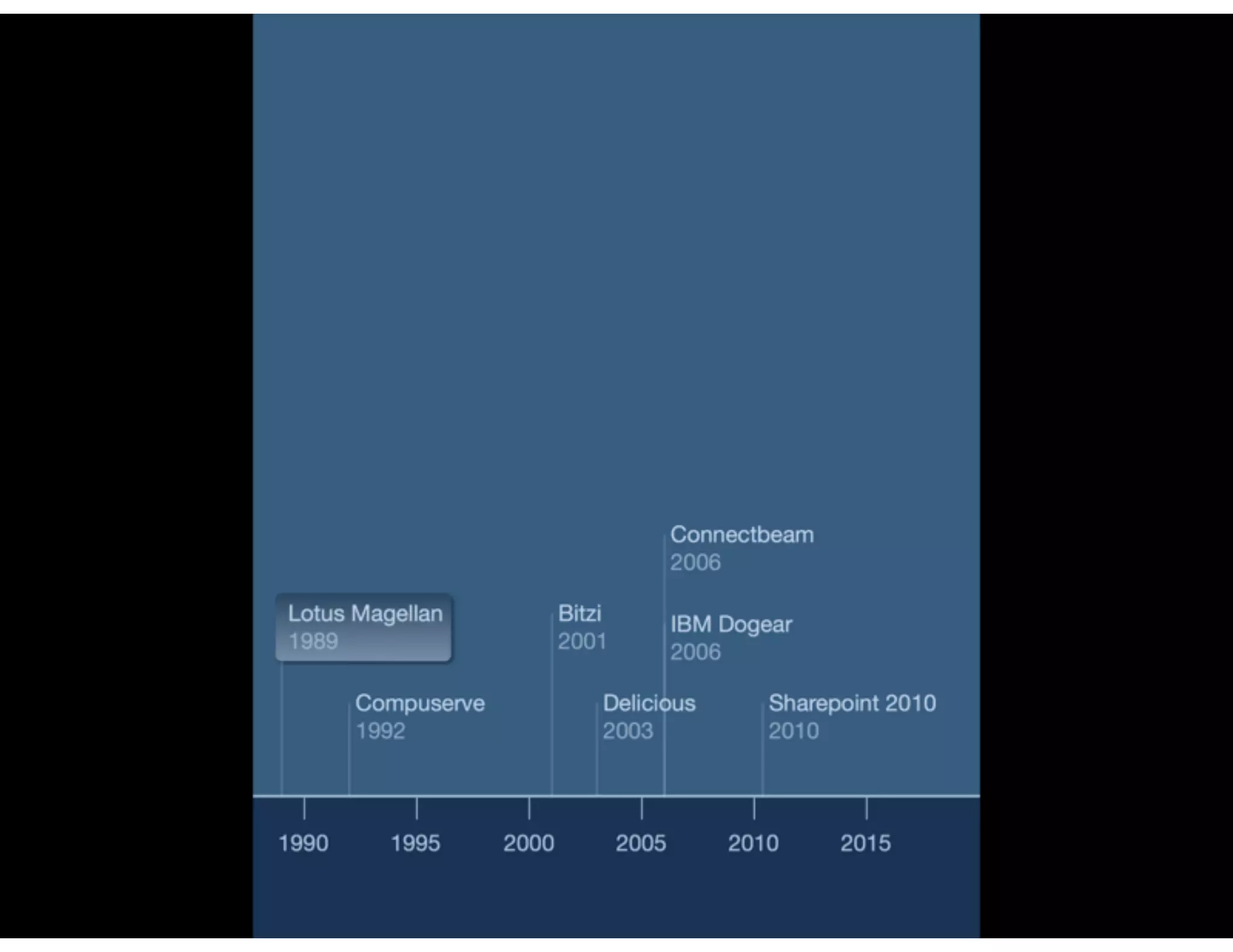

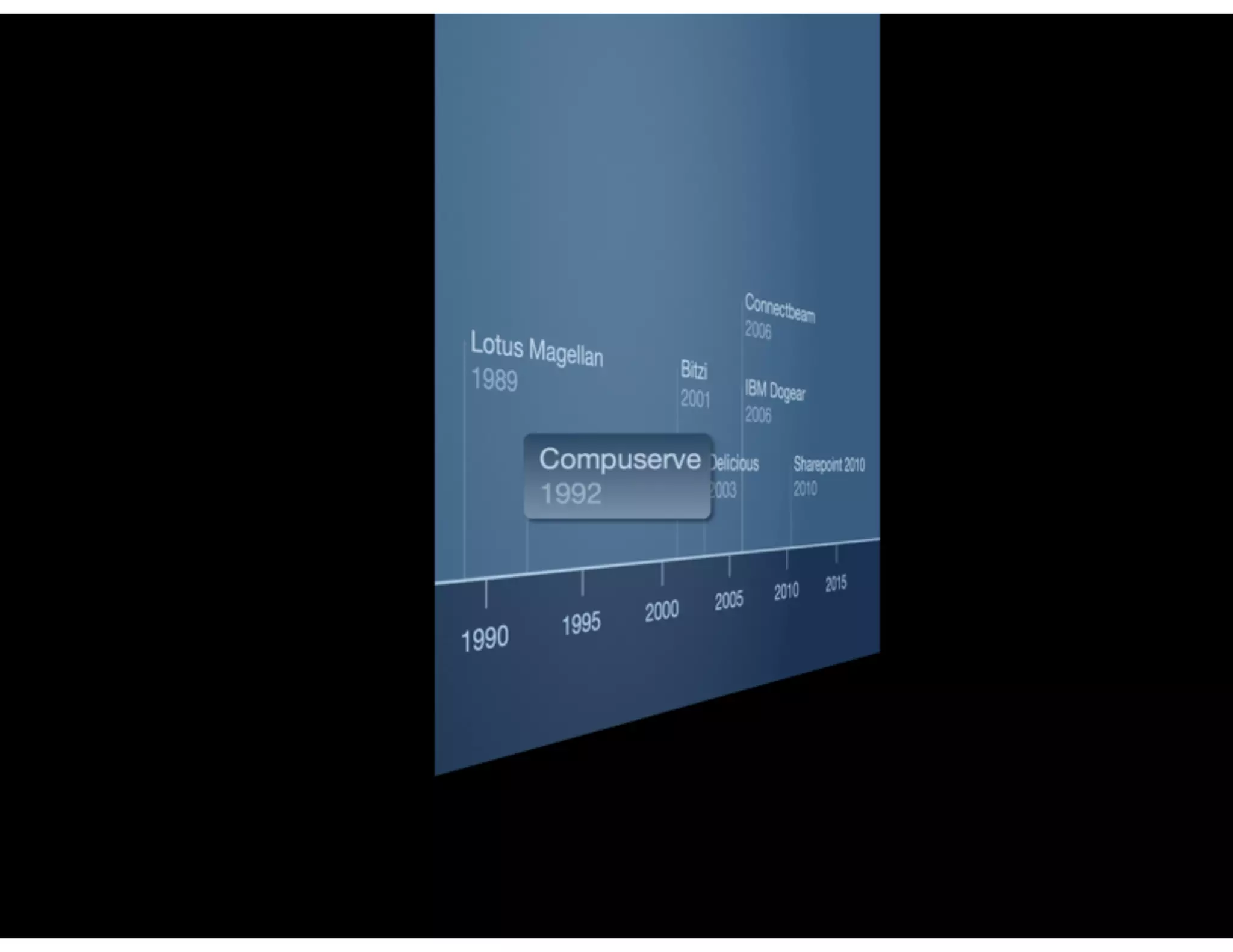




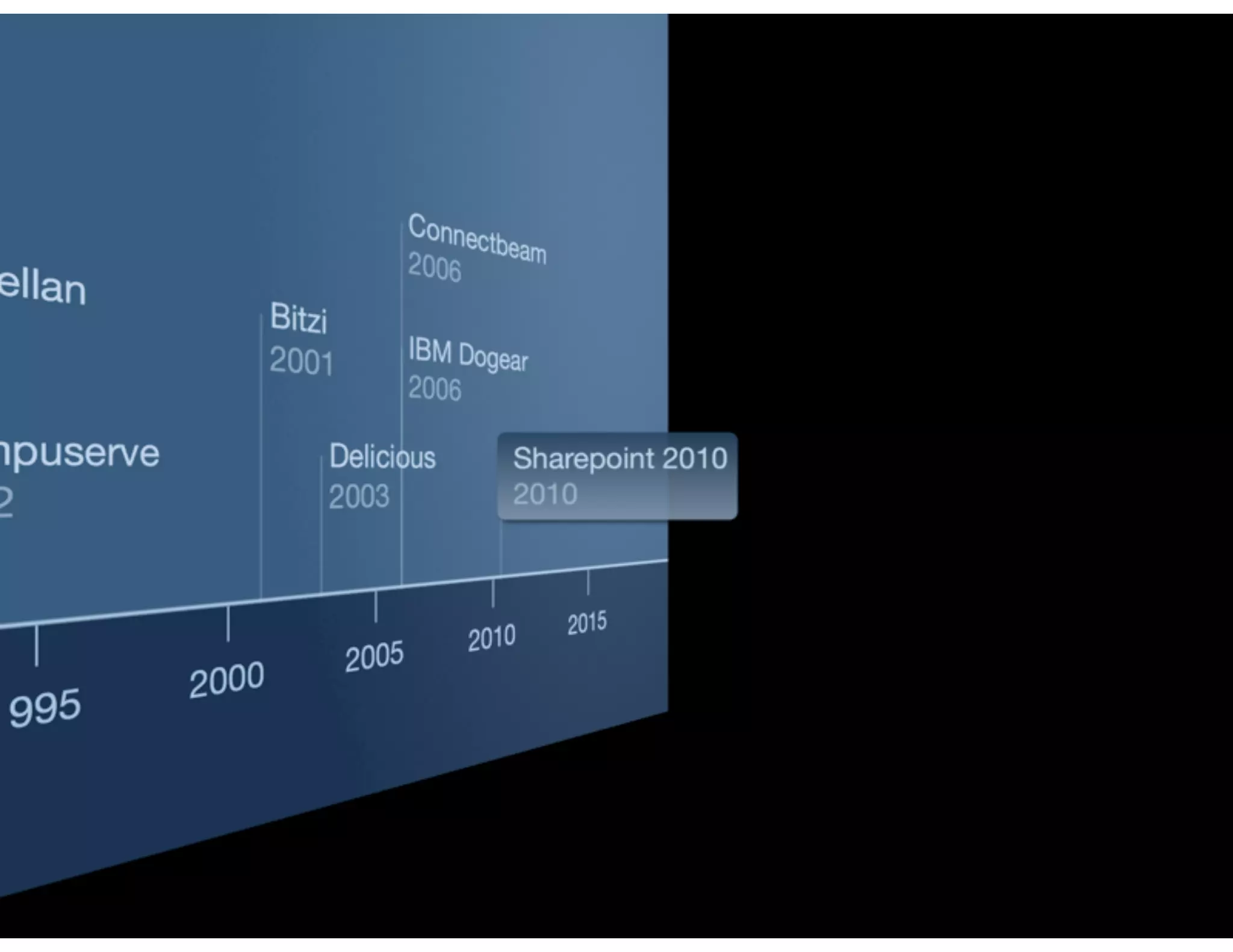
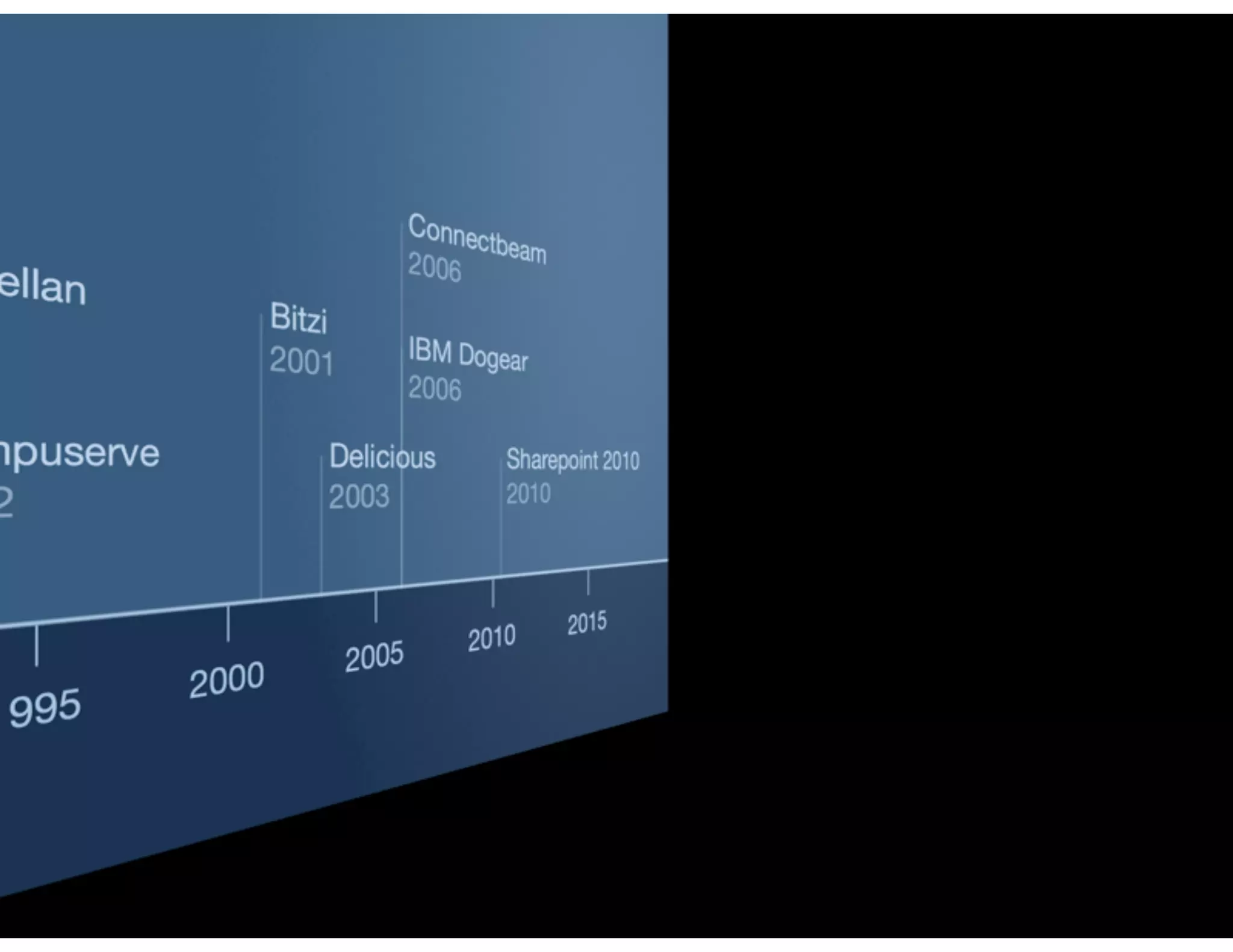
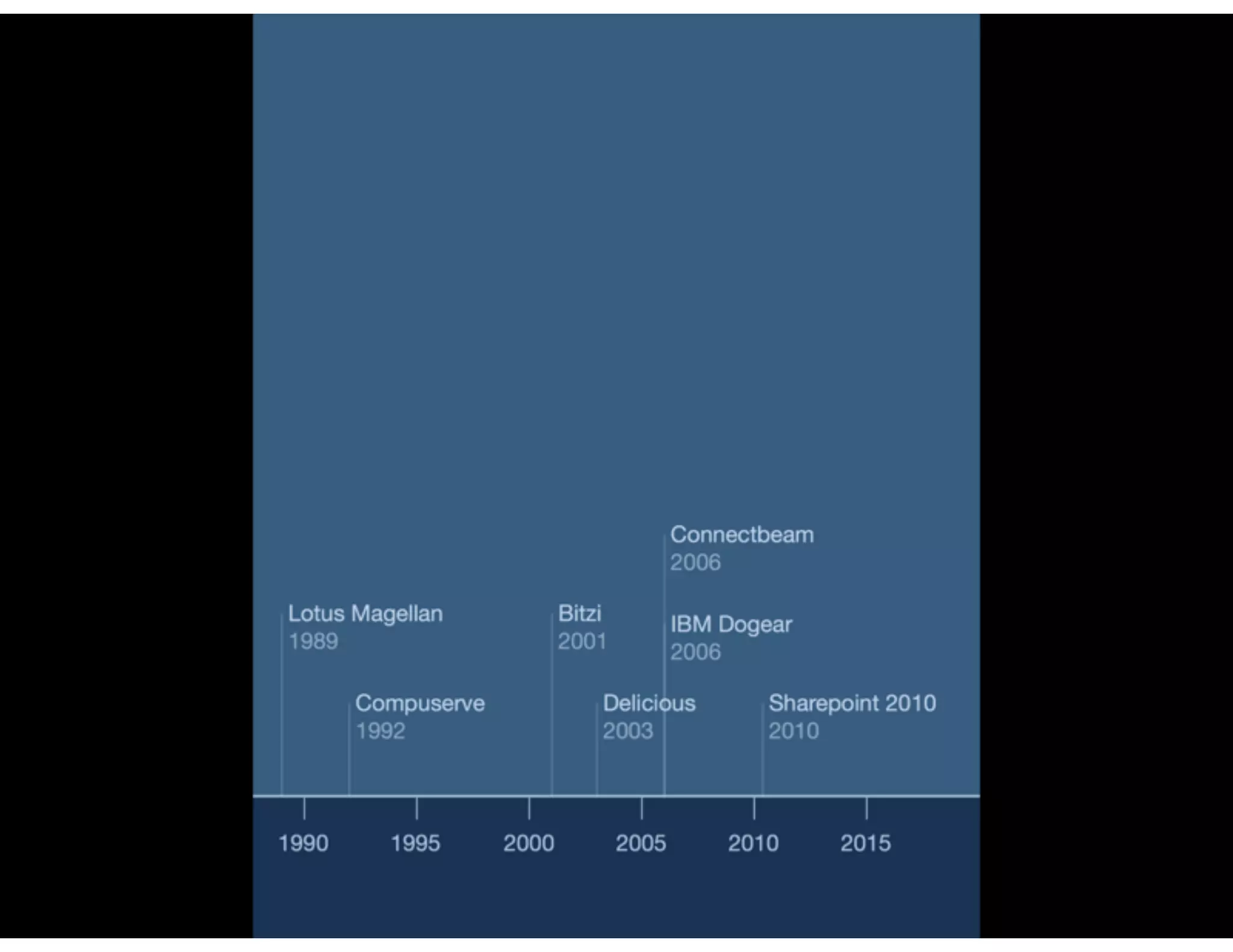





























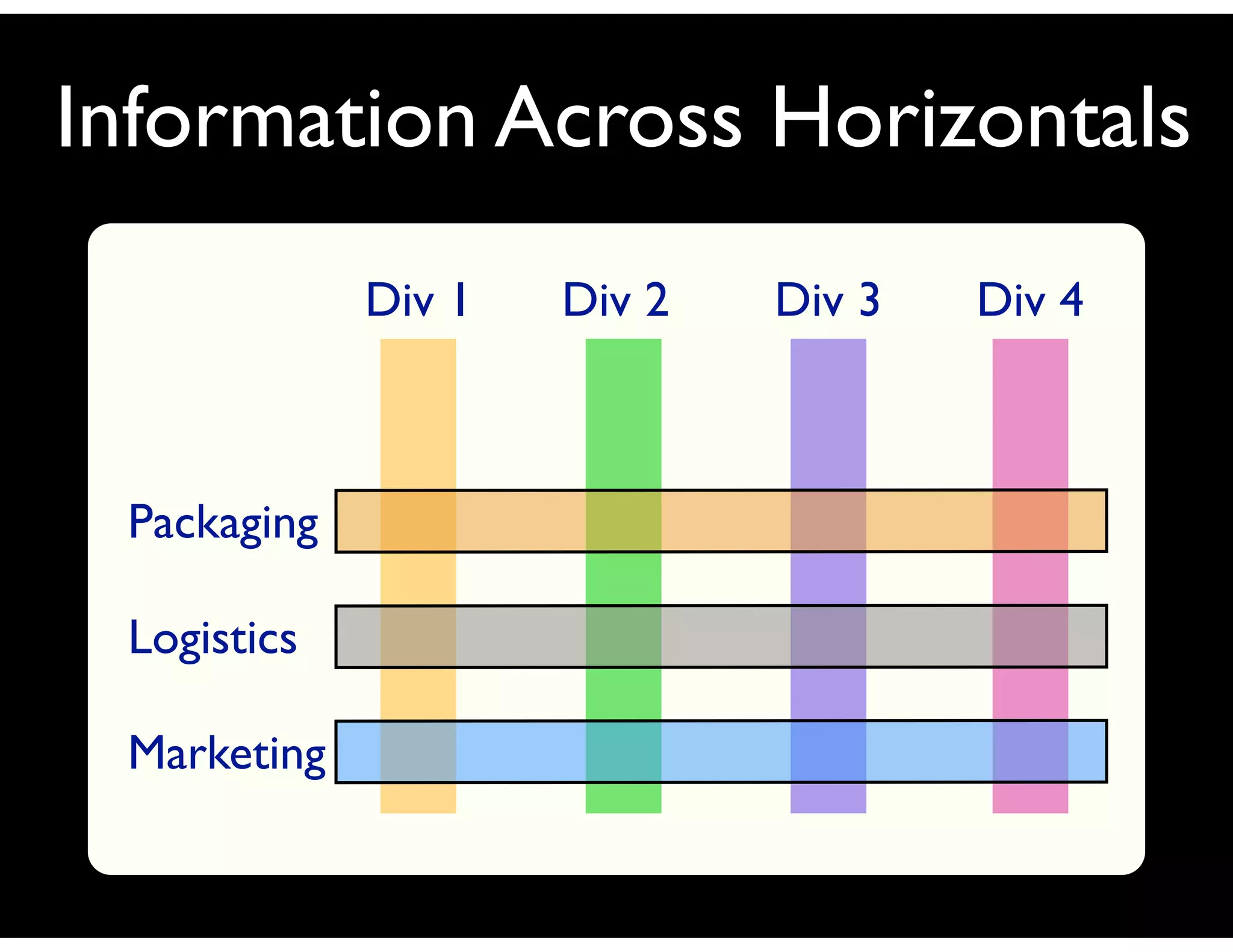











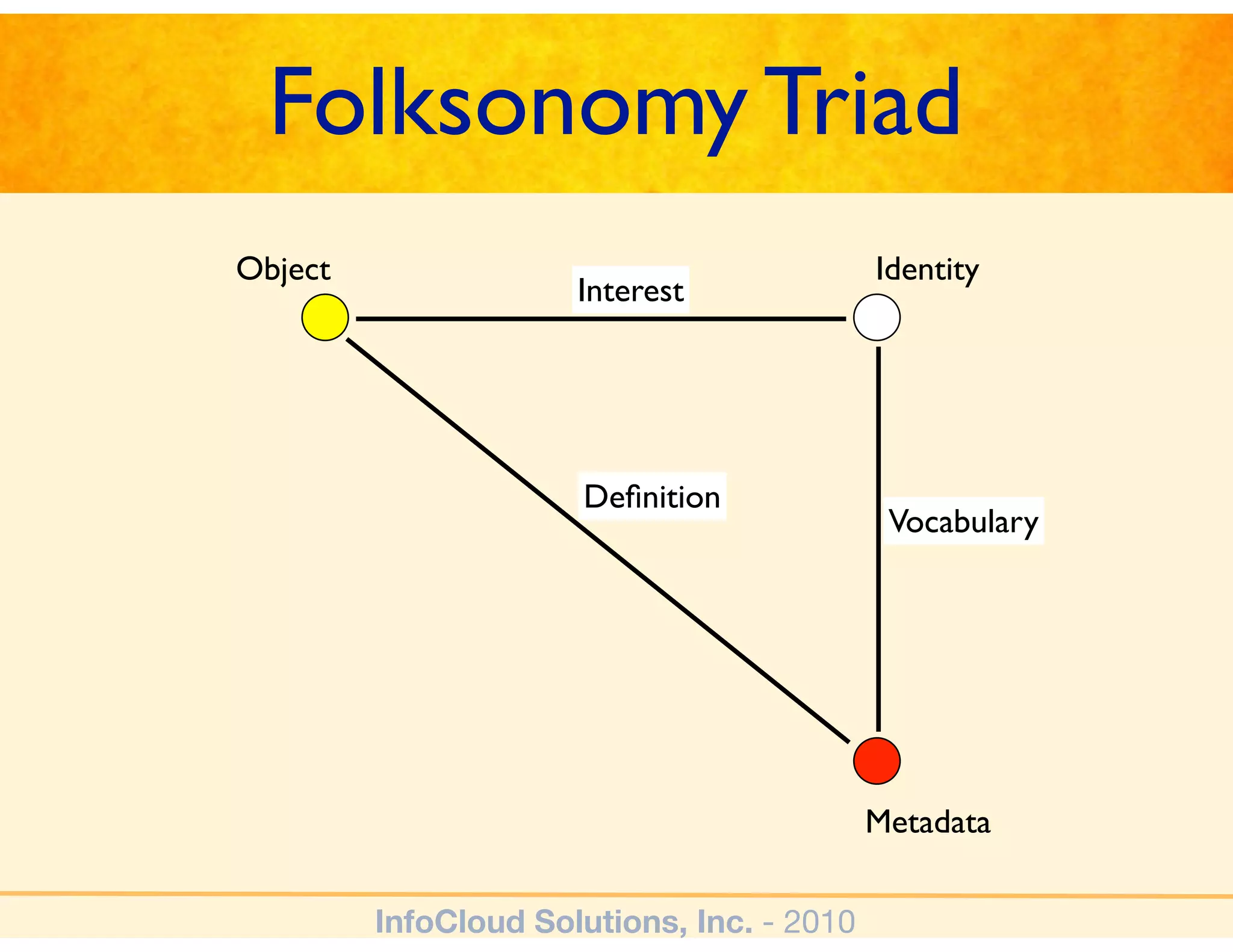
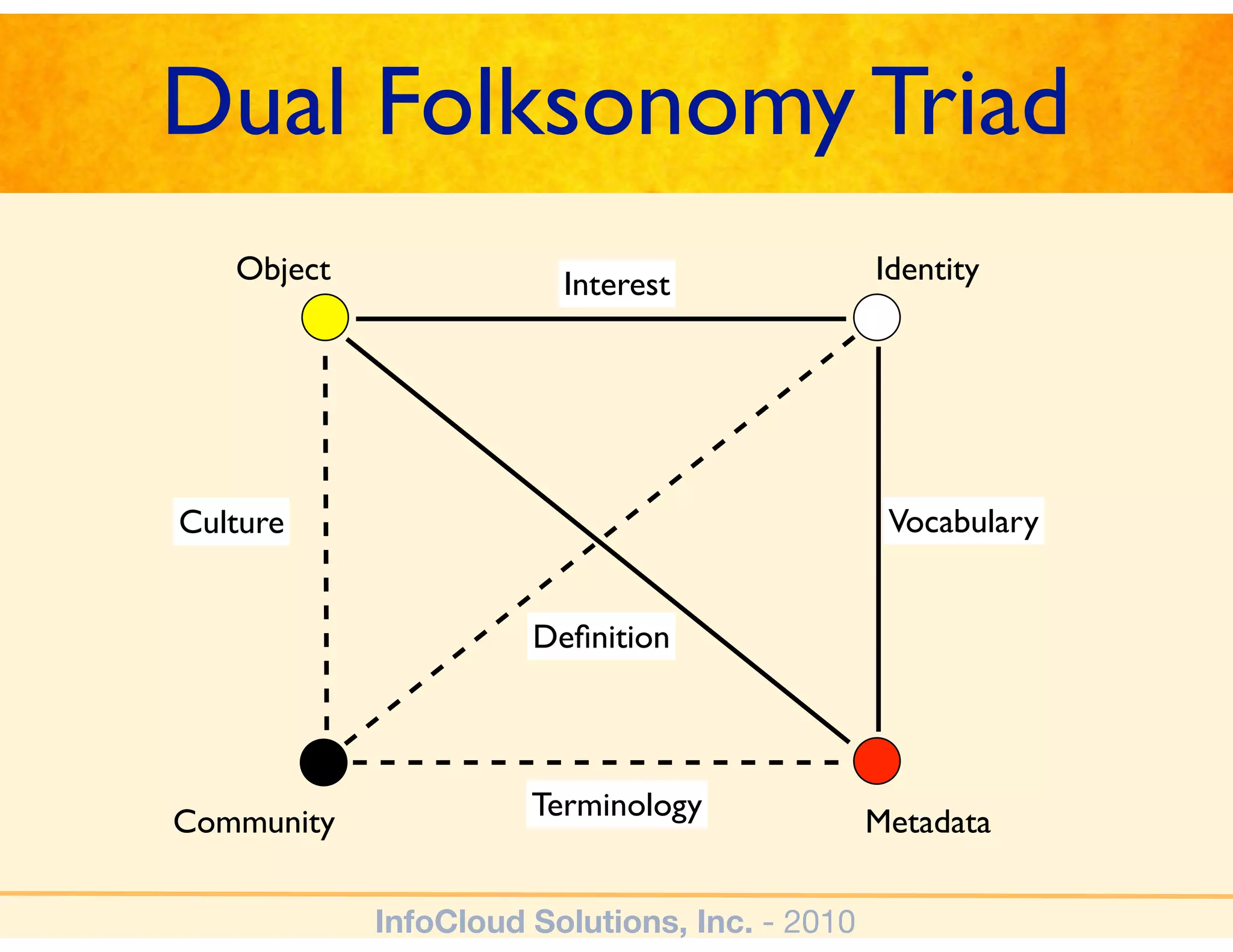
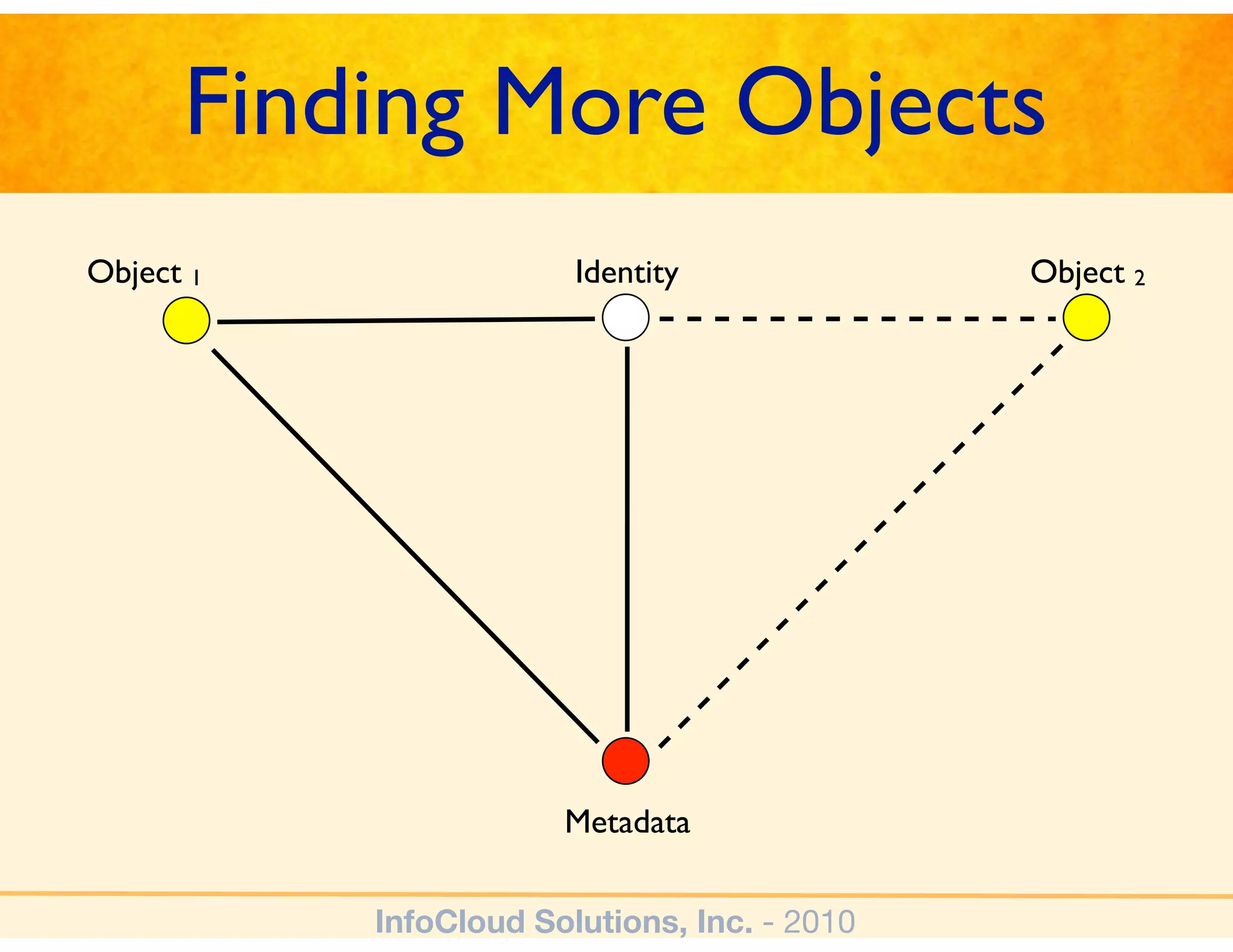
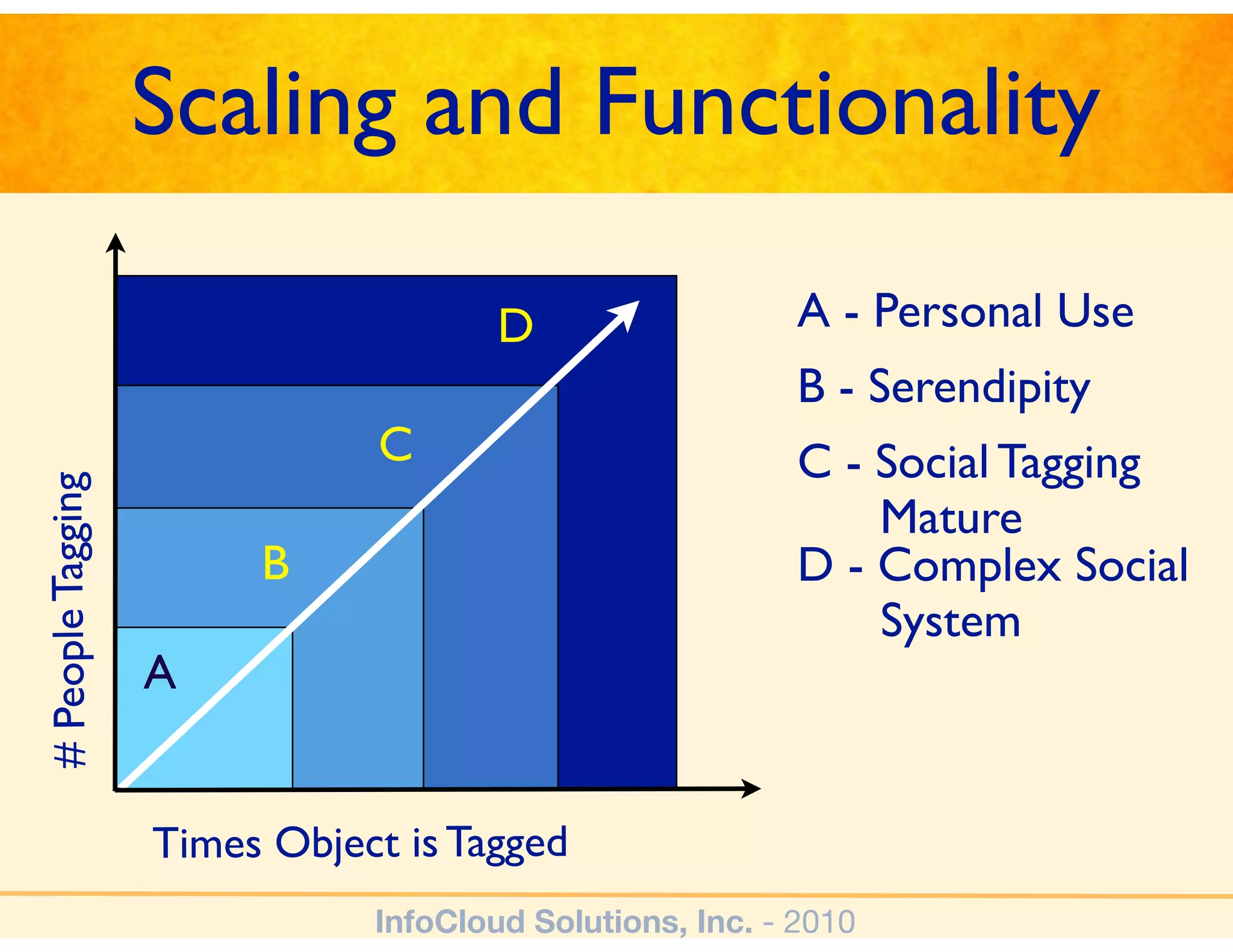
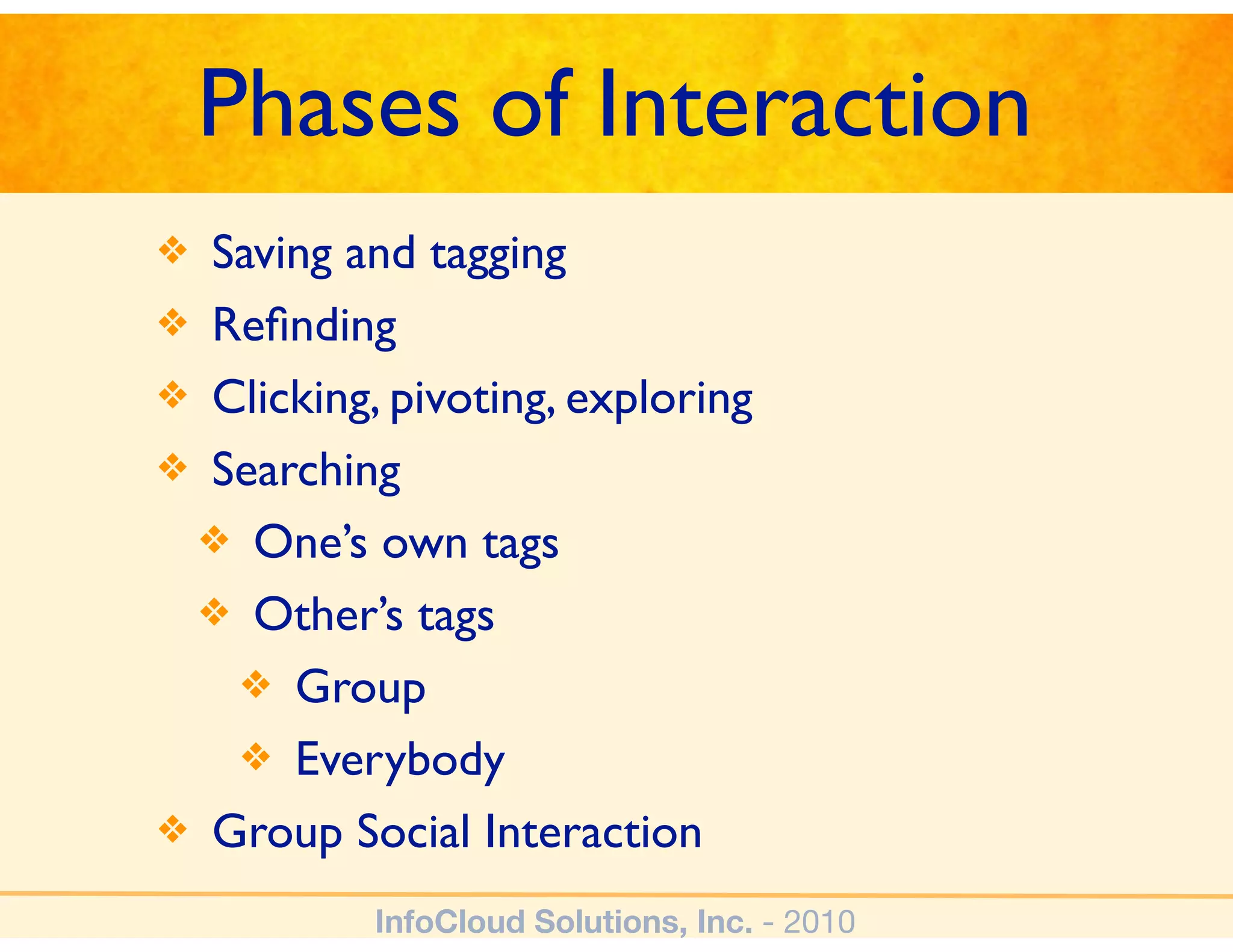
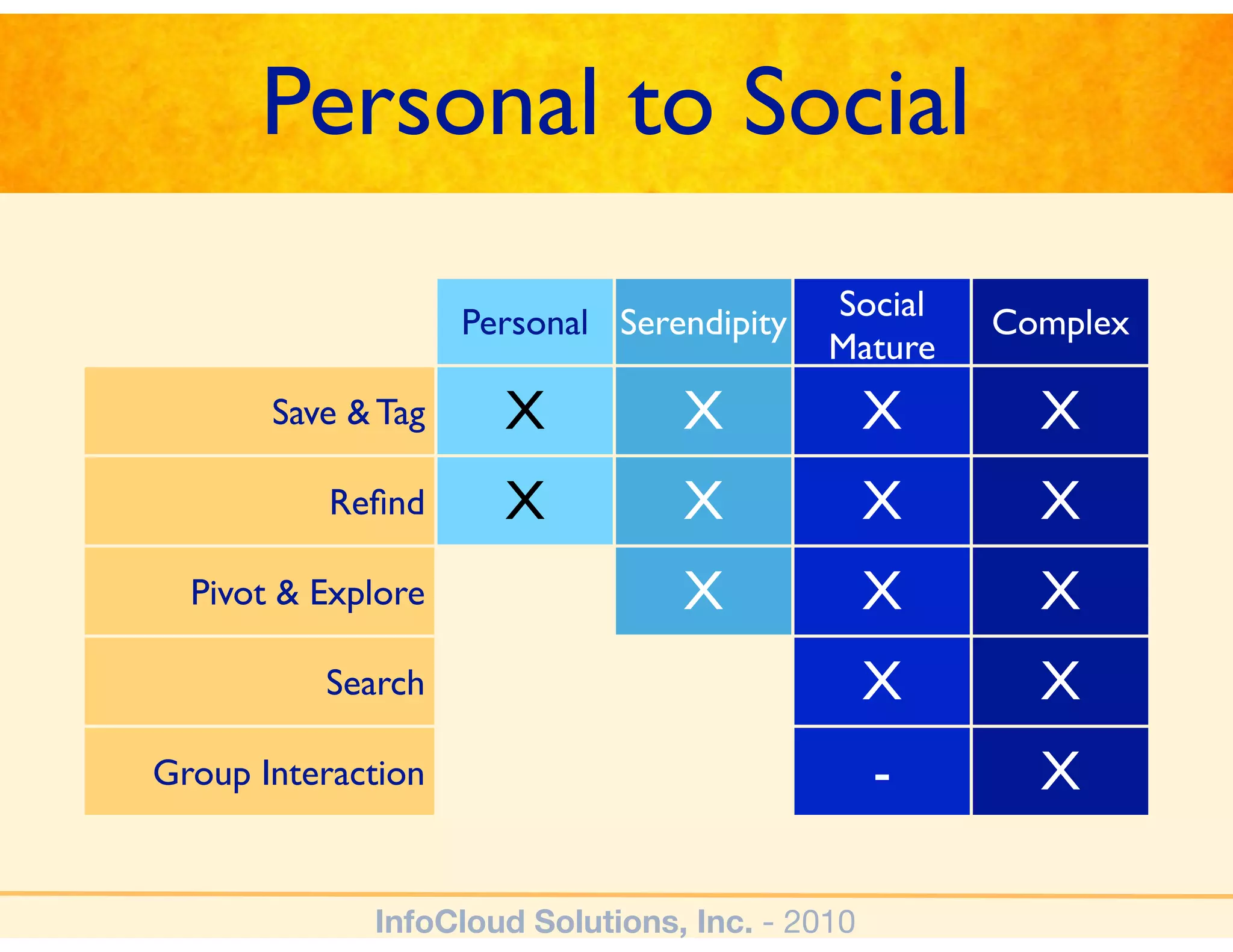




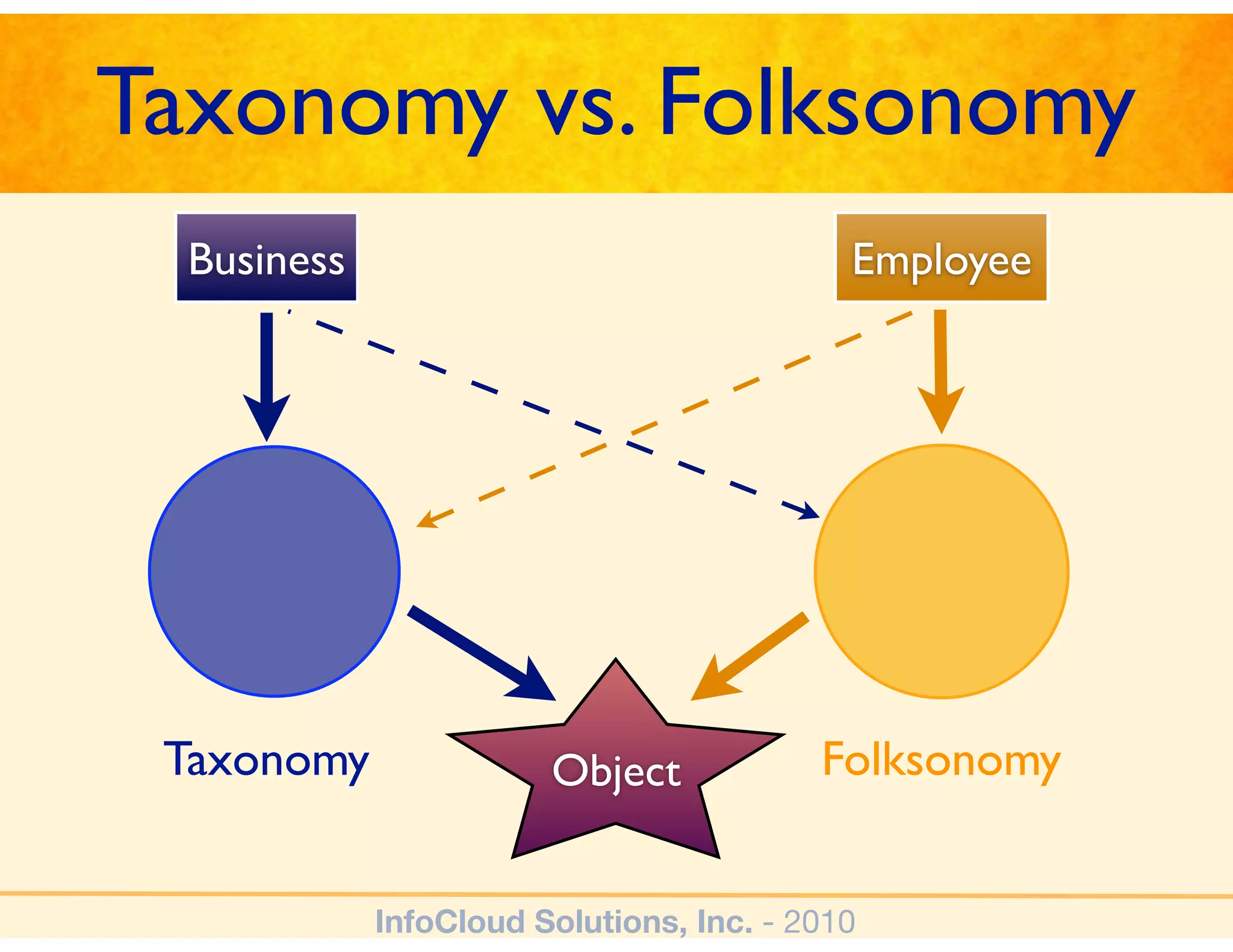
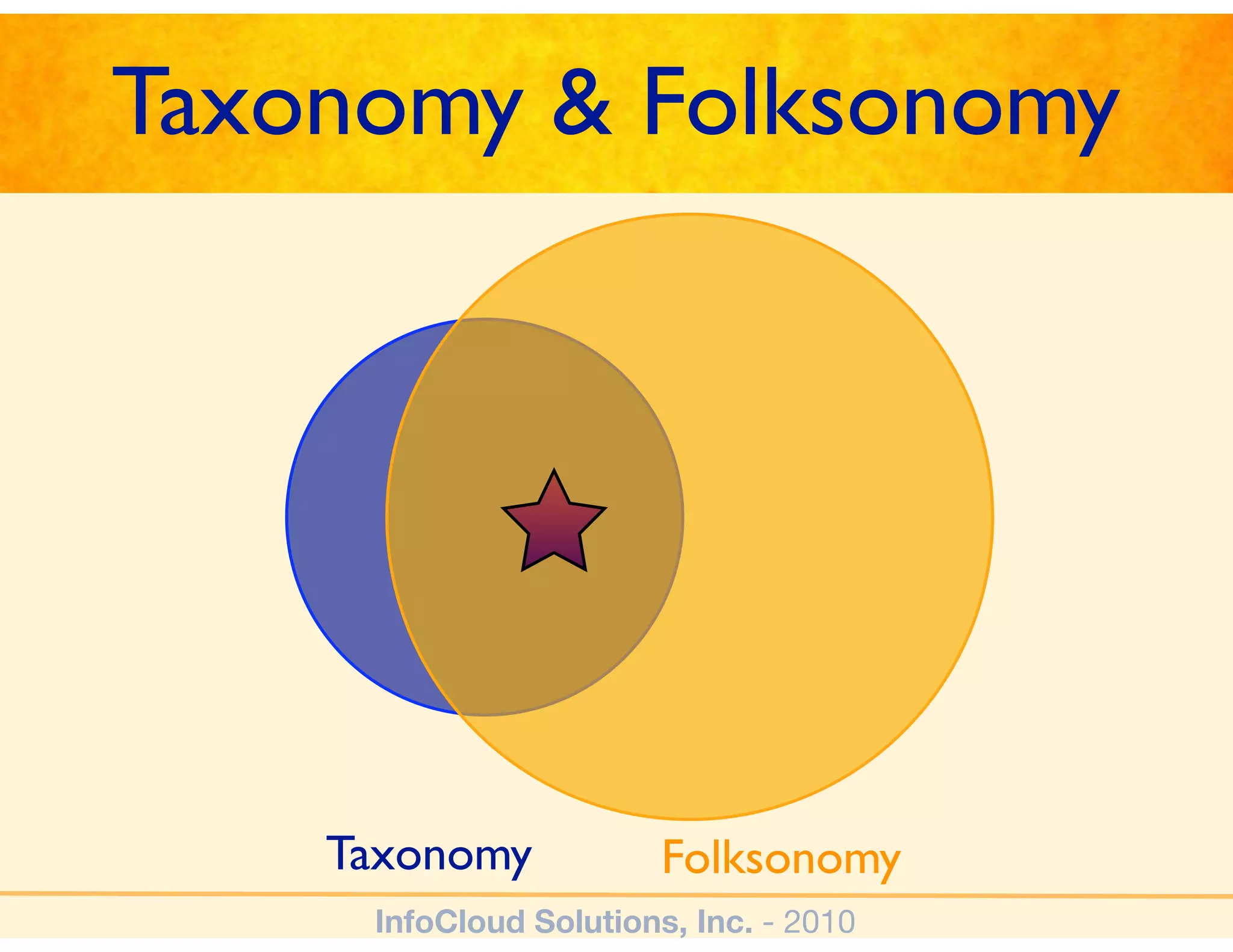


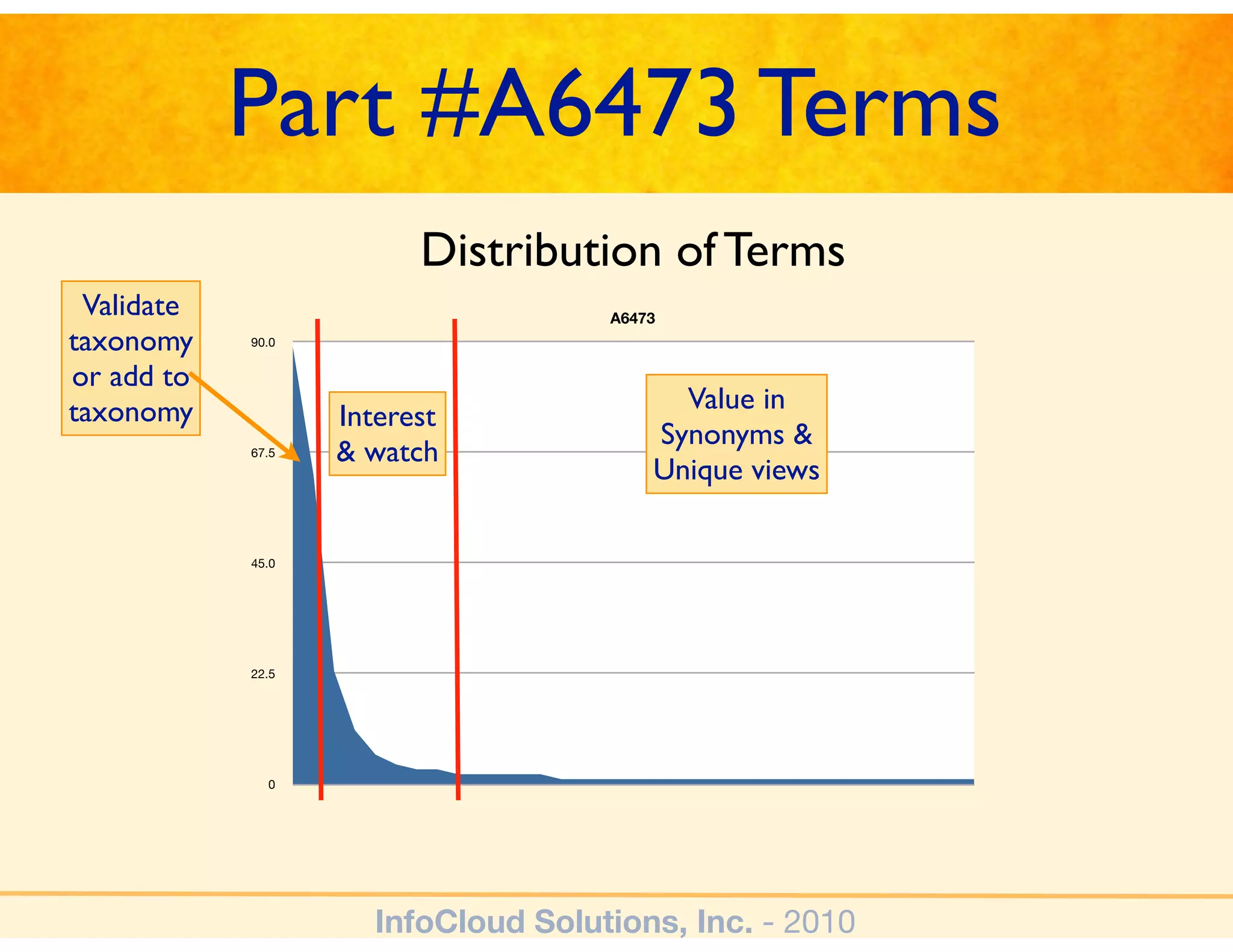
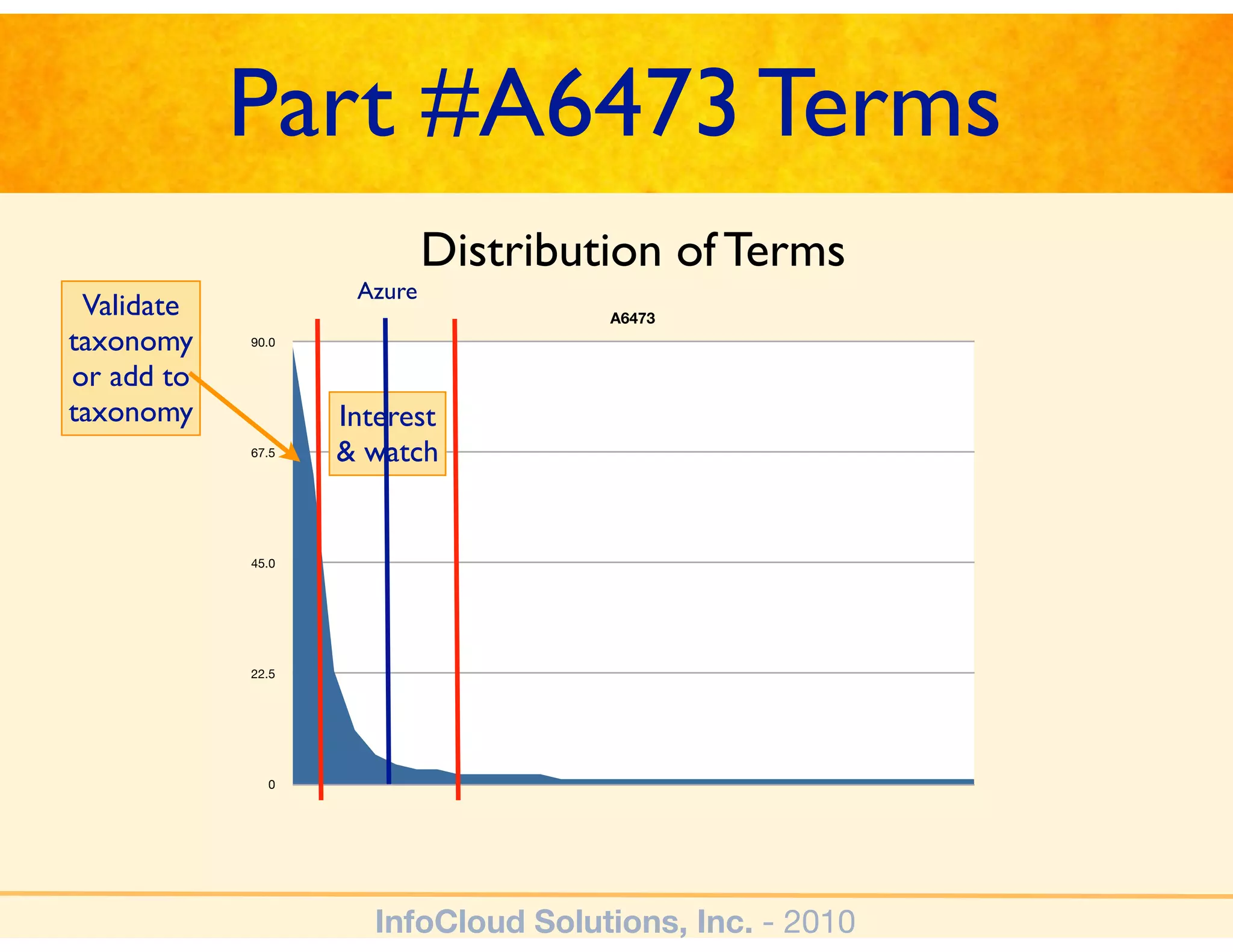
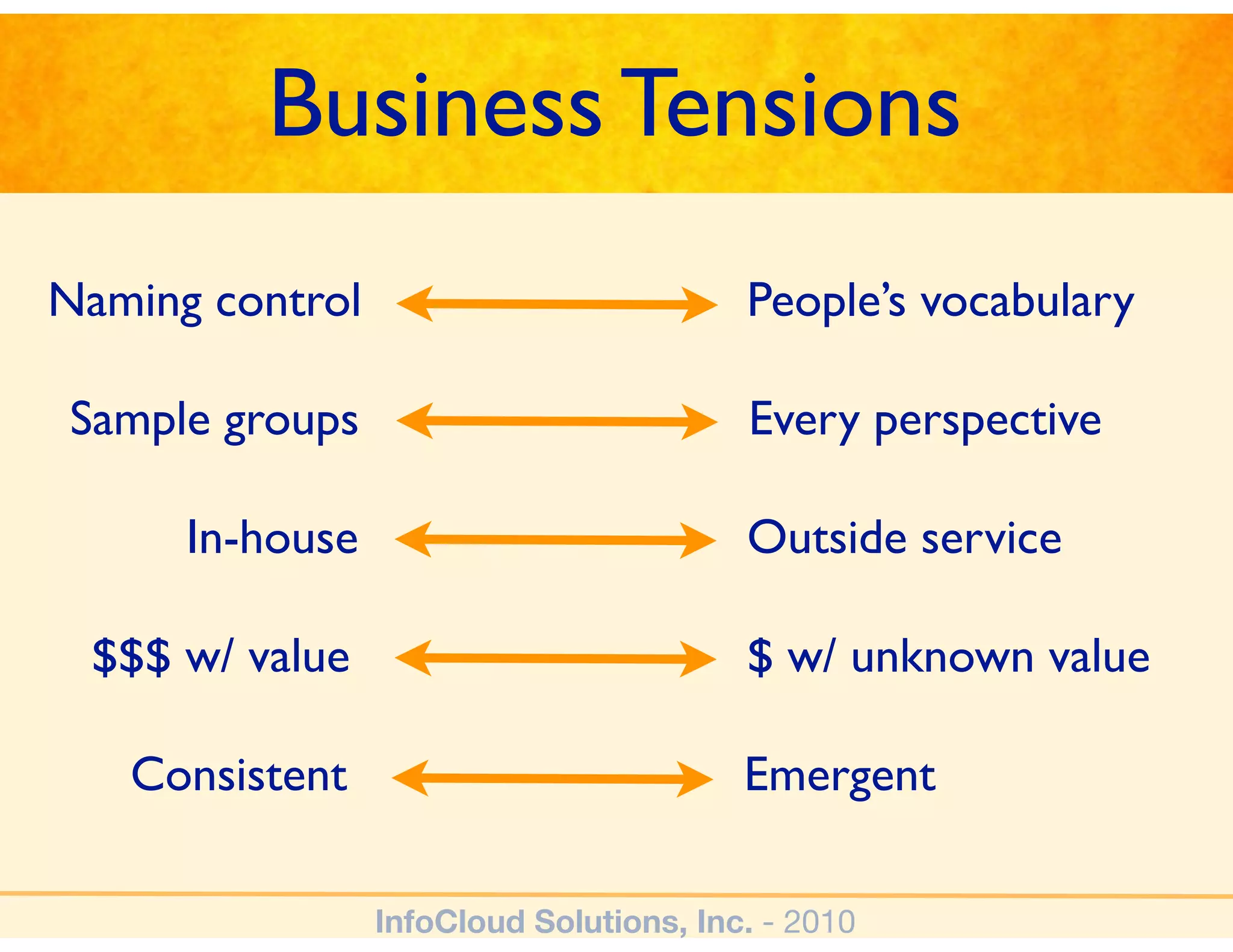




















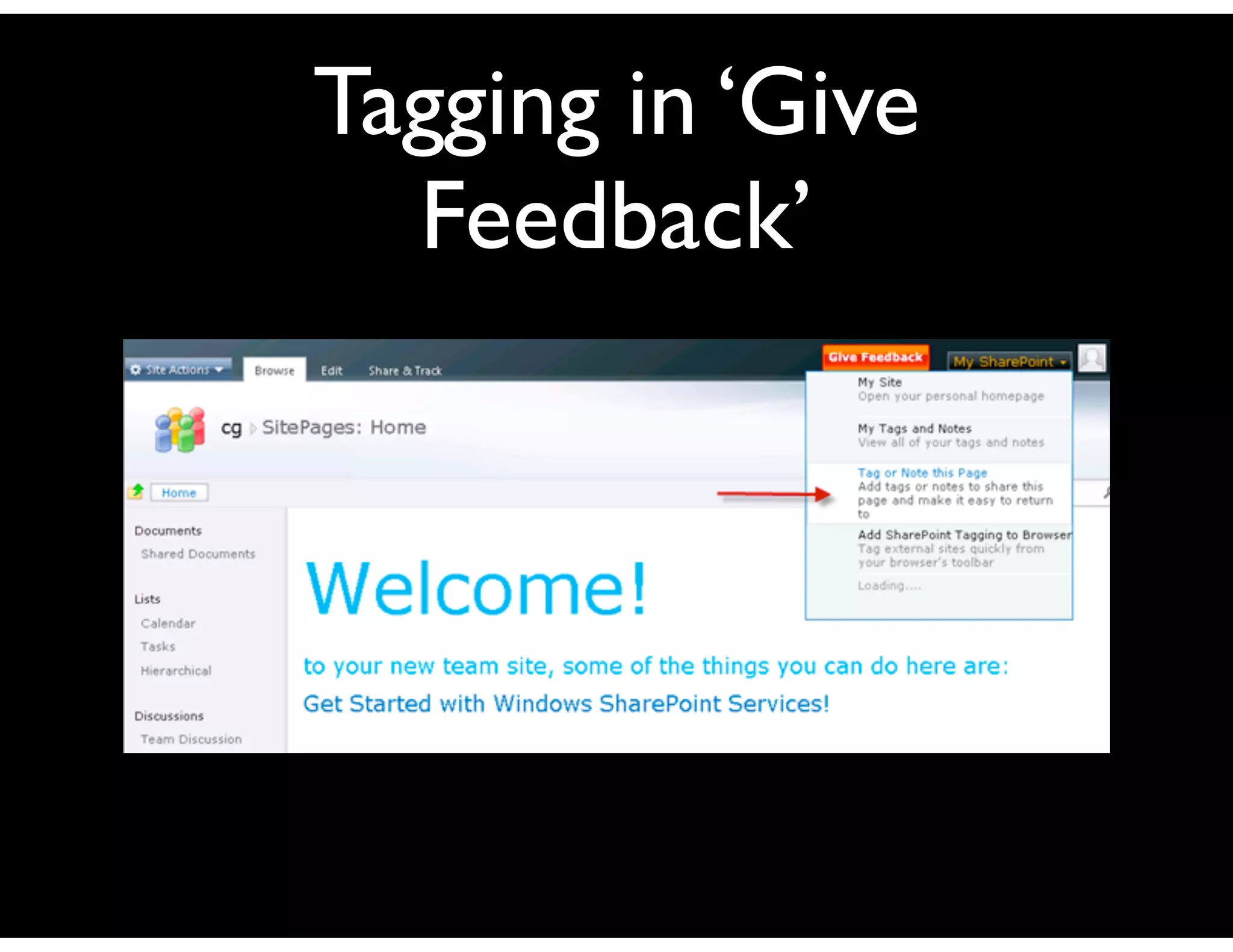
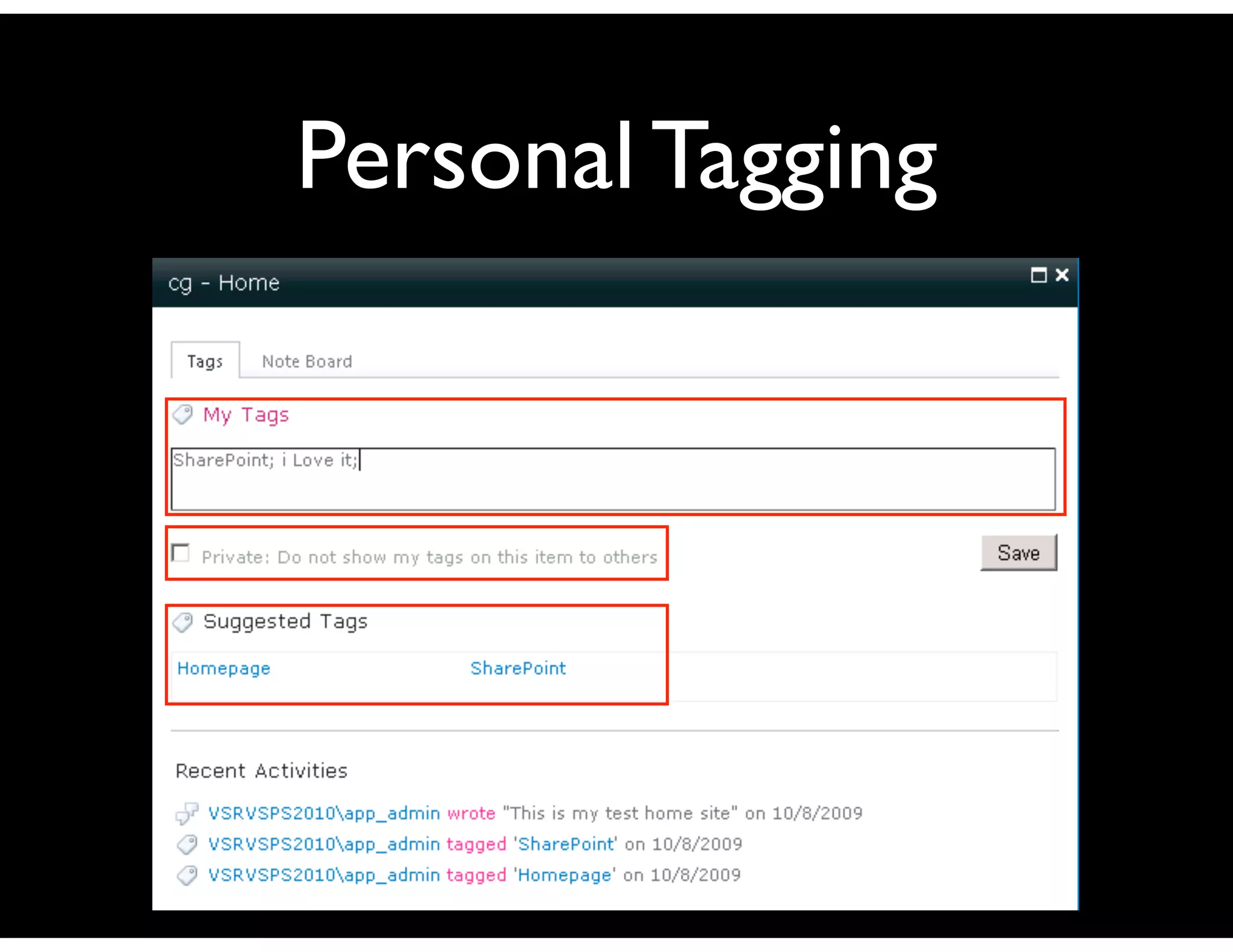

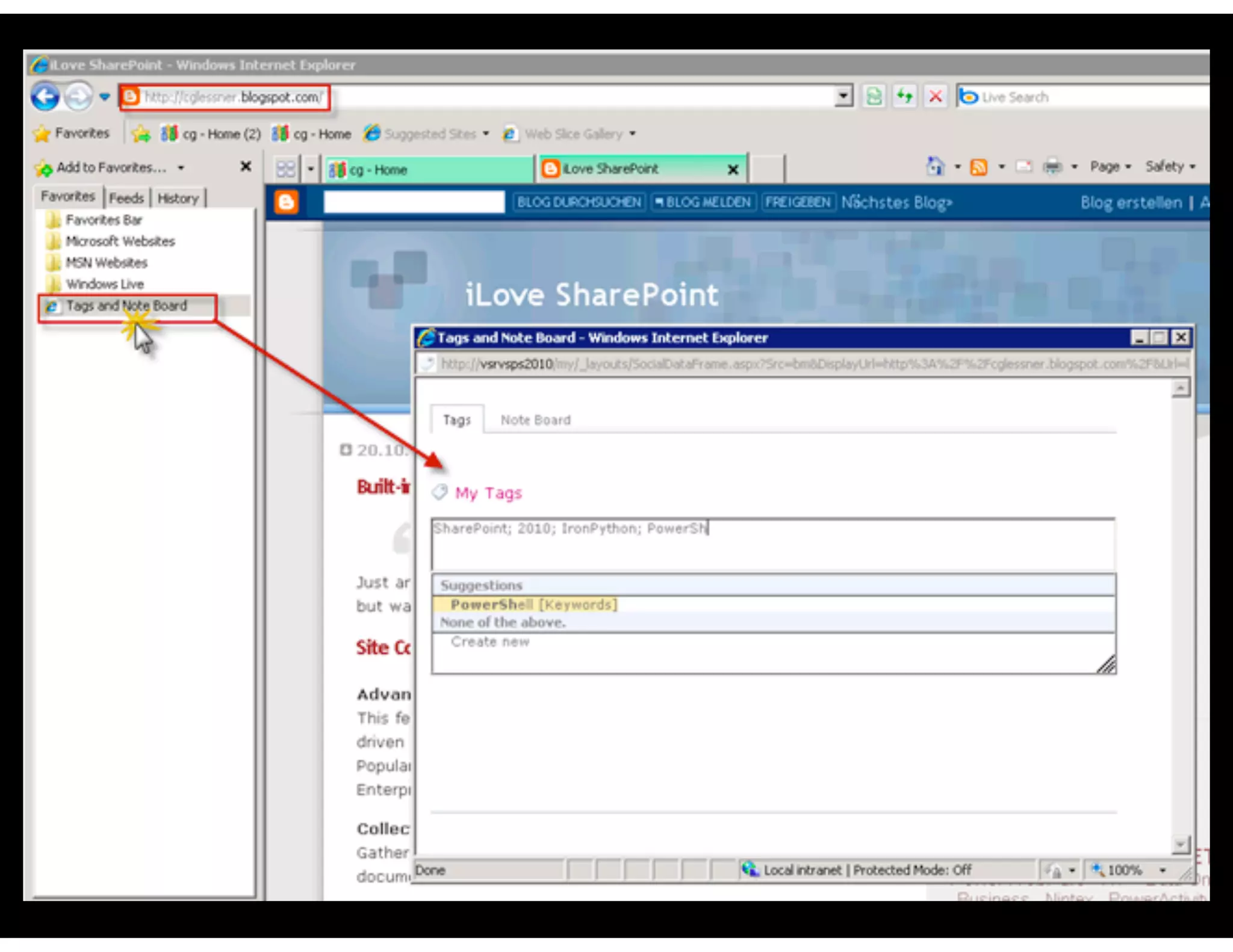







The document discusses the challenges and importance of tagging and folksonomy in improving search effectiveness within organizations, noting that traditional approaches often lead to insufficient search success rates. It defines folksonomy as a method where users tag information for retrieval based on personal understanding, emphasizing the need for user-driven vocabulary and metadata. Ultimately, it highlights the value of integrating folksonomy into tools like SharePoint to enhance information discovery and retrieval.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







