Downloaded 138 times
















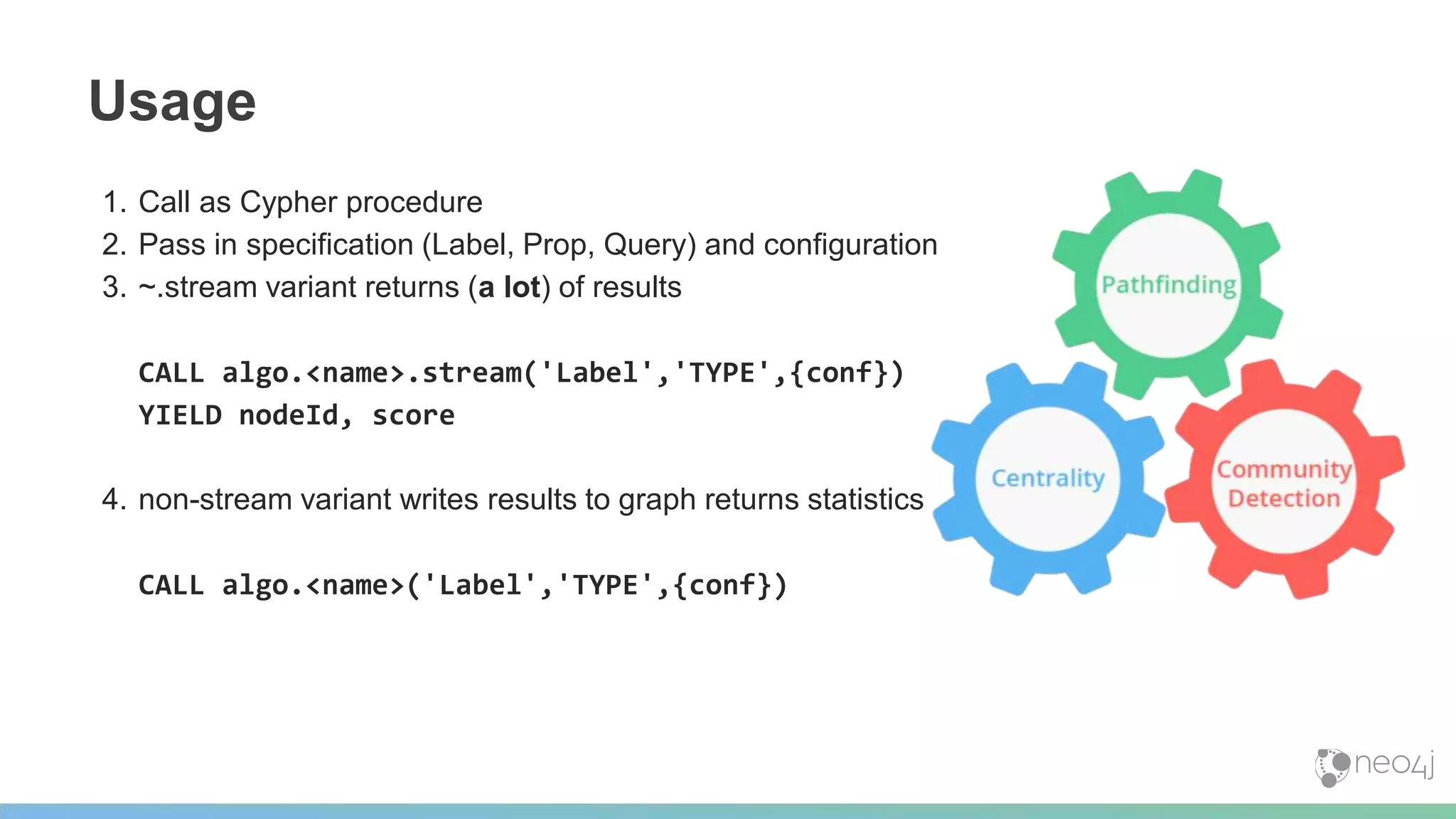





![DBPedia
Shallow Copy of Wikipedia: (Page) -[:Link]-> (Page)
CALL algo.pageRank.stream('Page', 'Link', {iterations:5}) YIELD node, score
WITH *
ORDER BY score DESC
LIMIT 5
RETURN node.title, score;
+--------------------------------------+
| node.title | score |
+--------------------------------------+
| "United States" | 13349.2 |
| "Animal" | 6077.77 |
| "France" | 5025.61 |
| "List of sovereign states" | 4913.92 |
| "Germany" | 4662.32 |
+--------------------------------------+
5 rows 46 seconds](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-46-2048.jpg)
![DBPedia – Largest Clusters
CALL algo.labelPropagation();
// First 1M pages by Rank
MATCH (n:Page)
WITH n
ORDER BY n.pagerank DESC
LIMIT 1000000
// group by partition
WITH n.partition AS partition,
count(*) AS clusterSize,
collect(n.title) AS pages
// return most influential node for largest clusters
RETURN pages[0] AS mainPage,
pages[1..10] AS otherPages
ORDER BY clusterSize DESC
LIMIT 20](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-47-2048.jpg)


![Yelp – Social - Statistics
MATCH (u:User) where exists ( (u)-[:FRIENDS]-() )
WITH u.average_stars as stars, u.review_count as reviews, u.funny as funny
RETURN max(stars),avg(stars),stdev(stars),max(reviews),avg(reviews),stdev(reviews),max(funny),avg(funny),stdev(funny);
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| max(stars) | avg(stars) | stdev(stars) | max(reviews) | avg(reviews) | stdev(reviews) | max(funny) | avg(funny) | stdev(funny) |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 5.0 | 3.8238072950764947 | 0.8862511758625753 | 11284 | 45.81704314022204 | 120.52419266925014 | 170896 | 36.26637835535585 | 731.6024752545679 |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
MATCH (u:User) where exists ( (u)-[:FRIENDS]-() )
WITH u.yelping_since as since
RETURN substring(since,0,4) as year, count(*) as total
ORDER BY year asc limit 10;
+----------------+
| year | total |
+----------------+
| "2004" | 64 |
| "2005" | 844 |
| "2006" | 4504 |
| "2007" | 11833 |
| "2008" | 20729 |
| "2009" | 33965 |
| "2010" | 53046 |
| "2011" | 70331 |
| "2012" | 62596 |
| "2013" | 57330 |
+----------------+](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-50-2048.jpg)
![Yelp – Social - PageRank
call algo.pageRank.stream('User','FRIENDS')
yield node,score with node,score
order by score desc limit 10
return node {.name, .review_count, .average_stars,.useful,.yelping_since,.funny},
score,
size( (node)<-[:FRIENDS]-()<-[:FRIENDS]-()) as in,
size( (node)-[:FRIENDS]->()-[:FRIENDS]->()) as out;
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| node | score |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| {funny -> 61200, name -> "Philip", average_stars -> 3.93, review_count -> 788, useful -> 69448, yelping_since -> "2007-06-09"} | 208.31336799999994 |
| {funny -> 21432, name -> "Des", average_stars -> 3.88, review_count -> 78, useful -> 140024, yelping_since -> "2014-04-01"} | 201.28600150000003 |
| {funny -> 465, name -> "Dallas", average_stars -> 4.17, review_count -> 330, useful -> 5517, yelping_since -> "2010-11-07"} | 192.164762 |
| {funny -> 1019, name -> "Cara", average_stars -> 3.96, review_count -> 842, useful -> 11738, yelping_since -> "2010-07-21"} | 184.01898249999996 |
| {funny -> 1233, name -> "Walker", average_stars -> 3.91, review_count -> 462, useful -> 12332, yelping_since -> "2007-01-25"} | 180.48898350000005 |
| {funny -> 13432, name -> "Gabi", average_stars -> 4.05, review_count -> 1730, useful -> 20759, yelping_since -> "2007-08-10"} | 163.29424850000004 |
| {funny -> 12848, name -> "Ruggy", average_stars -> 3.92, review_count -> 2118, useful -> 72265, yelping_since -> "2007-07-31"} | 161.87635500000002 |
| {funny -> 9997, name -> "Bill", average_stars -> 3.38, review_count -> 595, useful -> 12074, yelping_since -> "2014-04-05"} | 157.0438075 |
| {funny -> 1544, name -> "Ashley", average_stars -> 3.7, review_count -> 224, useful -> 1610, yelping_since -> "2009-09-29"} | 150.21423599999997 |
| {funny -> 3599, name -> "Risa", average_stars -> 4.08, review_count -> 1044, useful -> 22121, yelping_since -> "2011-07-30"} | 138.20863199999997 |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
10 rows
3236 ms](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-51-2048.jpg)
![Yelp
•Inferred network of users, via jointly reviewed businesses
• (u1:User)-[:WROTE]->(review1)-[:REVIEWS]->(business)<-[:REVIEWS]-(review2)<-[:WROTE]-(u2:User)
• 1,3bn paths
• Inferred network of businesses, via jointly reviewed by user
• (b1:Business)<-[:REVIEWS]-()<-[:WROTE]-(u)-[:WROTE]->()-[:REVIEWS]->(b2:Business)
• 214m paths
• subset: (b1:Business)-[:CO_OCCURENT_REVIEWS]-(b2:Business)](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-52-2048.jpg)
![Yelp
•Inferred network of users, via jointly reviewed businesses
• (u1:User)-[:WROTE]->(review1)-[:REVIEWS]->(business)<-[:REVIEWS]-(review2)<-[:WROTE]-(u2:User)
• 1.3bn paths
• Inferred network of businesses, via jointly reviewed by user
• (b1:Business)<-[:REVIEWS]-()<-[:WROTE]-(u)-[:WROTE]->()-[:REVIEWS]->(b2:Business)
• 214m paths](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-53-2048.jpg)

![Yelp – Business – Co-Occurrence
CALL apoc.periodic.iterate(
'MATCH (b:Business)
WHERE size((b)<-[:REVIEWS]-()) > 5 AND b.city="Las Vegas"
RETURN b',
'MATCH (b)<-[:REVIEWS]-(r1)<-[:WROTE]-(u)-[:WROTE]->(r2)-[:REVIEWS]->(b2)
WHERE id(b) < id(b2) AND b2.city="Las Vegas"
AND size((b2)<-[:REVIEWS]-()) > 5
AND r1.stars = r2.stars
WITH b, b2, count(*) AS weight, avg(r1.stars) as rating where weight > 5
MERGE (b)-[cr:B2B]-(b2)
ON CREATE SET cr.weight = weight, cr.rating = rating
SET b:Marked, b2:Marked',
{batchSize: 1});](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-55-2048.jpg)
![Yelp - Clustering Union Find
CALL algo.unionFind.stream(
'MATCH (b:Business:Marked) RETURN id(b) as id’,
'MATCH (b1:Business:Marked)-[r:B2B]-(b2)
RETURN id(b1) as source,
id(b2) as target,
count(r) as value',
{graph:'cypher'}) YIELD setId as cluster, nodeId
RETURN cluster, count(*) as size
ORDER BY size DESC LIMIT 10;
+--------------+
|cluster| size |
+--------------+
| 3 | 5625 |
| 1876 | 3 |
| 155 | 2 |
| 1091 | 2 |
| 1728 | 2 |
| 1177 | 2 |
| 337 | 2 |
| 3046 | 2 |
| 674 | 2 |
| 1948 | 2 |
+--------------+
10 rows
6615 ms](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-56-2048.jpg)
![Yelp - PageRank
CALL algo.pageRank.stream(
'MATCH (b:Business:Marked)
RETURN id(b) as id',
'MATCH (b1:Business:Marked)-[r:B2B]-(b2)
RETURN id(b1) as source,
id(b2) as target',
{graph:'cypher'})
YIELD node, score
RETURN node.name, score
ORDER BY score DESC
LIMIT 10;
+-------------------------------------------------------+
| node.name | score |
+-------------------------------------------------------+
| "McCarran International Airport" | 27.49973599999999 |
| "Hash House A Go Go" | 19.062398000000005 |
| "Bachi Burger" | 18.1494385 |
| "Mon Ami Gabi" | 17.720350000000003 |
| "Bacchanal Buffet" | 15.783480500000003 |
| "Yard House Town Square" | 14.427296999999998 |
| "Secret Pizza" | 13.156547 |
| "Rollin Smoke Barbeque" | 12.808718499999998 |
| "Wicked Spoon" | 12.639942499999997 |
| "Monta Ramen" | 12.3904845 |
+-------------------------------------------------------+
10 rows
6979 ms](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-57-2048.jpg)


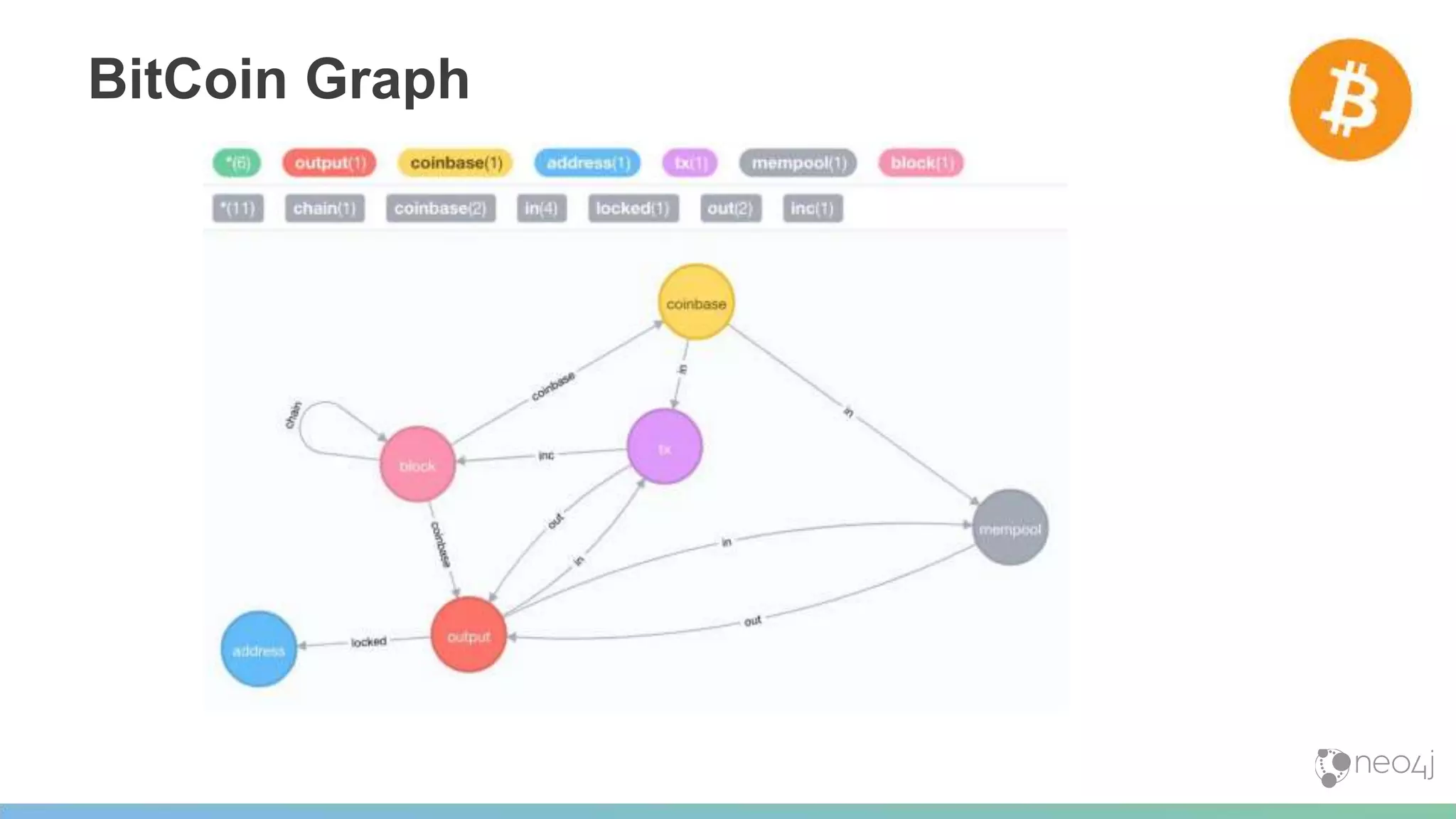

![BitCoin Graph
Inferred network of addresses, via transaction and output
(a1)<-[:locked]-(o1)-[:in]->(tx)-[:out]->(o2)-[:locked]->(a2)
CALL algo.unionFind.stream(
'match (o:output)-[:locked]->(a) with a limit 10000000 return id(a) as id',
'match (o:output)-[:locked]->(a) with o limit 10000000
match (o)-[:in]->(tx)-[:out]->(o2)-[:locked]->(a2)
return id(a) as source, id(a2) as target, count(tx) as weight',
{graph:'cypher'})
YIELD setId as cluster, nodeId
RETURN cluster, count(*) AS size
ORDER BY size DESC
LIMIT 10;
+-------------------+
| cluster | size |
+-------------------+
| 5036 | 4409420 |
| 6295282 | 1999 |
| 5839746 | 1488 |
| 9356302 | 833 |
| 6560901 | 733 |
| 6370777 | 637 |
| 8101710 | 392 |
| 5945867 | 369 |
| 2489036 | 264 |
| 1703620 | 203 |
+-------------------+
10 rows, 296 seconds](https://image.slidesharecdn.com/graphalgojan25v4-180126165857/75/Graph-Analytics-Graph-Algorithms-Inside-Neo4j-62-2048.jpg)


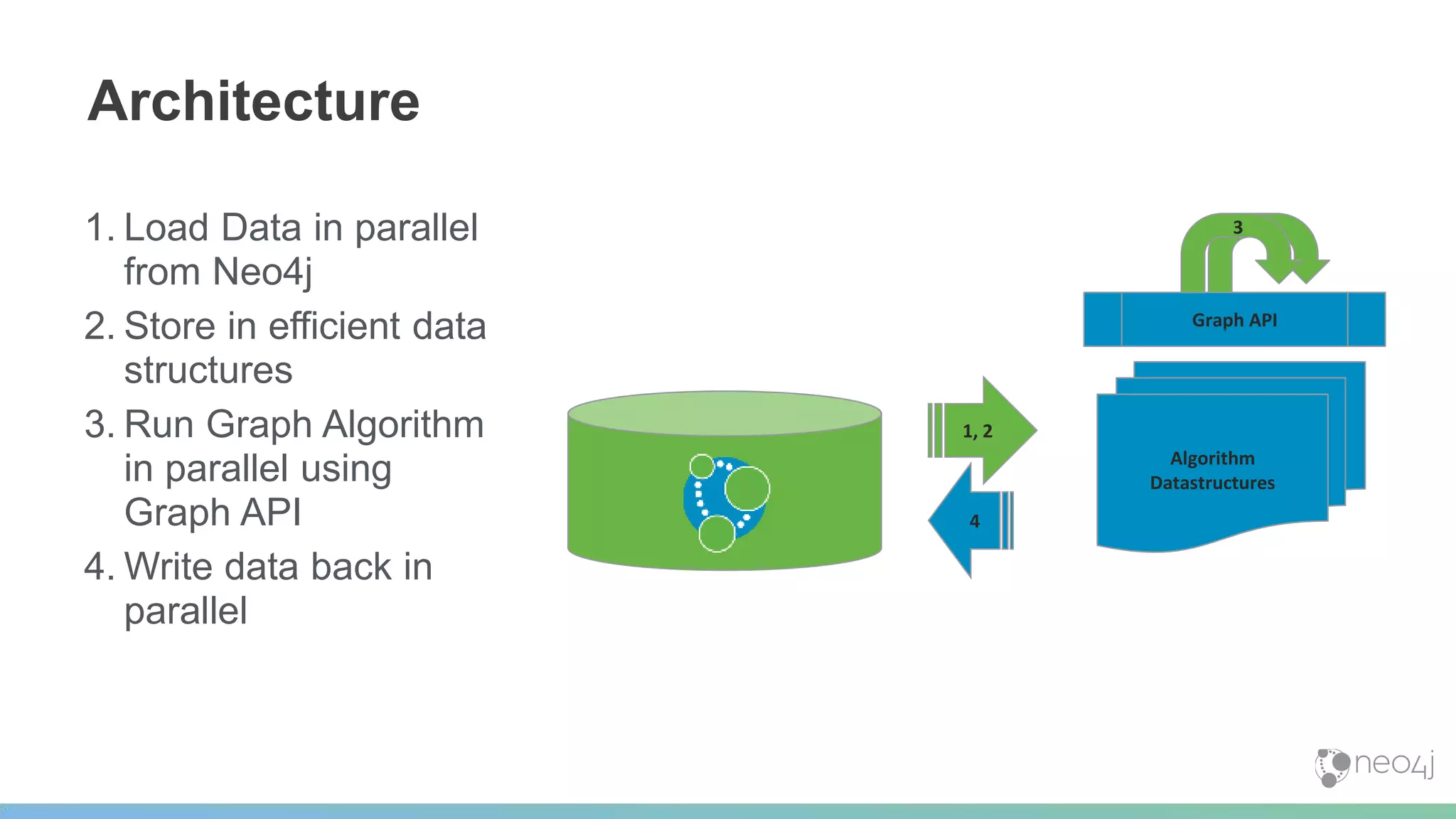

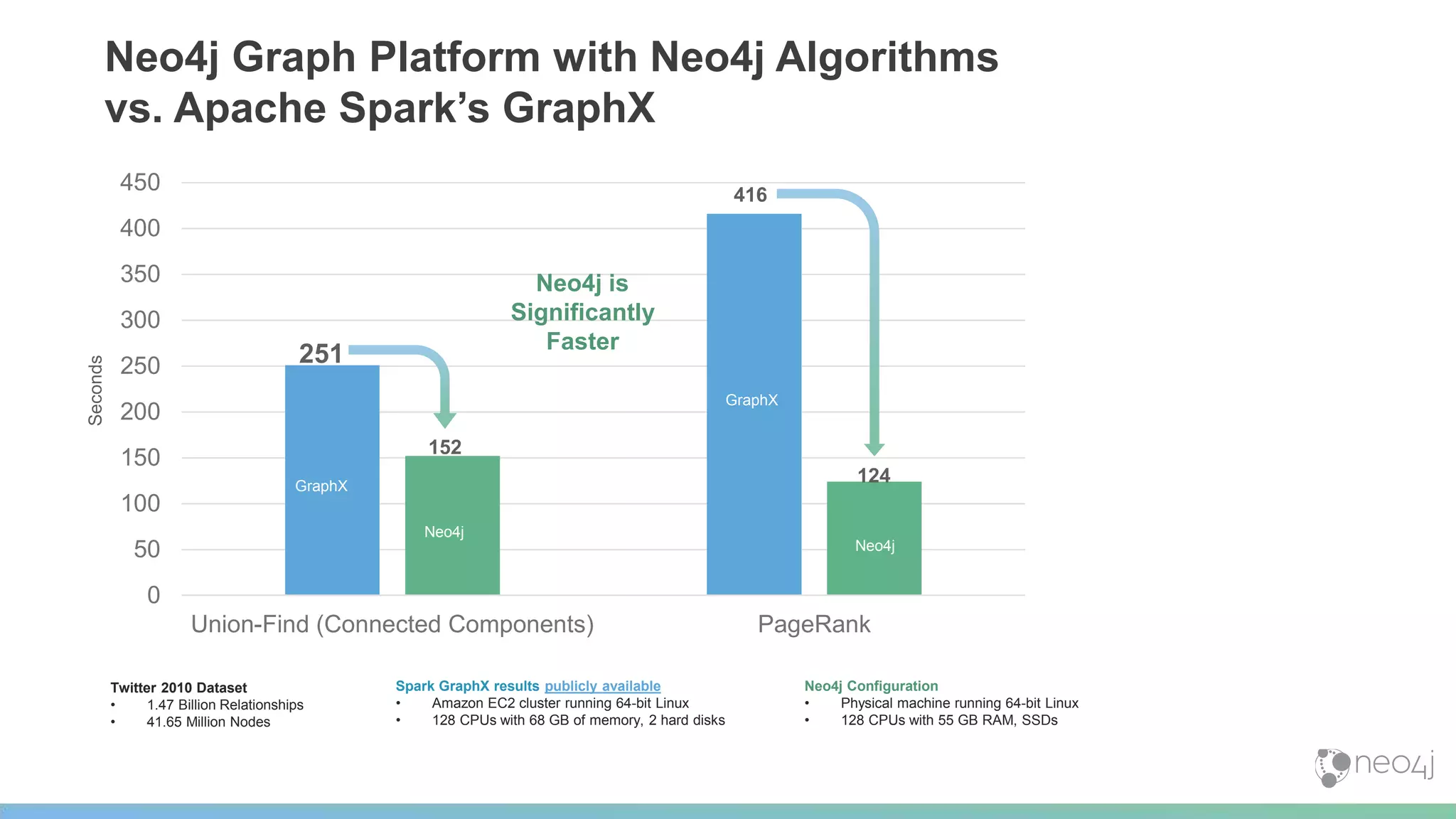






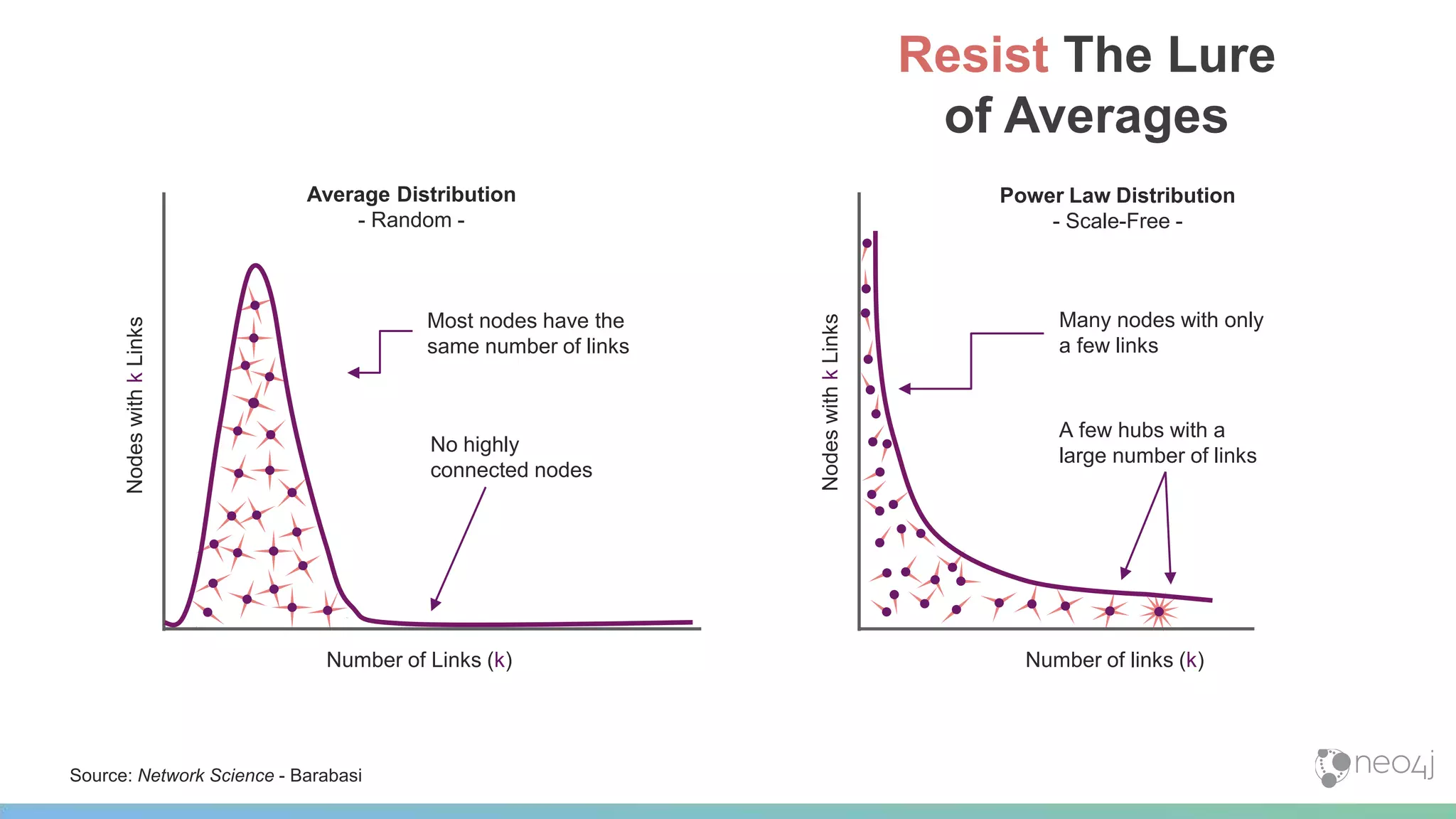
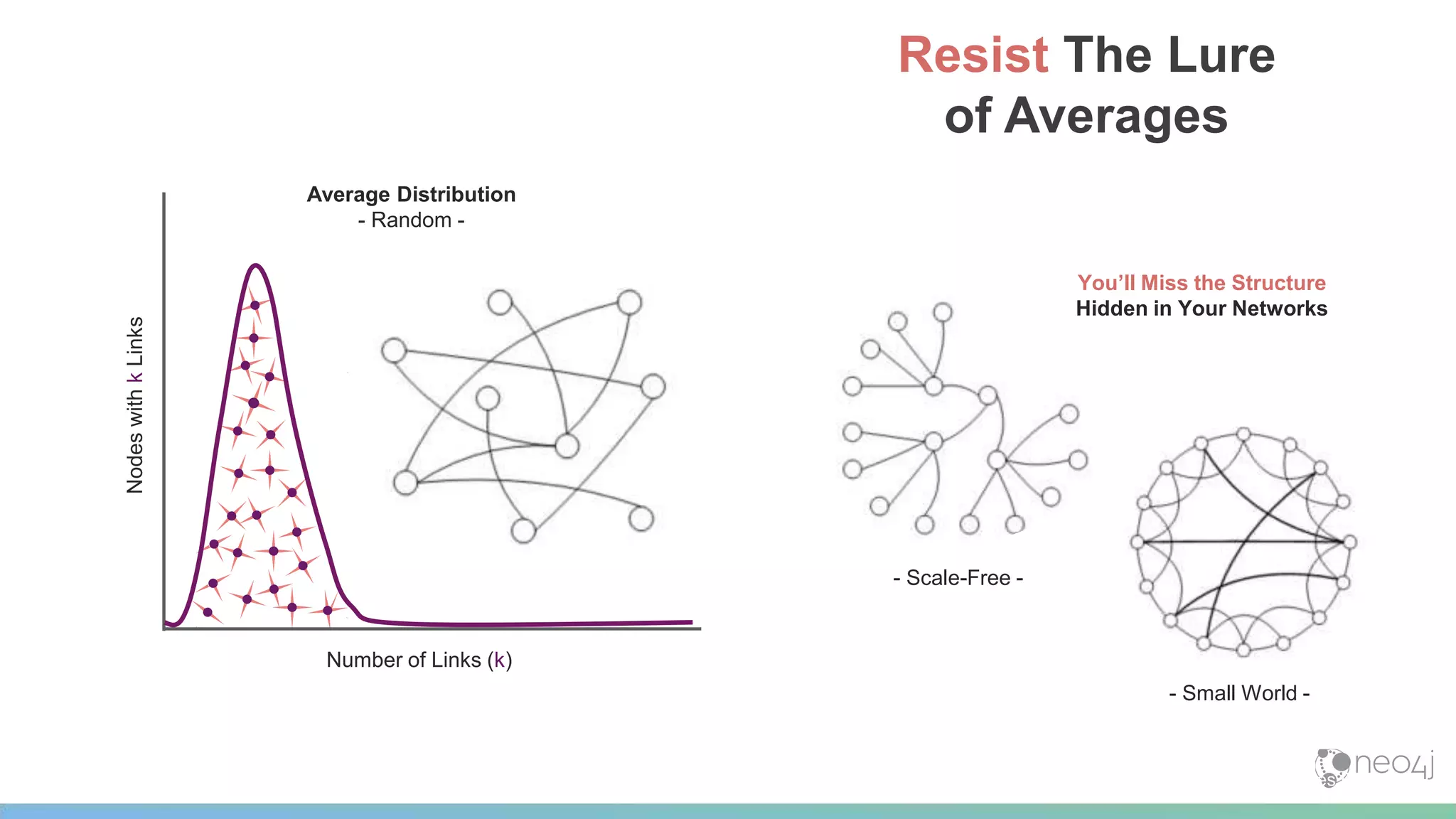
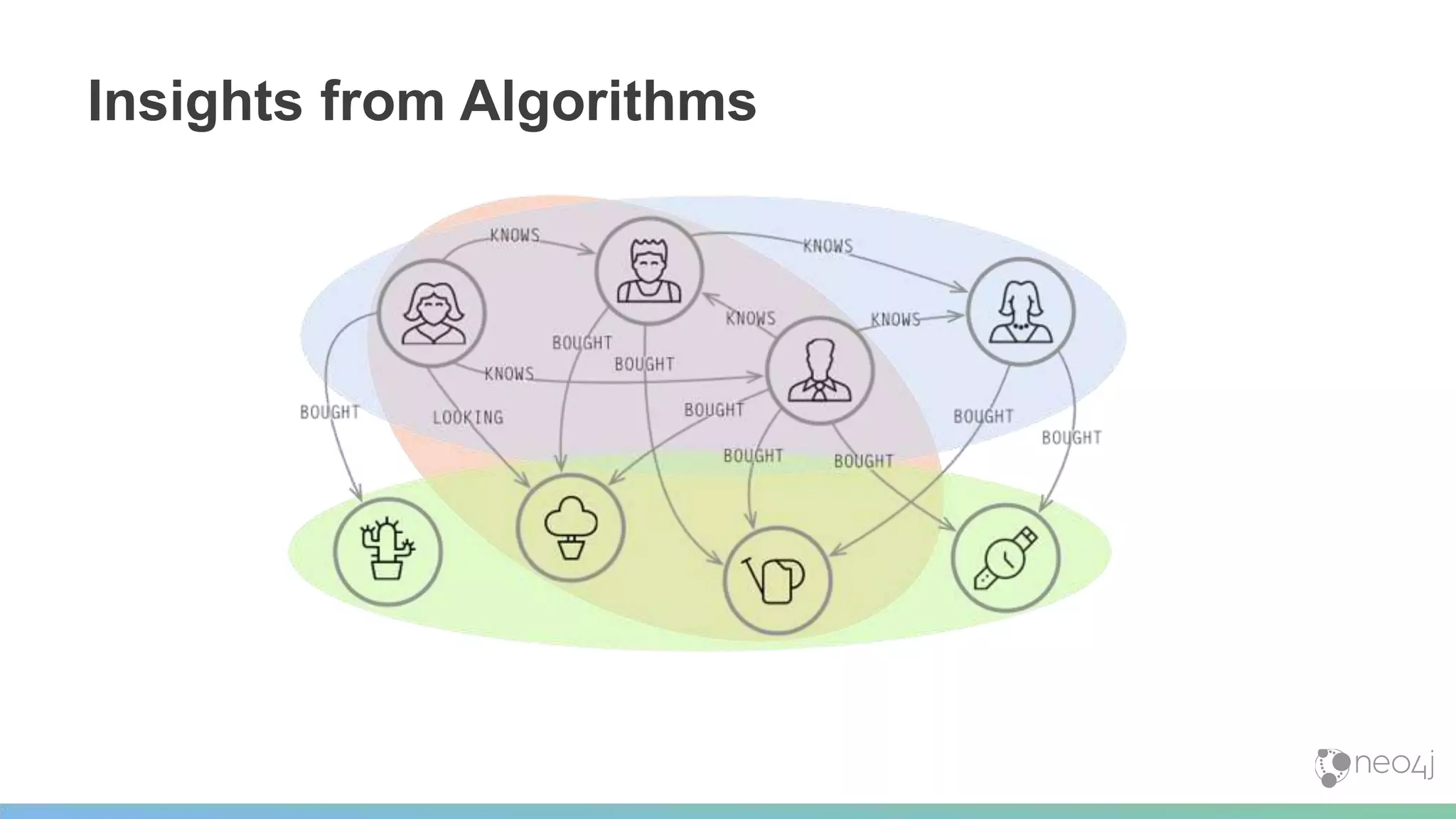
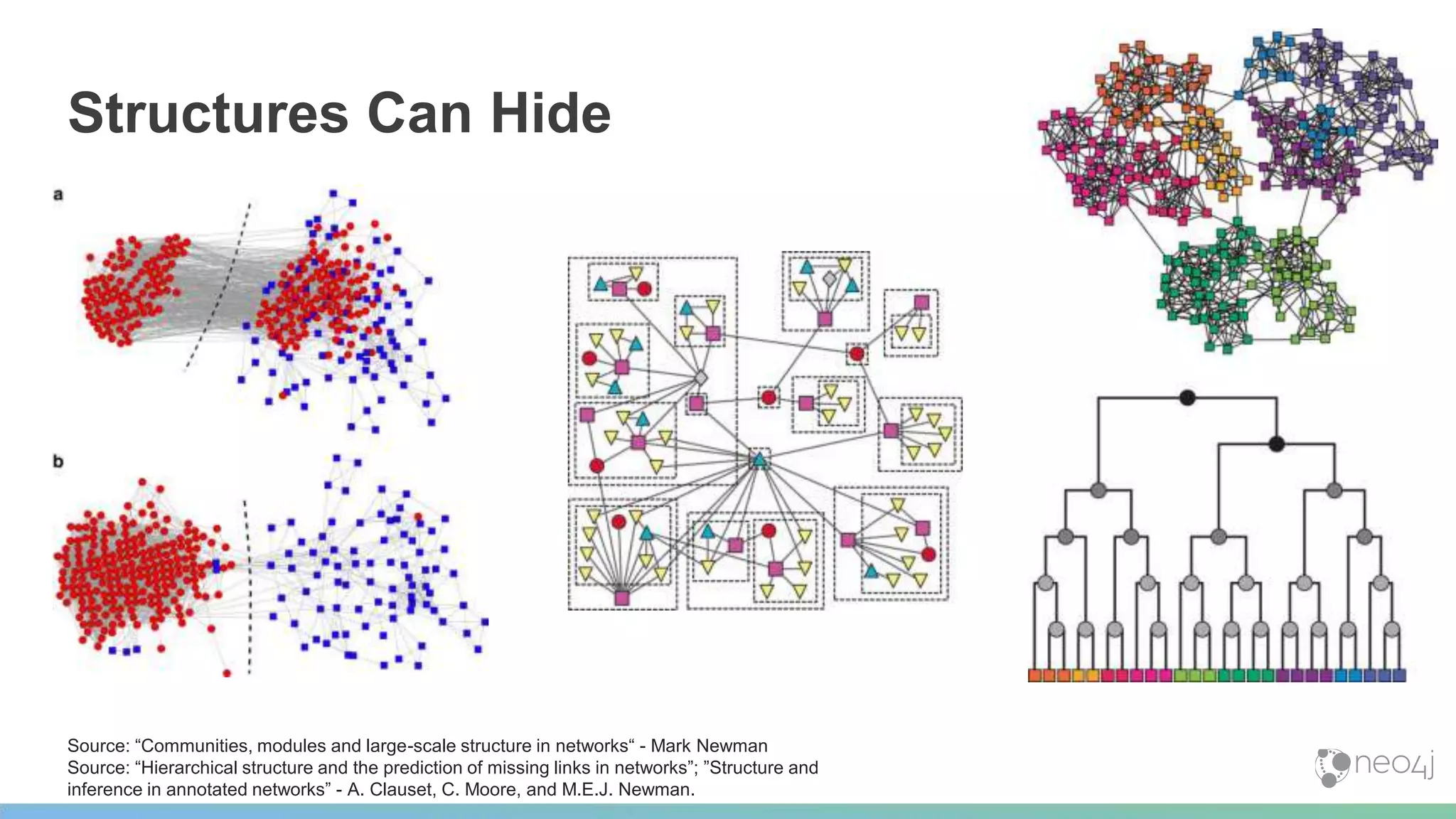
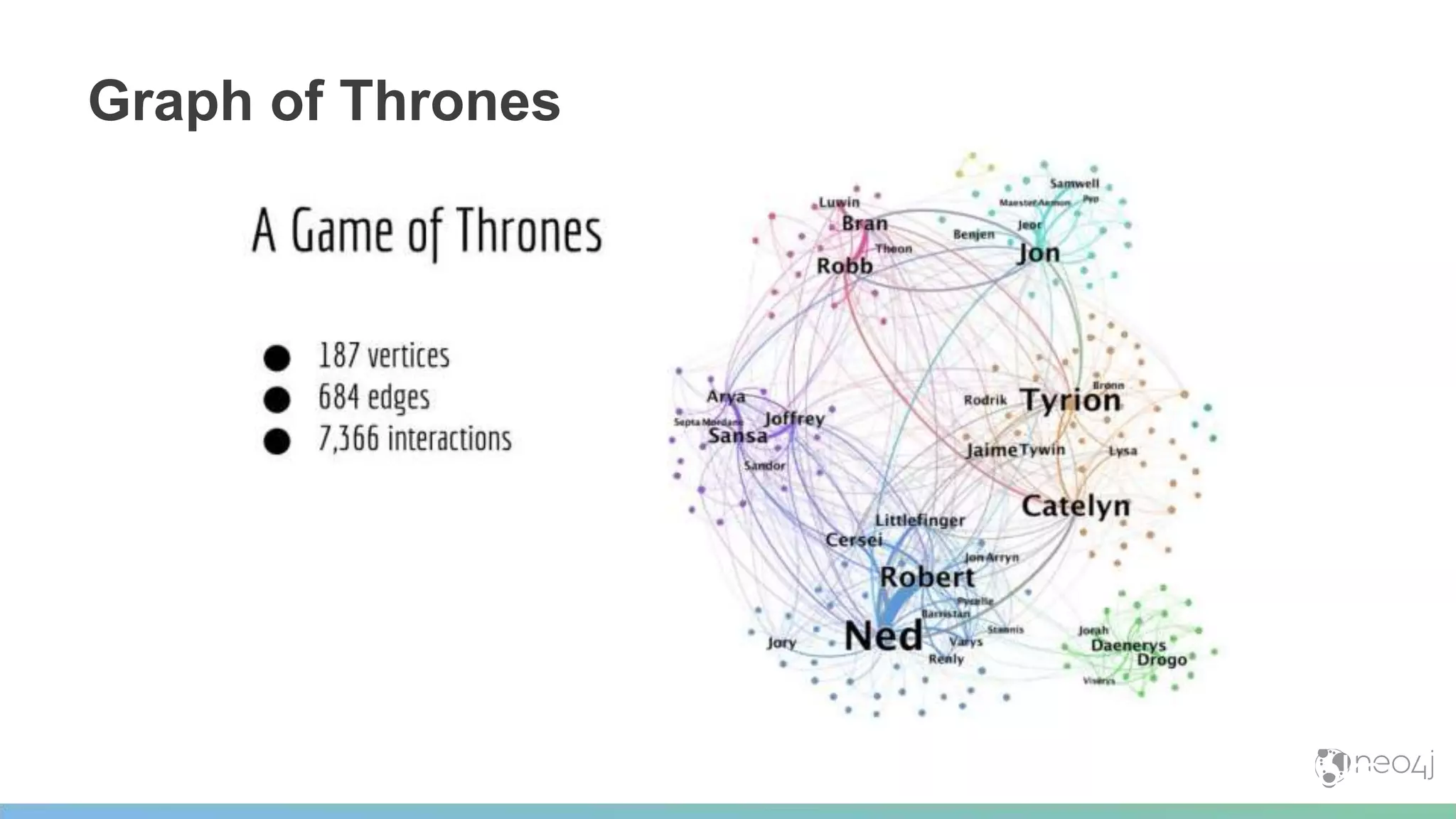
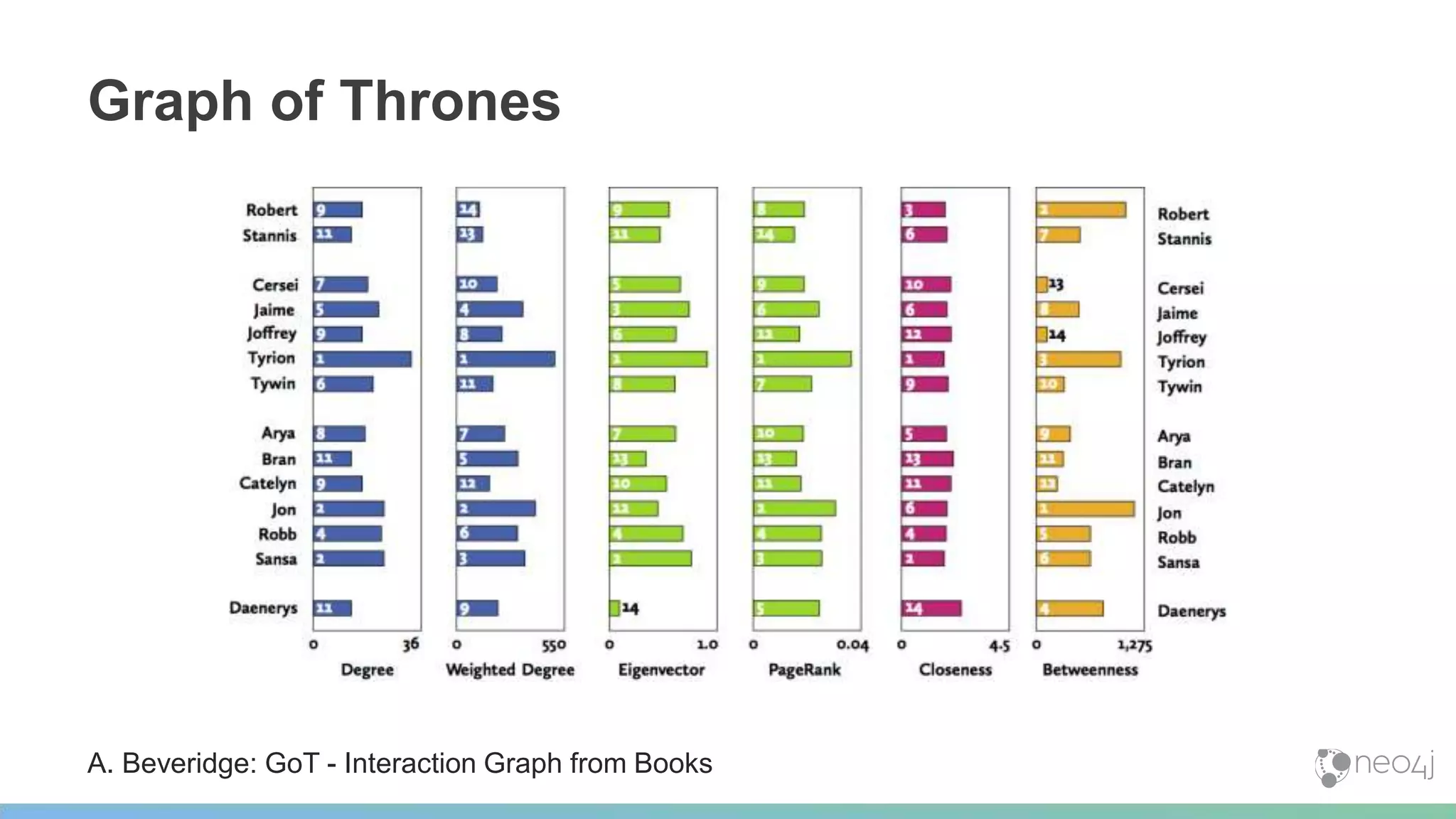
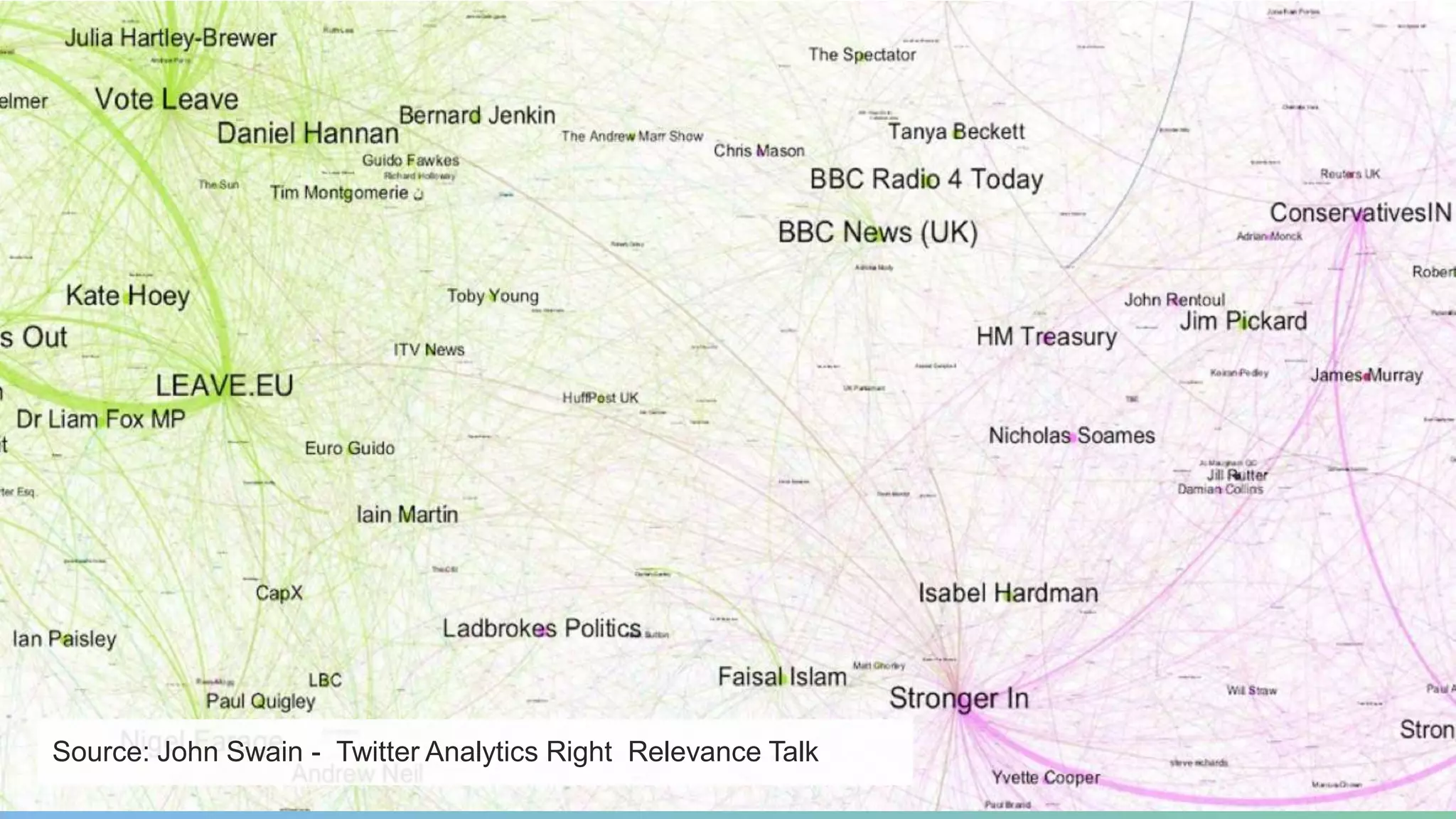
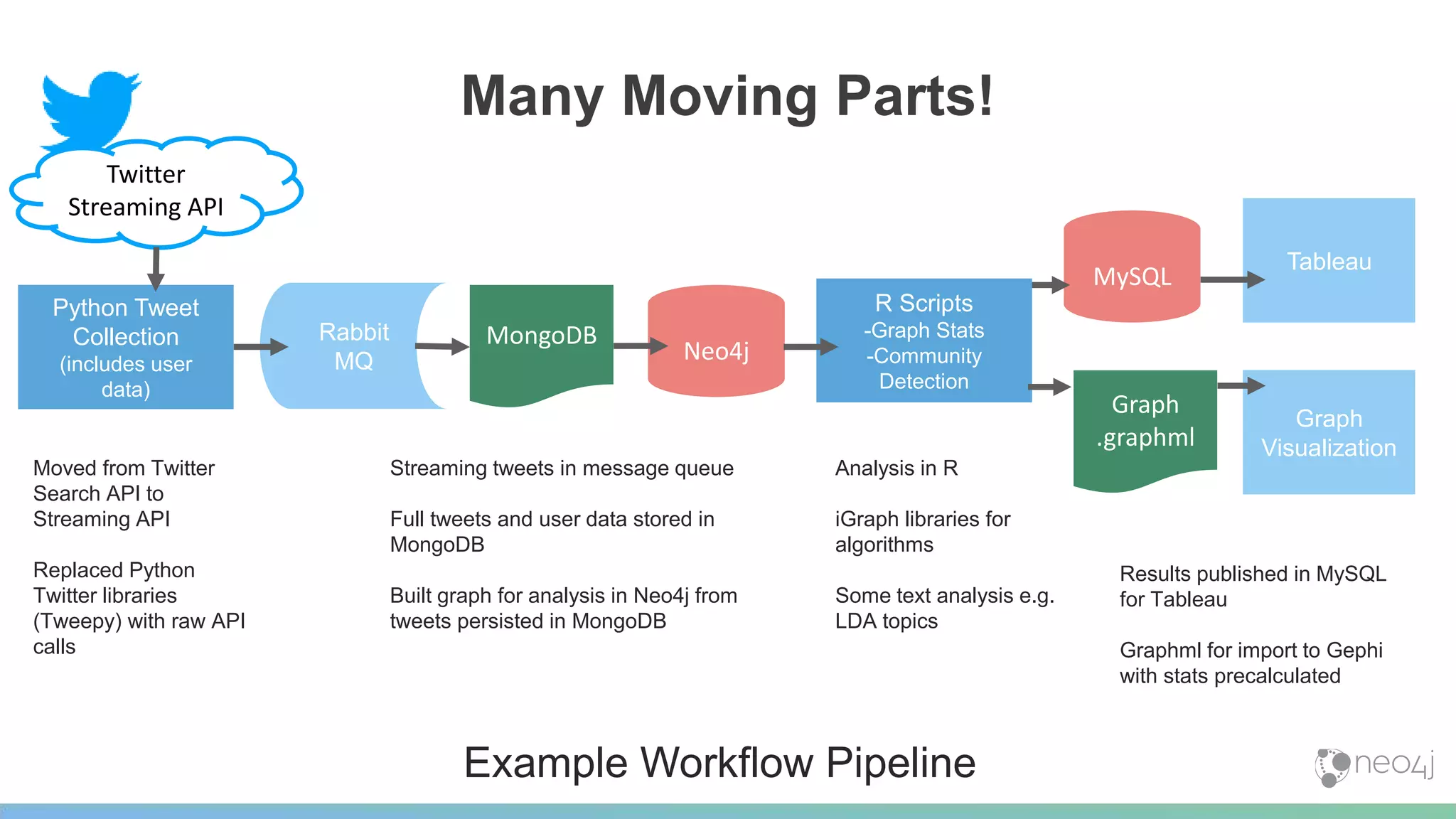
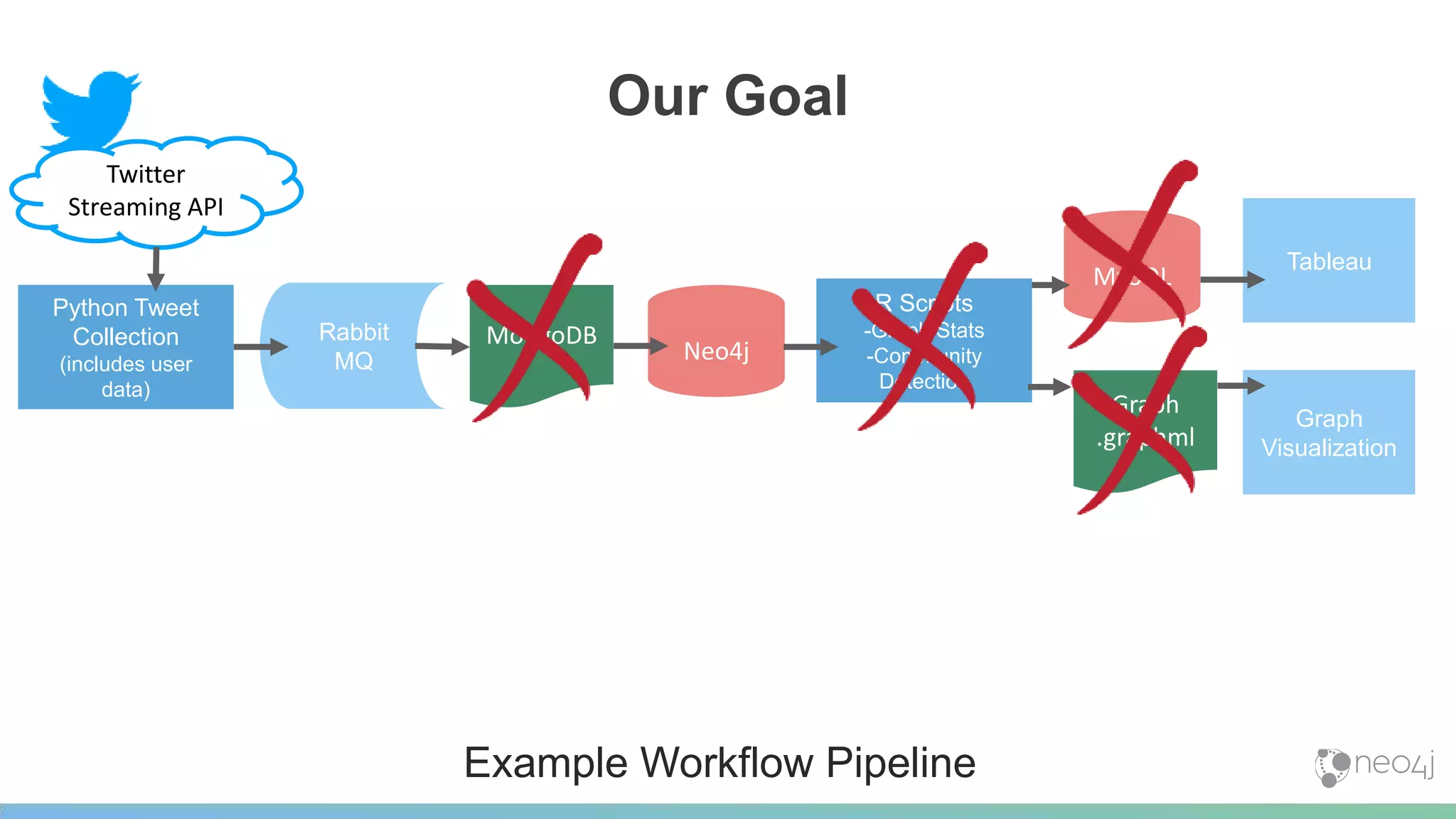
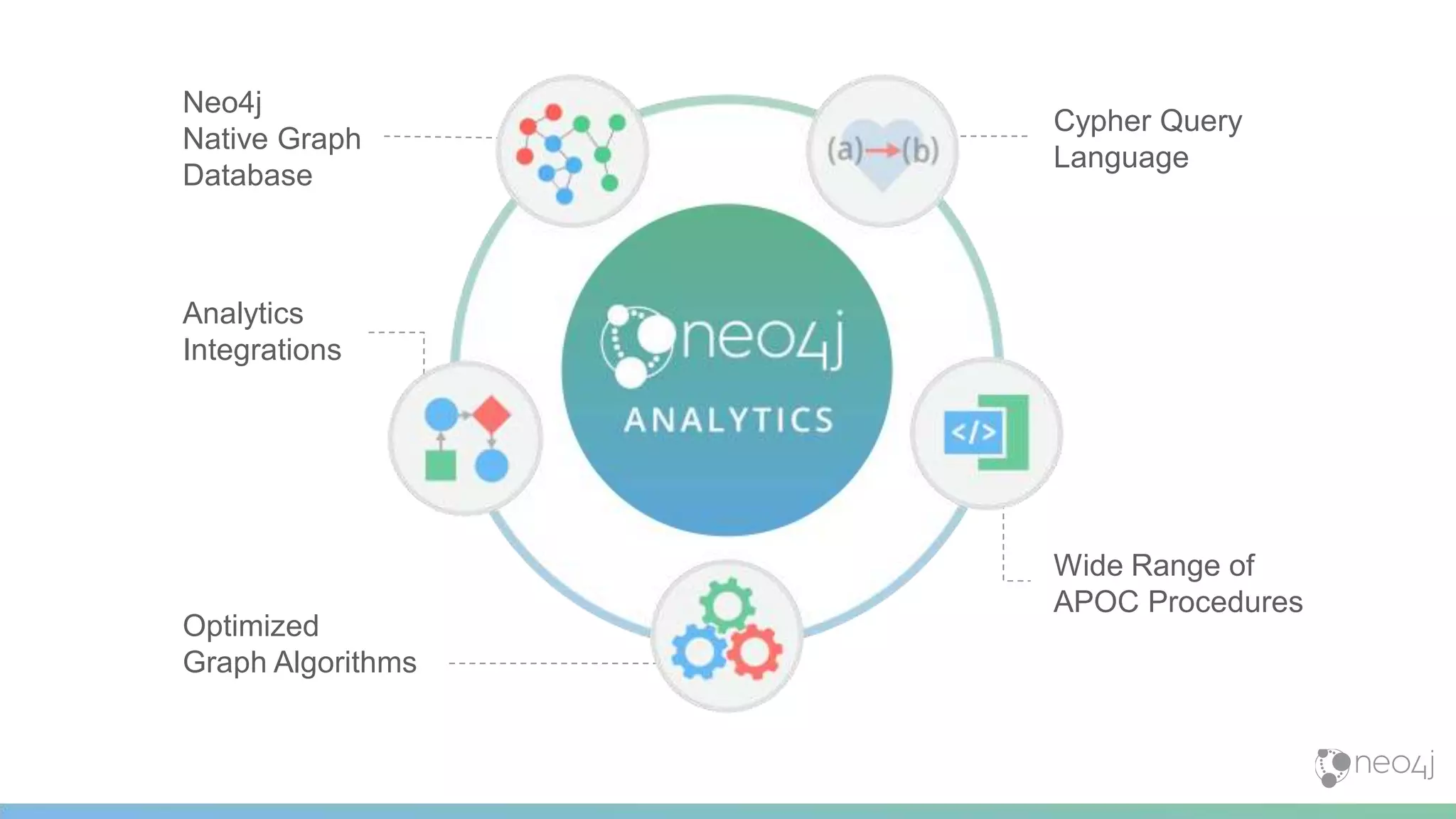
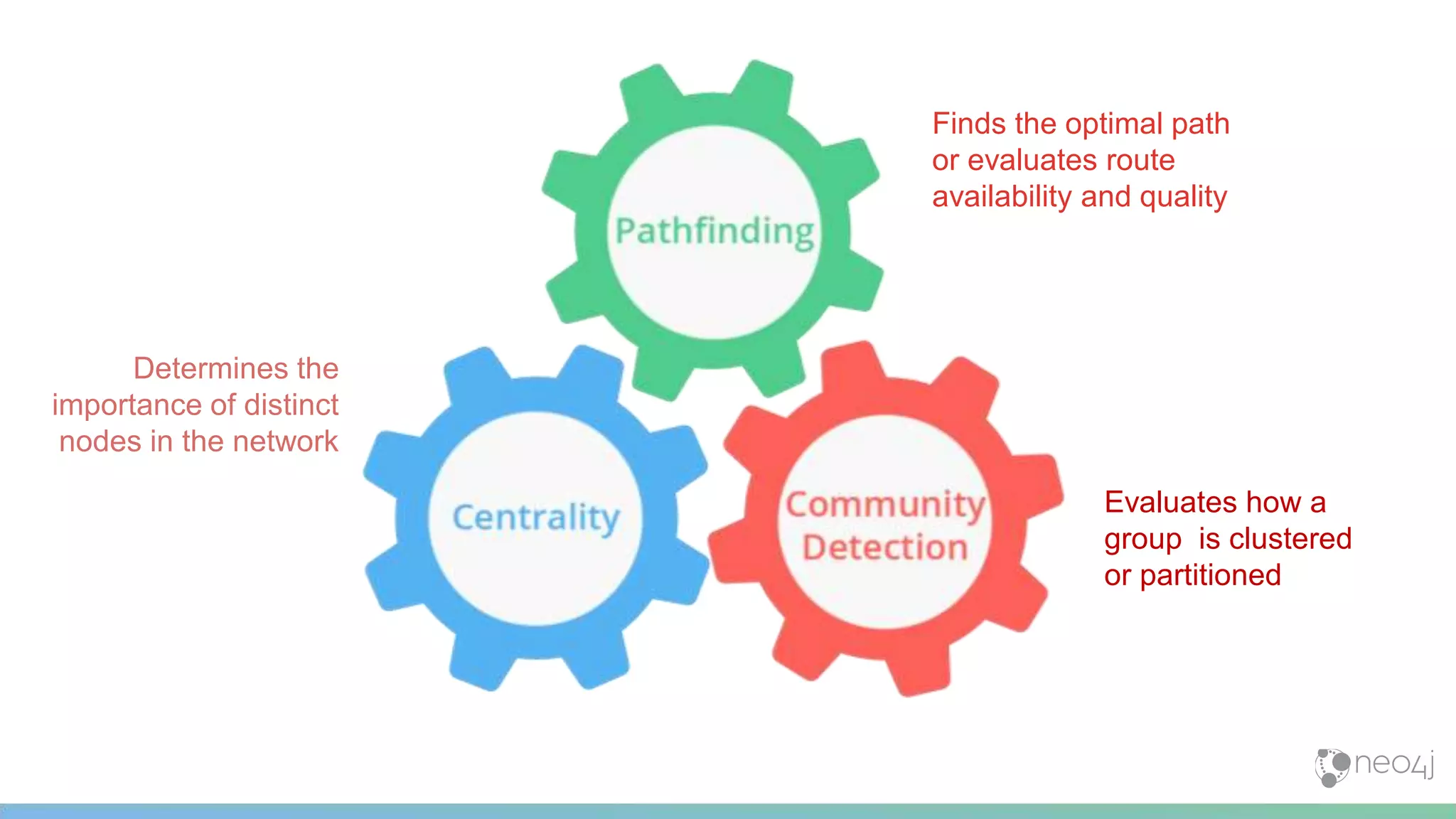
This document provides a summary of an event on optimized graph algorithms in Neo4j. It includes an introduction to graph analytics and algorithms, examples of analyzing real-world networks, and a demonstration of Neo4j's native graph database capabilities for graph analytics and algorithms. The presentation discusses preprocessing data from multiple sources into a graph, running algorithms like PageRank and community detection, and visualizing results.























































































