Download to read offline








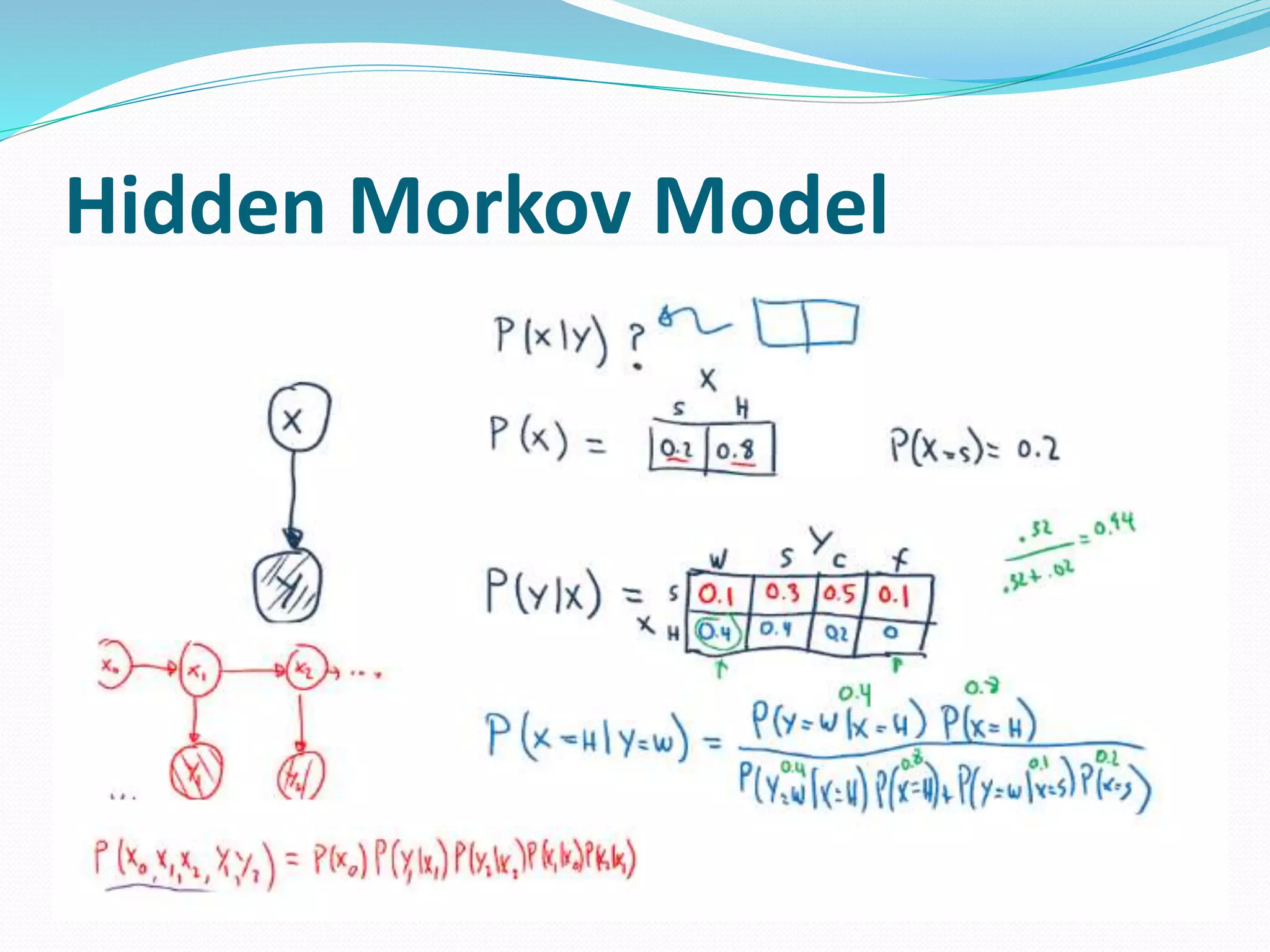

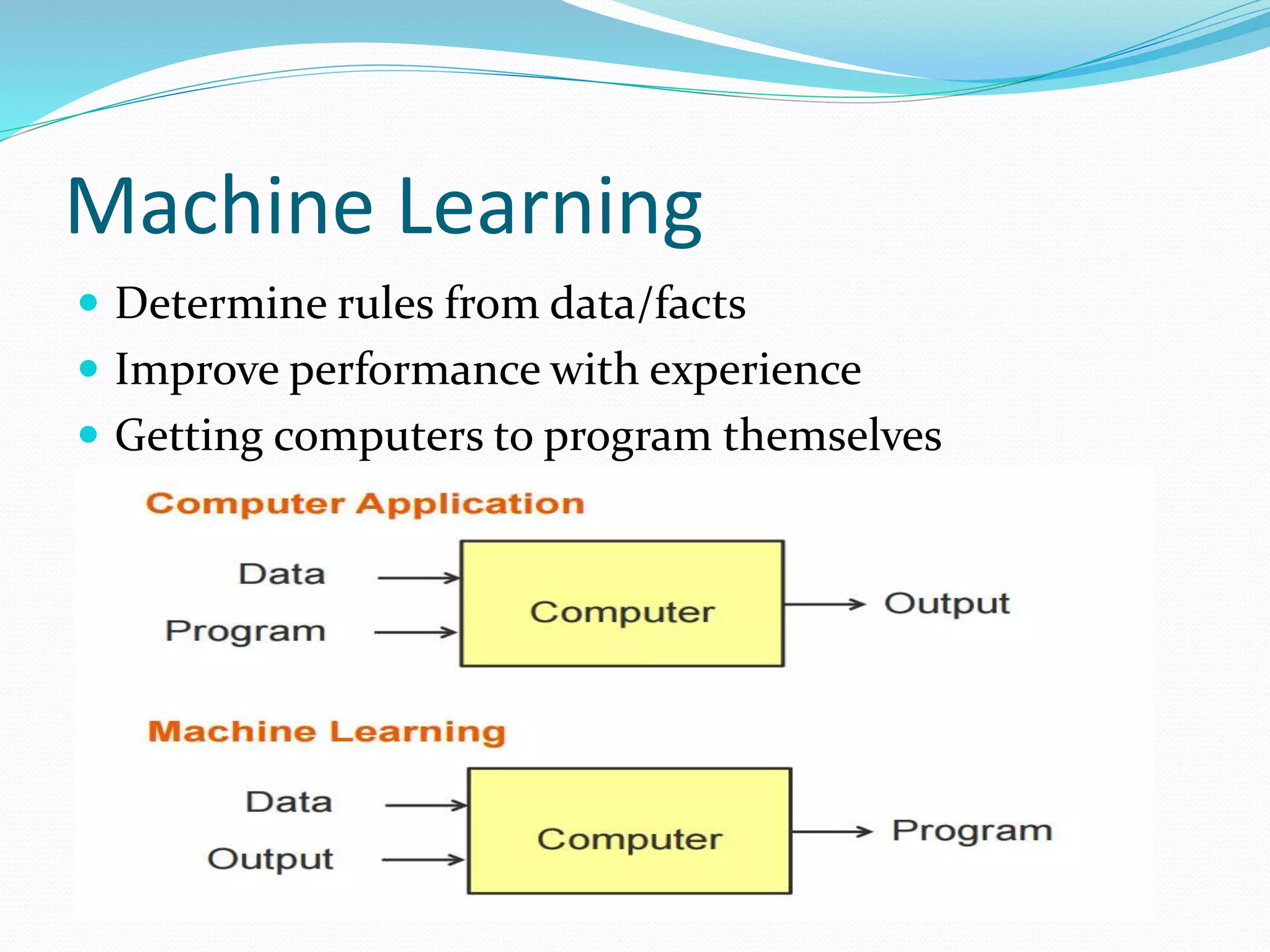







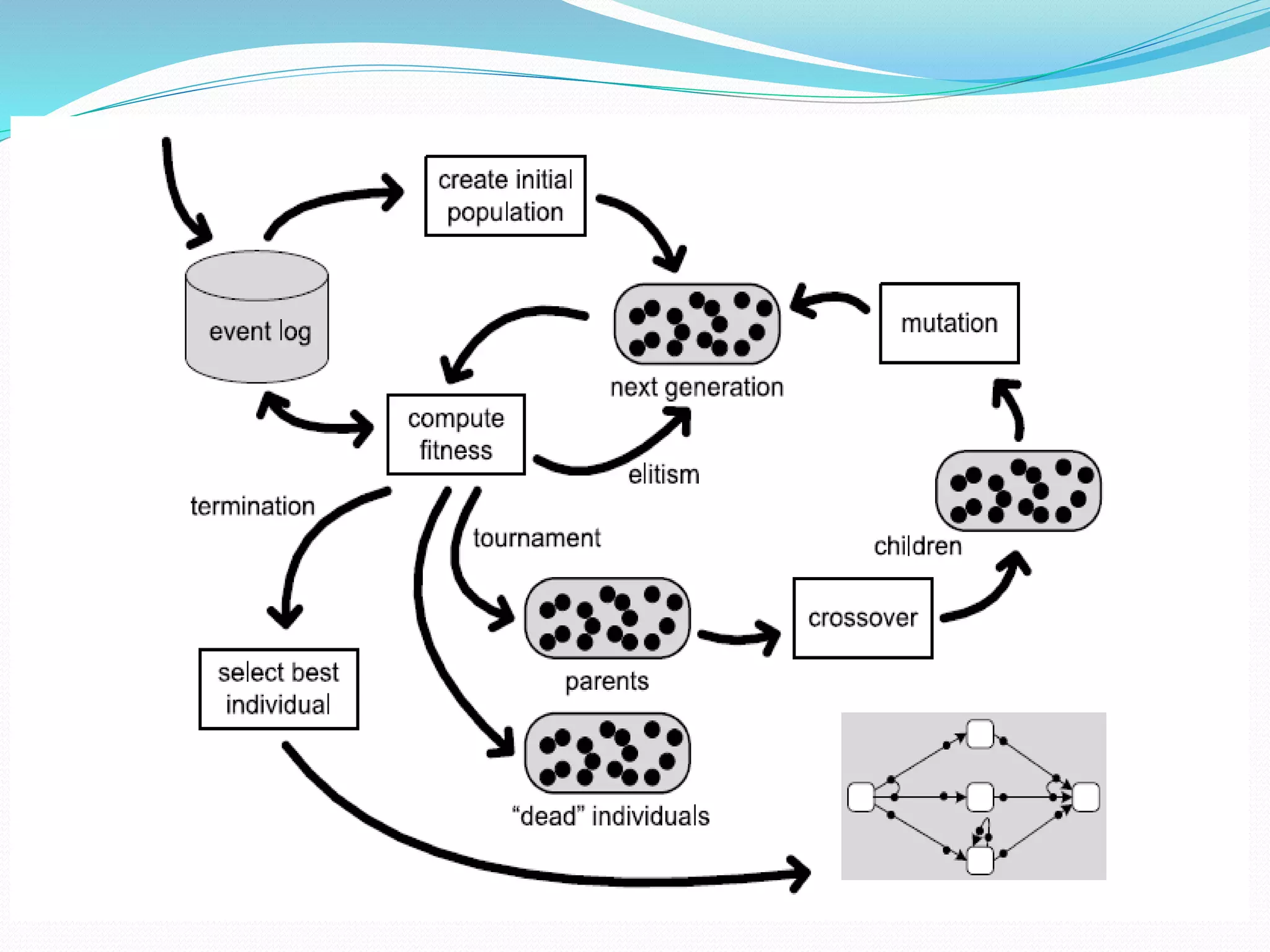




Process mining is a technique that analyzes event logs from information systems to discover business process models. There are four main approaches to process mining: discovery, conformance checking, enhancement, and online control. Discovery techniques take an event log and produce a process model without using any prior information. Conformance checking compares an existing process model to an event log of the same process. Enhancement extends or improves an existing process model using information from an event log. Direct algorithmic approaches, two-phase approaches, computational intelligence approaches, and partial approaches are the main techniques used in process mining.










































![[IJET-V1I4P3] Authors :Mekhala](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i4p3-150728160211-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




































