Downloaded 41 times











The document discusses the Split Miner, a process discovery tool that extracts accurate and simple business process models from event logs. It evaluates the quality of discovered models based on fitness, precision, generalization, complexity, and execution time, showcasing its effectiveness against other methodologies. Future work aims to enhance filtering, reduce the complexity of gateways, and develop real-time process discovery capabilities.
Presentation introduction on Split Miner, a tool for discovering business process models, by notable researchers.
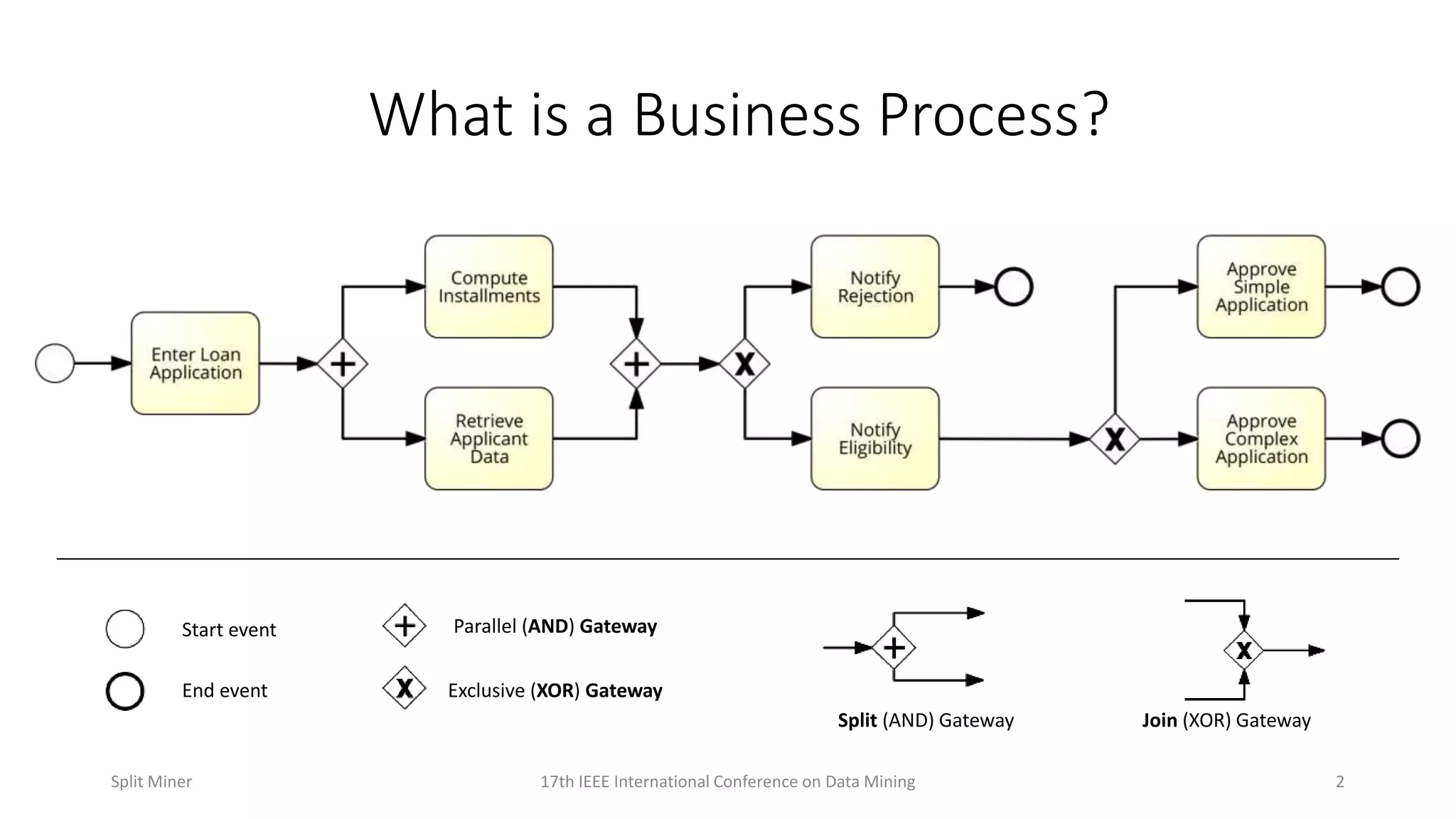
Explains fundamental concepts of business processes, including events such as start and end events, gateways, and splits.
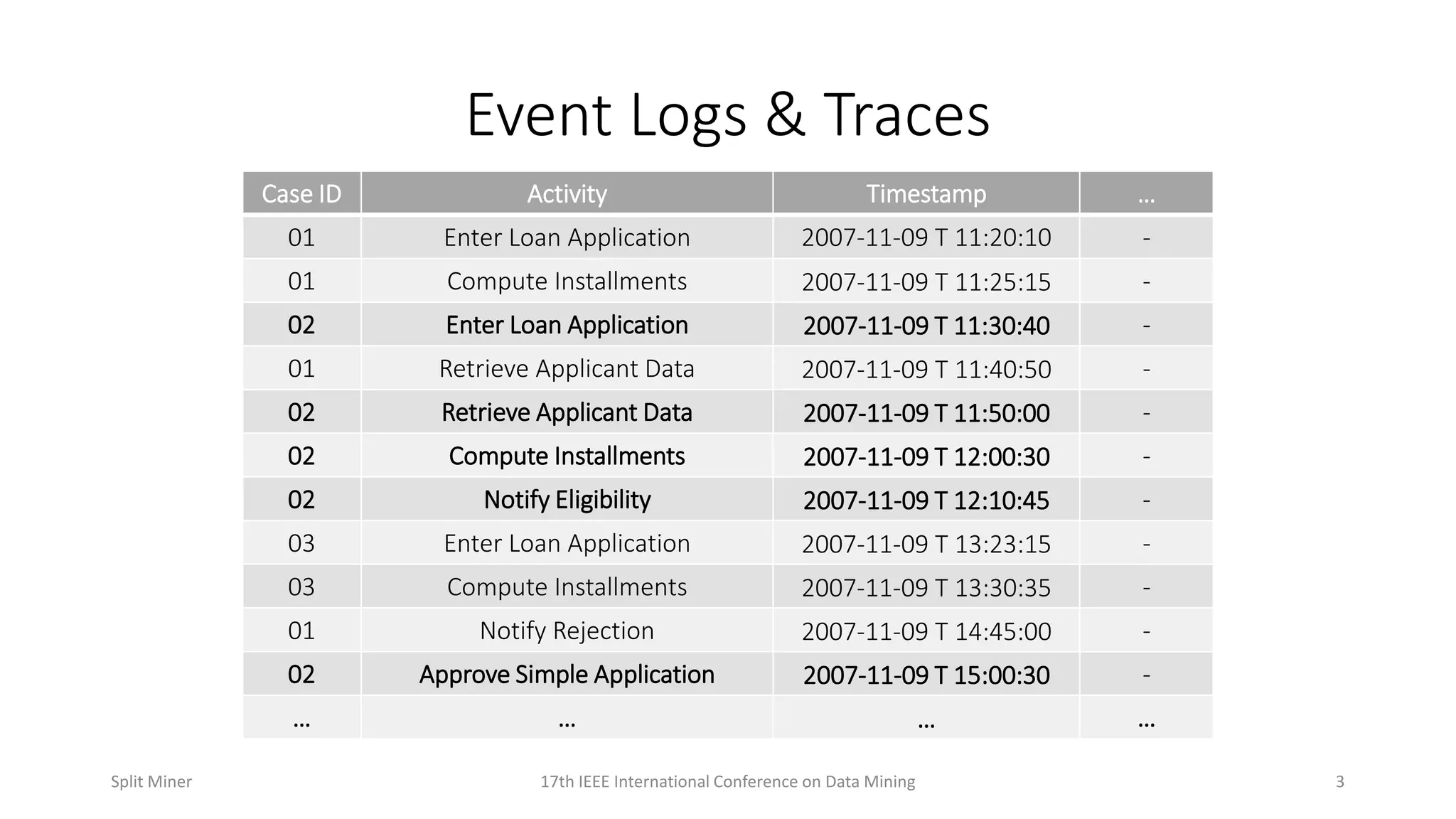
Detailed sample of event logs and traces, showing case IDs, activities, and timestamps associated with a loan application process.
Criteria for evaluating process models, emphasizing Recall (Fitness), Precision, F-Score, Generalization, and Complexity metrics.
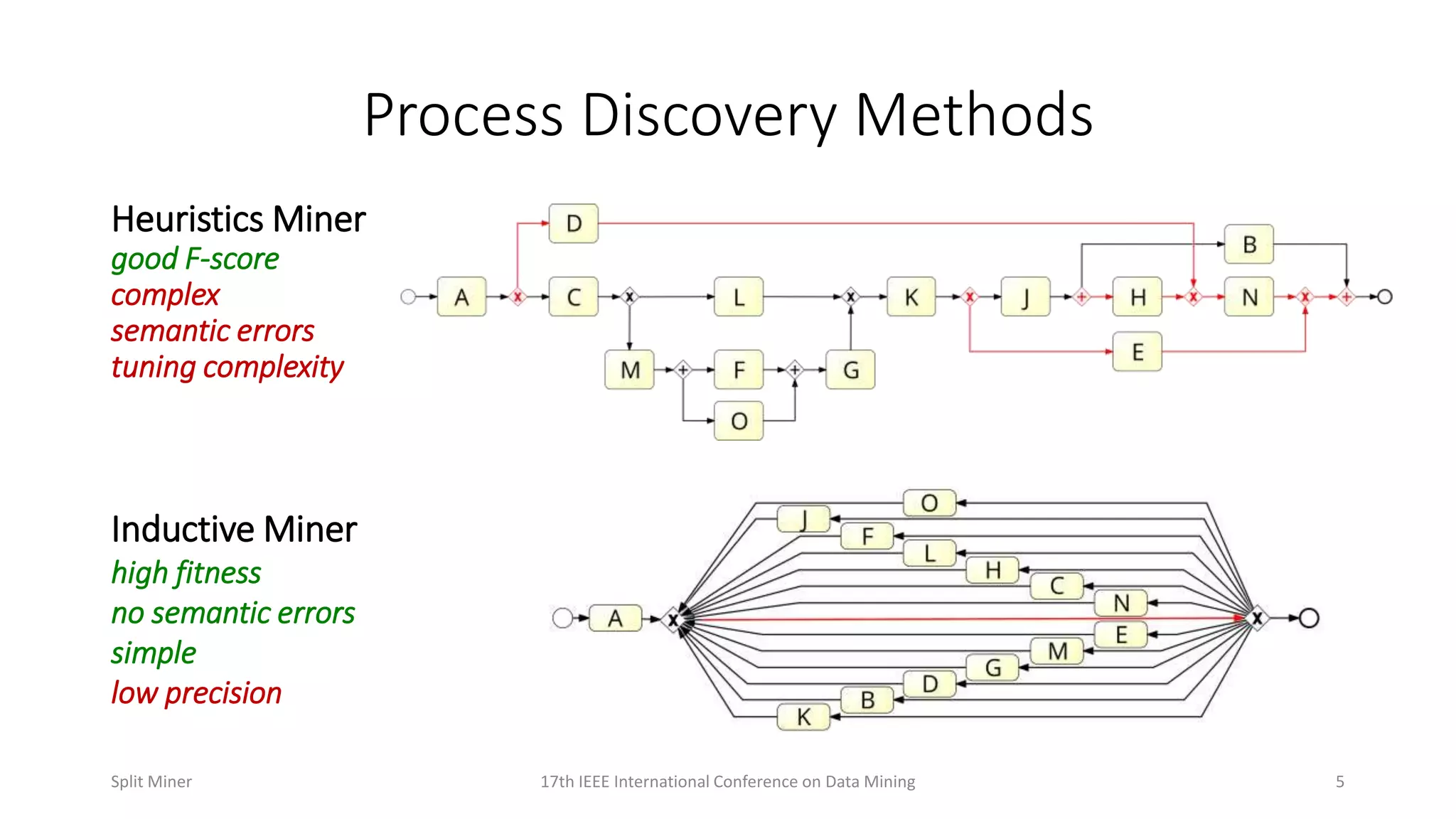
Examines different process discovery methods like Heuristic and Inductive Miner, highlighting their strengths and weaknesses.
Defines goals for the development of the Split Miner, focusing on balanced fitness and precision, high F-Score, low complexity, and execution time.
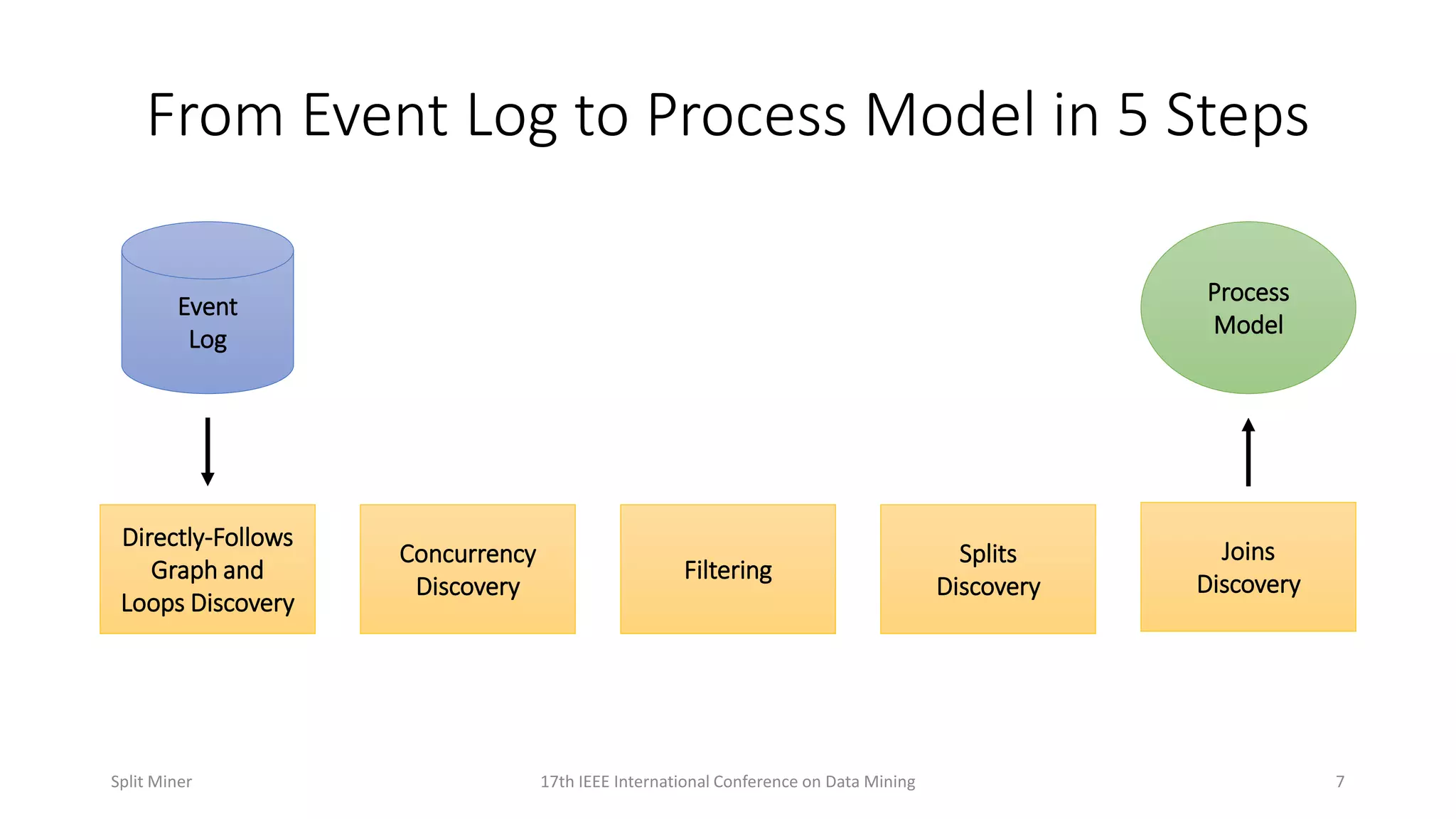
Describes the five steps involved in converting event logs into process models, detailing various discovery techniques.
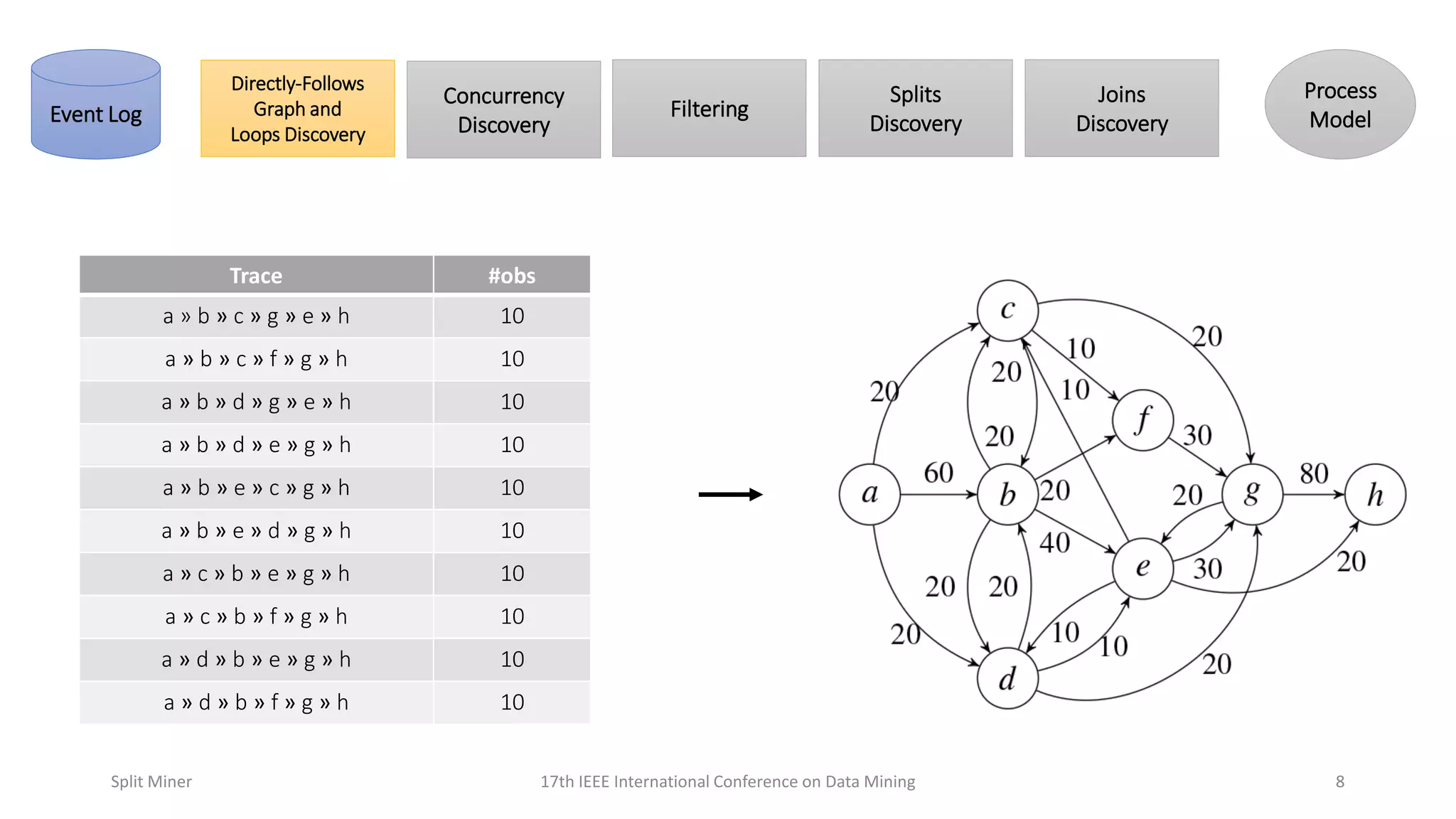
Further elaboration on tracing behaviors within event logs, showcasing observed patterns during model generation.
Continues from previous slide, further detailing traces and their significance in process model generation.
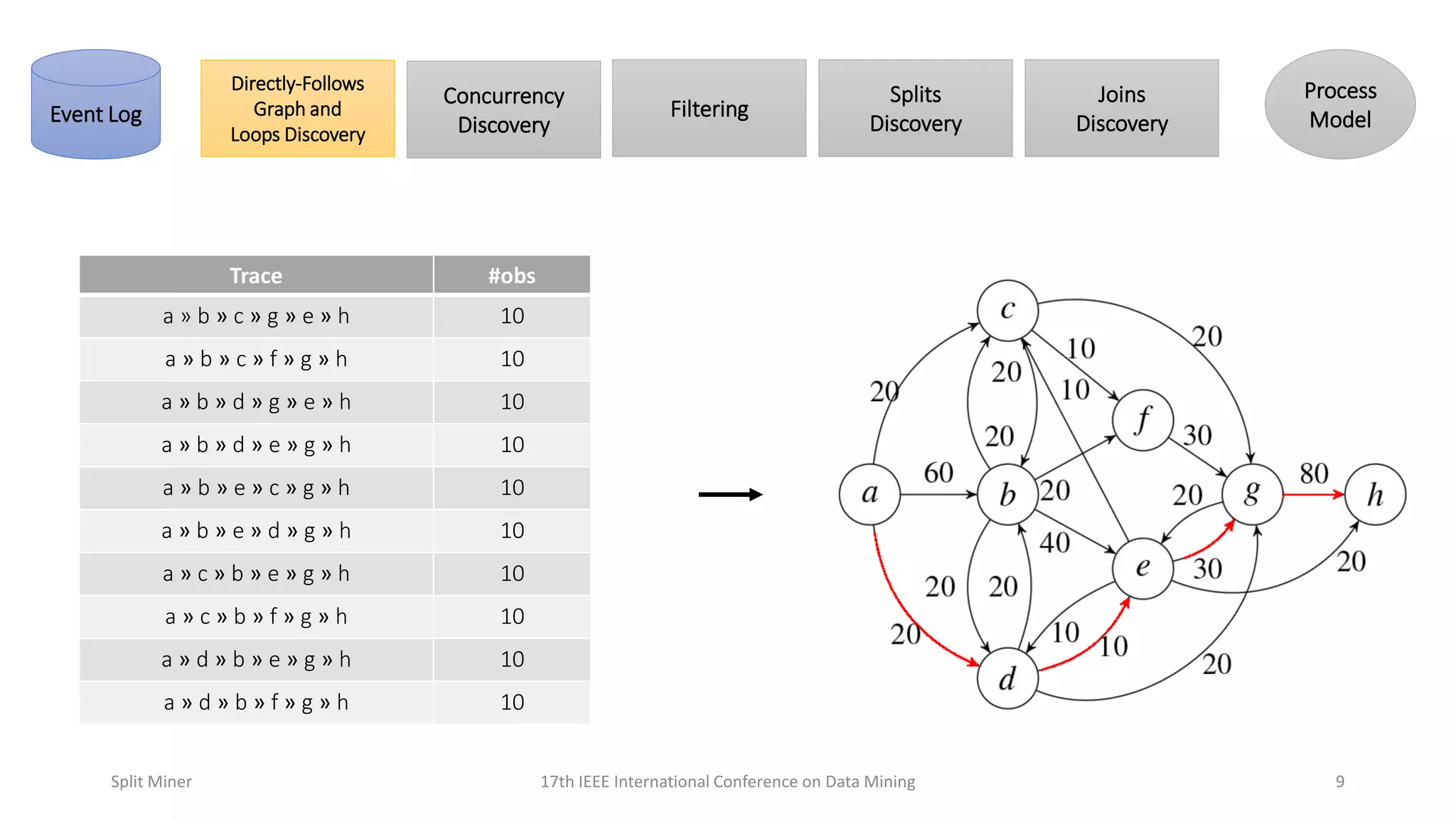
Focuses on the formation and utility of directly-follows graphs in process modeling.
Further explanation on how directly-follows graphs contribute to process modeling.
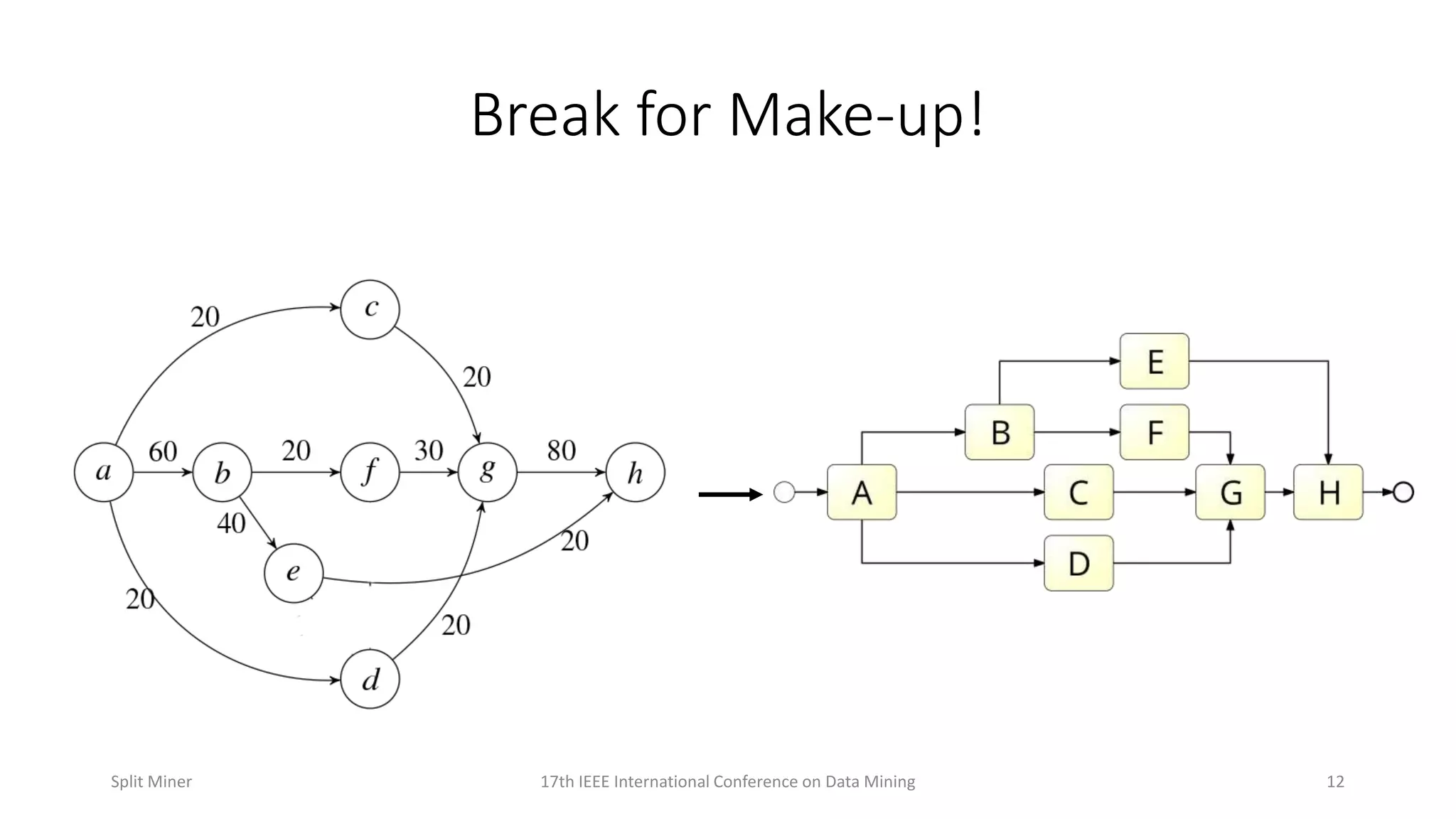
A brief intermission in the presentation.
Advanced features of directly-follows graphs impacting process modeling techniques.
Continues exploring advanced topics regarding loops and graph structures in process discovery.
Concludes the explanation of process model generation.
Explains the setup for evaluation using real-life event logs across various domains and metrics.
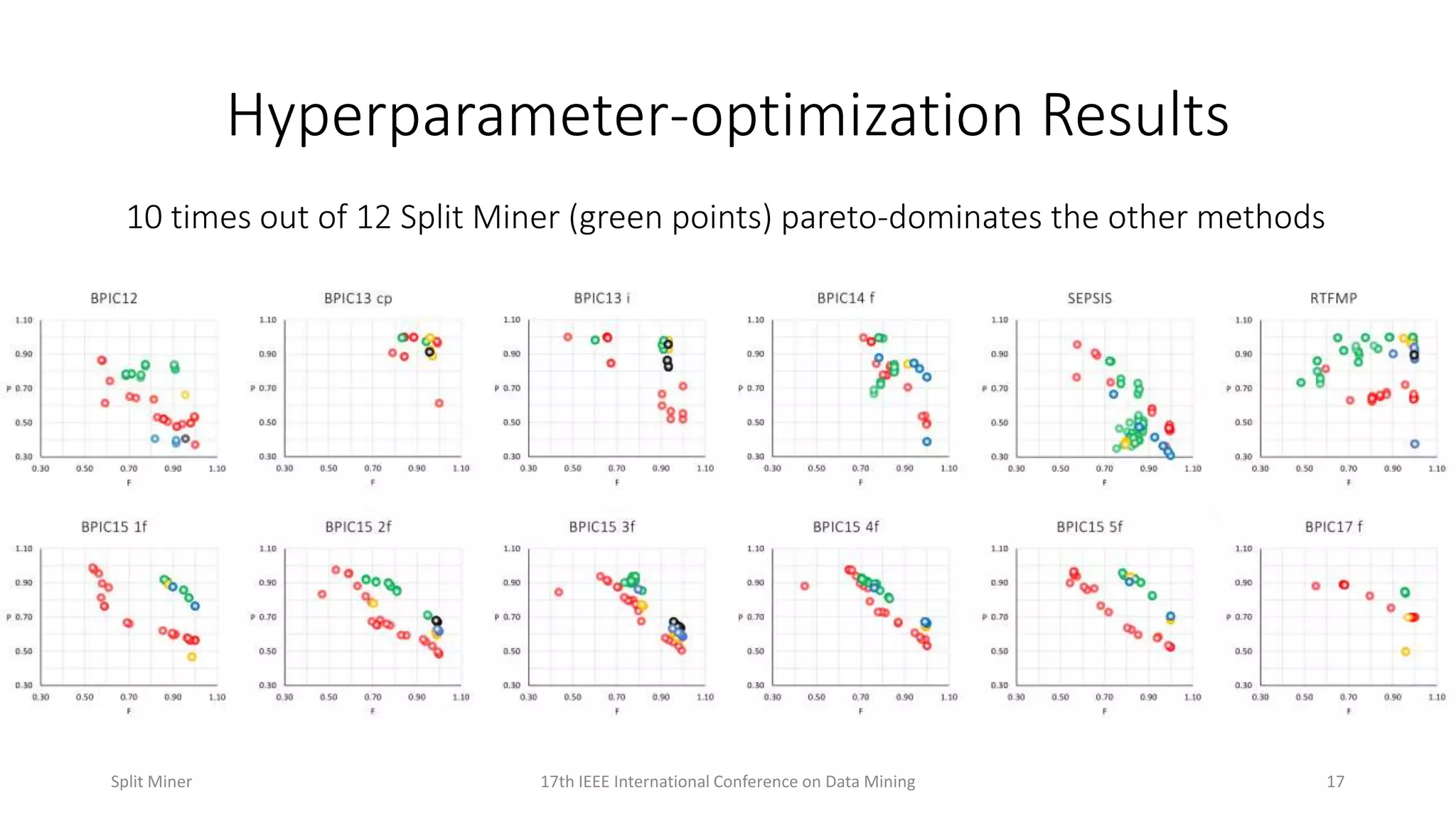
Presents results showing Split Miner's dominance over other methods based on hyperparameter optimization.
Highlights successful outcomes of Split Miner with default parameters, focusing on F-score and execution time advantages.
Introduces the integration of Split Miner within the Apromore framework.
Outlines potential improvements and future development areas for optimizing Split Miner.
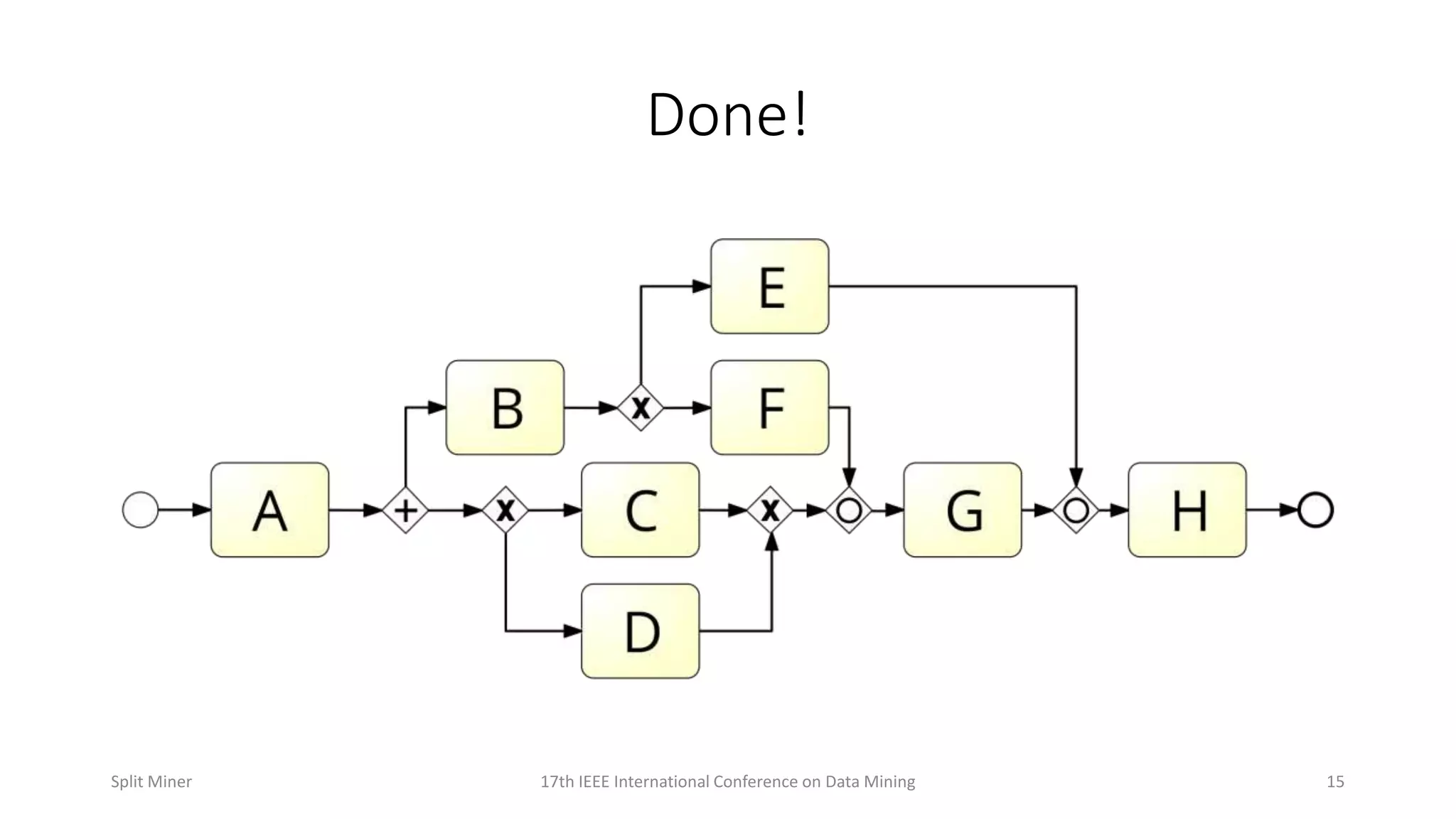
Wraps up the presentation and opens the floor for questions.
Contains supplementary slides with extra information.
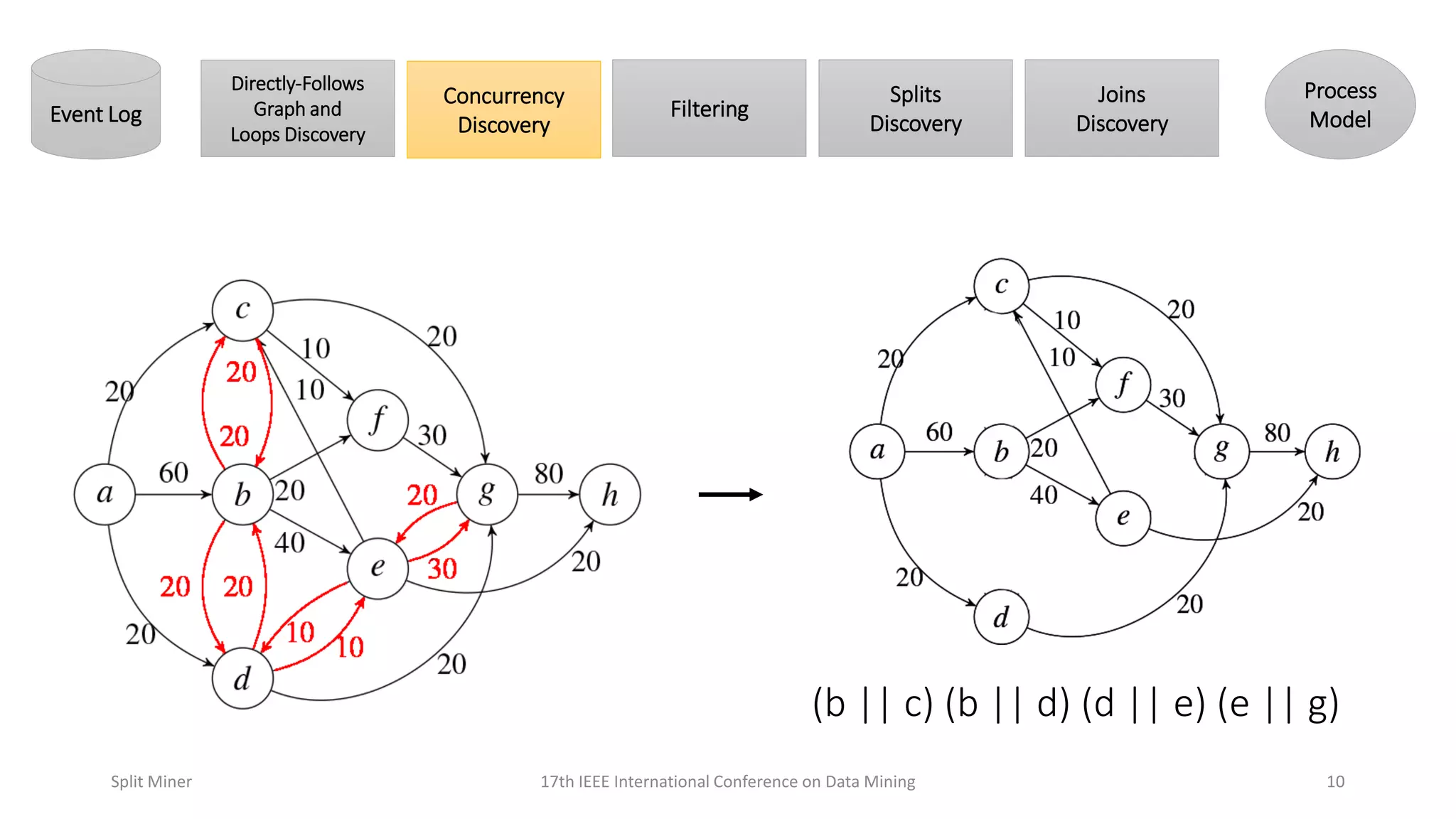
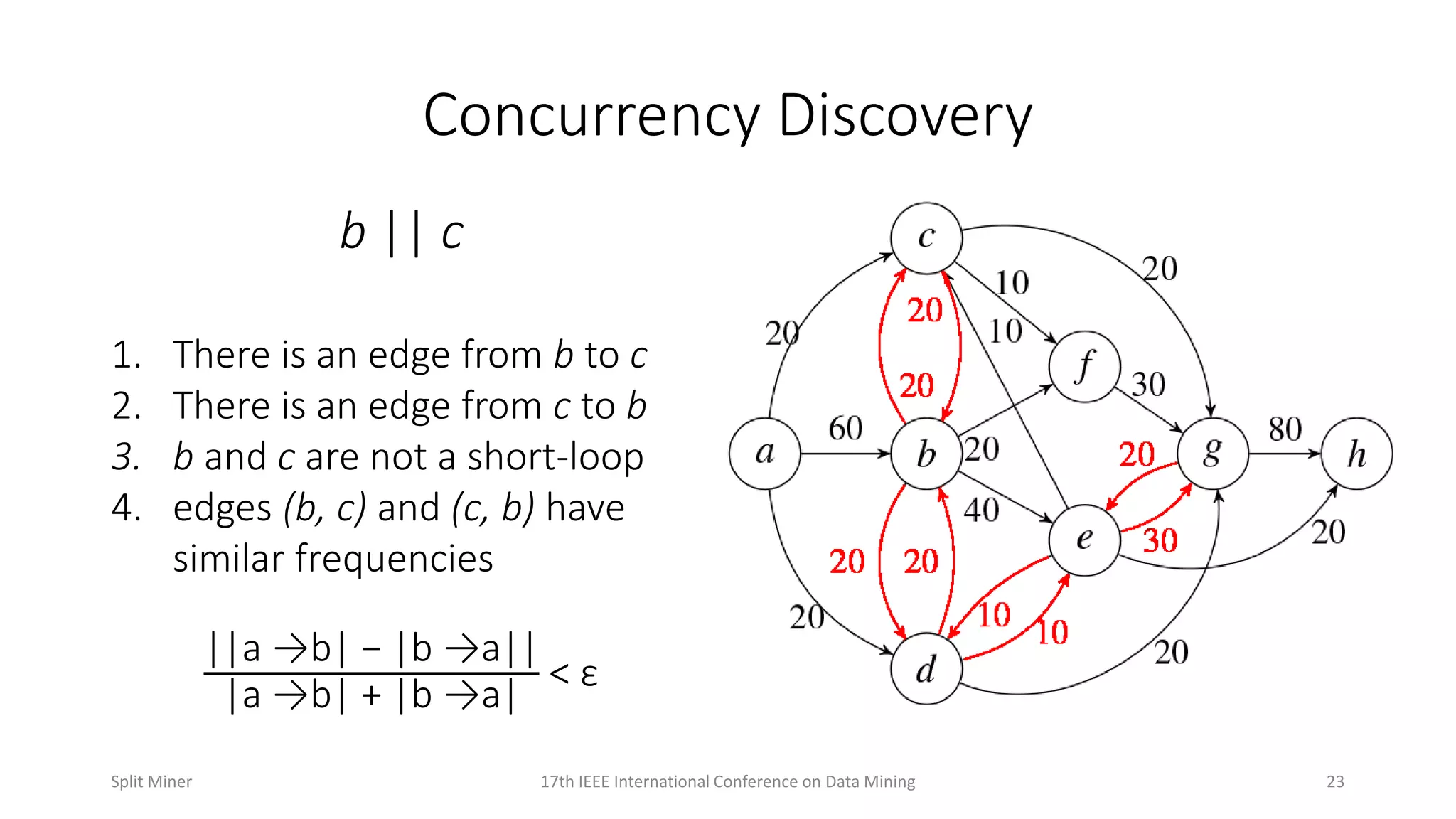
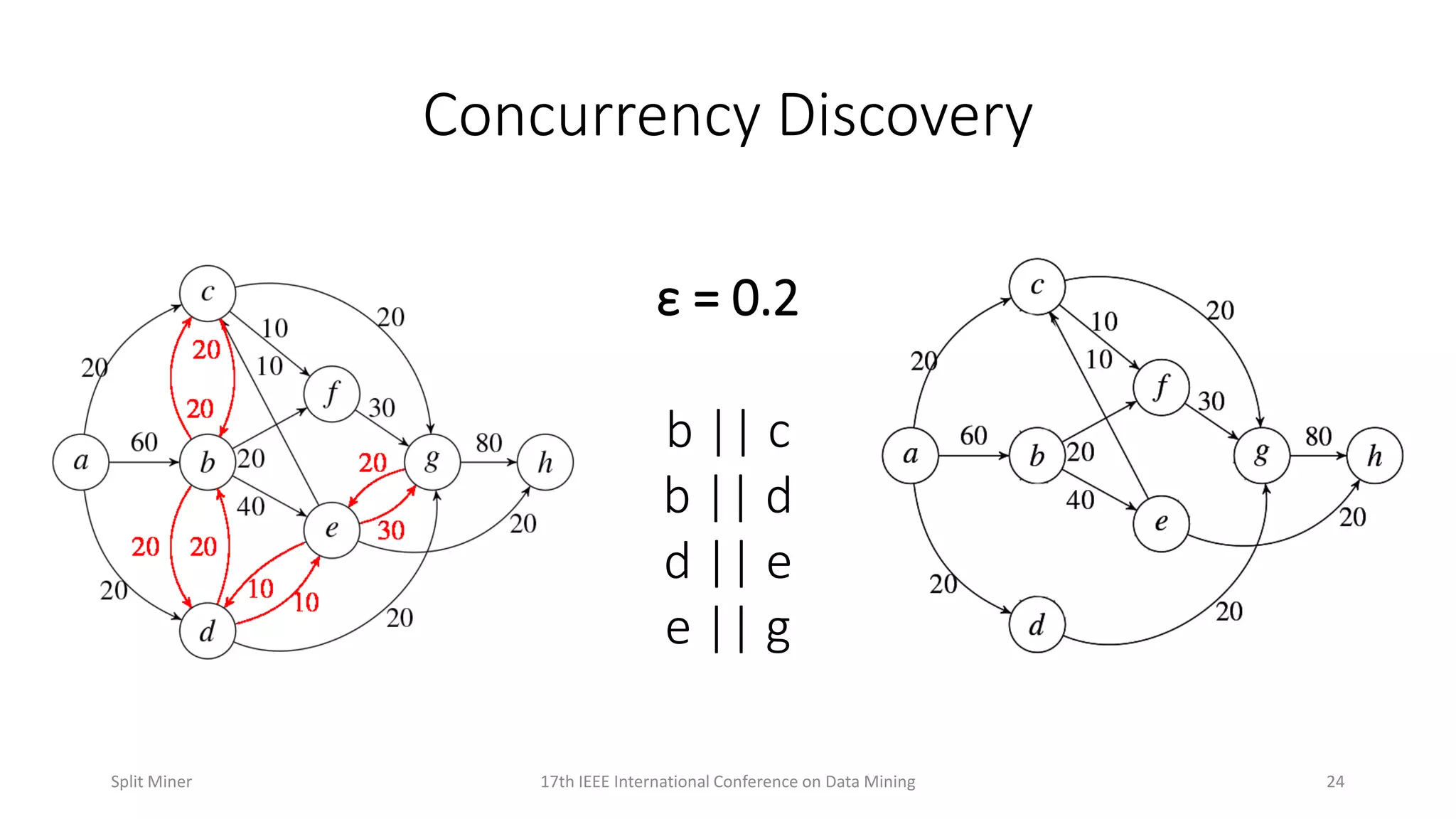
Describes the principles of concurrency discovery to identify parallel processes in a model.
Further elaboration on concurrency discovery principles with examples.
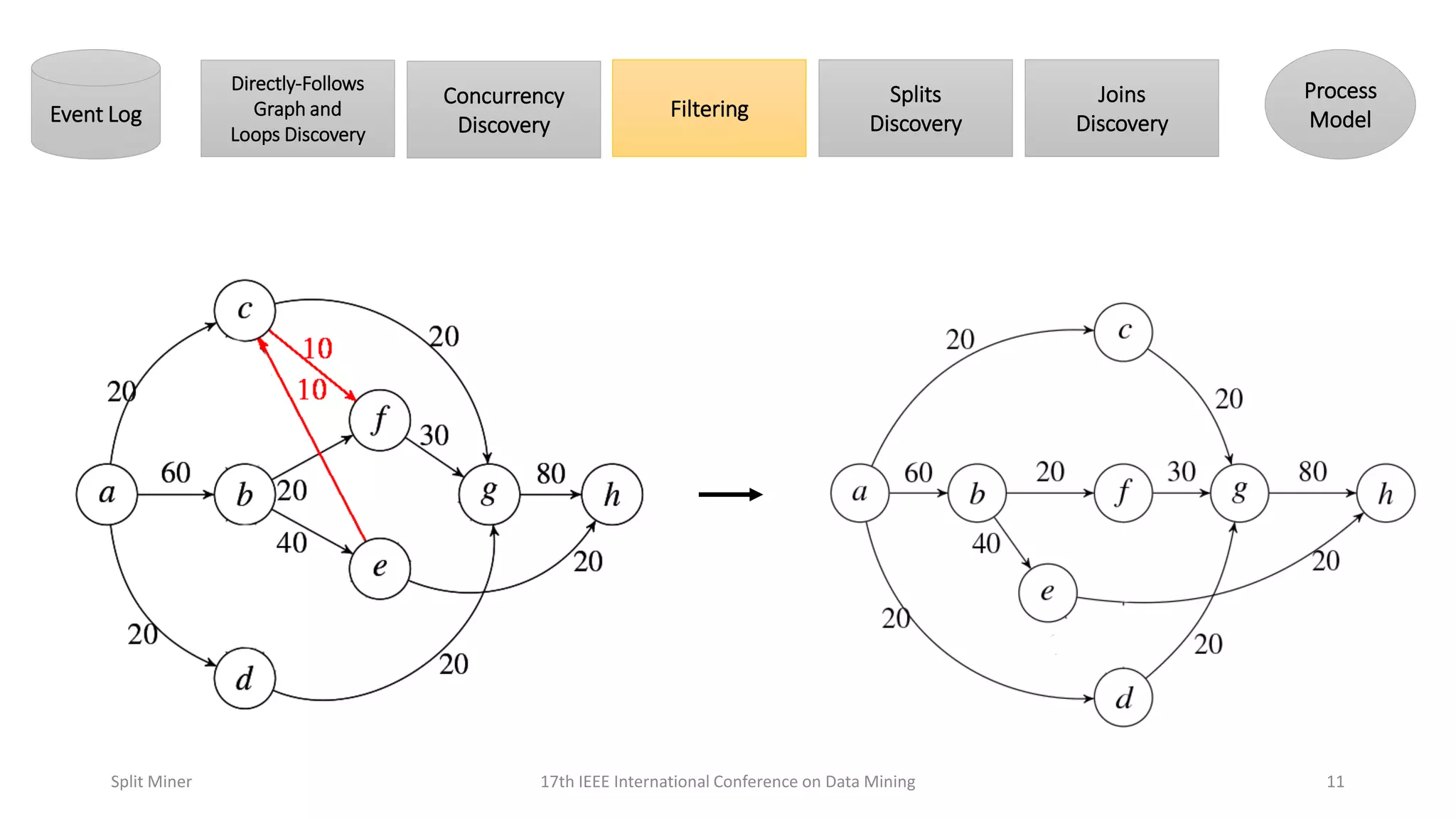
Explains methods for filtering event logs to retain frequent behaviors, enhancing model quality.
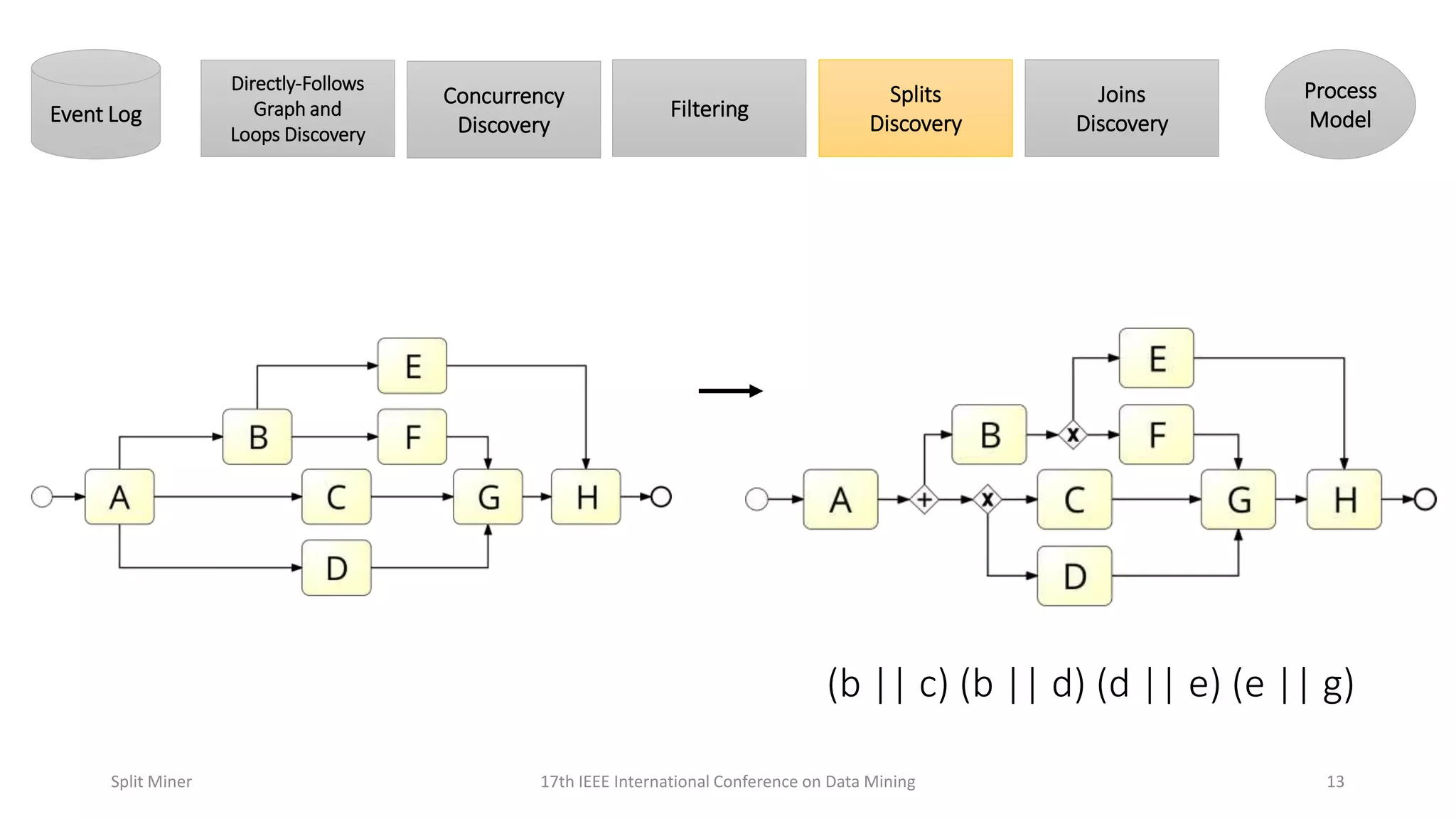
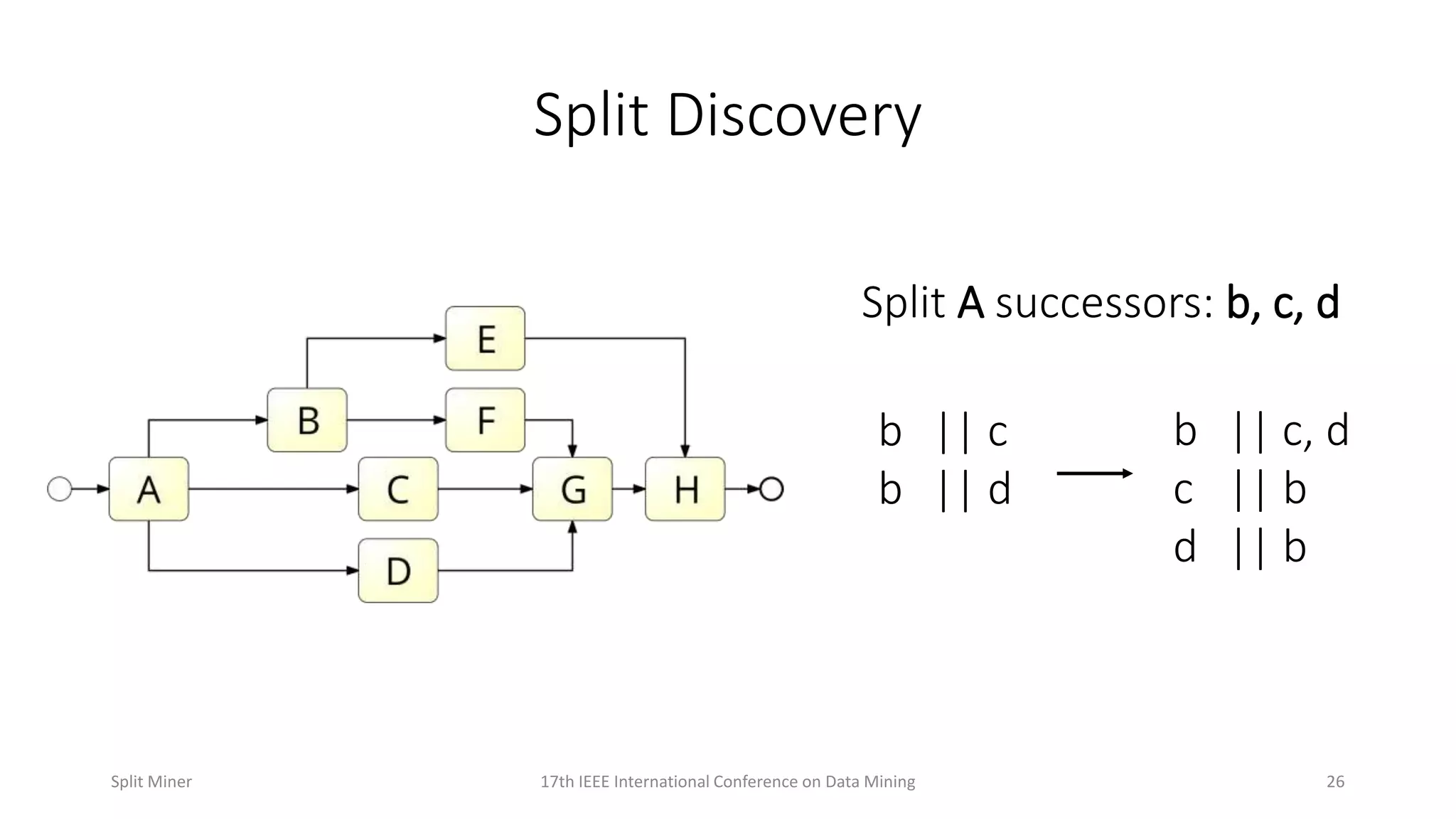
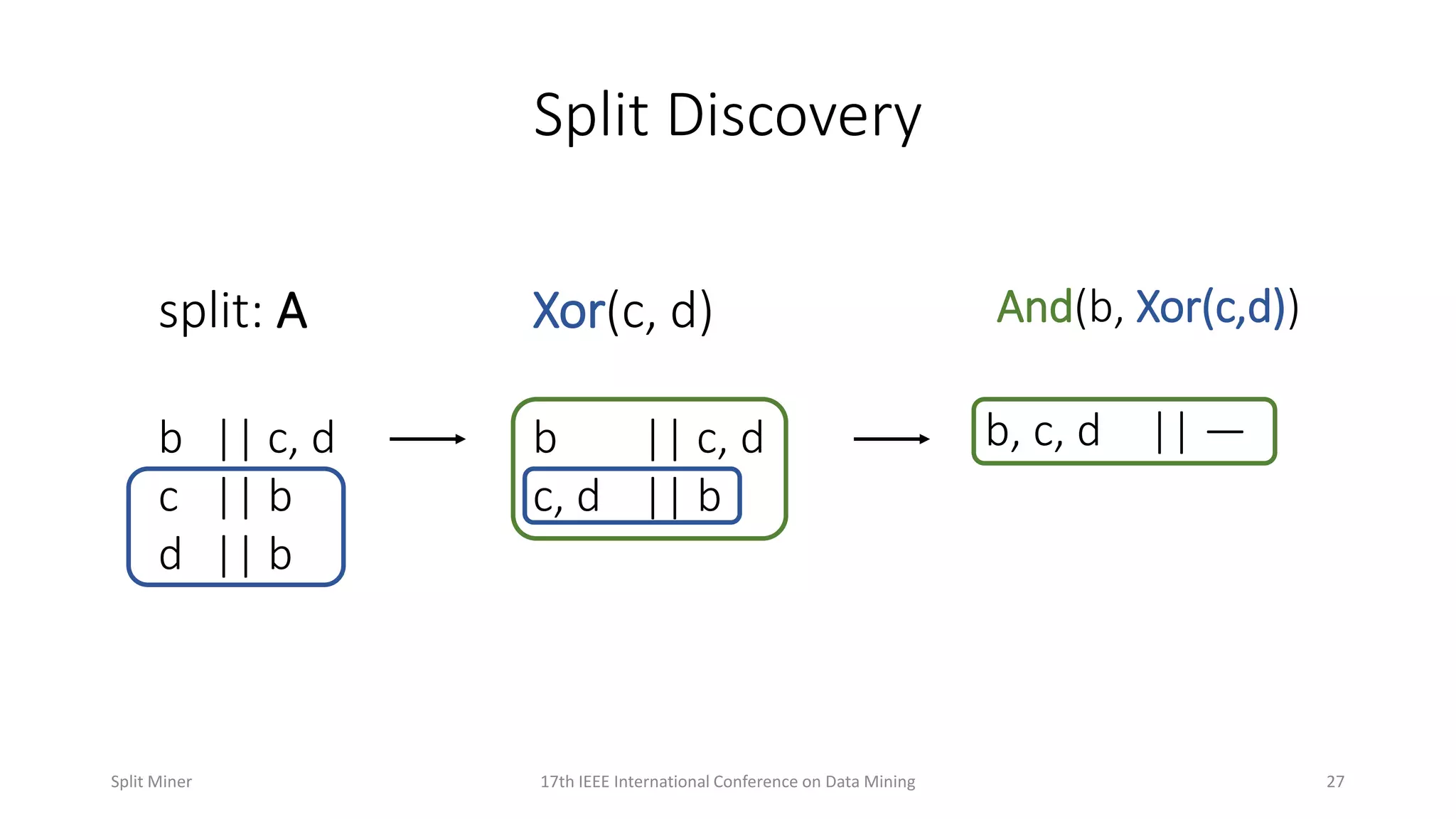
Details the process of discovering splits in event logs and their representation in process models.
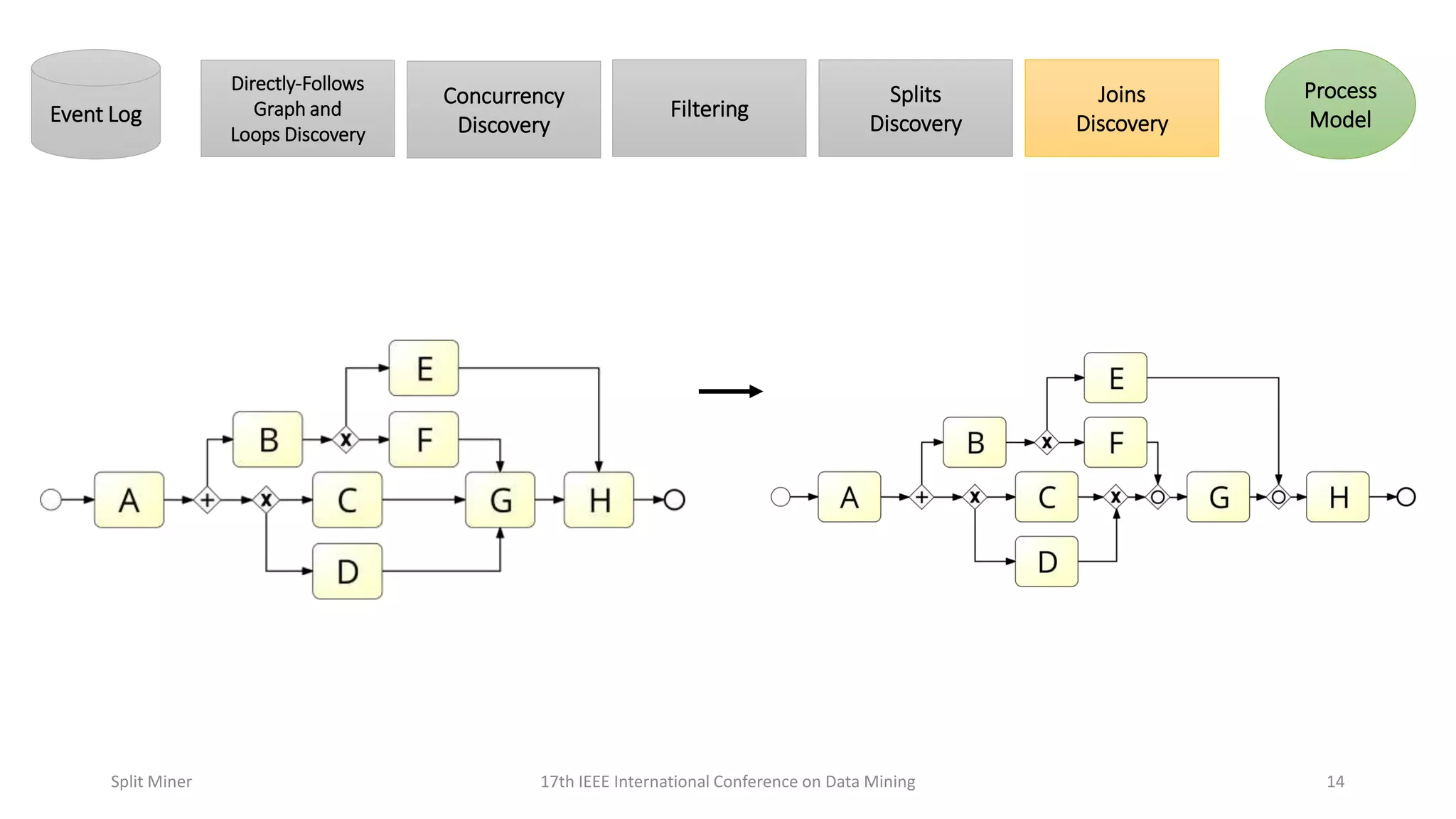
Discusses complex scenarios in split discovery and representation in process models.








































![[IJET-V1I4P3] Authors :Mekhala](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i4p3-150728160211-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














































