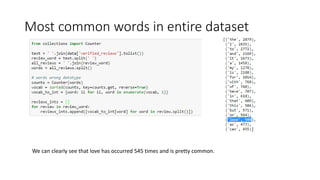
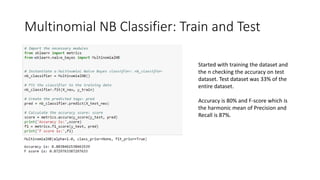
This document discusses sentiment analysis of Amazon Alexa reviews using machine learning classifiers. It analyzes a dataset of over 3,000 Alexa product reviews rated 1-5, classifying ratings 1-4 as negative and 5 as positive. Two classifiers are tested: Multinomial Naive Bayes achieves 80% accuracy and 87% F1 score, while Random Forest achieves slightly higher at 81% accuracy and 87.5% F1 score. Key terms like "love", "disappointed" are important indicators. Overall the analysis demonstrates the ability to accurately predict sentiment from reviews with these techniques.