Download to read offline




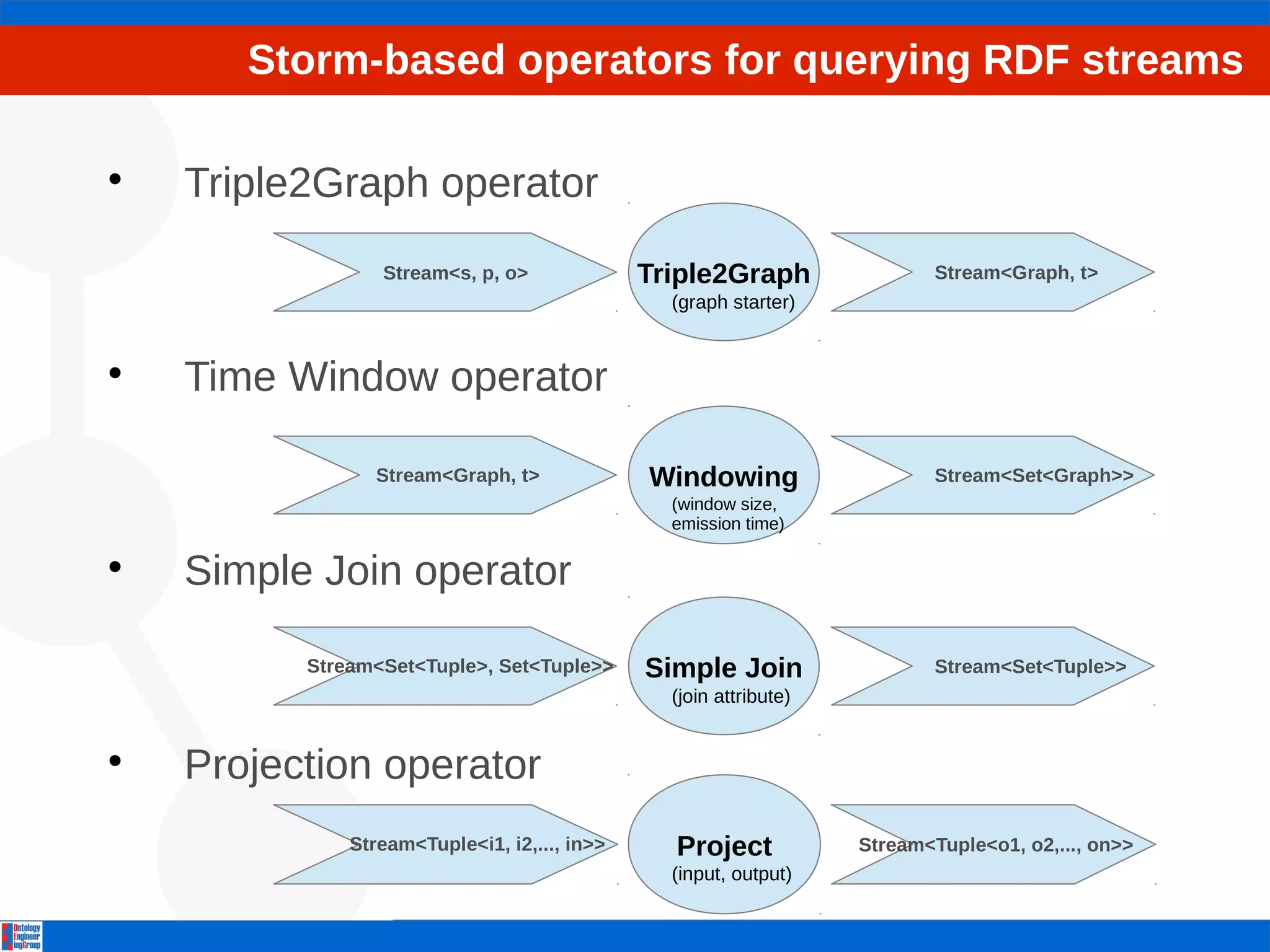
![Storm-based operators for querying RDF streams
Project
Project
Project
Project
Storm topology example (4 nodes)
SELECT ?obs.value ?sensors.location
FROM NAMED STREAM <obs> [60 SEC TO NOW]
FROM NAMED STREAM <sensors> [60 SEC TO NOW]
WHERE obs.sensorId = sensors.id ;
Simple Join
Simple Join
Simple Join
Simple Join
Windowing
<t0, t2...>
Windowing
<t1, t3...>
Windowing
<t0, t2...>
Windowing
<t1, t3...>
SPOUT
<obs>
Triple2Graph
Output
SPOUT
<sensors> Triple2Graph
t0
t1
t2
t3](https://image.slidesharecdn.com/ordring2014allaves-141020081440-conversion-gate01/75/Towards-efficient-processing-of-RDF-data-streams-9-2048.jpg)
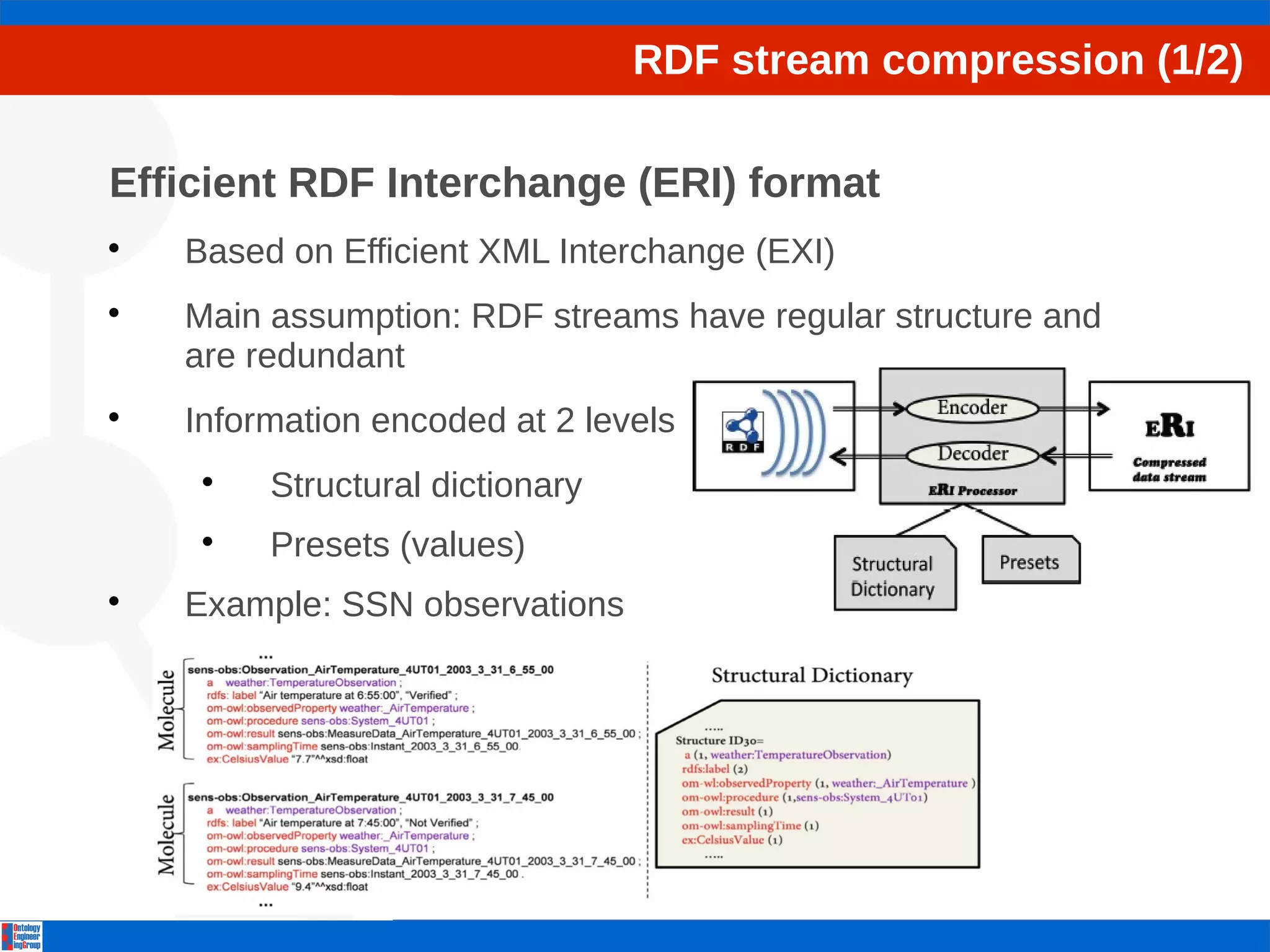
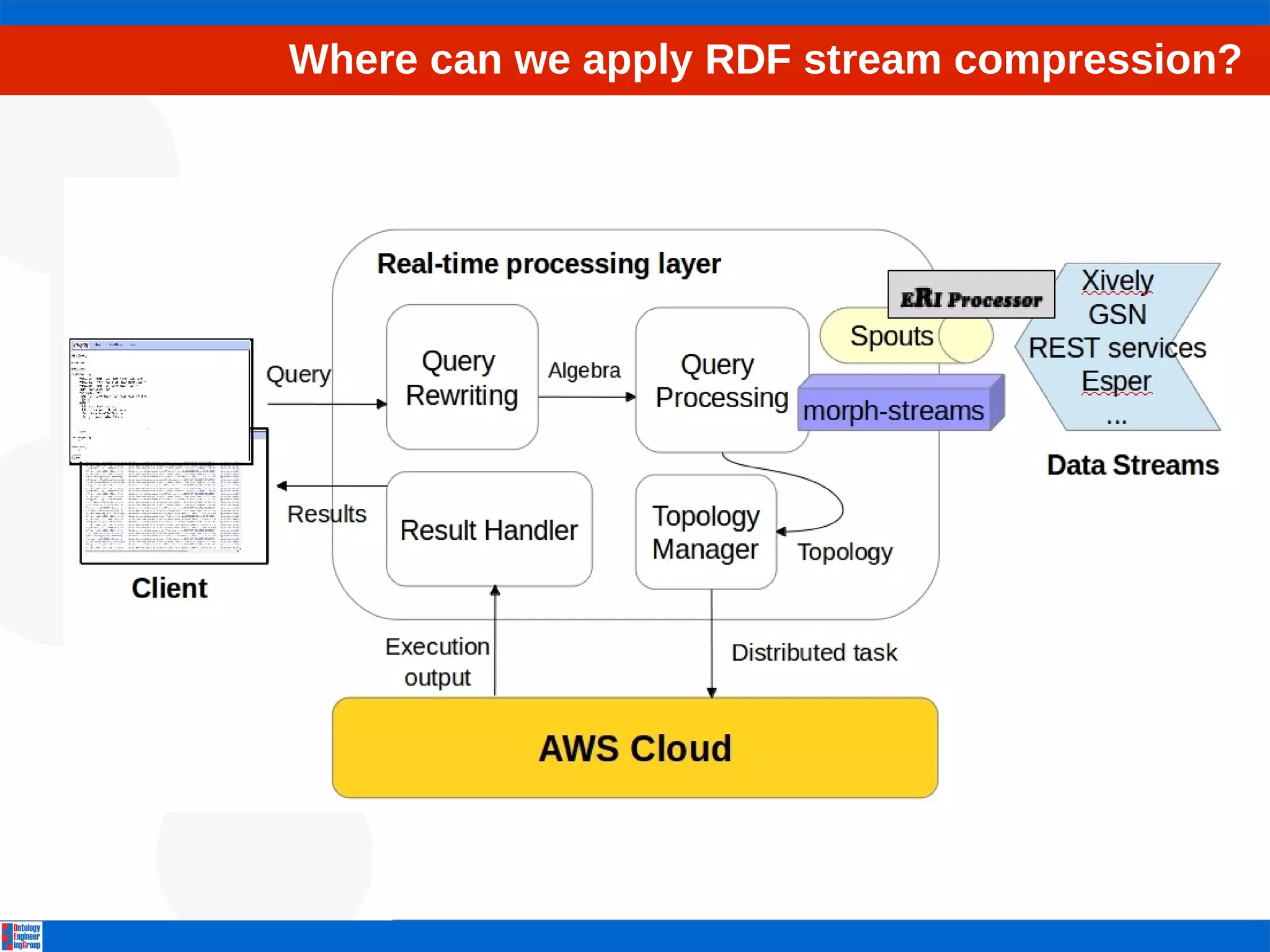





The document discusses the efficient processing of RDF data streams using Storm and Lambda architecture, focusing on developing a scalable and adaptive query processing engine. It outlines challenges facing RDF stream queries, provides an overview of Storm-based operators, and introduces a new format for RDF stream compression called ERI. Future work includes testing and optimizing query operators while addressing the integration of historical data with real-time processing.





















































































