Download to read offline



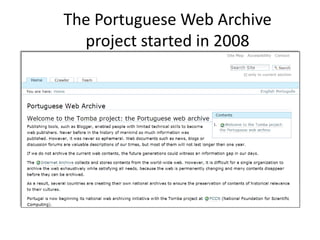
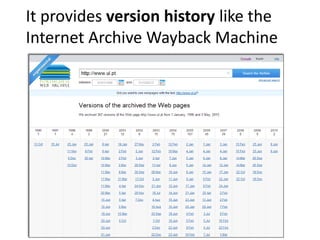
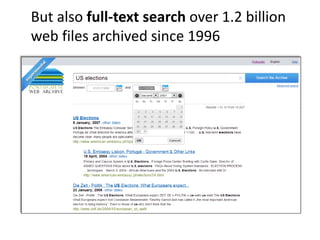


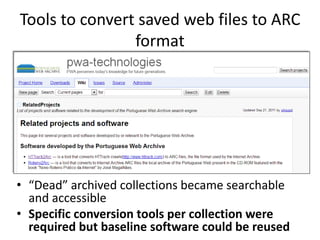

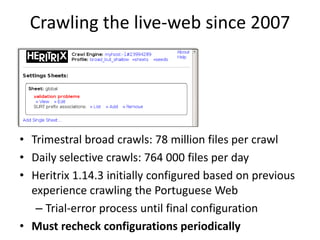
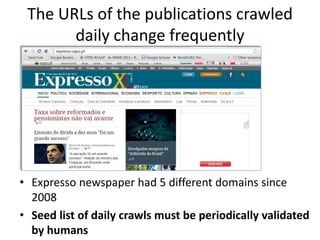










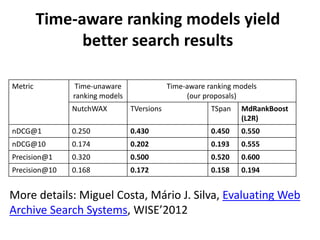











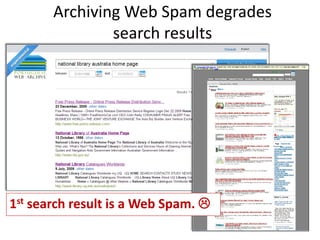

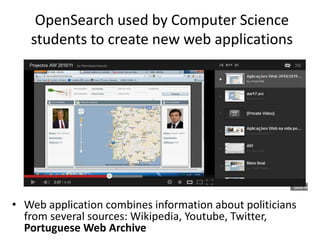




The document discusses lessons learned from the Portuguese web archive project, which has been operational since 2008 and includes full-text search over archived web content. It highlights integration efforts, improvements in search system relevance, and the importance of user interface design for web archiving. The conclusions emphasize the need for increased awareness of web archiving's significance in modern society and potential collaboration between archives and cultural institutions.










![[PREMONEY 2013] Jeff lawson](https://cdn.slidesharecdn.com/ss_thumbnails/jefflawson-130627092824-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































