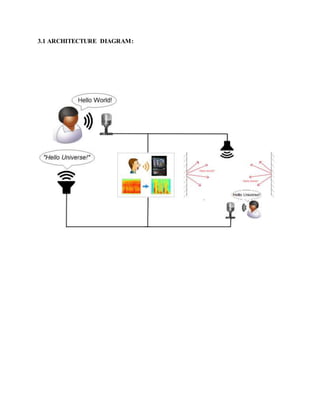
This document discusses using deep neural networks for speech enhancement by finding a mapping between noisy and clean speech signals. It aims to handle a wide range of noises by using a large training dataset with many noise/speech combinations. Techniques like global variance equalization and dropout are used to improve generalization. Experimental results show improvements over MMSE techniques, with the ability to suppress nonstationary noise and avoid musical artifacts. The introduction provides background on speech enhancement, recognition using HMMs and other models, and the role of deep learning advances.


![1.2 INTRODUCTION:
SPEECH ENHANCEMENT:
Speech enhancement aims to improve speech quality by using various algorithms. The
objective of enhancement is improvement in intelligibility and/or overall perceptual quality of
degraded speech signal using audio signal processing techniques. Enhancing of speech degraded
by noise, or noise reduction, is the most important field of speech enhancement, and used for
many applications such as mobile phones, VoIP, teleconferencing systems, speech recognition,
and hearing aids
SPEECH RECOGNITION:
Speech recognition (SR) is the inter-disciplinary sub-field of computational linguistics which
incorporates knowledge and research in the linguistics, computer science, and electrical
engineering fields to develop methodologies and technologies that enables the recognition
and translation of spoken language into text by computers and computerized devices such as
those categorized as Smart Technologies and robotics. It is also known as "automatic speech
recognition" (ASR), "computer speech recognition", or just "speech to text" (STT).
Some SR systems use "training" (also called "enrollment") where an individual speaker reads
text or isolated vocabulary into the system. The system analyzes the person's specific voice and
uses it to fine-tune the recognition of that person's speech, resulting in increased accuracy.
Systems that do not use training are called "speaker independent"[1] systems. Systems that use
training are called "speaker dependent".
Speech recognition applications include voice user interfaces such as voice dialing (e.g. "Call
home"), call routing (e.g. "I would like to make a collect call"), domotic appliance control,
search (e.g. find a podcast where particular words were spoken), simple data entry (e.g., entering
a credit card number), preparation of structured documents (e.g. a radiology report), speech-to-](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-2-320.jpg)



![or even if there were accelerations and deceleration during the course of one observation. DTW
has been applied to video, audio, and graphics – indeed, any data that can be turned into a linear
representation can be analyzed with DTW.
A well-known application has been automatic speech recognition, to cope with different
speaking speeds. In general, it is a method that allows a computer to find an optimal match
between two given sequences (e.g., time series) with certain restrictions. That is, the sequences
are "warped" non-linearly to match each other. This sequence alignment method is often used in
the context of hidden Markov models.
NEURAL NETWORKS
Neural networks emerged as an attractive acoustic modeling approach in ASR in the late 1980s.
Since then, neural networks have been used in many aspects of speech recognition such as
phoneme classification, isolated word recognition, and speaker adaptation.
In contrast to HMMs, neural networks make no assumptions about feature statistical properties
and have several qualities making them attractive recognition models for speech recognition.
When used to estimate the probabilities of a speech feature segment, neural networks allow
discriminative training in a natural and efficient manner. Few assumptions on the statistics of
input features are made with neural networks. However, in spite of their effectiveness in
classifying short-time units such as individual phones and isolated words, neural networks are
rarely successful for continuous recognition tasks, largely because of their lack of ability to
model temporal dependencies.
However, recently Recurrent Neural Networks(RNN's) and Time Delay Neural
Networks(TDNN's)[44] have been used which have been shown to be able to identify latent
temporal dependencies and use this information to perform the task of speech recognition. This
however enormously increases the computational cost involved and hence makes the process of
speech recognition slower. A lot of research is still going on in this field to ensure that TDNN's
and RNN's can be used in a more computationally affordable way to improve the Speech
Recognition Accuracy immensely.](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-6-320.jpg)
![Deep Neural Networks and Denoising Autoencoders[45] are also being experimented with to
tackle this problem in an effective manner.
Due to the inability of traditional Neural Networks to model temporal dependencies, an
alternative approach is to use neural networks as a pre-processing e.g. feature transformation,](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-7-320.jpg)
![DEEP NEURAL NETWORKS AND OTHER DEEP LEARNING MODELS
A deep neural network (DNN) is an artificial neural network with multiple hidden layers of units
between the input and output layers. Similar to shallow neural networks, DNNs can model
complex non-linear relationships. DNN architectures generate compositional models, where
extra layers enable composition of features from lower layers, giving a huge learning capacity
and thus the potential of modeling complex patterns of speech data.[47] The DNN is the most
popular type of deep learning architectures successfully used as an acoustic model for speech
recognition since 2010.
The success of DNNs in large vocabulary speech recognition occurred in 2010 by industrial
researchers, in collaboration with academic researchers, where large output layers of the DNN
based on context dependent HMM states constructed by decision trees were adopted. See
comprehensive reviews of this development and of the state of the art as of October 2014 in the
recent Springer book from Microsoft Research. See also the related background of automatic
speech recognition and the impact of various machine learning paradigms including notably deep
learning in a recent overview article.
One fundamental principle of deep learning is to do away with hand-crafted feature
engineering and to use raw features. This principle was first explored successfully in the
architecture of deep autoencoder on the "raw" spectrogram or linear filter-bank features, showing
its superiority over the Mel-Cepstral features which contain a few stages of fixed transformation
from spectrograms. The true "raw" features of speech, waveforms, have more recently been
shown to produce excellent larger-scale speech recognition results.
Since the initial successful debut of DNNs for speech recognition around 2009-2011, there have
been huge new progresses made. This progress (as well as future directions) has been
summarized into the following eight major areas:](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-8-320.jpg)




![helicopter. There has also been much useful work in Canada. Results have been encouraging,
and voice applications have included: control of communication radios, setting
of navigation systems, and control of an automated target handover system.
As in fighter applications, the overriding issue for voice in helicopters is the impact on pilot
effectiveness. Encouraging results are reported for the AVRADA tests, although these represent
only a feasibility demonstration in a test environment. Much remains to be done both in speech
recognition and in overall speech technology in order to consistently achieve performance
improvements in operational settings.
PROBLEMS:
In recent years, single-channel speech enhancement has attracted a considerable amount of
research attention because of the growing challenges in many important real-world applications,
including mobile speech communication, hearing aids design and robust speech recognition. The
goal of speech enhancement is to improve the intelligibility and quality of a noisy speech signal
degraded in adverse conditions. However, the performance of speech enhancement in real
acoustic environments is not always satisfactory. Numerous speech enhancement methods were
developed over the past several decades. Spectral subtraction subtracts an estimate of the short-
term noise spectrum to produce an estimated spectrum of the clean speech. In the iterative wiener
filtering was presented using an all-pole model.
A common problem usually encountered in these conventional methods is that the resulting
enhanced speech often suffers from an annoying artifact called “musical noise”. Another notable
work was the minimum mean-square error (MMSE) estimator introduced by Ephraim and Malah
[6]; their MMSE log-spectral amplitude estimator could result in much lower residual noise
without further affecting the speech quality. An optimally-modified log-spectral amplitude (OM-
LSA) speech estimator and a minima controlled recursive averaging (MCRA) noise estimation
approach were also presented in although these traditional MMSE-based methods are able to
yield lower musical noise (e.g., [10], [11]), a trade-off in reducing speech distortion and residual](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-13-320.jpg)



































![CHAPTER 8
8.1 CONCLUSION AND FUTURE:
In this paper, a DNN-based framework for speech enhancement is proposed. Among the various
DNN configurations, a large training set is crucial to learn the rich structure of the mapping
function between noisy and clean speech features. It was found that the application of more
acoustic context information improves the system performance and makes the enhanced speech
less discontinuous. Moreover, multi-condition training with many kinds of noise types can
achieve a good generalization capability to unseen noise environments. By doing so, the
proposed DNN framework is also powerful to cope with non-stationary noises in real-world
environments.
An over-smoothing problem in speech quality was found in the MMSE-optimized DNNs and
one proposed post-processing technique, called GV equalization, was effective in brightening the
formant spectra of the enhanced speech signals. Two improved training techniques were further
adopted to reduce the residual noise and increase the performance. Compared with the
LogMMSE method, significant improvements were achieved across different unseen noise
conditions. Another interesting observation was that the proposed DNN-based speech
enhancement system is quite effective for dealing with real-world noisy speech in different
languages and across different recording conditions not observed during DNN training.
In future studies, we would increase the speech diversity by first incorporating clean speech data
from a rich collection of materials covering more languages and speakers. Second, there are
many factors in designing the training set. We would utilize principles in experimental design
[54], [55] for multi-factor analysis to alleviate the requirement of a huge amount of training data
and still maintain a good generalization capability of the DNN model. Third, some other
features, such as Gammatone filterbank power spectra [50], Multi-resolution cochleagram
feature [56], will be adopted as in [50] to enrich the input information to DNNs. Finally, a
dynamic noise adaptation scheme will also be investigated for the purpose of improving tracking
of non-stationary noises.](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-52-320.jpg)
![CHAPTER 9
9.1 REFERENCES:
[1] L.-H. Chen, Z.-H. Ling, L.-J. Liu, and L.-R. Dai, “Voice conversion using deep neural
networks with layer-wise generative training,” IEEE/ACM Trans. Audio, Speech, Lang.
Process., vol. 22, no. 12, pp. 1859–1872, Dec. 2014.
[2] Z.-H. Ling, L. Deng, and D. Yu, “Modeling spectral envelopes using restricted Boltzmann
machines and deep belief networks for statistical parametric speech synthesis,” IEEE Trans.
Audio, Speech, Lang. Process., vol. 21, no. 10, pp. 2129–2139, Oct. 2013.
[3] B.-Y. Xia and C.-C. Bao, “Speech enhancement with weighted denoising Auto-Encoder,” in
Proc. Interspeech, 2013, pp. 3444–3448. [23] X.-G. Lu, Y. Tsao, S. Matsuda, and C. Hori,
“Speech enhancement based on deep denoising Auto-Encoder,” in Proc. Interspeech, 2013, pp.
436–440.
[4] A. L. Maas, Q. V. Le, T. M. O’Neil, O. Vinyals, P. Nguyen, and A. Y. Ng, “Recurrent neural
networks for noise reduction in robust ASR,” in Proc. Interspeech, 2012, pp. 22–25.
[5] M. Wollmer, Z. Zhang, F. Weninger, B. Schuller, and G. Rigoll, “Feature enhancement by
bidirectional LSTM networks for conversational speech recognition in highly non-stationary
noise,” in Proc. ICASSP, 2013, pp. 6822–6826.
[6] H. Christensen, J. Barker, N. Ma, and P. D. Green, “The CHiME corpus: A resource and a
challenge for computational hearing in multisource environments,” in Proc. Interspeech, 2010,
pp. 1918–1921.
[7] Y. X. Wang and D. L. Wang, “Towards scaling up classification-based speech separation,”
IEEE Trans. Audio, Speech, Lang. Process., vol. 21, no. 7, pp. 1381–1390, Jul. 2013.](https://image.slidesharecdn.com/helana-160509062407/85/speech-enhancement-53-320.jpg)



































































