







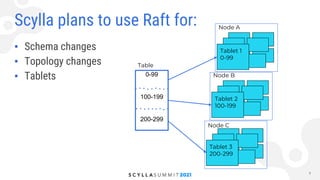


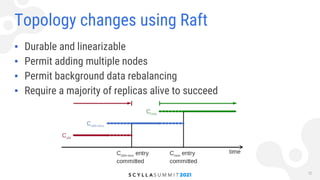





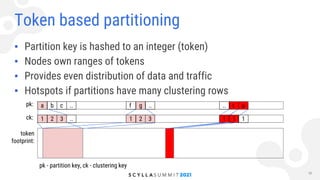






Konstantin Osipov from ScyllaDB discusses the implementation of Raft log replication in Scylla, focusing on its applications for schema and topology changes, as well as the use of lightweight transactions. The Raft protocol provides strong consistency with reduced network round trips per write, allowing for durable changes with linearizability while maintaining high availability. Scylla plans to leverage Raft for efficient management of schema changes, topology changes, and tablet partitioning, ensuring a consistent state across nodes.












![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)










































































