Downloaded 25 times













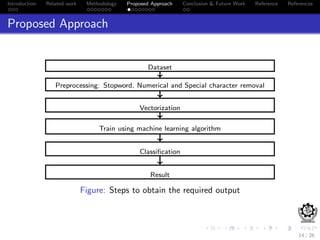




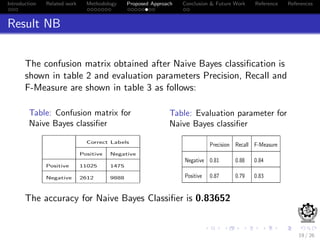








This document discusses sentiment analysis of movie reviews using machine learning techniques. It presents the methodology used, which includes preprocessing reviews, vectorizing them using TF-IDF, and training classifiers like Naive Bayes and Support Vector Machines. The results show that SVM outperforms NB, achieving an accuracy of 86.976% on a labeled movie review dataset. Future work proposed includes exploring other supervised learning classifiers and comparing their performance to SVM.























































