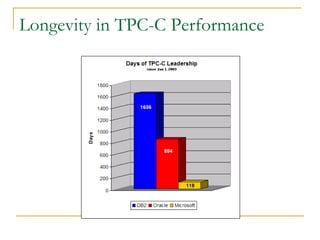
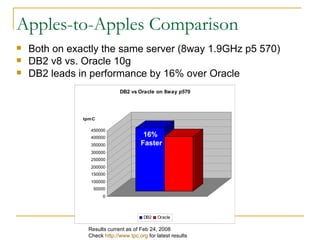
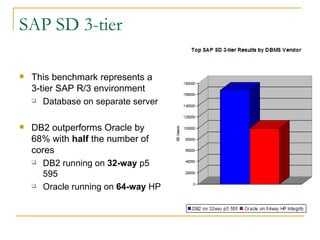
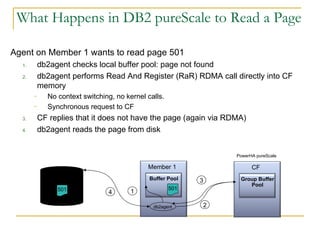
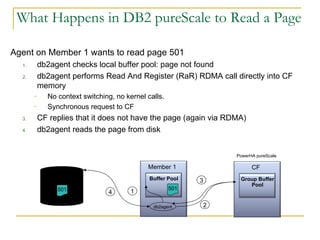
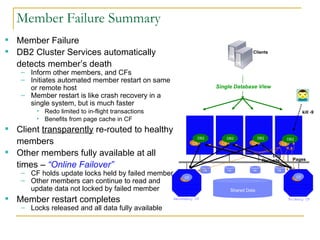
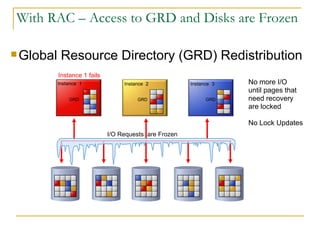
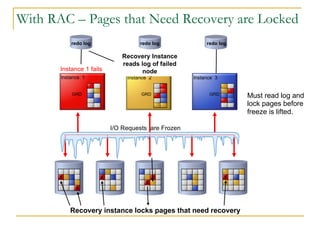
The document compares the online transaction processing (OLTP) performance of DB2 and Oracle Database. It discusses how DB2 offers more efficient logging and memory usage, which enables higher transactional performance on benchmarks like TPC-C. It also describes how DB2 pureScale provides faster and more scalable data sharing between nodes through its use of remote direct memory access (RDMA), avoiding the overhead of processes in Oracle RAC. DB2 pureScale allows nearly all data to remain available during node failures through its centralized coordination and recovery capabilities.
![Showdown: DB2 vs. Oracle Database for OLTP Conor O’Mahony Email: [email_address] Twitter: conor_omahony Blog: db2news.wordpress.com Conor O’Mahony Email: [email_address] Twitter: conor_omahony Blog: database-diary.com](https://image.slidesharecdn.com/showdown-ibmdb2versusoracledatabaseforoltp-110901093548-phpapp01/85/Showdown-IBM-DB2-versus-Oracle-Database-for-OLTP-1-320.jpg)























![Thank You! For more information, see www.ibm.com/db2 Or contact me at: Conor O’Mahony Email: [email_address] Twitter: conor_omahony Blog: database-diary.com](https://image.slidesharecdn.com/showdown-ibmdb2versusoracledatabaseforoltp-110901093548-phpapp01/85/Showdown-IBM-DB2-versus-Oracle-Database-for-OLTP-33-320.jpg)























































![[db tech showcase Tokyo 2016] E34: Oracle SE - RAC, HA and Standby are Still ...](https://cdn.slidesharecdn.com/ss_thumbnails/lqy2zqfxqmif8xeztxtr-signature-44327555e43d6a00760901a1f10c738a3c30da5dd494b81e3f7ae75f088cd2d2-poli-160815043717-thumbnail.jpg?width=640&height=640&fit=bounds)





























