Downloaded 31 times




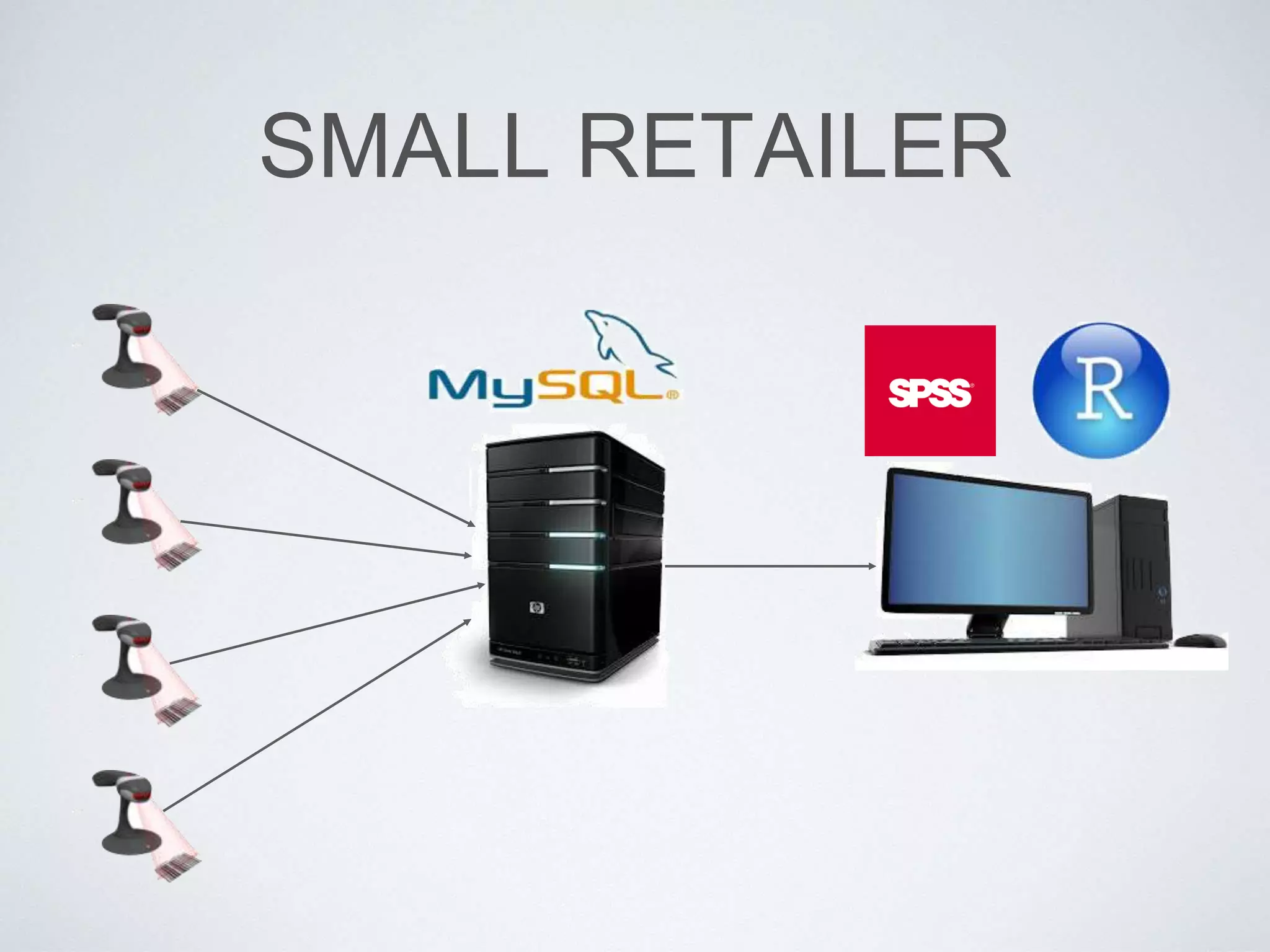
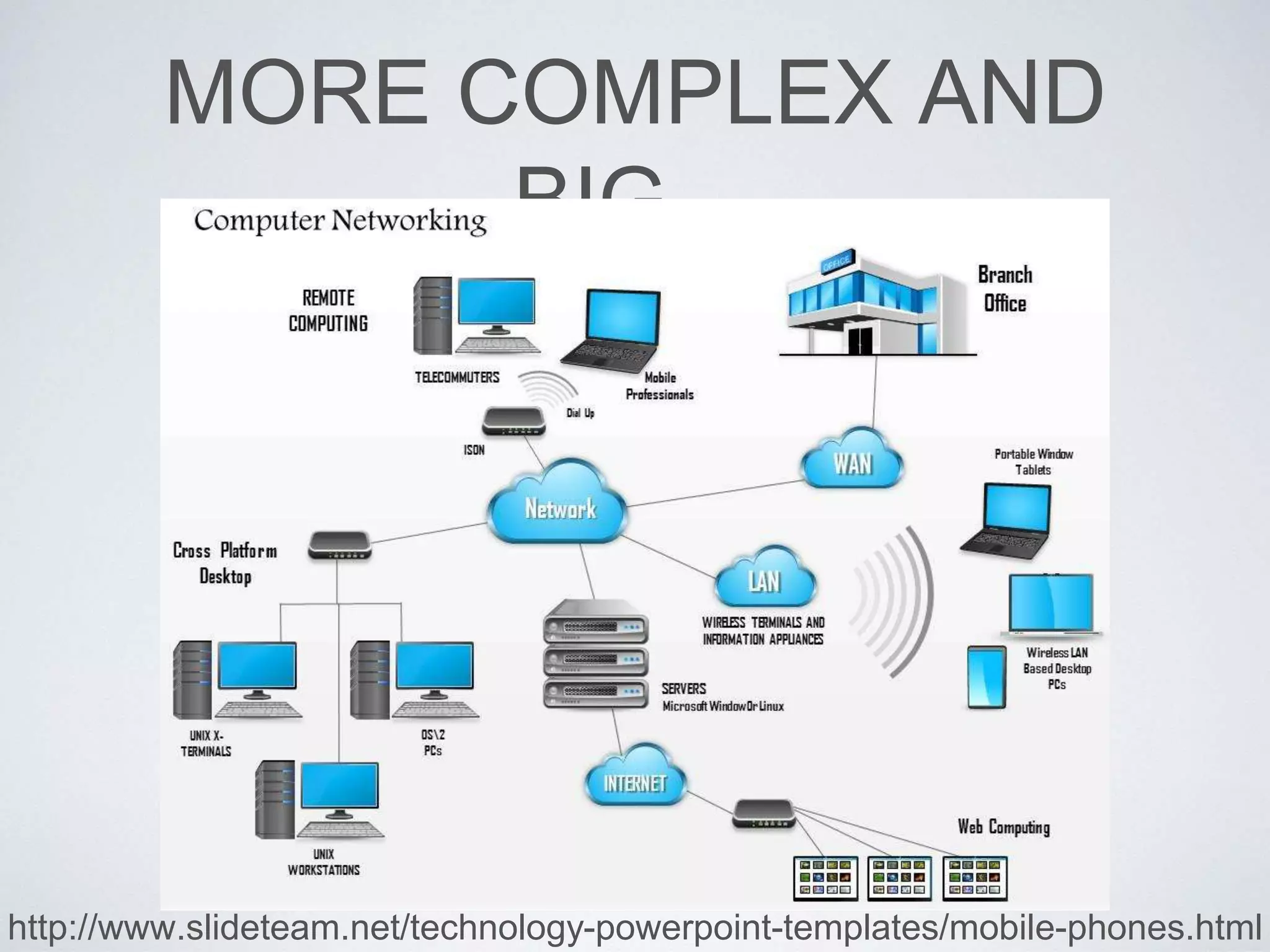
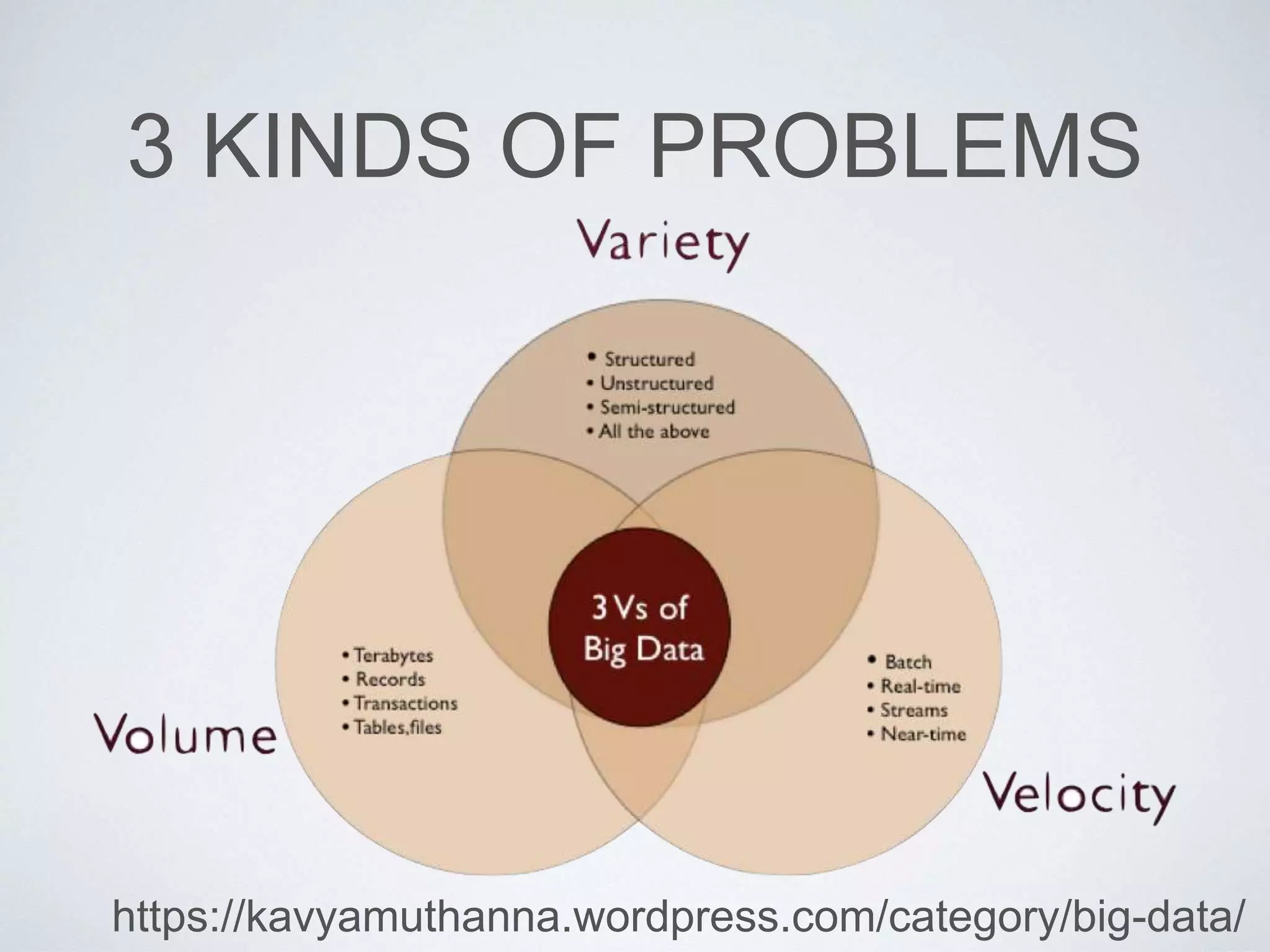









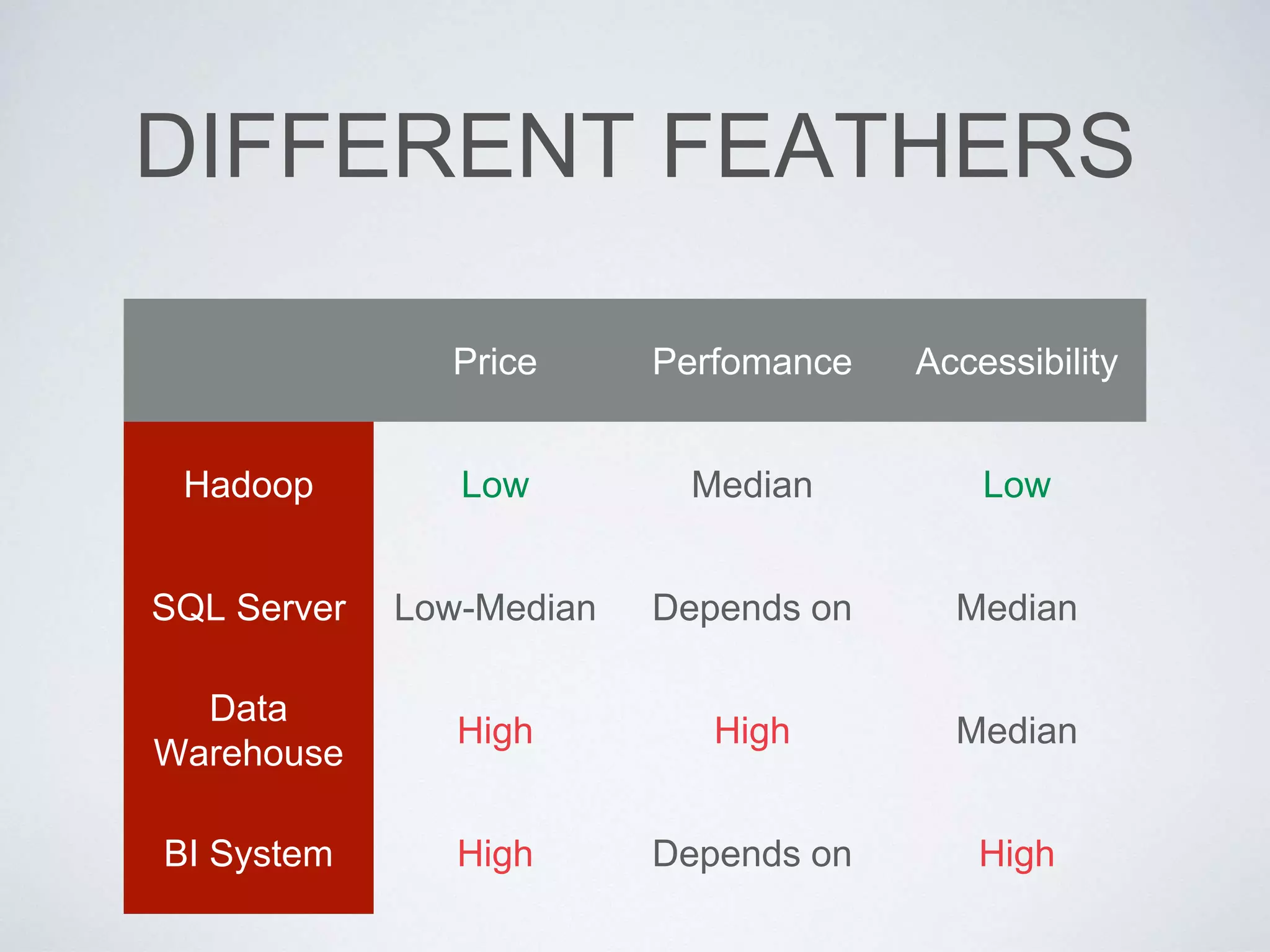
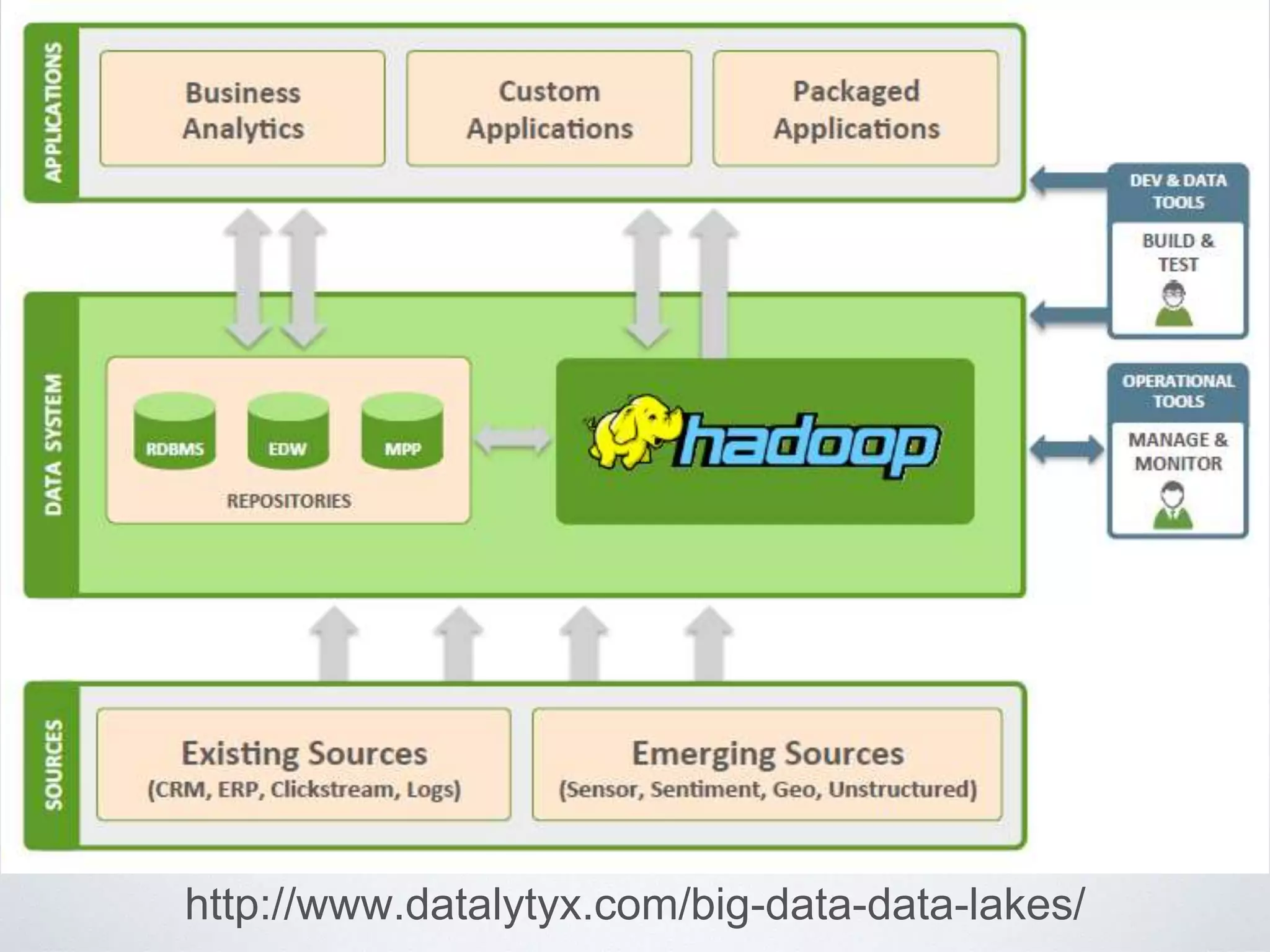
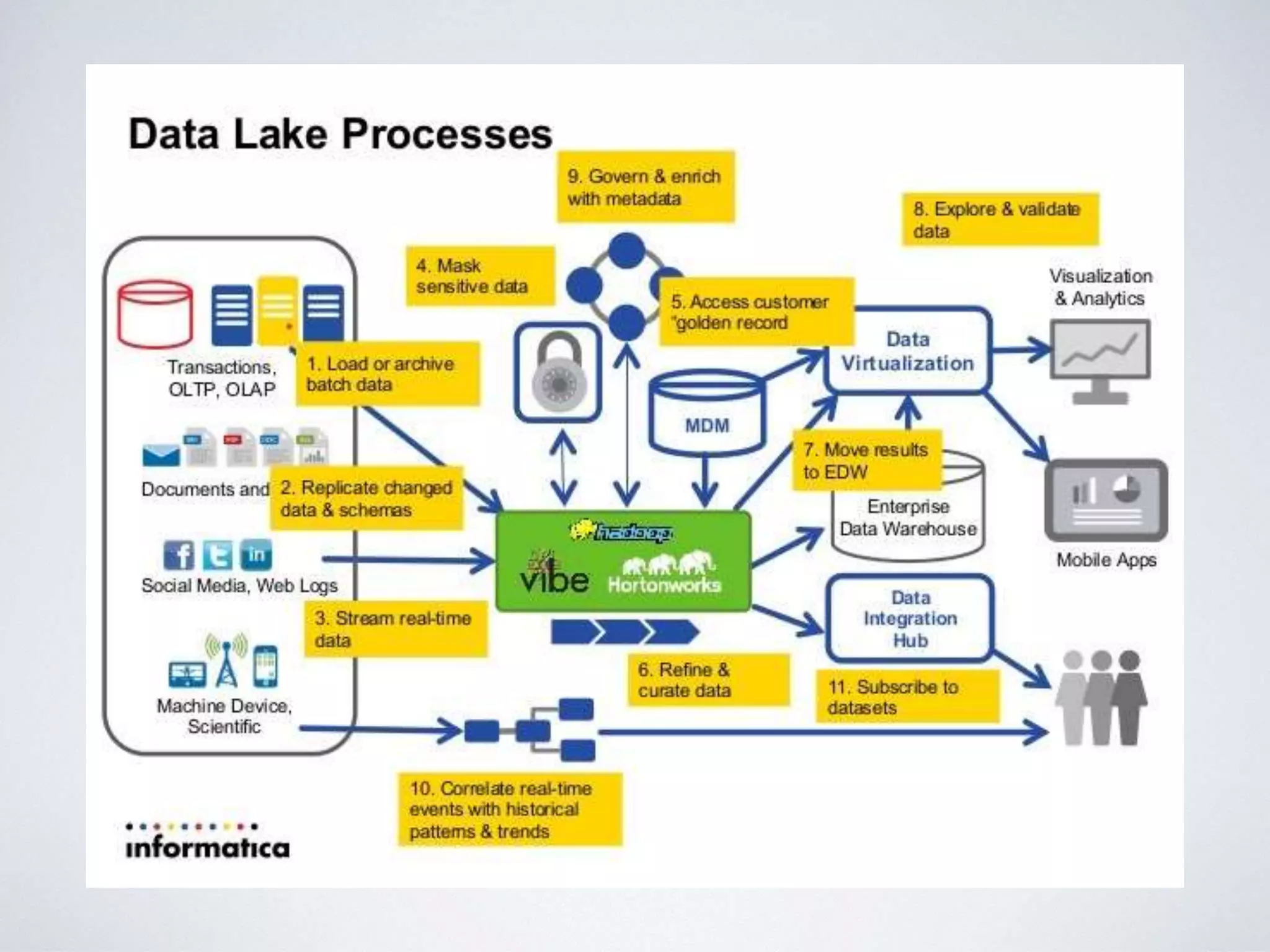

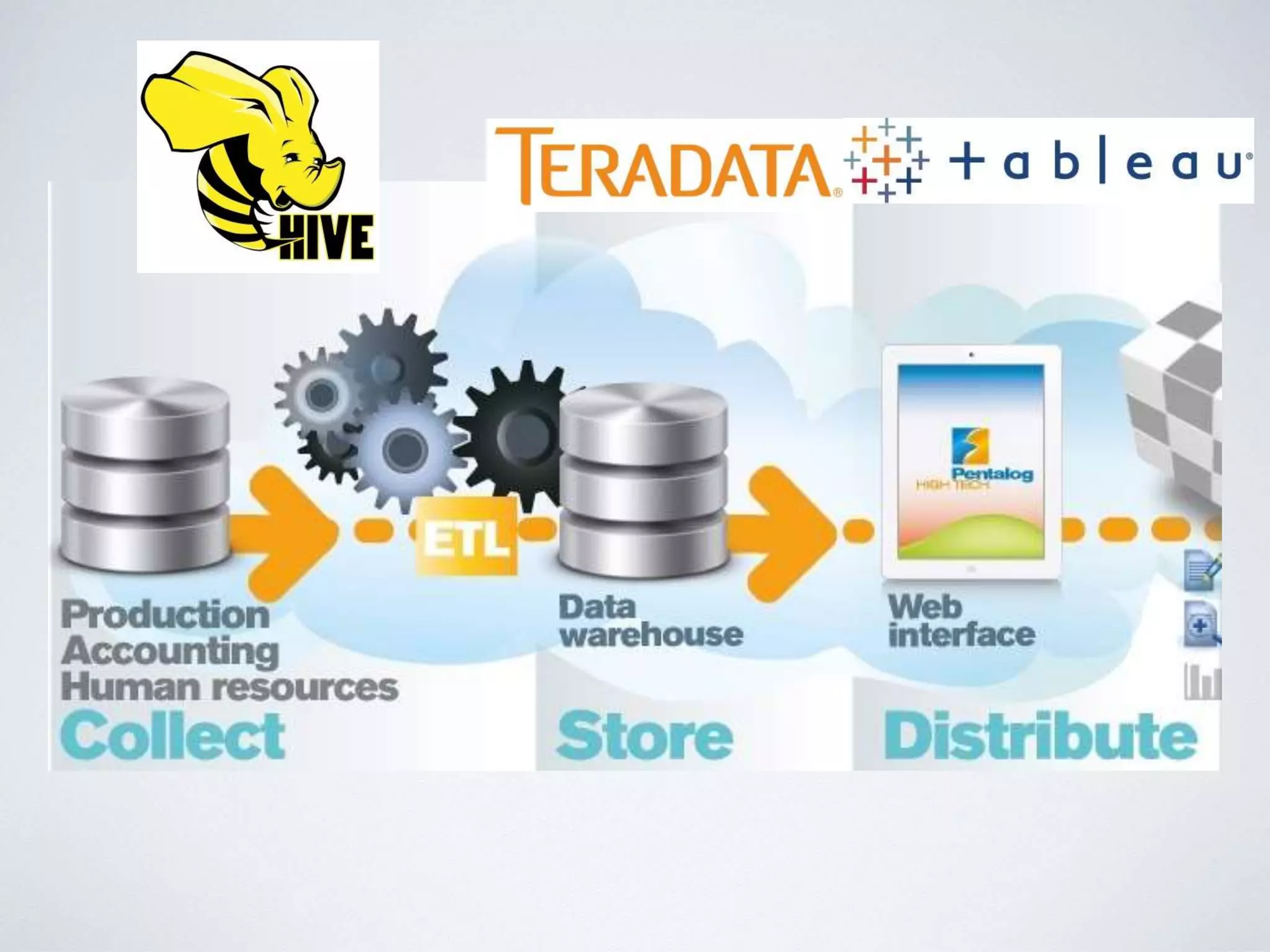

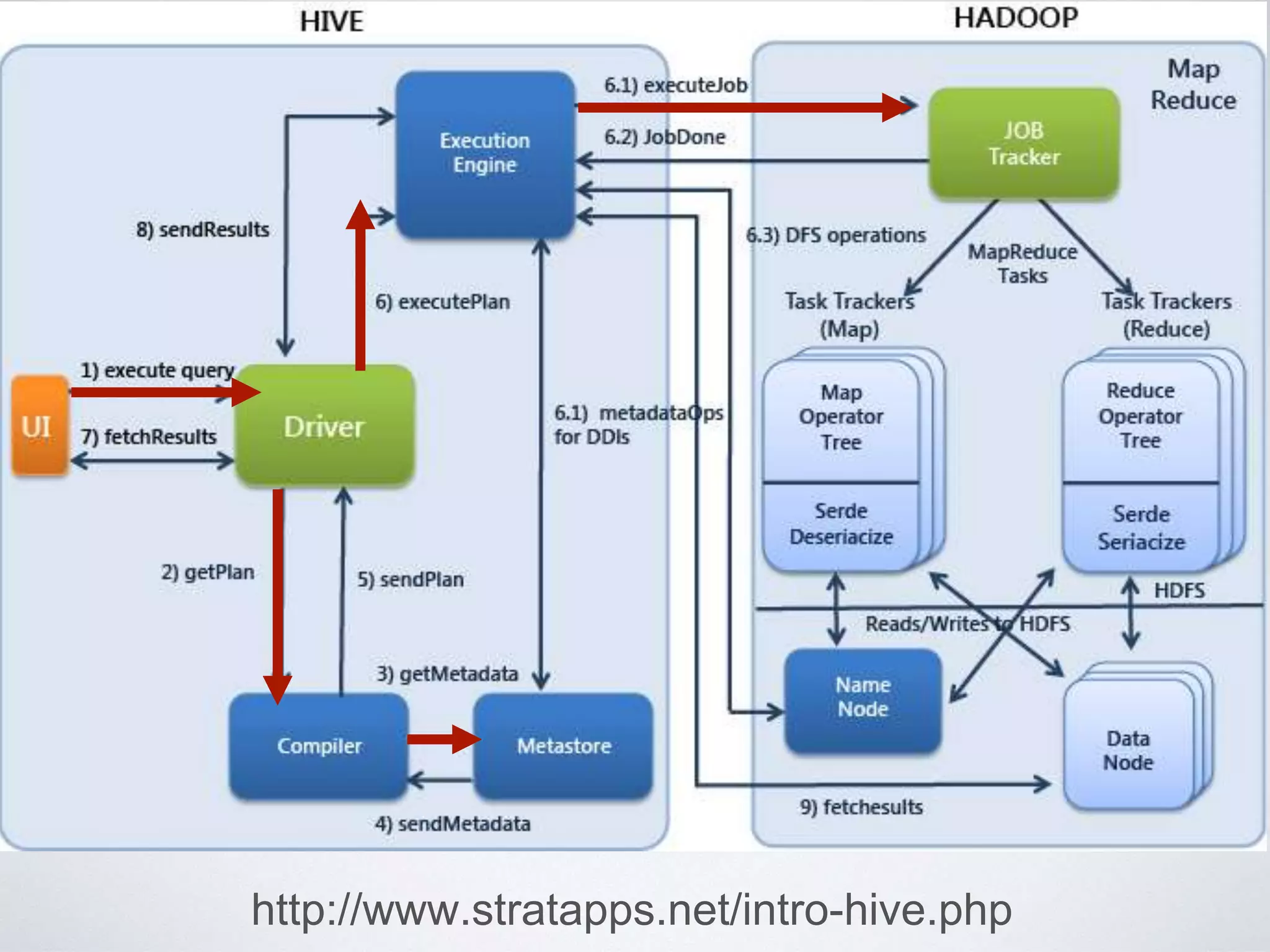
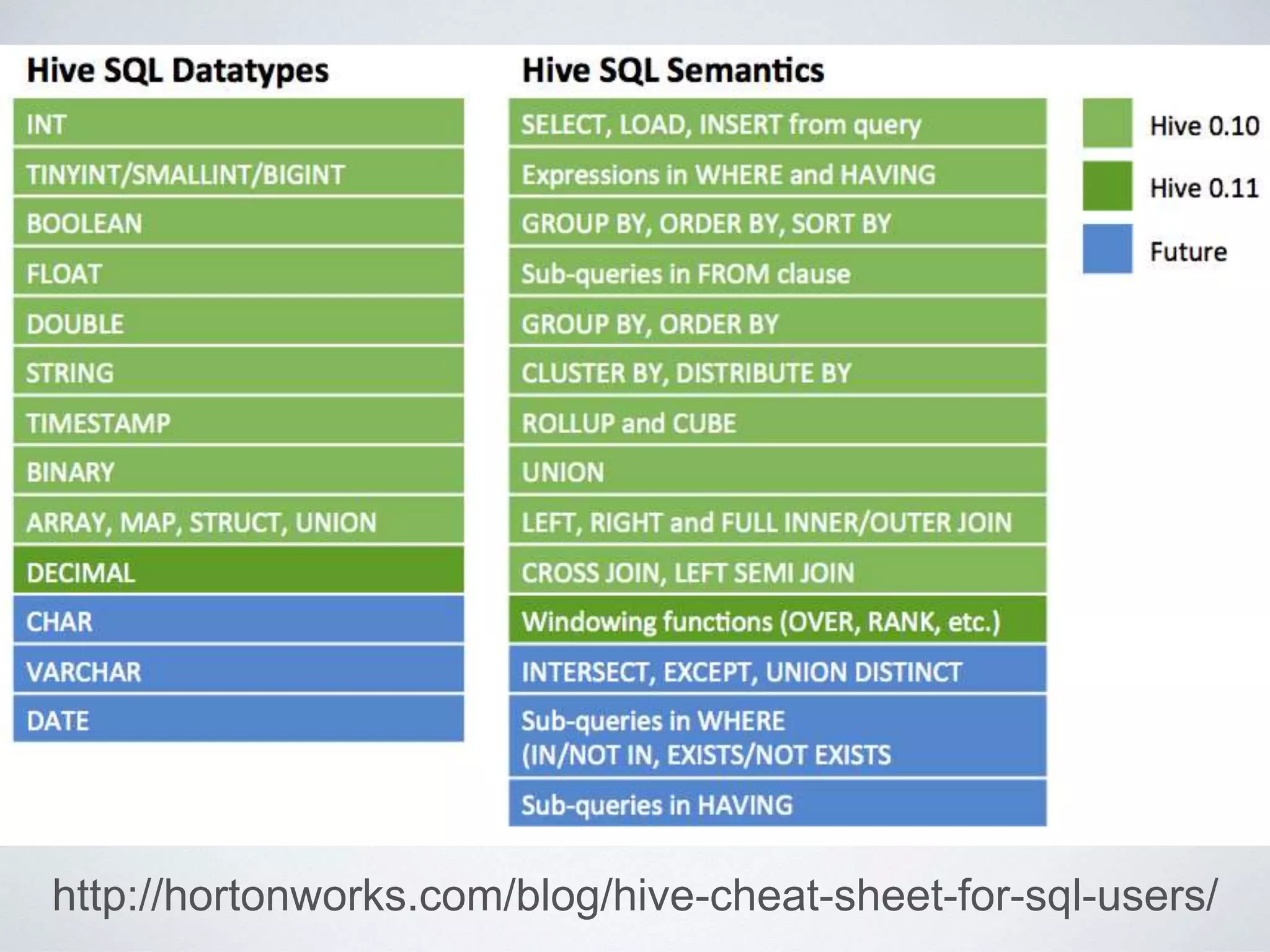
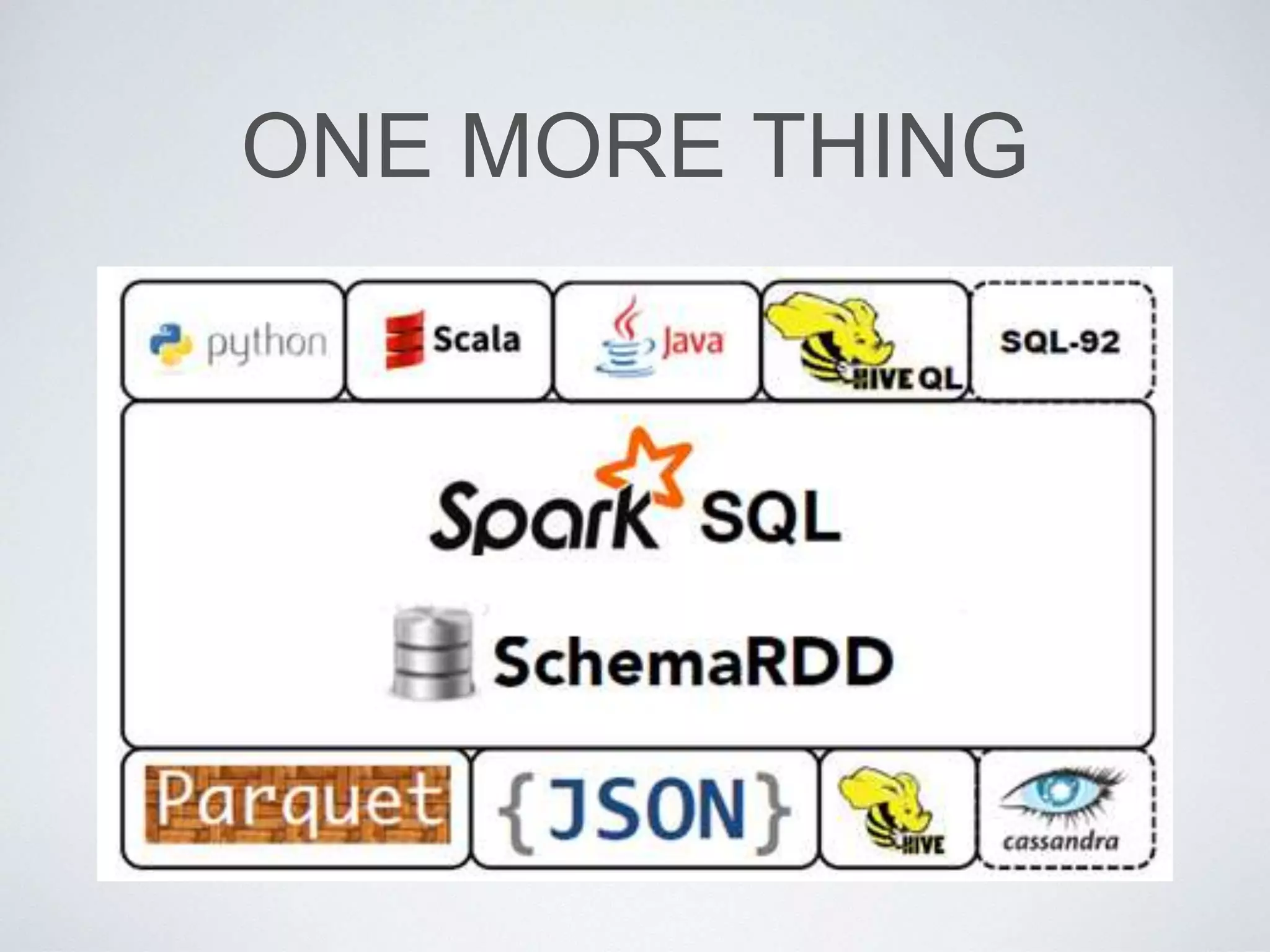

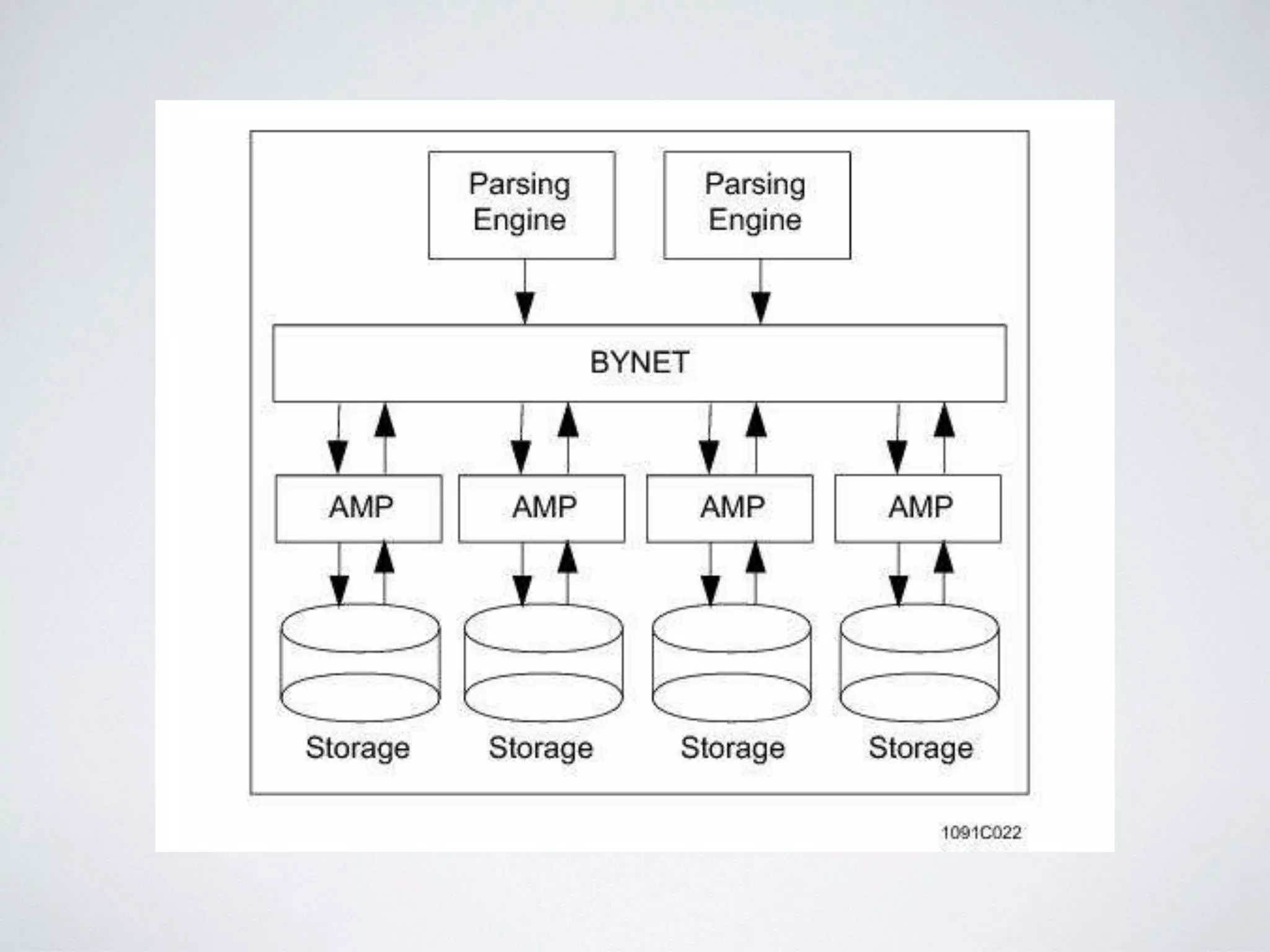
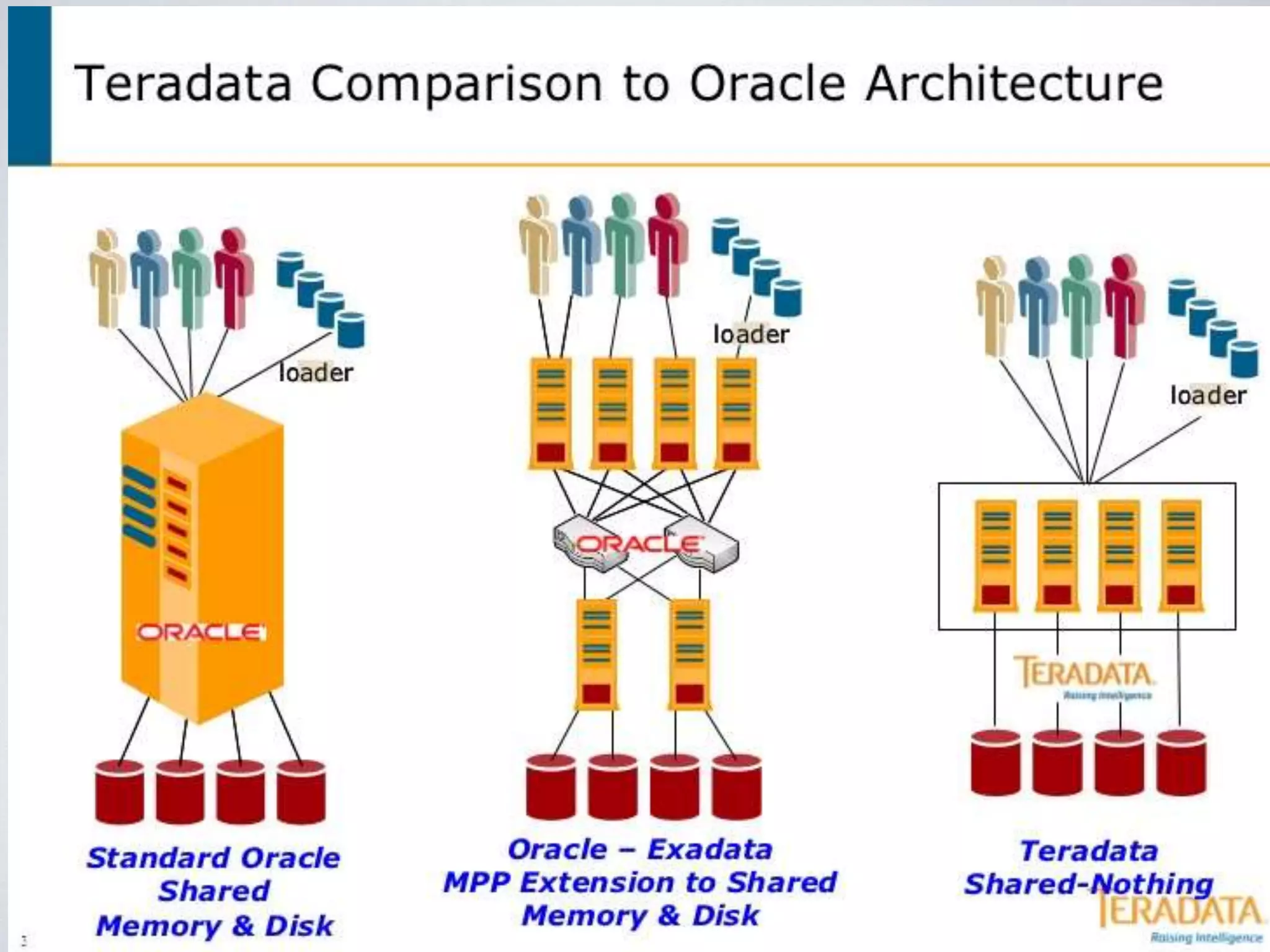
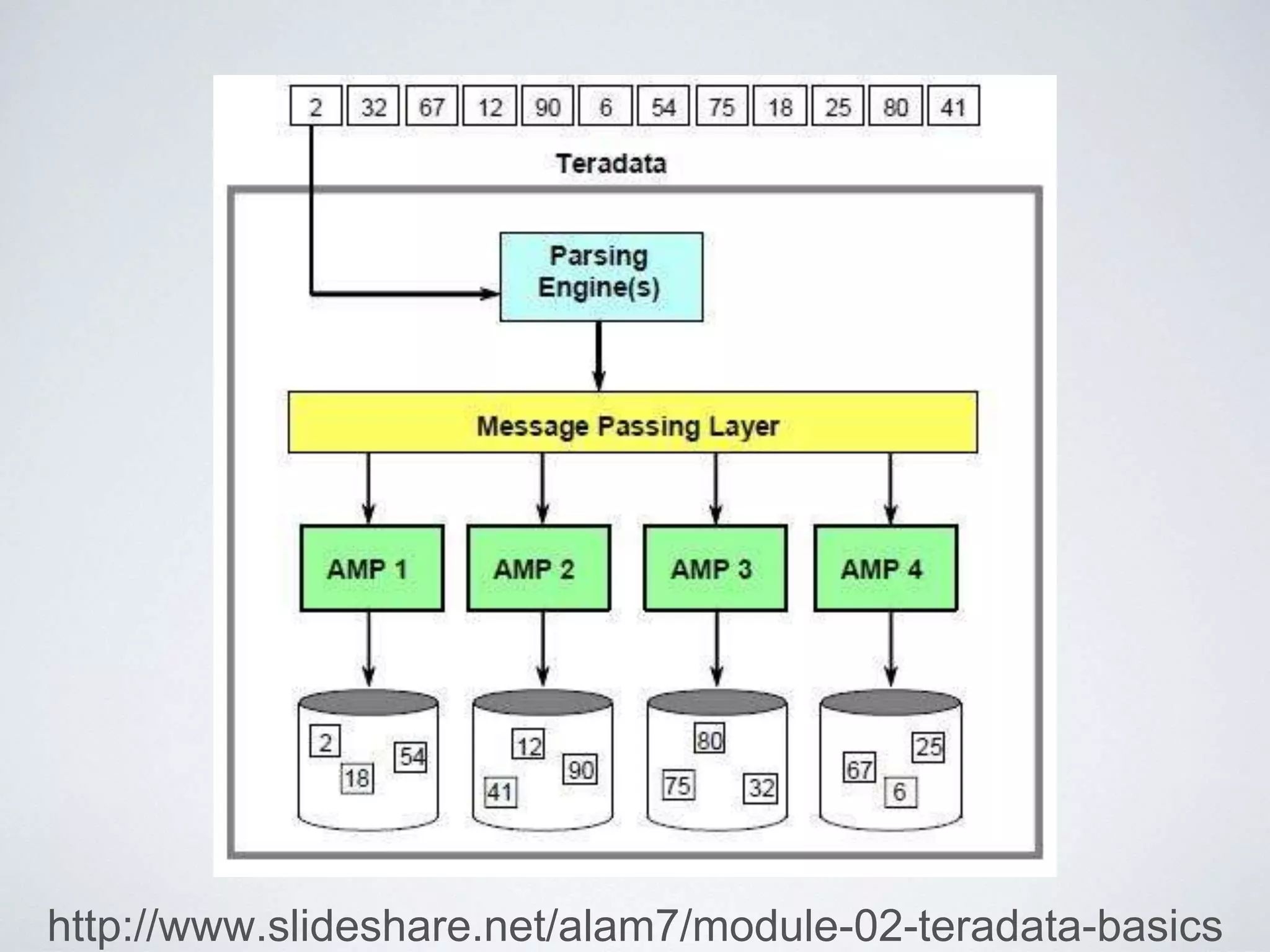
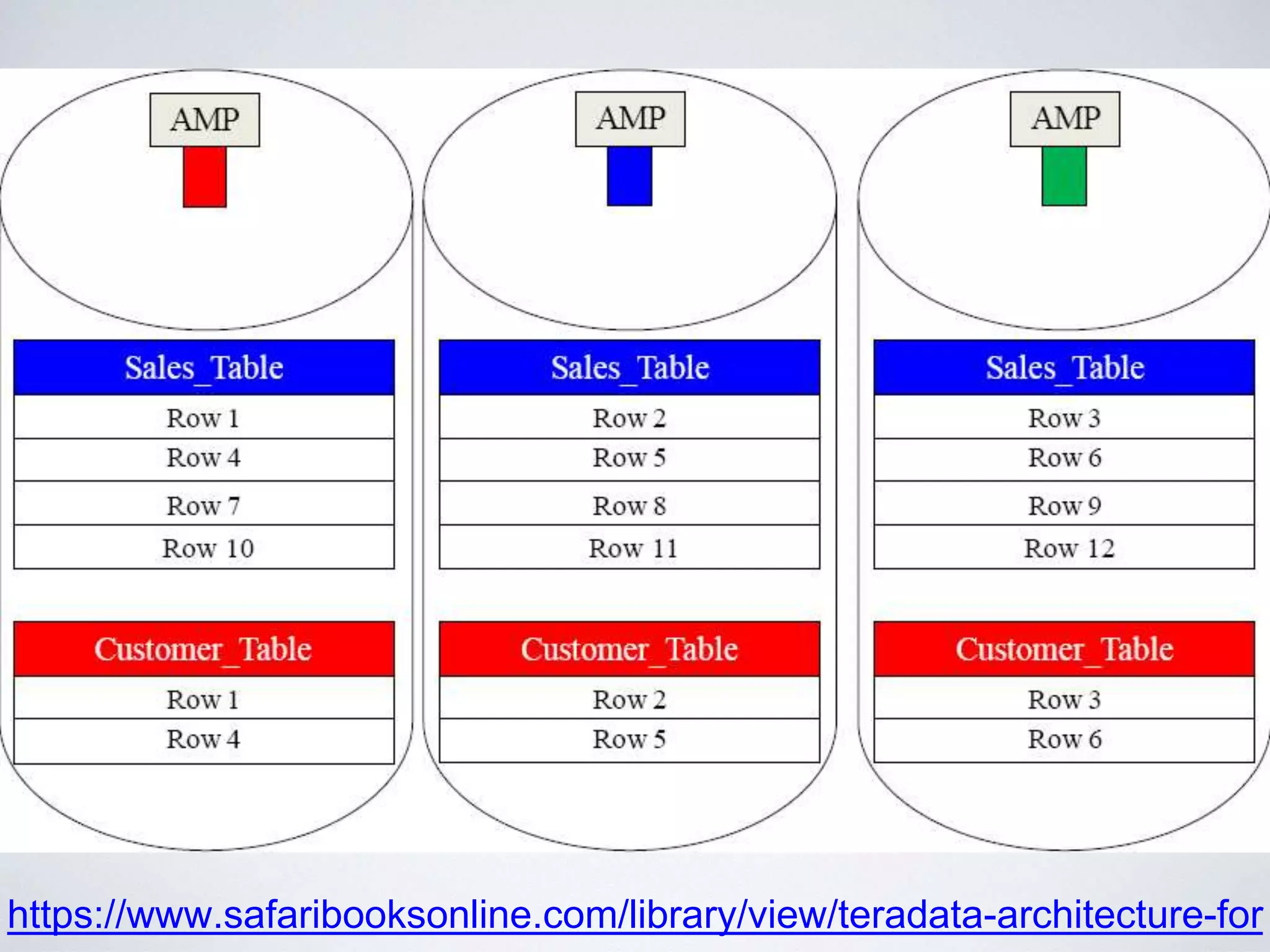

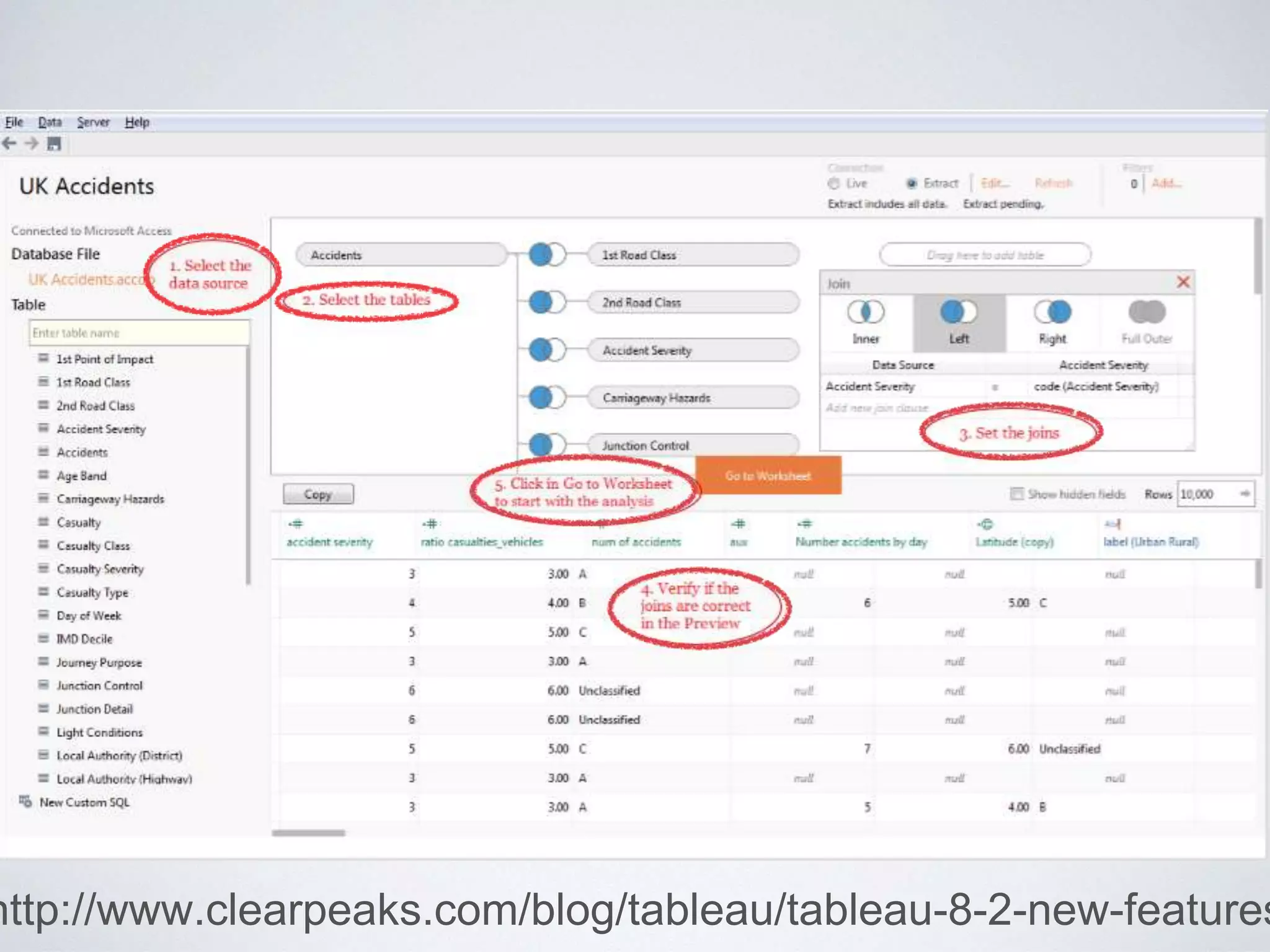
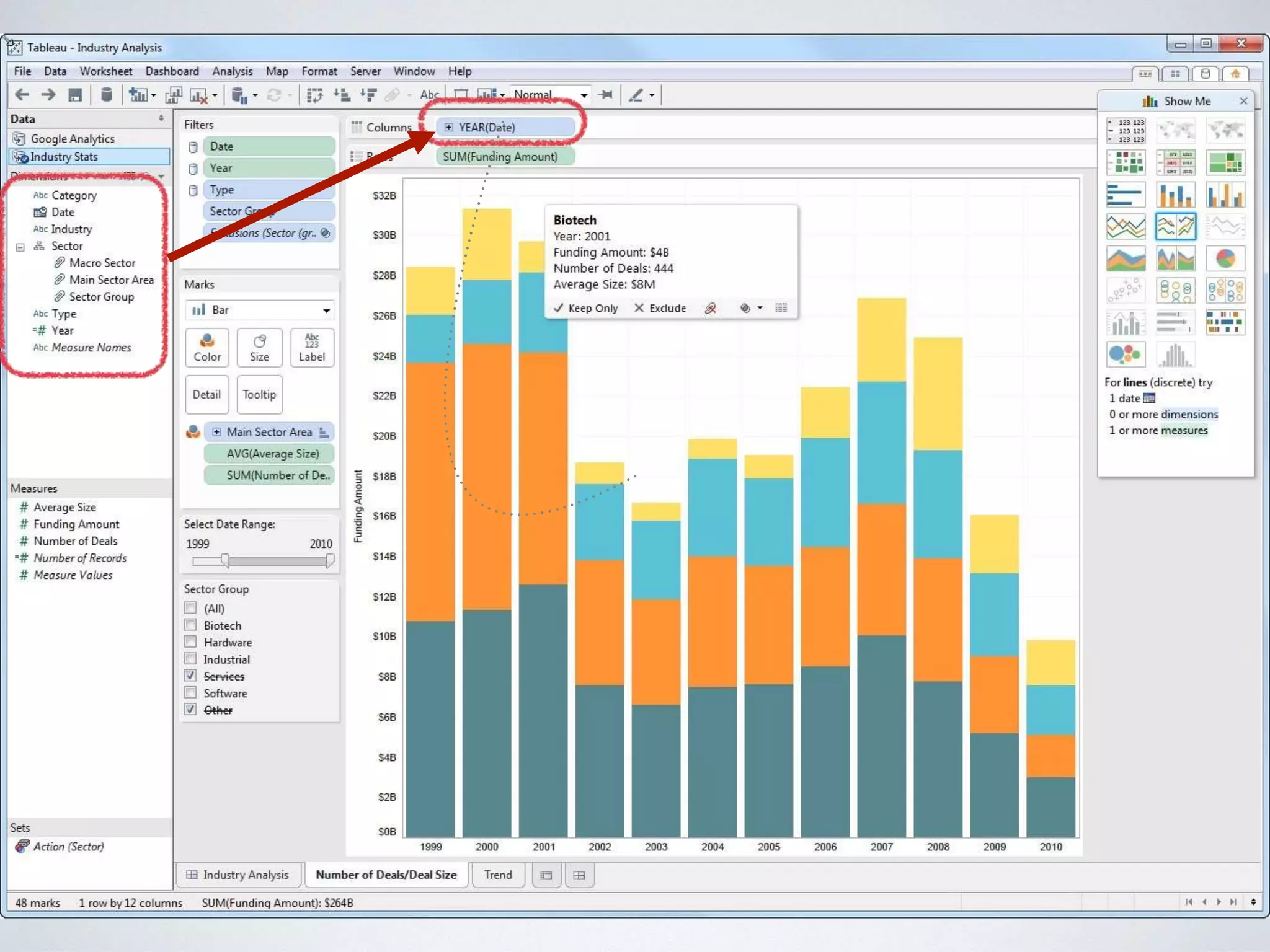
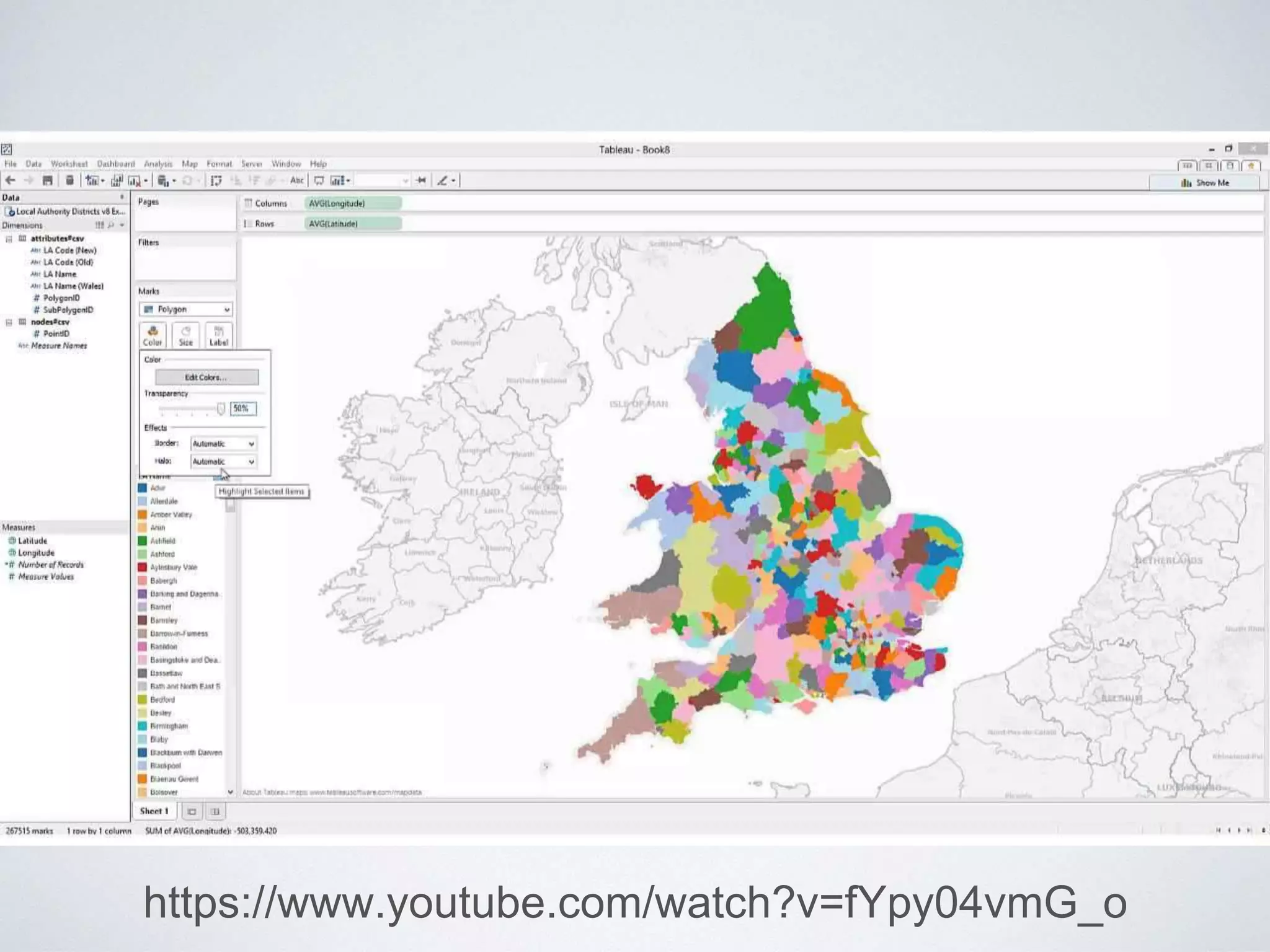
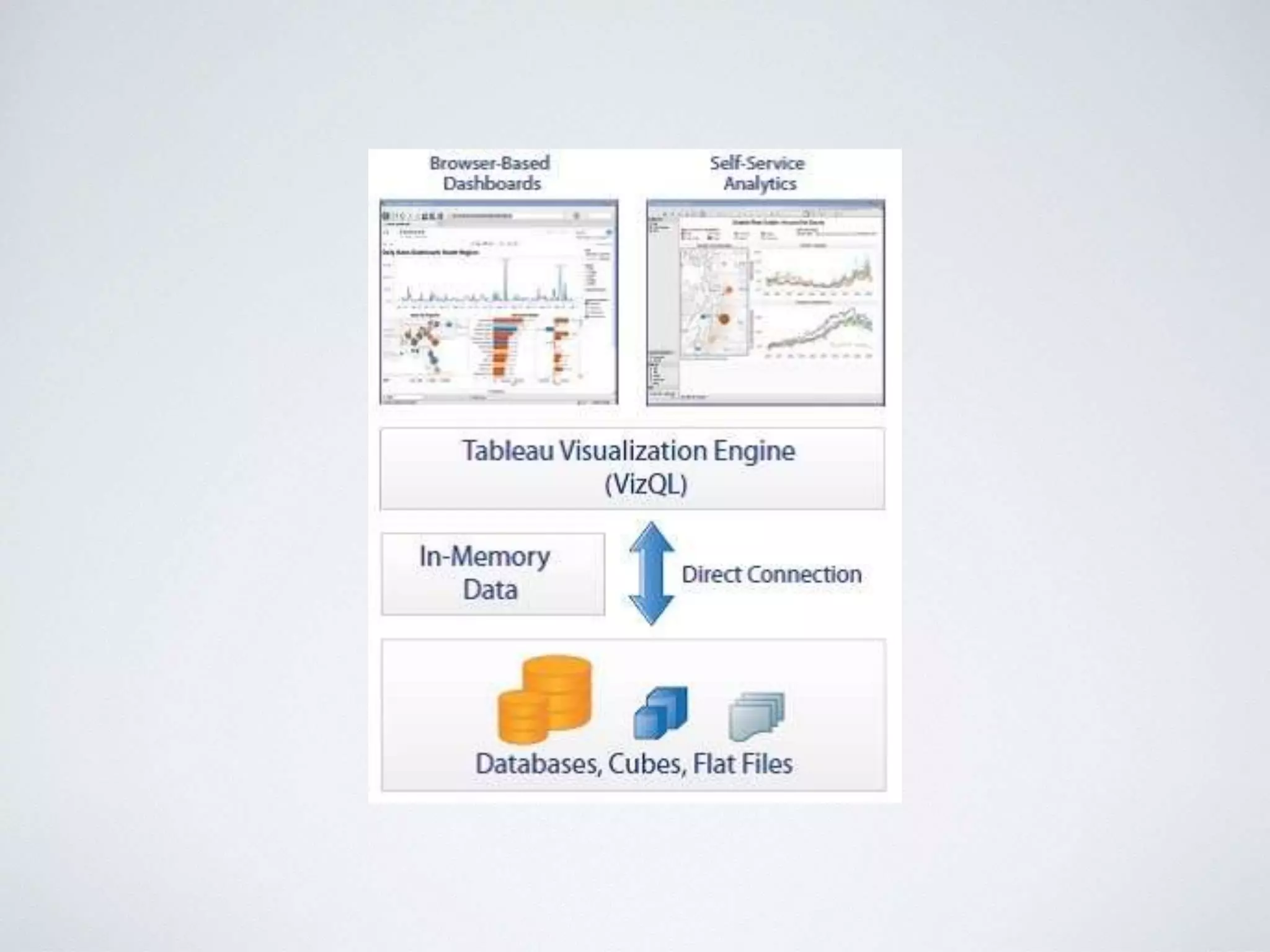
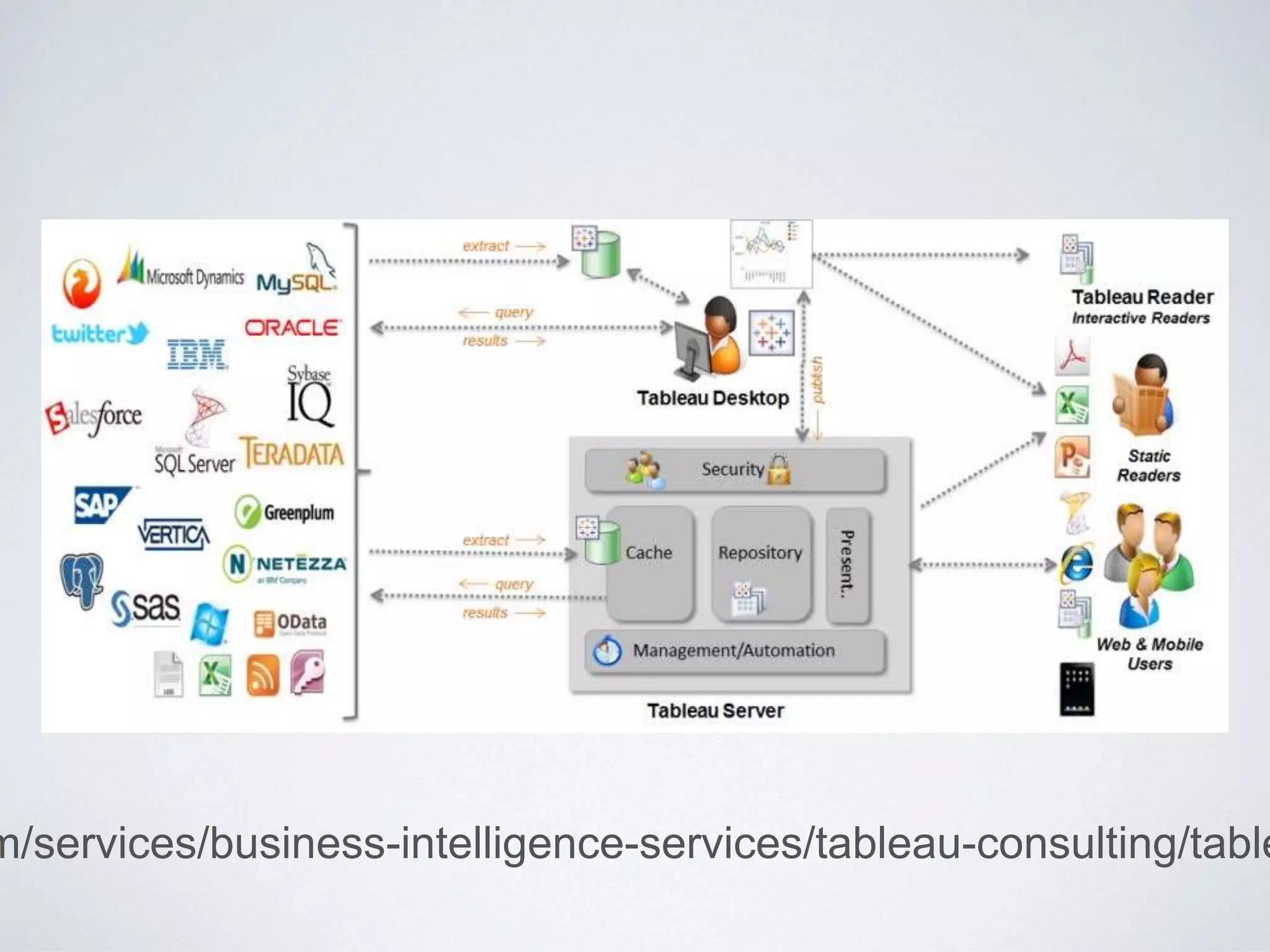

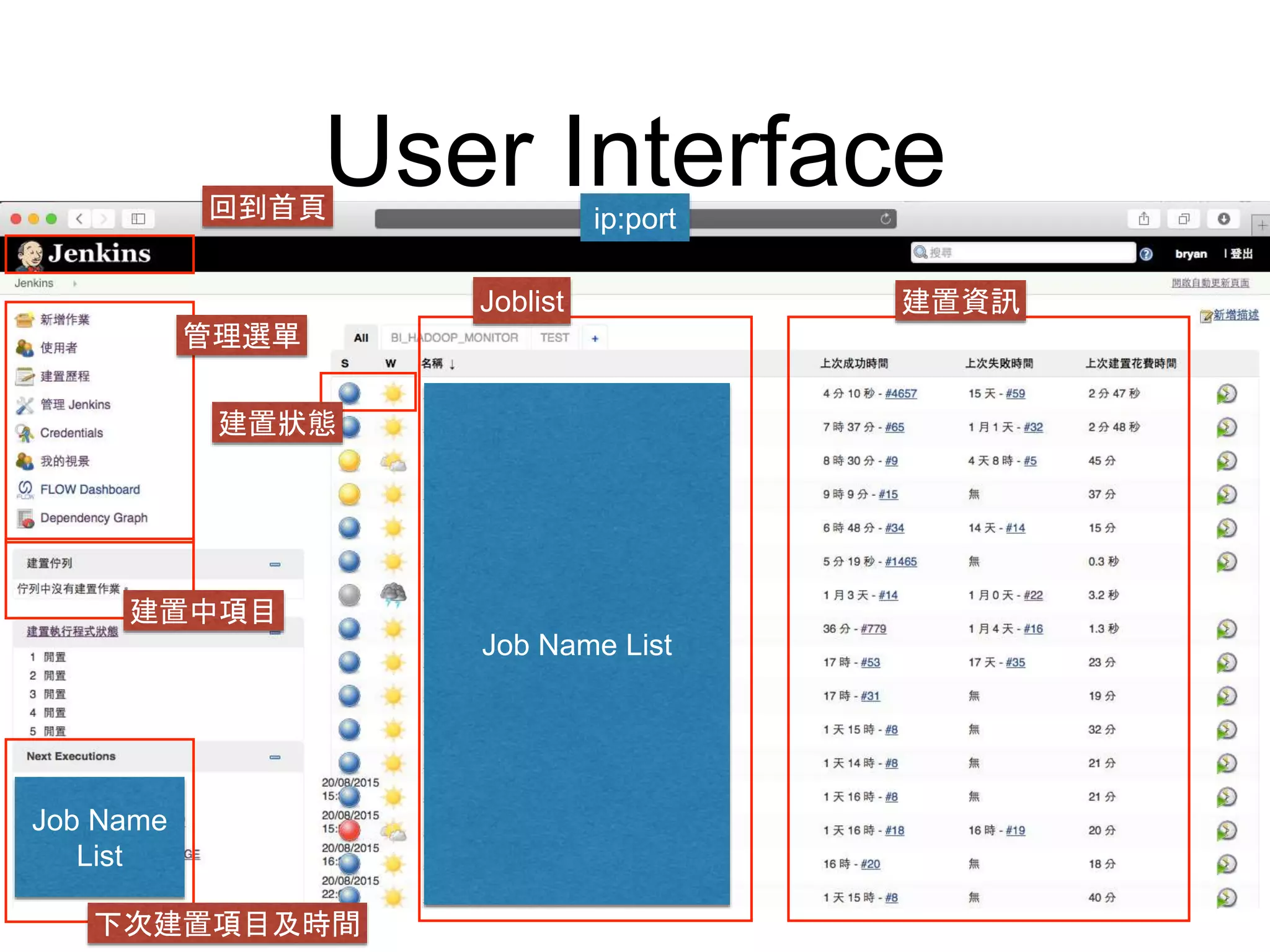

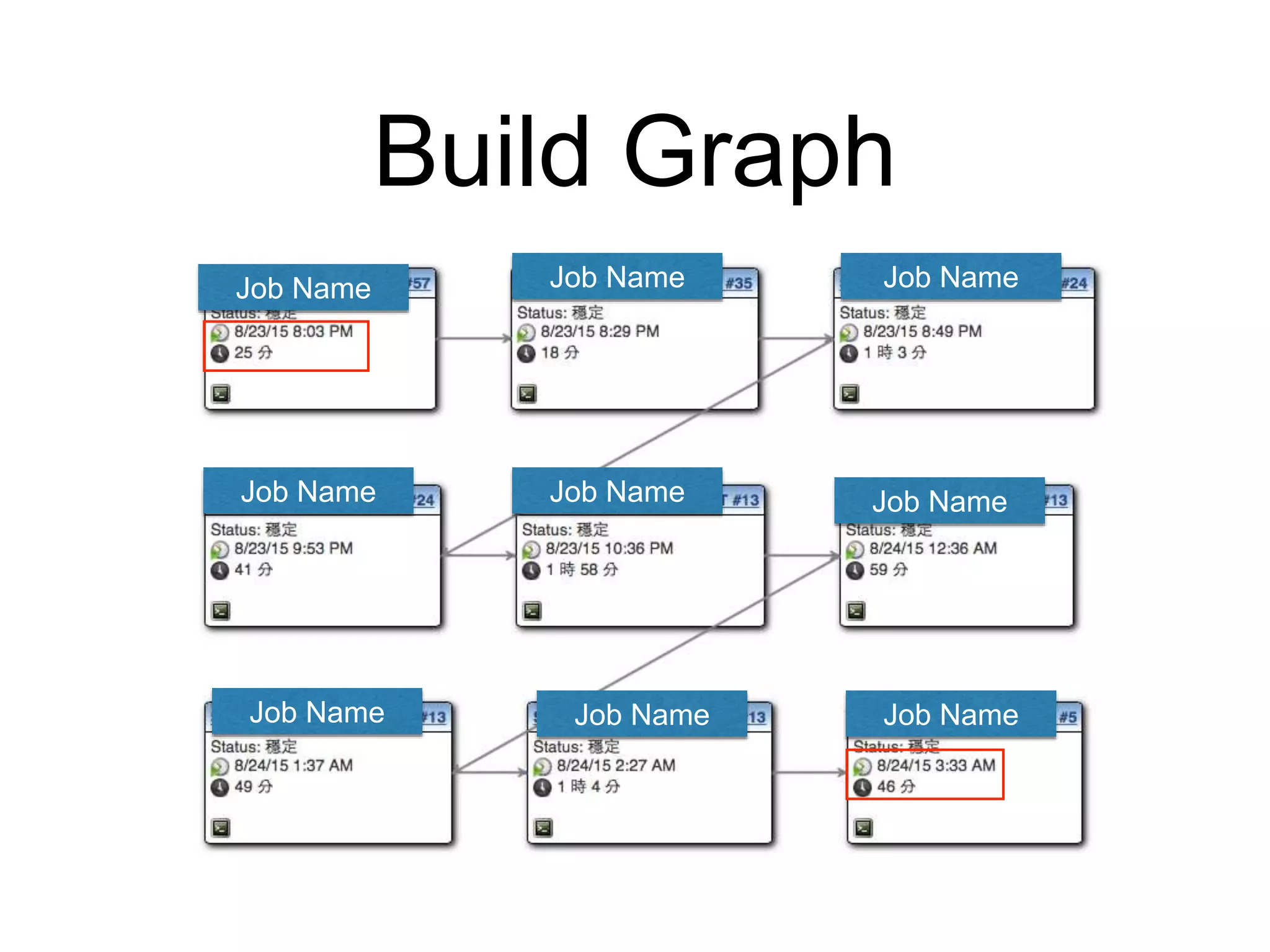

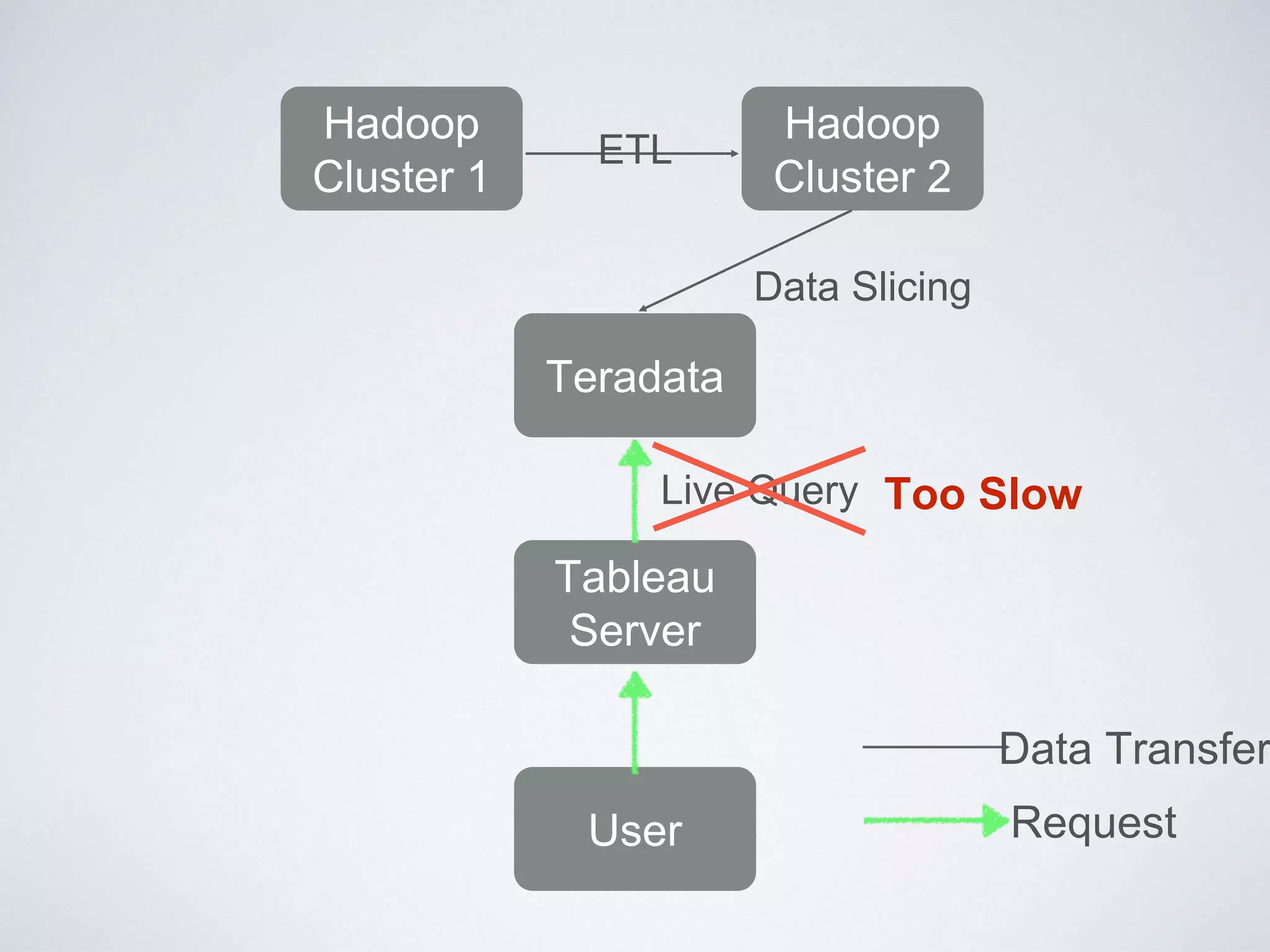
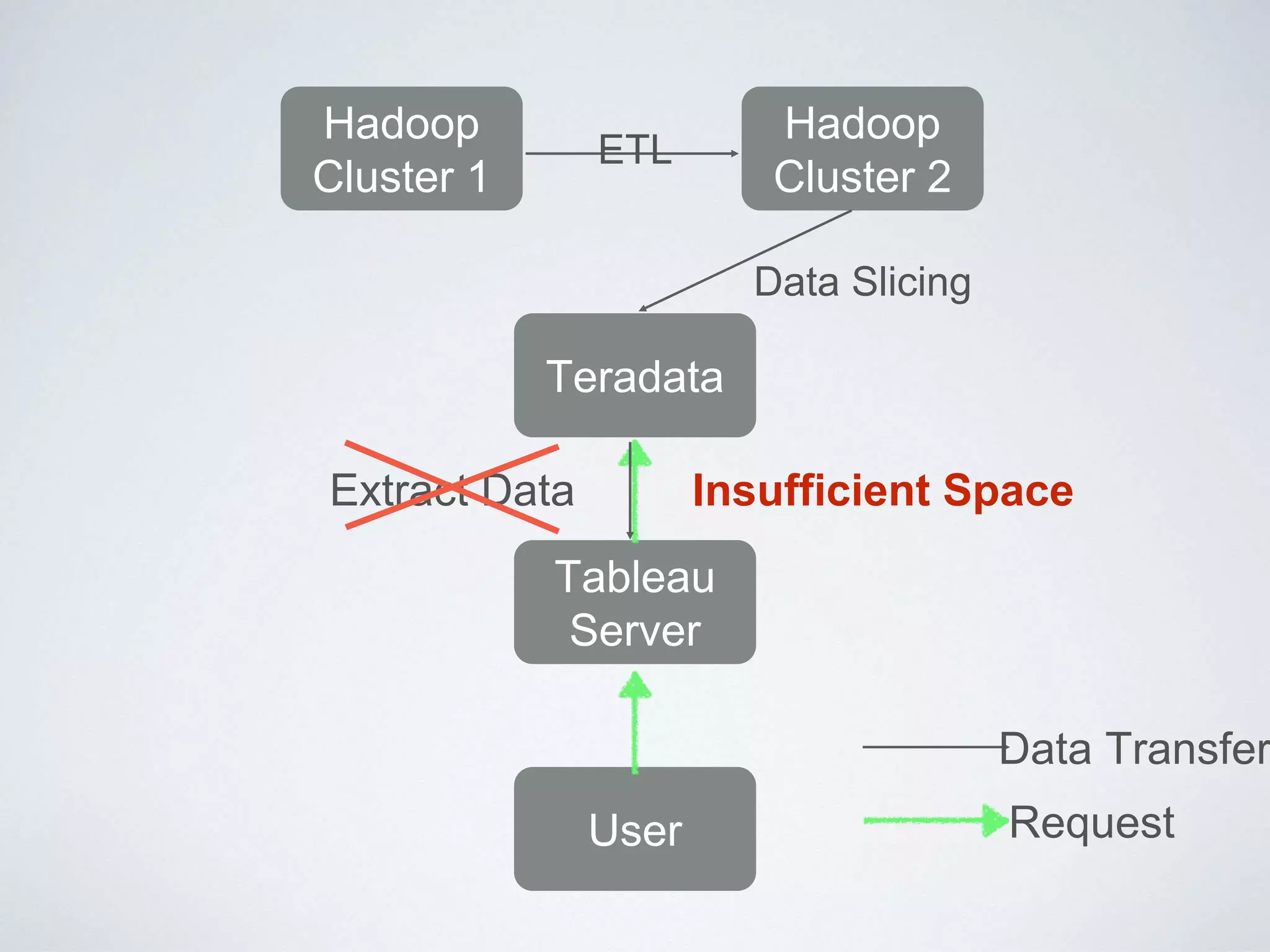
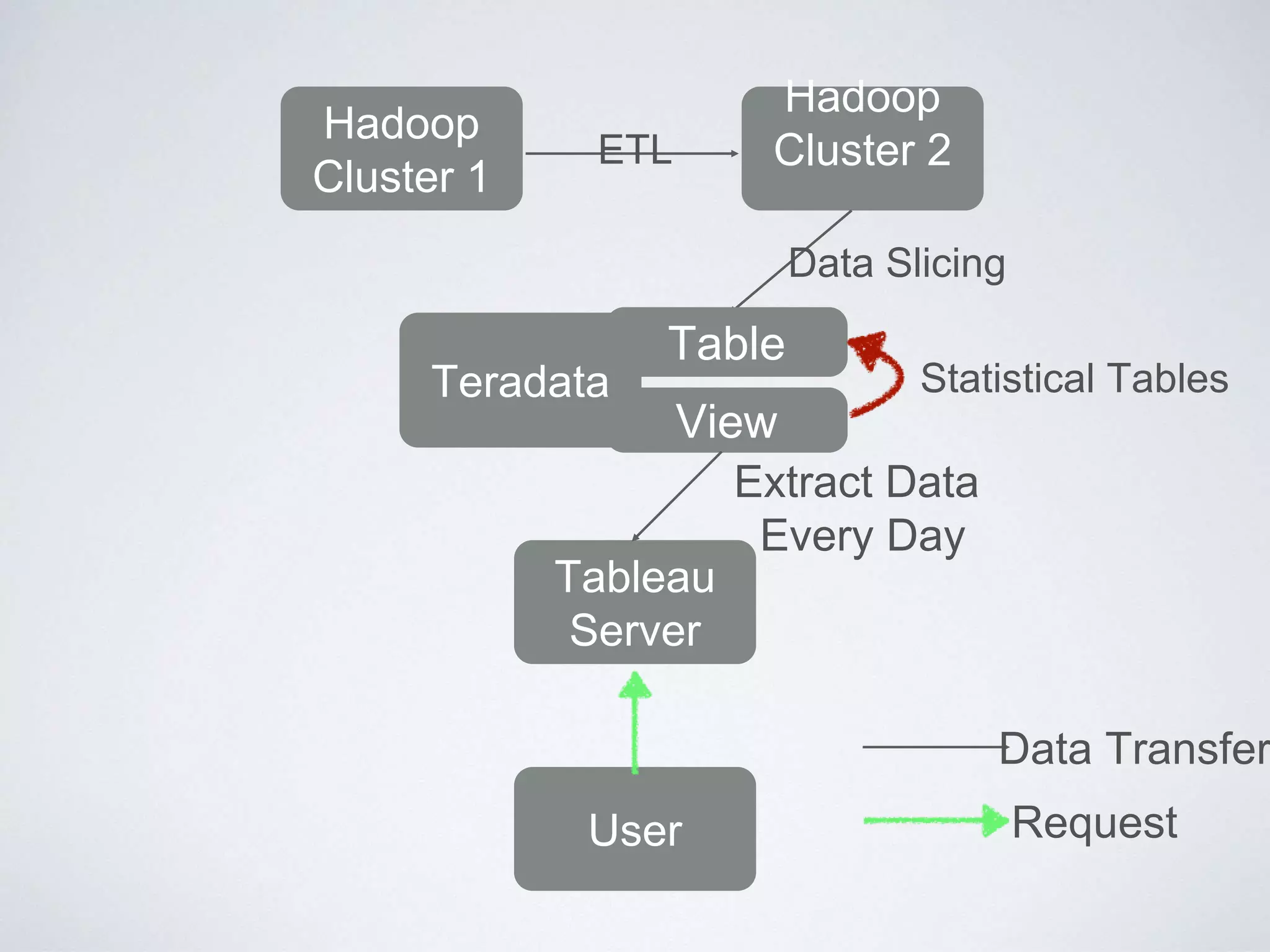
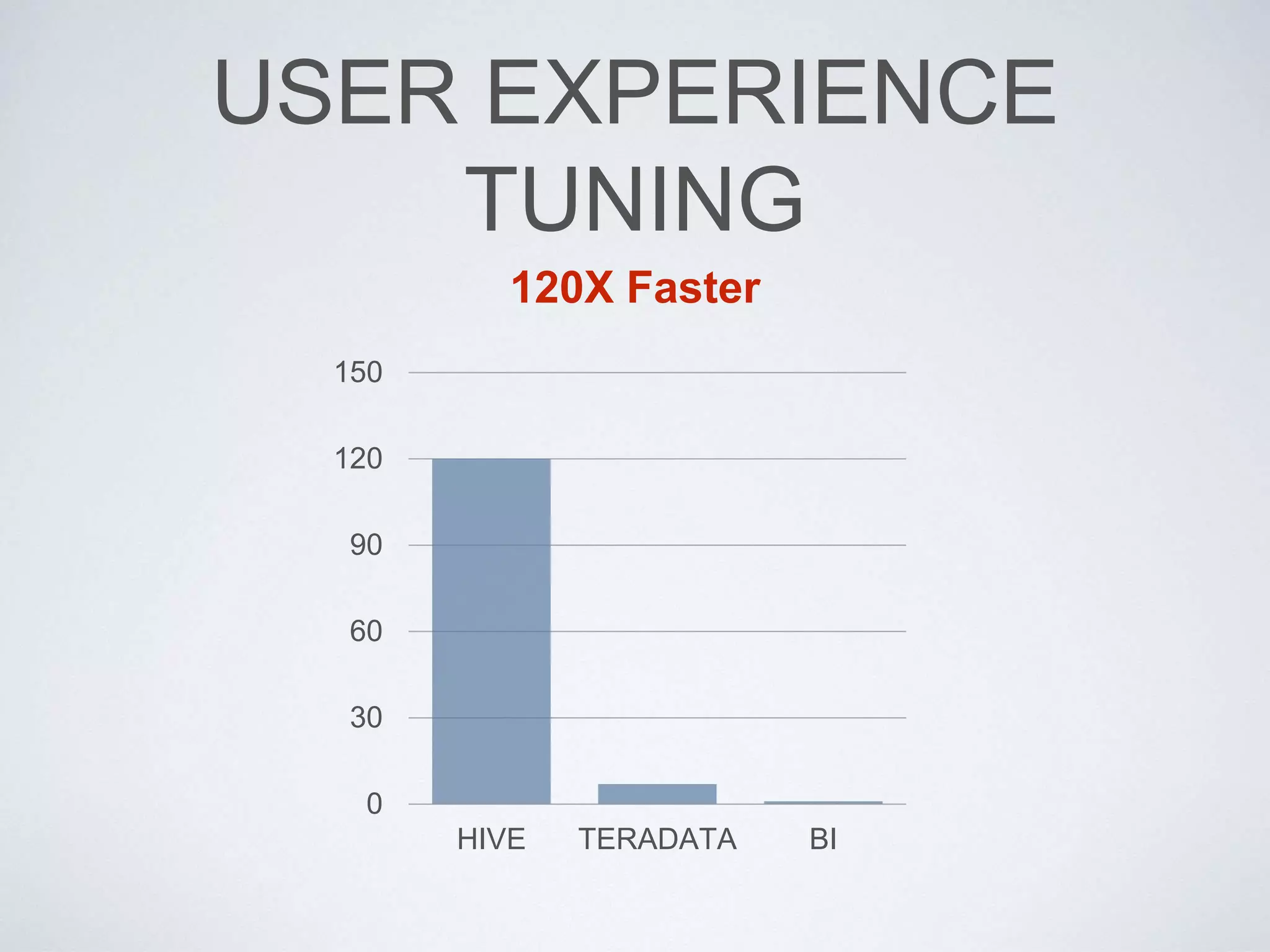




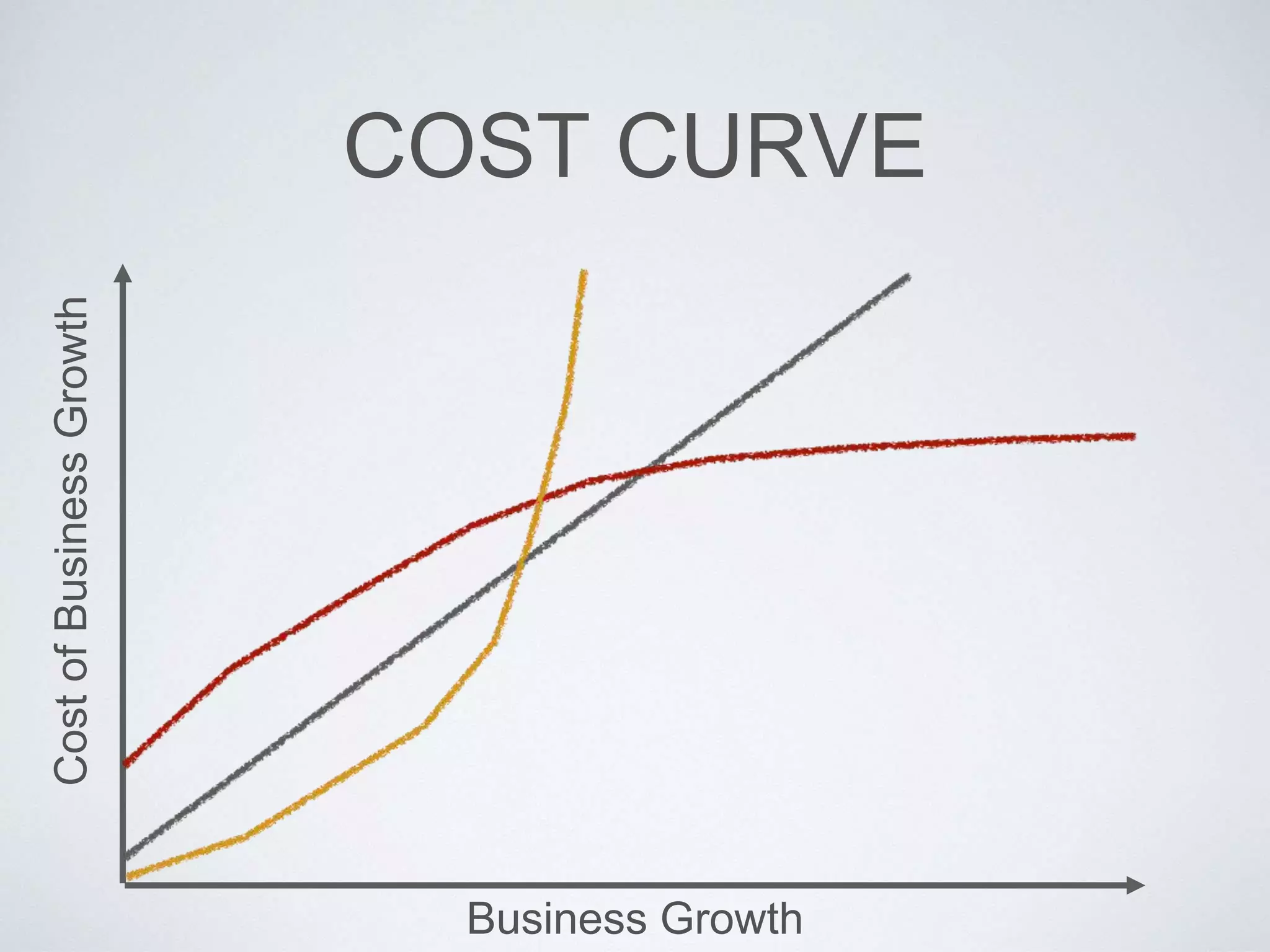
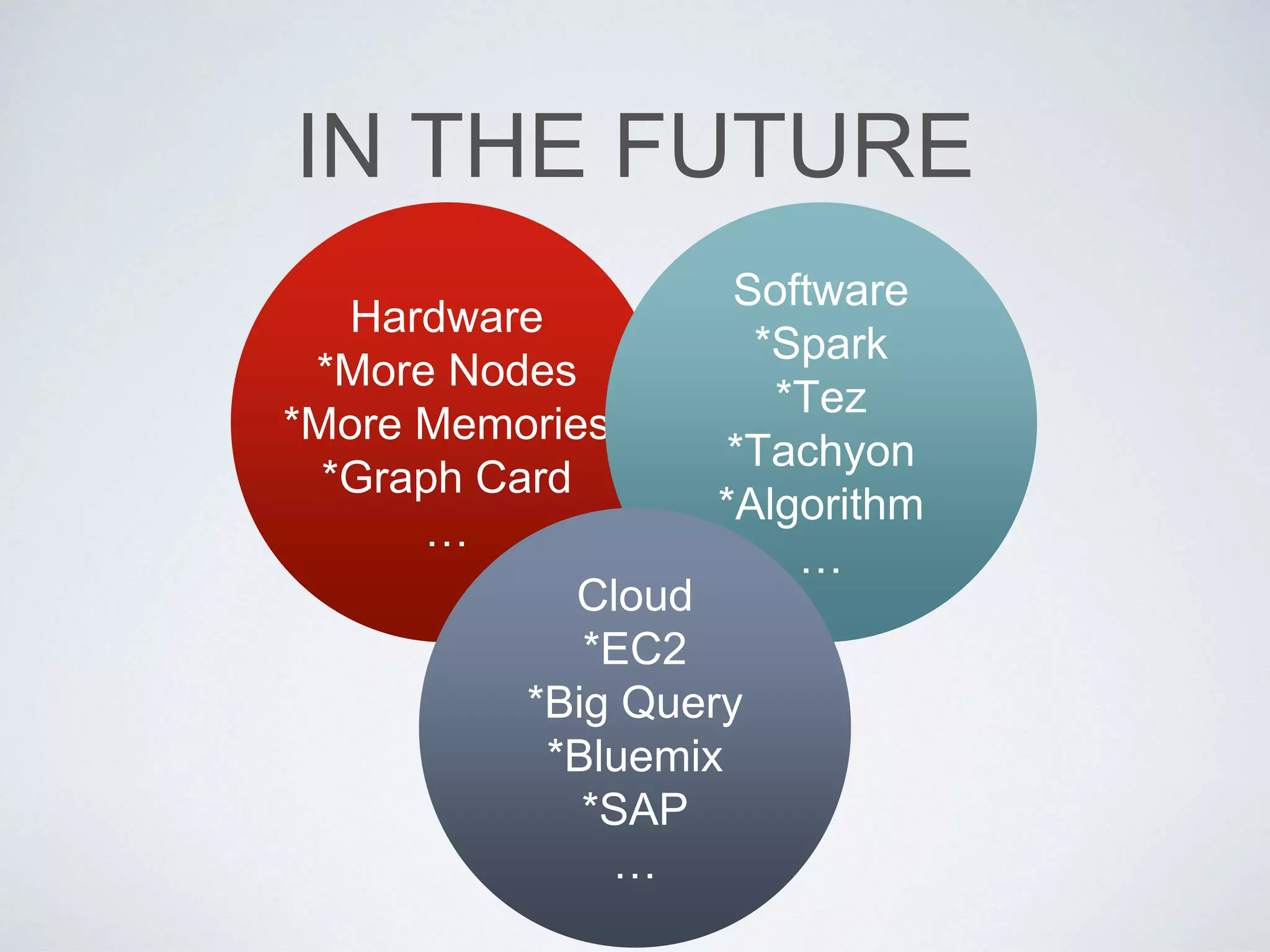









This document provides an overview of building a business intelligence (BI) system using a data lake ecosystem. It discusses using Hadoop, Hive, Teradata, Tableau and Jenkins together. The goals are to deal with big data problems like high volume, variety and velocity of data in a cost effective way. Sample architectures are proposed to handle ETL processes, data storage and querying, and visualization. Key considerations for choosing components include storage and management costs, processing time, and balancing needs with costs. The document concludes by suggesting that a good framework can help support business growth over time within a given cost curve.































































![[DBA]_HiramFleitas_SQL_PASS_Summit_2017_Summary](https://cdn.slidesharecdn.com/ss_thumbnails/dbahiramfleitassqlpasssummit2017summary-180202201153-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)


