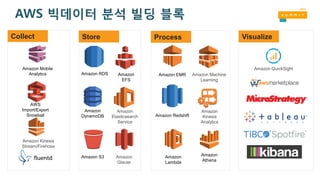
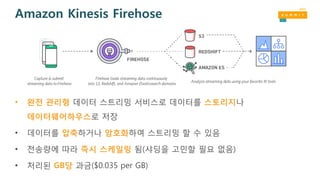
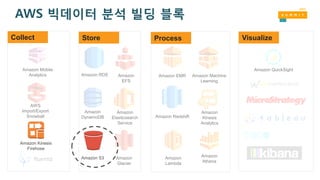
Amazon Kinesis Firehose
•완전 관리형 데이터 스트리밍 서비스로 데이터를 스토리지나
데이터웨어하우스로 저장
• 데이터를 압축하거나 암호화하여 스트리밍 할 수 있음
• 전송량에 따라 즉시 스케일링 됨(샤딩을 고민할 필요 없음)
• 처리된 GB당 과금($0.035 per GB)
Amazon S3
• 고가용성오브젝트 스토리지
• 99.999999999% 데이터 내구성
• 3개 시설을 걸친 데이터 복제
• 가상적으로 무제한 용량
• 사용한만큼 과금(사전 provisioning
불필요)
• event notification 기능을 통해 추가
작업 가능
Amazon S3
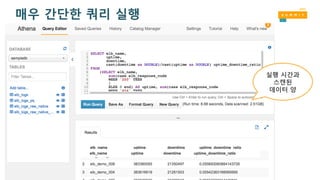
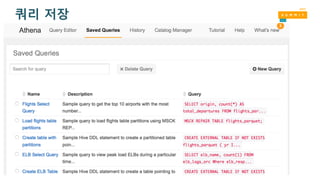
Amazon Athena –사용 편리성
• 콘솔 로그인
• 테이블 생성
• Hive DDL 구문
• ‘Add Table wizard’를 콘솔 상에서 사용
• 쿼리 실행!
17.
Amazon S3로 부터직접 질의
• 데이터 로딩이 필요치 않음
• raw 포맷 데이터에 질의(query)
• Text, CSV, JSON, weblogs, AWS service logs
• 최대의 성능과 낮은 비용을 위해 ORC 나 Parquet 같은 최적화된
포맷으로 변환
• 데이터 변환을 위한 ETL이 필요하지 않음
• S3 로부터의 직접 연결
• Amazon S3 의 내구성 및 가용성 활용
18.
ANSI SQL 지원
•ANSI SQL 지원
• 복잡한 join, nested 쿼리, window
함수들 지원
• 복잡한 데이터 유형 지원 (arrays,
structs)
• 데이터 파티션닝 지원
• (date, time, custom keys)
• e.g., Year, Month, Day, Hour or
Customer Key, Date
19.
친숙한 기술들을 활용
SQL쿼리 사용
메모리 기반 분산 쿼리 엔진
확장성을 지닌 ANSI-SQL 호환
DDL(Data Definition Language) functionality
복잡한 데이터 유형
다양한 데이터 포맷
데이터 파티션닝 지원
20.
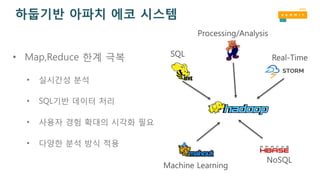
하둡기반 아파치 에코시스템
• Map,Reduce 한계 극복
• 실시간성 분석
• SQL기반 데이터 처리
• 사용자 경험 확대의 시각화 필요
• 다양한 분석 방식 적용
SQL
Processing/Analysis
Real-Time
Machine Learning
NoSQL
21.
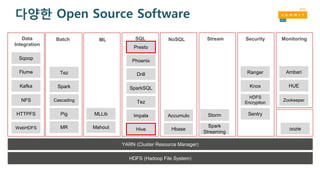
다양한 Open SourceSoftware
HDFS (Hadoop File System)
YARN (Cluster Resource Manager)
Tez
Spark
Cascading
Pig
MR Mahout
MLLib
Hive
Impala
Tez
SparkSQL
Drill
Hbase
Phoenix
Spark
Streaming
StormAccumulo
Sqoop
Flume
Kafka
NFS
Ranger
Knox
HTTPFS
WebHDFS
HDFS
Encryption
Sentry
oozie
Data
Integration
Batch ML SQL NoSQL Stream Security Monitoring
Zookeeper
HUE
Ambari
Presto
22.
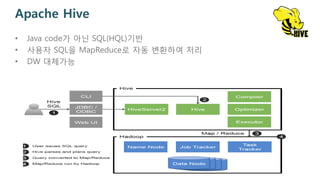
Apache Hive
• Javacode가 아닌 SQL(HQL)기반
• 사용자 SQL을 MapReduce로 자동 변환하여 처리
• DW 대체가능
23.
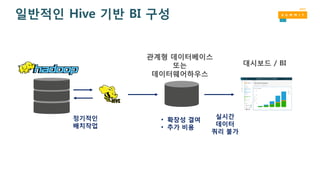
일반적인 Hive 기반BI 구성
정기적인
배치작업
관계형 데이터베이스
또는
데이터웨어하우스
대시보드 / BI
• 확장성 결여
• 추가 비용
실시간
데이터
쿼리 불가
24.
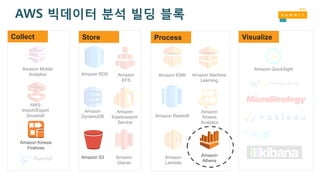
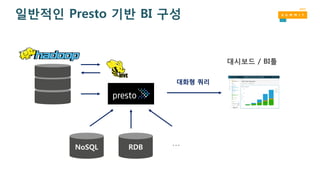
Presto
A distributed SQLquery engine for interactive data analysis against
GBs to PBs of data
What’s the problems to solve?
• Hive 는 BI용 대쉬보드에 사용하기에 너무 느려서
• Hive 기반 수행된 결과 저장용 DB(PostgreSQL, Redshift ) 별도 필요
• 데이터 소스가 HDFS가 아닌 경우도 있음
친숙한 기술들을 활용
SQL쿼리 사용
메모리 기반 분산 쿼리 엔진
확장성을 지닌 ANSI-SQL 호환
DDL(Data Definition Language) functionality
복잡한 데이터 유형
다양한 데이터 포맷
데이터 파티션닝 지원
27.
Amazon Athena 지원하는다양한 포맷들
• Text 파일(CSV, raw logs)
• Apache Web Logs, TSV 파일
• JSON (simple, nested)
• 압축된 파일
• Columnar 포맷 (Apache Parquet & Apache ORC)
• AVRO
28.
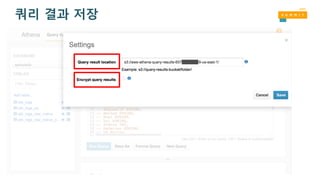
Amazon Athena –비용 효율성
• Pay per query
• $5 per TB scanned from S3
• DDL 쿼리와 실패한 쿼리는 무료
• 압축, columnar 포맷, 파티션을 사용하여 비용 절감 가능
29.
고객의 어려움 해결
S3에 있는 데이터 분석에 너무 많은 작업이 필요해요
No ETL, No 데이터 로딩, 라이브 데이터에 직접 쿼리
수집된 데이터세트에 접근만 하면 되는데..
사용자들이 원하는 모든 데이터를 점진적으로 쿼리 가능
우리는 하둡 클러스터나 데이터 웨어하우스 운영에 대한 전문성이
조금..
인프라를 관리할 필요가 없음
Pay By theQuery - $5/TB Scanned
• Query별 스캔된 데이터 양 만큼 과금
• 비용 절감 방법
• 압축
• Columnar 포맷으로 변환
• 파티션닝 적용
• 무료 : DDL 쿼리, 실패한 쿼리
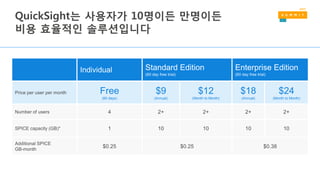
Dataset Size on Amazon S3 Query Run time Data Scanned Cost
Logs stored as Text
files
1 TB 237 seconds 1.15TB $5.75
Logs stored in
Apache Parquet
format*
130 GB 5.13 seconds 2.69 GB $0.013
Savings 87% less with Parquet 34x faster 99% less data scanned 99.7% cheaper
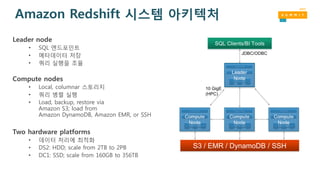
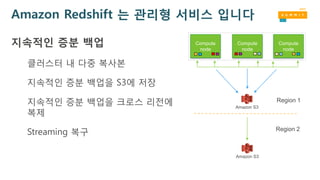
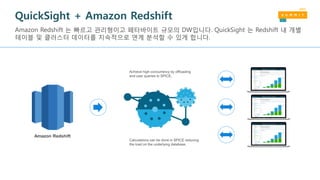
Amazon Redshift 는관리형 서비스 입니다
지속적인 증분 백업
클러스터 내 다중 복사본
지속적인 증분 백업을 S3에 저장
지속적인 증분 백업을 크로스 리전에
복제
Streaming 복구
Amazon S3
Amazon S3
Region 1
Region 2
45.
Amazon Redshift 는확장 가능합니다
• 근사 함수(Approximate functions)
• 사용자 정의 함수(User Defined Function)
• 머신러닝 / 데이터 사이언스
46.
Template
CREATE [ ORREPLACE ] FUNCTION
f_function_name
( [ argument_name arg_type, ... ] )
RETURNS data_type
{ VOLATILE | STABLE | IMMUTABLE }
AS $$
python_program
$$ LANGUAGE plpythonu;
Scalar UDF 예제 – URL parsing
Example
CREATE FUNCTION f_hostname (url
VARCHAR)
RETURNS varchar
IMMUTABLE AS $$
import urlparse
return
urlparse.urlparse(url).hostname
$$ LANGUAGE plpythonu;
SELECT REGEXP_REPLACE(url, '(https?)://([^@]*@)?([^:/]*)([/:].*|$)', ‘3')
FROM table;
SELECT f_hostname(url)
FROM table;
47.
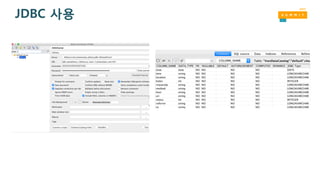
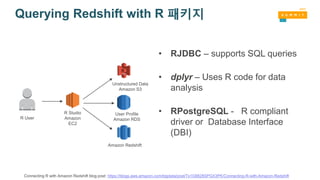
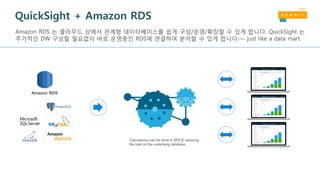
Querying Redshift withR 패키지
• RJDBC – supports SQL queries
• dplyr – Uses R code for data
analysis
• RPostgreSQL - R compliant
driver or Database Interface
(DBI)
R User
R Studio
Amazon
EC2
Unstructured Data
Amazon S3
User Profile
Amazon RDS
Amazon Redshift
Connecting R with Amazon Redshift blog post: https://blogs.aws.amazon.com/bigdata/post/Tx1G8828SPGX3PK/Connecting-R-with-Amazon-Redshift
48.
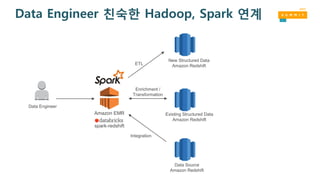
Data Engineer 친숙한Hadoop, Spark 연계
Data Engineer
Existing Structured Data
Amazon Redshift
New Structured Data
Amazon Redshift
Amazon EMR
spark-redshift
Enrichment /
Transformation
ETL
Data Source
Amazon Redshift
Integration
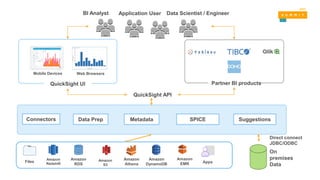
Amazon Quicksight
• 빠르고클라우드 기반 BI 서비스로 기존
BI 솔루션 대비 1/10 비용
• AWS 서비스, 외부 플랫폼, 파일등을
데이터 소스로 활용
• 인메모리 계산 엔진(SPICE)기반으로
분석 및 시각화를 가속
• 다른 파트너사 BI 솔루션으로 연계 확장
• 월 사용자 당 $9 부터 시작
QuickSight API
Data PrepMetadata SuggestionsConnectors SPICE
QuickSight UI
Mobile Devices Web Browsers
Partner BI products
Amazon
S3
Amazon
Athena
Amazon
DynamoDB
Amazon
EMR
Amazon
Redshift
Amazon
RDS
Files Apps
Direct connect
JDBC/ODBC
On
premises
Data
BI Analyst Data Scientist / EngineerApplication User
DW, 자동화된 리포트
TB-PB단위의 정형화된
데이터를
주기적인 시간,일,주
단위 배치 분석
빠른 쿼리
DW 팀, BI 팀, 분석가
Adhoc 쿼리, 로그 분석
SQL 기술만으로
히스토리컬
데이터/로그를
새로운 아이디어로 분석
분석가, BI 팀, 데이터
엔지니어
Data Transformation,
ETL
비정형데이터의 변환
Spark, MapReduce,
Hadoop cluster
데이터 엔지니어, 데이터
사이언티스트
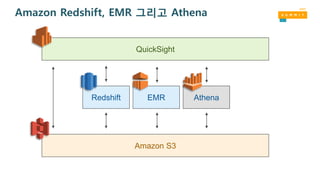
Amazon Redshift, EMR 그리고 Athena
RedshiftEMR Athena
62.
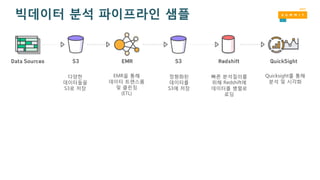
빅데이터 분석 파이프라인샘플
다양한
데이터들을
S3로 저장
EMR을 통해
데이터 트랜스폼
및 클린징
(ETL)
정형화된
데이터를
S3에 저장
빠른 분석질의를
위해 Redshift에
데이터를 병렬로
로딩
Quicksight를 통해
분석 및 시각화
63.
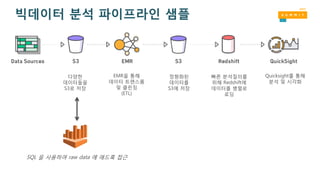
SQL 을 사용하여raw data 에 애드혹 접근
다양한
데이터들을
S3로 저장
EMR을 통해
데이터 트랜스폼
및 클린징
(ETL)
정형화된
데이터를
S3에 저장
빠른 분석질의를
위해 Redshift에
데이터를 병렬로
로딩
Quicksight를 통해
분석 및 시각화
빅데이터 분석 파이프라인 샘플
64.
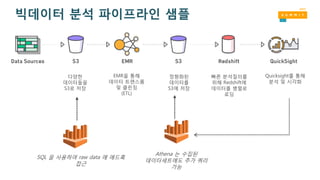
SQL 을 사용하여raw data 에 애드혹
접근
Athena 는 수집된
데이터세트에도 추가 쿼리
가능
다양한
데이터들을
S3로 저장
EMR을 통해
데이터 트랜스폼
및 클린징
(ETL)
정형화된
데이터를
S3에 저장
빠른 분석질의를
위해 Redshift에
데이터를 병렬로
로딩
Quicksight를 통해
분석 및 시각화
빅데이터 분석 파이프라인 샘플
65.
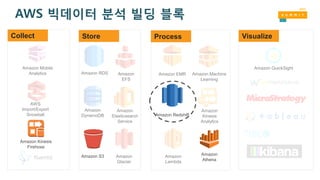
꼭 기억해 주세요!
Amazon
S3
CollectStore Process Visualize
Amazon
Kinesis
Firehose
Amazon
Athena
Amazon
QuickSight
AWS 서버리스 서비스만으로 대규모 데이터를
손쉽게 분석할 수 있습니다!
66.
본 강연이 끝난후…
• [AWS Big Data Blog] Derive Insights from
IoT in Minutes using AWS IoT, Amazon
Kinesis Firehose, Amazon Athena, and
Amazon QuickSight
• 한글 랩 가이드 - http://bit.ly/2pjTVzt
https://www.awssummit.kr
AWS Summit 모바일앱을 통해 지금 세션 평가에
참여하시면, 행사 후 기념품을 드립니다.
#AWSSummitKR 해시태그로 소셜 미디어에
여러분의 행사 소감을 올려주세요.
발표 자료 및 녹화 동영상은 AWS Korea 공식 소셜
채널로 공유될 예정입니다.
여러분의 피드백을 기다립니다!




























![Template
CREATE [ OR REPLACE ] FUNCTION
f_function_name
( [ argument_name arg_type, ... ] )
RETURNS data_type
{ VOLATILE | STABLE | IMMUTABLE }
AS $$
python_program
$$ LANGUAGE plpythonu;
Scalar UDF 예제 – URL parsing
Example
CREATE FUNCTION f_hostname (url
VARCHAR)
RETURNS varchar
IMMUTABLE AS $$
import urlparse
return
urlparse.urlparse(url).hostname
$$ LANGUAGE plpythonu;
SELECT REGEXP_REPLACE(url, '(https?)://([^@]*@)?([^:/]*)([/:].*|$)', ‘3')
FROM table;
SELECT f_hostname(url)
FROM table;](https://image.slidesharecdn.com/1-170418084631/85/AWS-AWS-Summit-Seoul-2017-46-320.jpg)









![본 강연이 끝난 후…
• [AWS Big Data Blog] Derive Insights from
IoT in Minutes using AWS IoT, Amazon
Kinesis Firehose, Amazon Athena, and
Amazon QuickSight
• 한글 랩 가이드 - http://bit.ly/2pjTVzt](https://image.slidesharecdn.com/1-170418084631/85/AWS-AWS-Summit-Seoul-2017-66-320.jpg)










































![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)


![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)



