Downloaded 28 times




















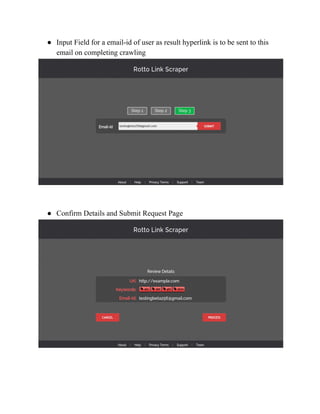




The document is a summer internship report by Akshay Pratap Singh detailing the development of a Rotto Link web crawler, aimed at identifying broken links within websites, as part of his Bachelor of Technology degree at Shri Mata Vaishno Devi University. The web crawler operates by taking a seed URL, analyzing hyperlinks, and storing results in a database while utilizing a Flask-based backend and an AngularJS frontend. The internship, conducted at Ophio Computer Solutions, focuses on enhancing web applications and providing tools to improve website maintenance through automated link checking.






























![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































